
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
一、Pytorch简介
PyTorch是一个基于python的科学计算包,主要针对两类人群:
- 作为NumPy的替代品,可以利用GPU的性能进行计算
- 作为一个高灵活性、速度快的深度学习平台
在PyTorch中搭建神经网络并使用真实的天气信息预测明天是否会下雨。
- 预处理 CSV 文件并将数据转换为张量
- 使用 PyTorch 构建神经网络模型
- 使用损失函数和优化器来训练模型
- 评估模型并了解分类不平衡的危害
在开始构建神经网络之前,首先了解一下几个重要概念。
torch.Tensor一个多维数组,支持诸如backward()等的自动求导操作,同时也保存了张量的梯度。nn.Module神经网络模块。是一种方便封装参数的方式,具有将参数移动到GPU、导出、加载等功能。nn.Parameter张量的一种,当它作为一个属性分配给一个Module时,它会被自动注册为一个参数。autograd.Function实现了自动求导前向和反向传播的定义,每个Tensor至少创建一个Function节点,该节点连接到创建Tensor的函数并对其历史进行编码。
二、实验过程
2.1数据集介绍
数据集包含来自多个澳大利亚气象站的每日天气信息。本次目标是要回答一个简单的问题:明天会下雨吗?
2.2加载数据
首先导入本次实验用到的第三方库
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from torch import nn, optim
import torch.nn.functional as F
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 6
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
接下来先通过Pandas读取导入数据集
df = pd.read_csv('./data/weatherAUS.csv')
df.head()

这里有很多特征列。也有很多NaN。下面来看看整体数据集大小。
df.shape
(145460, 23)
从数据集形状看,这里数据还不少,超过14.5w条数据。
2.3数据预处理
在数据预处理这,我们并不希望数据集和目标问题有多复杂,尝试将通过删除大部分数据来简化这个问题。这里只使用4个特征来预测明天是否会下雨。在你实际案例中,根据实际问题,特征数量可以比这多,也可以比这少,只要注意下面输入数据维度即可。
cols = ['Rainfall', 'Humidity3pm', 'Pressure9am', 'RainToday', 'RainTomorrow']
df = df[cols]
2.3.1特征转换
因为神经网络只能处理数字。所以我们将把文字的
yes 和 no
分别转换为数字
1 和 0。
df['RainToday'].replace({'No': 0, 'Yes': 1}, inplace = True)
df['RainTomorrow'].replace({'No': 0, 'Yes': 1}, inplace = True)
2.3.2缺失值处理
删除缺少值的行。也许会有更好的方法来处理这些缺失的行,但我们这里将简单地处理,直接删除含有缺失值的行。
df = df.dropna(how='any')
df.head()

2.3.3样本不平衡处理
到目前为止,我们有了一个可以使用的数据集。这里我们需要回答的一个重要问题是 -- 我们的数据集是否平衡? 或者 明天到底会下多少次雨?
因此通过
sns.countplot
函数直接定性分析整个样本集中是否下雨分别多少次,以此判断正负样本(是否有雨)是否平衡。
sns.countplot(df.RainTomorrow);

从结果看,下雨次数明显比不下雨次数要少很多。再通过具体定量计算正负样本数。
df.RainTomorrow.value_counts() / df.shape[0]
0.0 0.778762
1.0 0.221238
Name: RainTomorrow, dtype: float64
事情看起来不妙。约78%的数据点表示明天不会下雨。这意味着一个预测明天是否下雨的模型在78%的时间里是正确的。
如果想要解决此次样本不平衡可以采用欠采样或过采样处理,以缓解其带来的影响,我们暂不做任何处理,但愿他对结果影响不大。
2.4特征工程
2.4.1划分训练集和测试集
数据预处理的最后一步是将数据分割为训练集和测试集。这一步大家应该并不陌生,可以直接使用
train_test_split()。
X = df[['Rainfall', 'Humidity3pm', 'RainToday', 'Pressure9am']]
y = df[['RainTomorrow']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=RANDOM_SEED)
2.4.2数据类型转换
为了符合 PyTorch 所需求的数据类型。使用 python标准库将数据加载到numpy数组里。然后将这个数组转化成将全部数据转换为张量
(torch.Tensor)
。
注意:Torch张量和NumPy数组将共享它们的底层内存位置,因此当一个改变时,另外也会改变。
X_train.head()

