
最远点采样(FSP)是一种常用的采样算法,主要用于点云数据(如激光雷达点云数据、分子坐标等)的采样。
一:算法原理
最远点采样的研究对象是点云数据,即一堆离散的坐标点。广义上其它许多样本数据类型也可以使用FPS算法并进行最远点采样,如我们经常使用的iris、dry bean dataset等数据集的数据类型,这些数据可以把每一条看做p维空间中的一个点,并且也可以用各种距离度量方法计算各条数据之间的距离。兔兔在这里为了方便,只针对三维点云数据进行实例讲解。
FPS的核心思想是使得所有采样点之间的距离尽可能的远,也就是数据尽可能的离散均匀。例如对于数据(1,2,3,4,5,6,7,8,9),我们若需要采集3个点,第一个点为1,那么第二个点就需要选择与1最远的点,即9,第三个点需要与1和9都尽可能的远,即5。当然,如果我们继续取点,则需要与1,5,7距离都尽可能的远,即3或7。这个过程是我们的一种直观理解,对于这一类问题,我们需要一种确定的算法来进行采样。
1.首先,对于三维点云数据,我们一般采取欧式距离度量点之间距离,即空间中两点直线距离。
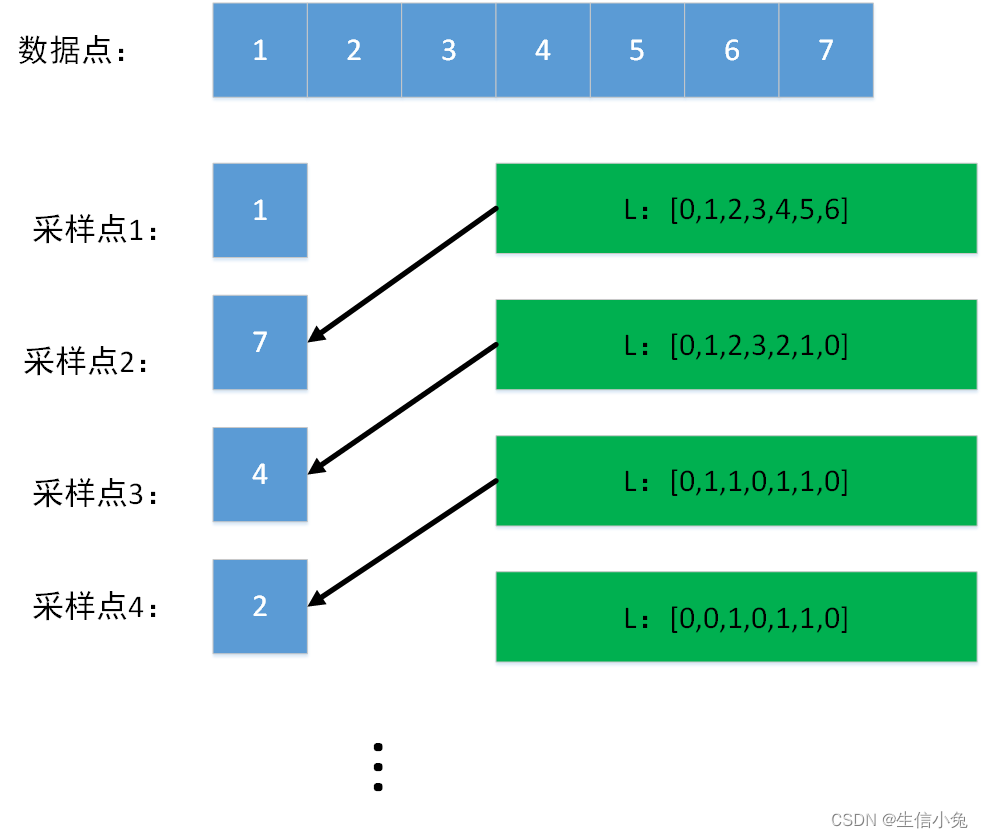
2.在对第一个点采样时,理论上我们可以随机从数据中选取一个点。另一种规范的做法是:求整个数据点(点云)的重心(即所有点坐标求和平均得到的坐标点),选取距离重心最远的点,记为P0。
然后,我们继续选取剩余的所有点中距离P0最远的点,记为P1。
对于剩下的每个点,分别计算到P0和P1的距离,并选取最短的那个作为这个点到P0,P1整体的距离。计算这些距离后选择距离最大的那个点,记为P2。
依次重复操作,直到选取所需数目的点。例如:继续选取点,分别计算剩余各点到P0,P1,P2的距离,并选取最短的那个距离作为某点到P1,P2,P3整体的距离,然后选取这些点中距离最大的那个点,记为P3。
在算法实现的过程中,在第3步计算所有点到P0距离时,我们不妨定义一个一维数据L,L中各个位置的值表示各点到P0的距离,L中值最大的那个索引对应的点即为P1。寻找P2时,我们计算各点到P1距离,如果距离小于到P0的距离,就更新L数组中相应位置的值,否则不更改,计算好后L中值最大的那个索引对应的点即为P2,以此类推。
二:算法实现
import numpy as np
def distance(p1,p2):
return np.sqrt(np.sum((p1-p2)**2))
def FPS(sample,num):
'''sample:采样点云数据,
num:需要采样的数据点个数'''
n=sample.shape[0]
center=np.mean(sample,axis=0) #点云重心
select_p=[] #储存采集点索引
L=[]
for i in range(n):
L.append(distance(sample[i],center))
p0=np.argmax(L)
select_p.append(p0) #选距离重心最远点p0
L=np.zeros(shape=n)
for i in range(num-1):
for p in range(n):
d = []
for j in select_p:
d.append(distance(sample[j],sample[p]))
d=min(d)
L[p]=d
select_p.append(np.argmax(L))
return select_p,sample[select_p]
point=np.random.randint(0,20,size=(200,3))
index,select_sample=FPS(sample=point,num=100)
print(index,select_sample)
当然,上述代码虽然比较直观,并且能够实现FPS采样,但是每一次都需要重复计算点到各采样点的值,这样会使程序运行速度慢,兔兔运行时需要8.52s。
import numpy as np
def distance(p1,p2):
return np.sqrt(np.sum((p1-p2)**2))
def FPS(sample,num):
'''sample:采样点云数据,
num:需要采样的数据点个数'''
n=sample.shape[0]
center=np.mean(sample,axis=0) #点云重心
select_p=[] #储存采集点索引
L=[]
for i in range(n):
L.append(distance(sample[i],center))
p0=np.argmax(L)
select_p.append(p0) #选距离重心最远点p0
L=[]
for i in range(n):
L.append(distance(p0,sample[i]))
select_p.append(np.argmax(L))
for i in range(num-2):
for p in range(n):
d=distance(sample[select_p[-1]],sample[p])
if d<=L[p]:
L[p]=d
select_p.append(np.argmax(L))
return select_p,sample[select_p]
index,select_sample=FPS(sample=point,num=100)
print(index,select_sample)
改进后代码的运行时间约为0.24s,时间明显缩短许多。
三:总结
FPS作为一种采样算法,够对一些数据进行有效的采样,在实际问题中具有广泛应用,例如:当今十分热门的PointNet++中也使用了这种方法,我想很多同学也是因为PointNet++等模型来学习FPS算法,但是FPS的应用远远不止局限于此,它的这种方法与思想仍可以更广泛地应用于其它方面。
版权归原作者 生信小兔 所有, 如有侵权,请联系我们删除。