
这段时间研究AI平台的能力。 今天我把库博检测工具发现的一个Java安全漏洞相关代码传到几款AI工具上进行分析,看看这几款工具反馈的结果。这些工具包括ChatGPT-3.5、Forefront Claude、AIChat(组合)和清华ChatGlm。
首先我们看看库博检测出的这个漏洞是否存在。先在代码。
protected* void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {*
**// TODO Auto-generated method stub***/**** **文件下载** **有目录遍历攻击漏洞的代码**/*request.setCharacterEncoding(**"UTF-8"**);*response.setContentType(**"text/html;charset=utf-8"**);*response.setCharacterEncoding(**"utf-8"**);*OutputStream out = null;***//**获取项目部署绝对路径下的**upload**文件夹路径**,**下载**upload**目录下面的文件*String root = request.getServletContext().getRealPath(**"/upload"**);***//**获取文件名*String filename = request.getParameter(**"filename"**);*File file = **new** File(root + **"/"** + filename);***//**根据文件路径创建输入流*FileInputStream fis = **new** FileInputStream(file);*out=response.getOutputStream();***//**设置响应头**,**弹出下载框*System.out.println(root + **"/"** + filename);***//response.setContentType("application/x-msdownload");***// response.addHeader("Content-Disposition", "attachment;filename=" + new