PyTorch中也是非常方便,直接通过
from_numpy
直接转换。
X_train = torch.from_numpy(X_train.to_numpy()).float()
y_train = torch.squeeze(torch.from_numpy(y_train.to_numpy()).float())
X_test = torch.from_numpy(X_test.to_numpy()).float()
y_test = torch.squeeze(torch.from_numpy(y_test.to_numpy()).float())
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
torch.Size([99751, 4]) torch.Size([99751])
torch.Size([24938, 4]) torch.Size([24938])
到目前为止,所有数据准备工作已经结束。
2.5构建模型
接下来我们将使用PyTorch建立一个简单的神经网络(NN),尝试预测明天是否会下雨。本次构建的神经网络结构分为三个层,输入层、输出层和隐藏层。
输入层: 我们的输入包含四列数据:
"Rainfall, Humidity3pm, RainToday, Pressure9am"
(降雨量,湿度下午3点,今天下雨,压力上午9点)。将为此创建一个适当的输入层。
输出层: 输出将是一个介于 0 和 1 之间的数字,代表模型认为明天下雨的可能性。预测将由网络的输出层提供给我们。
隐藏层: 将在输入层和输出层之间添加两个隐藏层。这些层的参数(神经元)将决定最终输出。所有层都将是全连接的,即全连接层。
一个神经网络的典型训练过程如下:
定义包含一些可学习参数(或者叫权重)的神经网络
在输入数据集上迭代
通过网络处理输入
计算loss(输出和正确答案的距离)
将梯度反向传播给网络的参数
更新网络的权重,一般使用一个简单的规则:
weight = weight - learning_rate * gradient可以使用
torch.nn
包来构建神经网络。即使用 PyTorch 构建神经网络的一种简单方法是创建一个继承自
torch.nn.Module
的类。
这里将
nn.Module
子类化(它本身是一个类并且能够跟踪状态)。在这种情况下,我们要创建一个类,该类包含前进步骤的权重,偏差和方法。
nn.Module
具有许多我们将要使用的属性和方法(例如
.parameters()和.zero_grad()
)。
class Net(nn.Module):
def __init__(self, n_features):
super(Net, self).__init__()
self.fc1 = nn.Linear(n_features, 5)
self.fc2 = nn.Linear(5, 3)
self.fc3 = nn.Linear(3, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return torch.sigmoid(self.fc3(x))
我们只需要定义 forward 函数,backward函数会在使用autograd时自动定义,backward函数用来计算导数。我们可以在 forward 函数中使用任何针对张量的操作和计算。
2.5.1可视化神经元
这里的可视化神经元主要基于https://github.com/Prodicode/ann-visualizer
net = Net(X_train.shape[1])
# pip install graphviz
# mac上安装graphviz 需要用 brew install graphviz
ann_viz(net, view=True)

