
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
BP神经网络需要注意的地方。
今天我们主要和大家说一下BP神经网络需要注意的地方
数值型字段的预处理方式
因为我们BP神经网络输入字段一般只接受0-1之间的数值,所以我们要对数值型字段进行处理,比较通用的有极值标准化,
极值标准化,就是将某值减去最小值除以最大值和最小值的差。
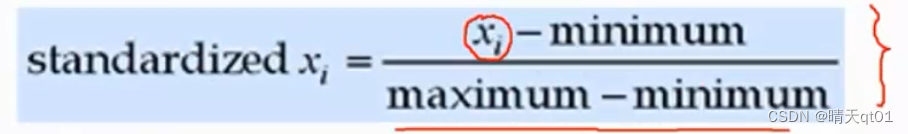
数值型或者顺序型的数值,都可以用该值无论原来的值有多大,都会被处理为0~1之间
类别型字段的预处理方式:
比如类别型字段里有男女,或者很多个种类的字段。 一般有3种编码处理方法,按情况而定
第一种distributed(binary)coding scheme
这个叫分散编码技巧,比如4个种类,我们采用2个神经元进行输入,种类1是0,1,种类2是1,0,种类3是1,1,种类4是0,0
这种编码技巧不好,虽然神经元比较少,但是效果通常比较差。为什么呢:因为系统会自动认为01,10,这两个的距离比较近,而11,00,的距离比较远。事实是4个值互相独立,没有距离的关系。
第二种1-of-N coding scheme
这个编码方式使用的人比较多。这个其实就是我们的one hot encoding独热编码的模式。比如4个种类的类别字段,我们就采取4个神经元进行输入,1000代表种类1,0100代表种类2,0010代表种类3,0001代表种类4
第三种1-of-N-1 coding scheme