String(filename.getBytes()));**String agent = request.getHeader(**"USER-AGENT"**).toLowerCase();*String name = **new** String(filename.getBytes(agent.indexOf(**"msie"**) != -**1** ? **"GBK"** : CharEncoding.UTF_8), CharEncoding.ISO_8859_1);*response.setContentType(**"application/octet-stream"**);*response.setHeader(**"Content-Length"**, **""** + file.length());*response.setHeader(**"Pragma"**, **"NO-cache"**);*response.setHeader(**"Cache-Control"**, **"No-cache"**);*response.setCharacterEncoding(**"UTF-8"**);*response.setContentType(**"text/html"**);*response.setDateHeader(**"Expires"**, -**1**);**response.setHeader(**"Content-disposition"**, **"attachment;filename="** + name);***//response.addHeader("Content-Length", "" + file.length());***//byte[] b = new byte[fis.available()];***byte**[] b = **new** **byte**[**1024**];***int** len=**0**;***while** ((len=fis.read(b))!=-**1**)*out.write(b,**0**,len);****if**(len==-**1**)*{*fis.close();*request.getSession().setAttribute(**"message2"**,**"**下载完成!**"**);*request.getRequestDispatcher(**"/filetraversal.jsp"**).forward(request, response);*}*** }*
库博检测是以安全漏洞维度展示的,所以点击某个漏洞类型,可以看到该安全漏洞对应的代码位置。当前这个版本没有以文件形式展示漏洞方式了(国内工具基本上都没有该功能,库博之前版本是有的)。
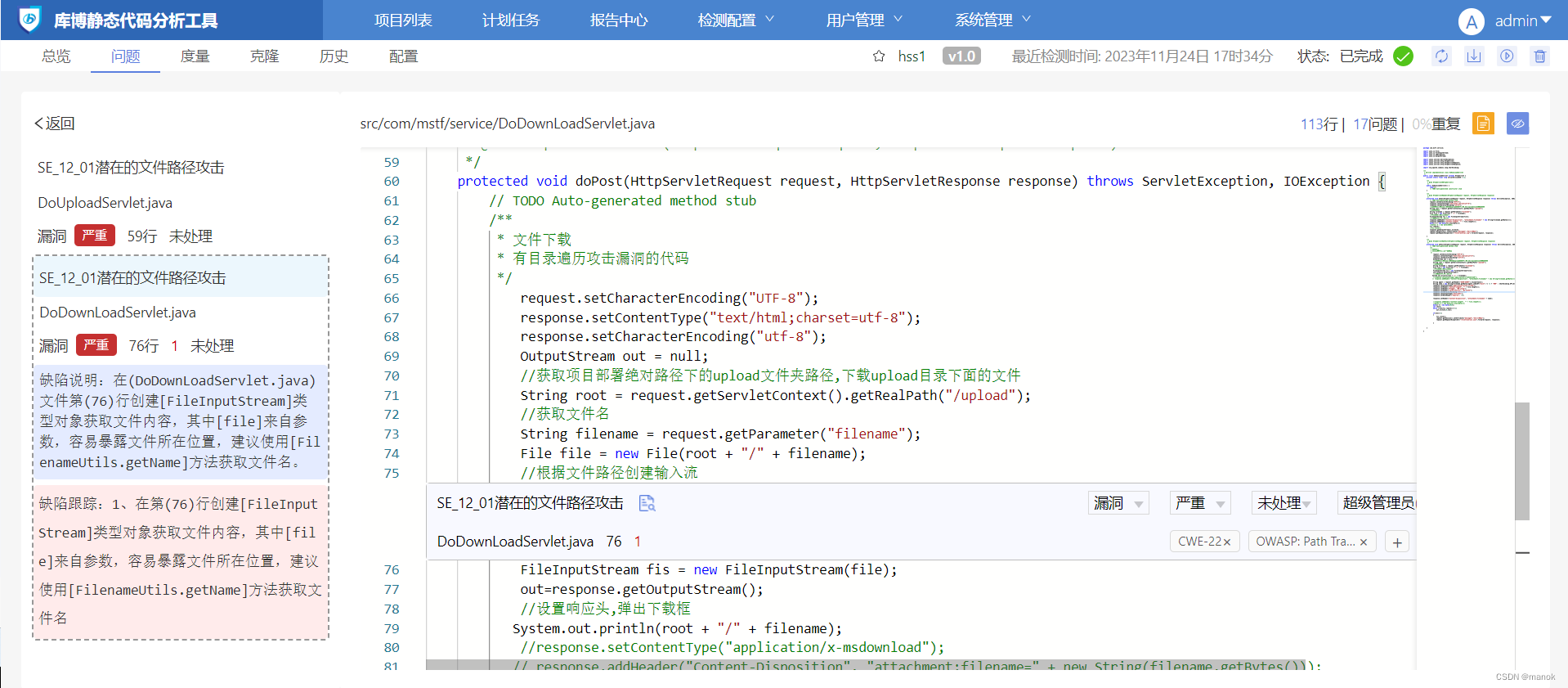
首先我们测试一下边界AICHAT,我们使用推荐模型组合,输入代码后,给出分析结果如下。
可以看到,AI引擎给找出来了多个缺陷,其中第一条就是我们最关注的路径遍历,能够给出来。第2条代码中不存在,但是3、5、6还的确是存在的问题。这样看,分析还是比较全面的。
使用国外AI工具Forefront Chat进行分析,该工具也是集成Chatgpt、Claude 1.2,该引擎是需要在互联网进行搜索,大概1分钟没有反馈出结果。
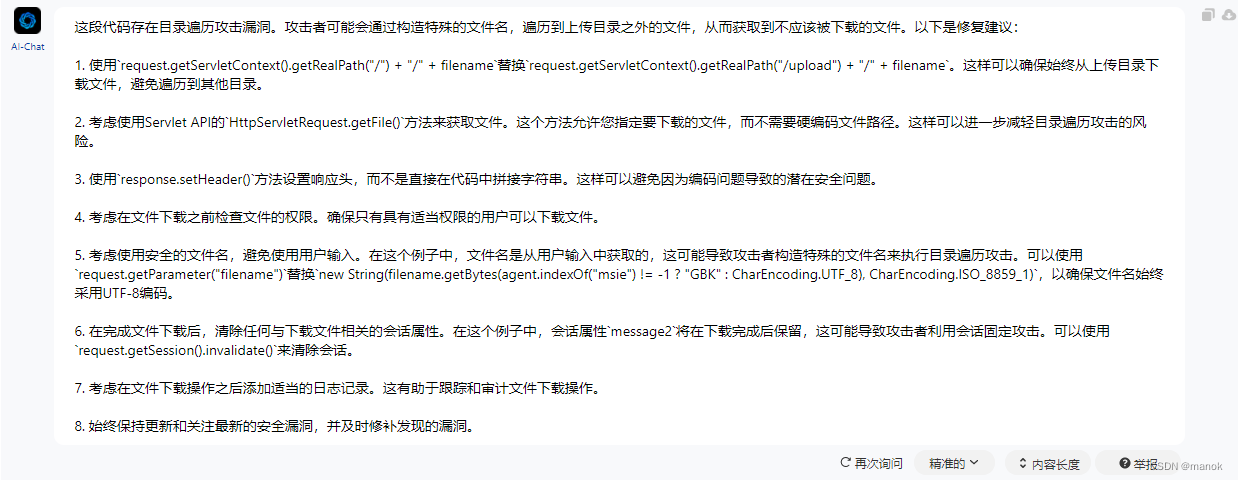
我们看Chatgpt官方网站上,使用Chatgpt-3.5引擎的分析结果。
分析上面的结果,可以看到发现了3个安全问题,第1个事路径遍历,第2个问题,国产AI工具也给出了类似结果。而第3个问题感觉是一个误报,因为在代码中进行流资源释放,但是是在一个分支进行了释放,应该算是一个误报。
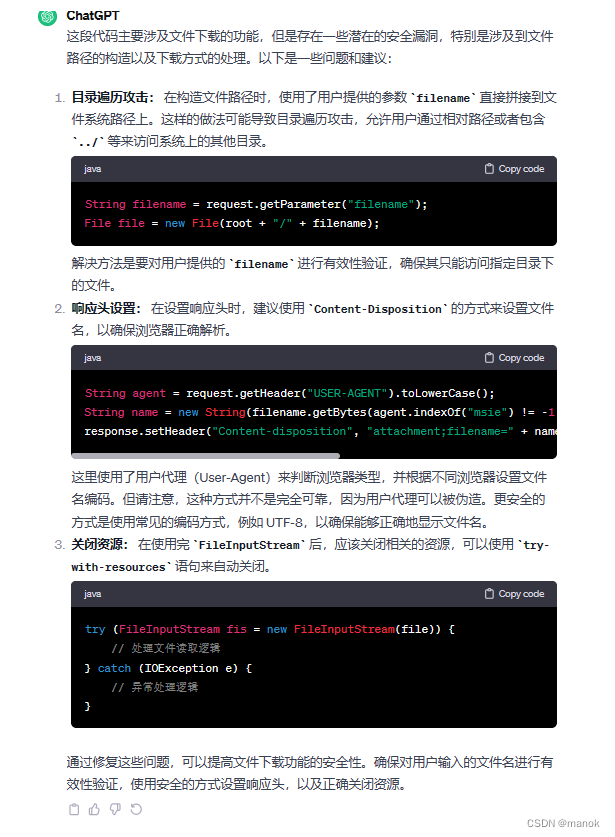
我们再看看在清华大学的ChatGlm平台上的分析结果。
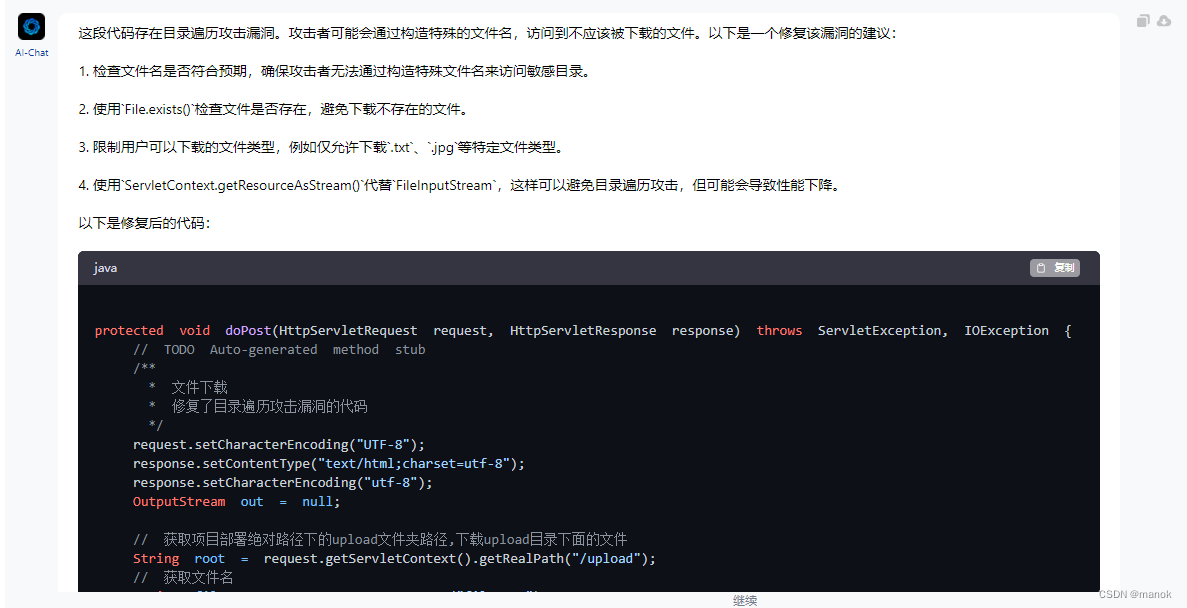
……………省略中间代码,见下面。
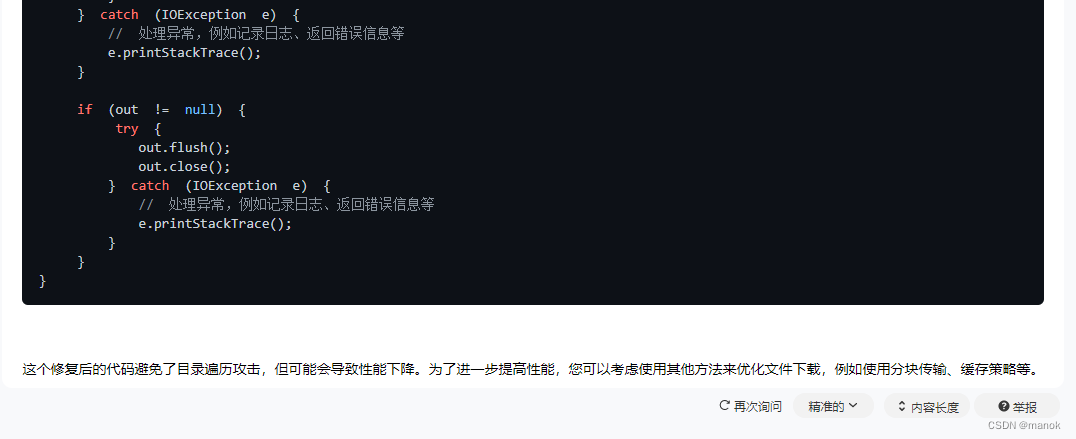
为了方便,我贴出所有返回的代码。
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub*/**** **文件下载** **修复了目录遍历攻击漏洞的代码**/*request.setCharacterEncoding("UTF-8");*response.setContentType("text/html;charset=utf-8");*response.setCharacterEncoding("utf-8");*OutputStream