我们首先在构造函数中创建模型的层。
forward()
方法是奇迹发生的地方。它接受输入 并允许它流过每一层。有一个相应的由PyTorch定义到向后传递
backward()
方法,它允许模型从当前发生的误差中学习,并修正模型参数。
2.5.2激活函数
细心的小伙伴可能会注意到构建的神经网络中调用
F.relu
和
torch.sigmoid
。这些是激活函数,那我们为什么需要这些?
神经网络的一个很酷的特性是它们可以近似非线性函数。事实上,已经证明它们可以逼近任何函数。不过,如果想通过堆叠线性层来逼近非线性函数,此时就需要激活函数。激活函数可以让神经网络摆脱线性世界并学习更多。通常将其应用于某个层的输出。
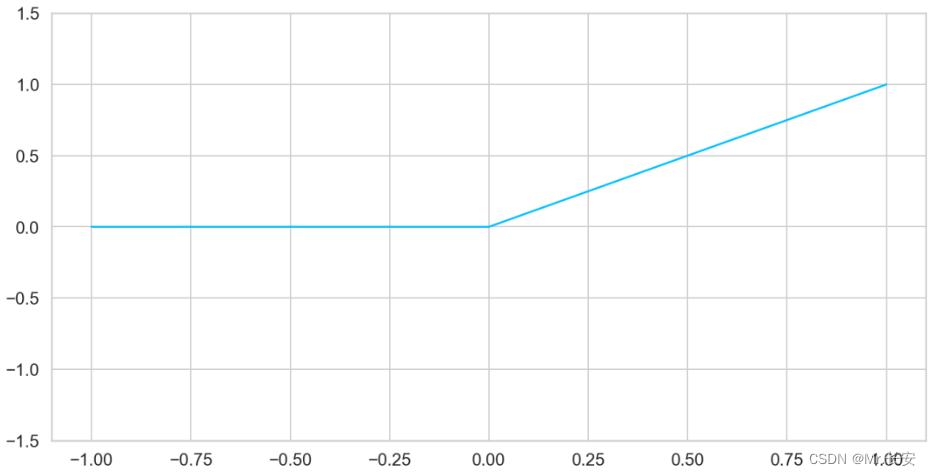
ReLU
从最广泛使用的激活函数之一的 ReLU 定义开始:

该激活函数简单易行,其结果就是输入值与零比较,得到的最大值。
从可视化结果看
ax = plt.gca()
plt.plot(
np.linspace(-1, 1, 5),
F.relu(torch.linspace(-1, 1, steps=5)).numpy()
)
ax.set_ylim([-1.5, 1.5]);
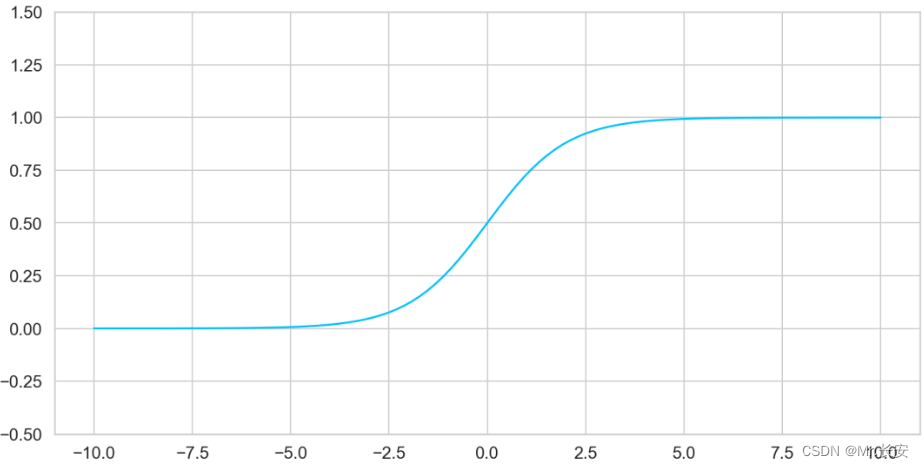
** Sigmoid**
它被定义为:

当需要进行二元决策 / 分类(回答yes或no)时,
sigmoid
函数是很有用的。sigmoid 以一种超级的方式将输入值压缩在 0 和 1 之间。
从可视化结果看
ax = plt.gca()
plt.plot(
np.linspace(-10, 10, 100),
torch.sigmoid(torch.linspace(-10, 10, steps=100)).numpy()
)
ax.set_ylim([-0.5, 1.5]);
2.5.3训练神经网络
目前为止,我们已经看到了如何定义网络,接下来需要找到预测明天是否会下雨的参数。即需要找到该模型应用于此次问题的最佳参数。而要想做到这点,首先需要一些评价指标来告诉我们,该模型目前做得有多好。接下来需要计算损失,并更新网络的权重。
损失函数
一个损失函数接受一对(output, target)作为输入,计算一个值来估计网络的输出和目标值相差多少。BCELoss是一个损失函数,其度量两个向量之间的差。
criterion = nn.BCELoss()
而在我们的例子中,这两个向量即是我们的模型的预测和实际值。该损失函数的期望值由 sigmoid 函数输出。该值越接近 0,模型效果越好。
但是我们如何找到最小化损失函数的参数呢?
优化器
假设我们的神经网络的每个参数都是一个旋钮。优化器的工作是为每个旋钮找到完美的位置,使损失接近0。实战中,模型可能包含数百万甚至数十亿个参数。有这么多旋钮要转,如果有一个高效的优化器可以快速找到解决方案,那就完美了。而理想很丰满,现实很骨感。深度学习中的优化效果只能达到令人满意的结果。在实践中,可以提供可接受的准确性的足够好的参数,就应该心满意足了。在使用神经网络时,PyTorch中提供了许多经过良好调试过的优化器,可能希望使用各种不同的更新规则,如SGD、Nesterov-SGD、Adam、RMSProp等。虽然你可以从这些优化器中选择,一般情况下,首选的还是Adam。
optimizer = optim.Adam(net.parameters(), lr=0.001)
一个模型的可学习参数可以通过
net.parameters()
。
自然地,优化器需要输入参数。第二个参数
lr
是 learning rate (学习率),这是要找到的最优参数和到达最优解的速度之间的权衡。而为此找到最优解的方法或过程可能是黑魔法和大量的暴力“实验”。
在 GPU 上计算
在 GPU 上进行大规模并行计算是现代深度学习的推动因素之一。为此,您将需要配置 NVIDIA GPU。如果你的设备上装有GPU,PyTorch 中可以非常轻松地将所有计算传输到 GPU。
我们首先检查 CUDA 设备是否可用。然后,我们将所有训练和测试数据传输到该设备。最后移动模型和损失函数。张量可以使用
.to
方法移动到任何设备(device)上。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
X_train = X_train.to(device)
y_train = y_train.to(device)
X_test = X_test.to(device)
y_test = y_test.to(device)
net = net.to(device)
criterion = criterion.to(device)
寻找最优参数
拥有损失函数固然很好,追踪模型的准确性是一件更容易理解的事情,而一般通过定义准确性来做模型评价。
def calculate_accuracy(y_true, y_pred):
predicted = y_pred.ge(.5).view(-1)
return (y_true == predicted).sum().float() / len(y_true)
我们定义一个预值,将连续概率值转换为二分类值。即将每个低于 0.5 的值转换为 0,高于0.5的值设置为 1。最后计算正确值的百分比。所有的模块都准备好了,我们可以开始训练我们的模型了。
def round_tensor(t, decimal_places=3):
return round(t.item(), decimal_places)
for epoch in range(1000):
y_pred = net(X_train)
y_pred = torch.squeeze(y_pred)
train_loss = criterion(y_pred, y_train)
if epoch % 100 == 0:
train_acc = calculate_accuracy(y_train, y_pred)
y_test_pred = net(X_test)
y_test_pred = torch.squeeze(y_test_pred)
test_loss = criterion(y_test_pred, y_test)
test_acc = calculate_accuracy(y_test, y_test_pred)
print(f'''epoch {epoch}
Train set - loss: {round_tensor(train_loss)}, accuracy: {round_tensor(train_acc)}
Test set - loss: {round_tensor(test_loss)}, accuracy: {round_tensor(test_acc)}
''')
optimizer.zero_grad() # 清零梯度缓存
train_loss.backward() # 反向传播误差
optimizer.step() # 更新参数