这个编码方式使用的人也比较多,就是之前我们说独热模型,可能会导致神经元间共线性极强,就会采取少一个输入层神经元。比如4个种类。种类1是100,种类2是010,种类3是001,种类4是000。它和上面的方法差不多。
目标字段的数据预处理:
因为我们神经网络使用的是sigmoid function 所以就会导致结果数值,
比如目前我需要预测某人的年收入,1万,2万,还是3万,我们就不能使用这种数值,必须要标准化,让他介于0-1之间,
就可以把它设为1个神经元节点,分为高收入(high loyalty)和第收入(low loyalty)越接近1就收入就越高,越接近0收入就越低。或者用两个节点,10代表高收入(high loyalty)01代表低收入(low loyalty)也可以。两个节点就必须用softmax function 因为不能同时高收入或者低收入
如果输出的是n个值比如杂志喜好也要用独热模型,1-of-N的编码模式来编码。比如4个种类,我们采用4个神经元进行输出,种类1是0,1,0,0种类2是1,0,0,0种类3是0,0,0,1,种类4是0,0,1,0,
数据预处理实际案例:
案例一,客户好坏预测
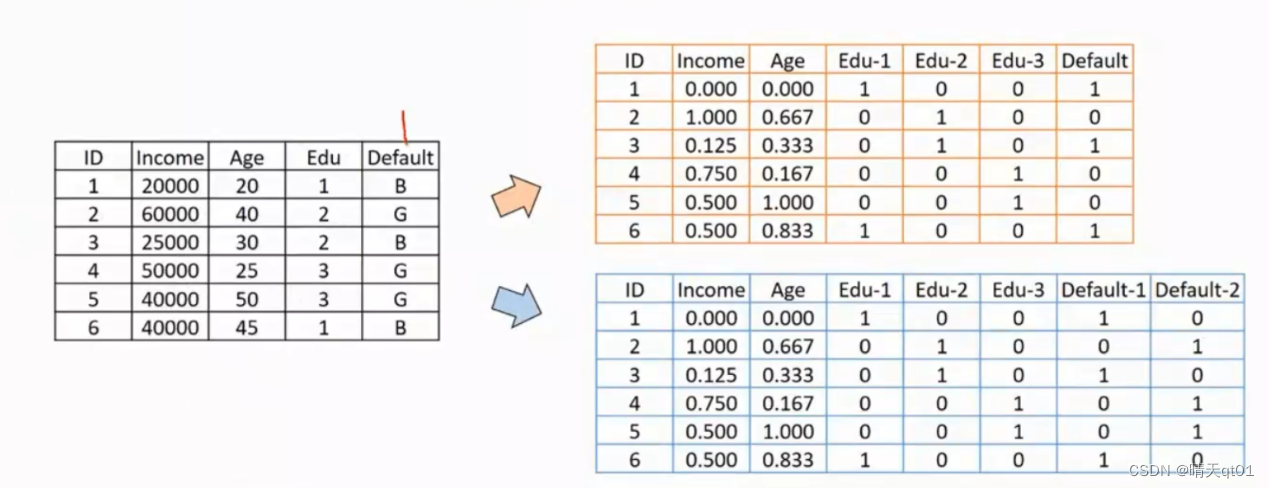
这是一个分两类的问题。B代表坏客户,G代表好客户。输入字段都是数值型字段。education一般是类别型
这里的数值型字段我们都采用了极值标准化的方法,教育字段我们采用了独热模型的编码方式 目标字段有两种情况,第一种就是把坏客户当成1,好客户当成0,或者采用2个字段,好客户为10,坏客户为01。