out = null;*// **获取项目部署绝对路径下的upload文件夹路径,下载upload目录下面的文件*String root = request.getServletContext().getRealPath("/upload");*// **获取文件名*String filename = request.getParameter("filename");*// **检查文件名是否符合预期*if (filename == null || filename.trim().isEmpty()) {*response.sendError(HttpServletResponse.SC_BAD_REQUEST, "Invalid file name");*return;*}*// **限制用户可以下载的文件类型*String allowedExtensions = "txt,jpg,png,gif";*String fileExtension = filename.substring(filename.lastIndexOf('.') + 1).toLowerCase();*if (!allowedExtensions.contains(fileExtension)) {*response.sendError(HttpServletResponse.SC_BAD_REQUEST, "Invalid file extension");*return;*}*File file = new File(root + "/" + filename);*// **使用ServletContext.getResourceAsStream()代替FileInputStream*try (InputStream is = request.getServletContext().getResourceAsStream("/upload/" + filename)) {*if (is == null) {*response.sendError(HttpServletResponse.SC_NOT_FOUND, "File not found");*return;*}*response.setContentType("application/octet-stream");*response.setHeader("Content-Length", String.valueOf(is.available()));*response.setHeader("Pragma", "NO-cache");*response.setHeader("Cache-Control", "No-cache");*response.setCharacterEncoding("UTF-8");*response.setContentType("text/html");*response.setDateHeader("Expires", -1);*response.setHeader("Content-disposition", "attachment;filename=" + filename);*byte[] buffer = new byte[1024];*int bytesRead;*while ((bytesRead = is.read(buffer)) != -1) {*out.write(buffer, 0, bytesRead);*}*} catch (IOException e) {*// **处理异常,例如记录日志、返回错误信息等*e.printStackTrace();*}*if (out != null) {*try {*out.flush();*out.close();*} catch (IOException e) {*// **处理异常,例如记录日志、返回错误信息等*e.printStackTrace();*}*}*
}
突然感觉清华大学的这个AI引擎功能强大,不但给出了4个问题,最亮眼的给出的修复后的代码,这段代码我还没有时间去替换原来代码去编译看看是否存在问题,但是这个功能足于领先了。为了验证引擎,我把返回的代码又贴了回去,让引擎分析分析是否存在漏洞。其反馈结果如下:

在其提供的修复代码的基础上又检测出的问题,其提供的修复代码中,增加了对于文件类型的限制。
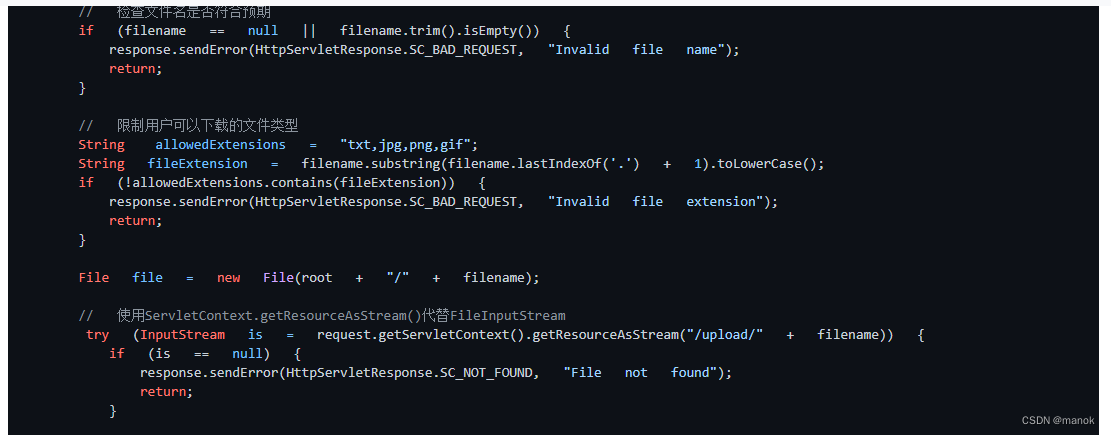
通过这个例子说明,国内AI引擎有自己创新之处,但是在一些细节上还是存在瑕疵,需在在引擎或训练数据上做的更精细。
(结束)
版权归原作者 manok 所有, 如有侵权,请联系我们删除。