在训练期间,我们向模型传输数据共计
10,000
次。每次测量损失时,将误差传播到模型中,并要求优化器找到更好的参数。用
zero_grad()
方法清零所有参数的梯度缓存,然后进行随机梯度的反向传播。如果忽略了这一步,梯度将会累积,导致模型不可用。测试集上的准确率为 83.4% 听起来挺合理,但可能要让你失望了,这样的结果并不是很理想,接下来看看是如何不合理。但首先我们需要学习如何保存和加载训练好的模型。
2.6保存模型
训练一个好的模型可能需要很多时间。可能是几周、几个月甚至几年。如果在训练过程了忘记保存,或不知道需要保存模型,这将会是非常痛苦的事情。因此这里需要确保我们知道如何保存宝贵的工作。其实保存很容易,但你不能忘记这件事。
MODEL_PATH = 'model.pth' # 后缀名为 .pth
torch.save(net, MODEL_PATH) # 直接使用torch.save()函数即可
当然恢复模型也很容易,直接使用
torch.load()
函数即可。
net = torch.load(MODEL_PATH)
2.7模型评估
如果知道你的模型会犯什么样的错误不是很好吗?当然,这一点是非常难做到的。但是你可以通过一定的方法得到一个估计值。而仅使用准确性来评估并不是一个好方法,尤其在样本不平衡的二分类数据集上。仔细回想一下,我们的数据是一个很不平衡的数据集,其几乎不包含明天会降雨样本。深入研究模型性能的一种方法是评估每个类的精确度和召回率。在我们的例子中,将是结果标签分别是
no rain
和
rain
。
classes = ['No rain', 'Raining']
y_pred = net(X_test)
y_pred = y_pred.ge(.5).view(-1).cpu()
y_test = y_test.cpu()
print(classification_report(y_test, y_pred, target_names=classes))
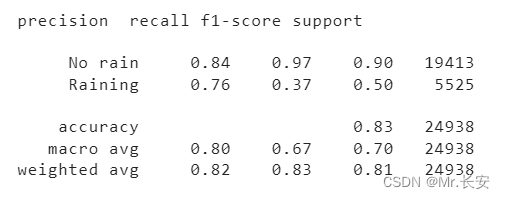
精确度最大值为1,表明该模型只适用于识别相关的样本。召回率最大值为1,表示模型可以在这个类的数据集中找到所有相关的示例。可以看到模型在无雨类方面表现良好,因为样本中无雨类样本数量较大。不幸的是,我们不能完全相信有雨类的预测,因为样本不平衡导致模型倾向于无雨类。可以通过查看一个简单的混淆矩阵来评估二分类效果。
cm = confusion_matrix(y_test, y_pred)
df_cm = pd.DataFrame(cm, index=classes, columns=classes)
hmap = sns.heatmap(df_cm, annot=True, fmt="d")
hmap.yaxis.set_ticklabels(hmap.yaxis.get_ticklabels(), rotation=0, ha='right')
hmap.xaxis.set_ticklabels(hmap.xaxis.get_ticklabels(), rotation=30, ha='right')
plt.ylabel('True label')
plt.xlabel('Predicted label');

你可以清楚地看到,当我们的模型预测要下雨时,我们应该抱有怀疑的态度。
2.8模型预测
使用一些假设的例子上测试下模型。
def will_it_rain(rainfall, humidity, rain_today, pressure):
t = torch.as_tensor([rainfall, humidity, rain_today, pressure]) \
.float() \
.to(device)
output = net(t)
return output.ge(0.5).item()
这个函数将根据模型预测返回一个布尔值。让我们试试看:
will_it_rain(rainfall=10, humidity=10,
rain_today=True, pressure=2)
>>> True
will_it_rain(rainfall=0, humidity=1,
rain_today=False, pressure=100)
>>> False
根据一些参数得到了两种不同的返回值。到这里为止,模型已准备好部署来,但实际情况下,请不要匆忙部署,因为该模型并不是一个最佳的状态,只是用来掩饰如何使用PyTorch搭建模型!
三、总结
如果你看到这里,将给你点个赞!因为你现在成功搭建了一个可以预测天气的神经网络深度学习模型。虽然此次用PyTorch搭建的深度学习模型是一个入门级别的模型,但其他更加复杂的神经网络模型的核心步骤与此类似。
说实话,构建性能良好的模型真的很难,但在多次搭建模型过程中,你会不断学到一些技巧,并能够不断进步,这将会帮助你以后做的更好。
版权归原作者 Mr.长安 所有, 如有侵权,请联系我们删除。