两种方法的区别就在于激活函数,一个用的是smoid function和softmax function
案例二数字预测:

输入字段1是促销花费,area是电面面积,position是店面位置,0是市区,1是郊区。刚好。目标字段是来电客户人数千人为单位。
前两个字段我们就直接采用极值标准化。Position改变一下字段类型就好。然后目标字段也是进行极值标准化,但是因为我们要预测的话肯定要把结果还原为原来的数值。预测之后,这时我们直接把它乘以最大值与最小值的差,在加上最小值,就会变回原来的数值。
所以目标字段是数值型字段还是类别型字段的唯一区别就在于前者介于0-1之间,后者要么是1要么是0(狗头)
BP神经网络总结:
我们做一个BP神经网络的总结,
BP神经网络有输入层,隐藏层,输出层
输入层将数据给隐藏层,隐藏层用组合函数组合之后,过激活函数,这边最经常使用的是sigmoid function,
输出层就看你是回归问题还是二分类还是,多分类问题。第一个用线性函数,第二个就sigmoid,第三个就softmax函数。
刚开始我们使用从左往右的处理方式feedforward 然后结果不理想,在使用backward pass 来修正权重值和bias。利用节点误差来调整。先利用输出层的节点误差,然后隐藏层的节点误差,一步一步由后往前传导过去。得到优化的BP神经网络模型。
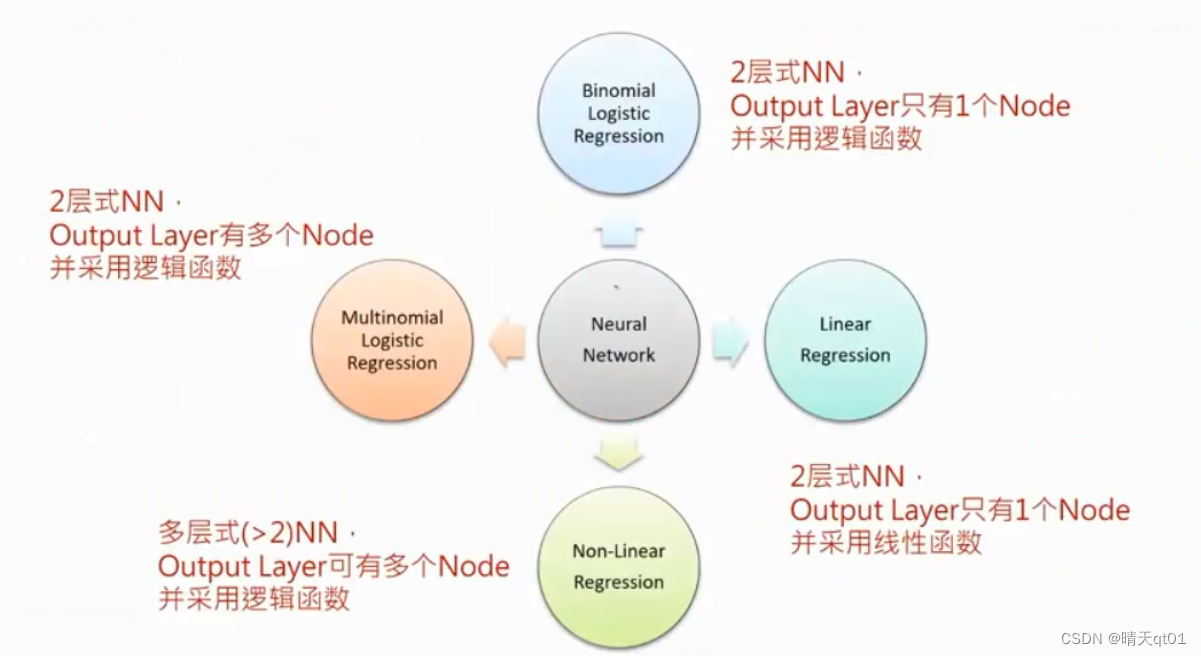
BP神经网络与逻辑回归、线性回归及非线性回归间的关系。
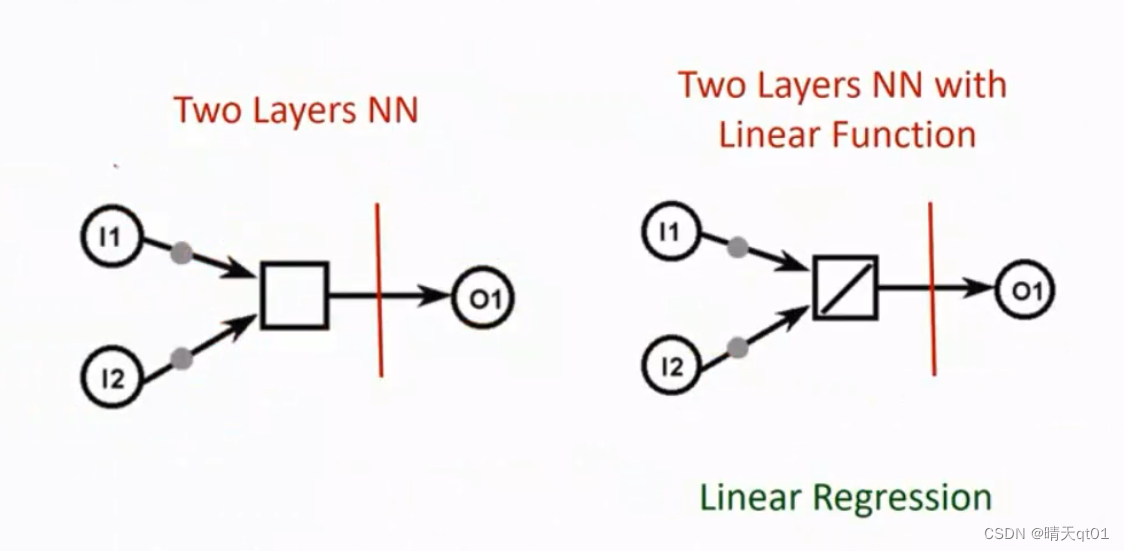
这边如果我们采用的是只有输入输出层,激活函数用的线性函数,这种两层式的BP模型,就会退化为线性回归模型。
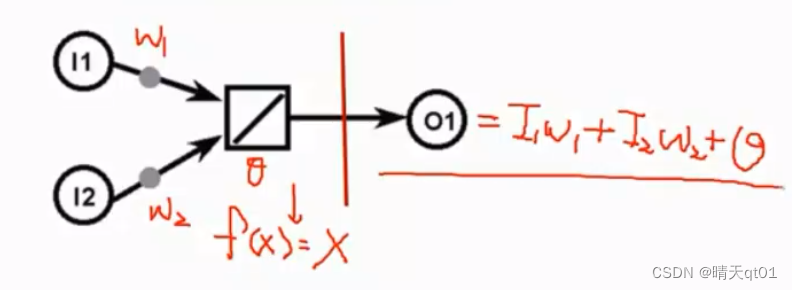
我们会发现得到的模型就是就是I1w1+I2w2+bias=O1
还是一样,我们只有输出层和输出层,其中激活函数用的是sigmoid function。那么你就会发现。这样两层的神经网络,就会退化为逻辑回归。基本是就是在做2分类的问题。左图也被我们称为二元逻辑回归。在统计里把sigmoid函数叫做逻辑函数。是同一个函数,一模一样。输出层改为多神经元,那就会变成多元逻辑回归。
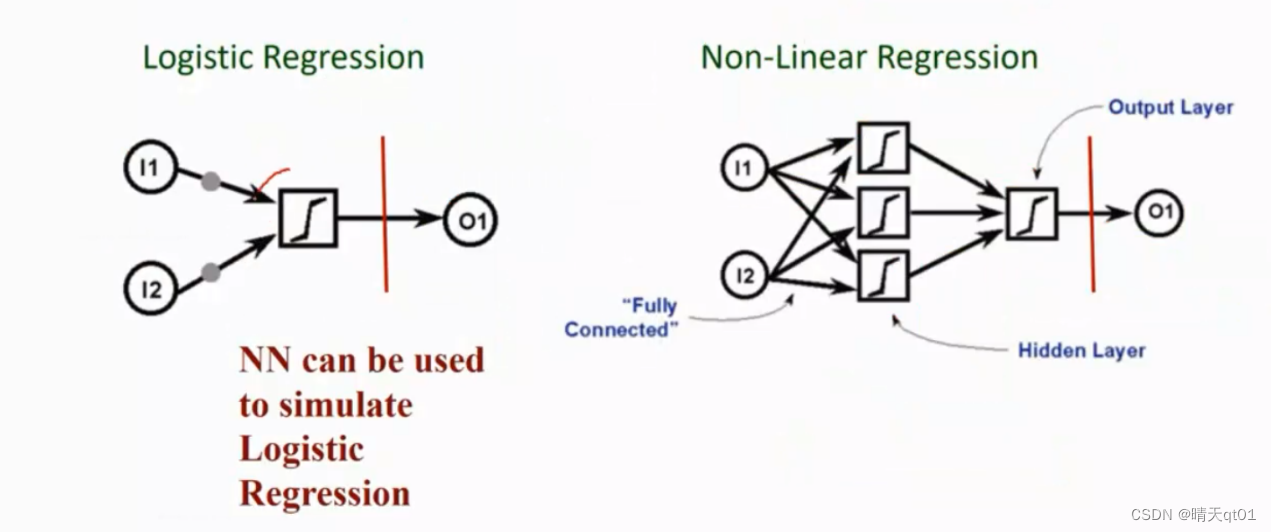
右图是增加了一个异常层的逻辑回归问题,那么能解决的就可以是非常复杂的非线性的逻辑回归模型。所以其实BP神经网络是一个集大成的神经网络,它可以同设定网络架构的方式来变为不同的模型。
BP神经网络的优缺点:
BP神经网络的优点:
1:预测的准确度很高
2:能很快的预测出结果(不用像决策树一样考虑要走左边还是右边,它直接一条路计算走到黑。)
缺点:
训练时间非常长,尤其是到深度学习的时候,它可能要训练好几天。
很难了解其中的权重值代表什么含义。(使用我们经常叫它黑箱子,因为没有可读性,但是输入的值有很准确。)
版权归原作者 晴天qt01 所有, 如有侵权,请联系我们删除。