
plt.hist()具体作用:
如图所示,左栏是数字value。右栏是频数frequency。现在我将0~5这个区间划分为10个bin(箱子),每个箱子的大小都为0.5。如下图最右侧所示。
可以看到,图中的数字所对应的频数会按照Bins的所标识的数字的不同进行相加。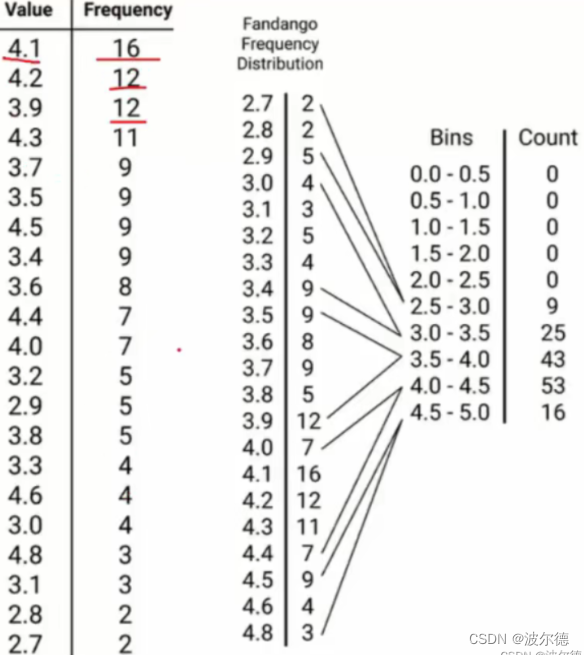
plt.hist()也就是这个作用。将一个大区间划分为等间隔的小区间,并统计每个区间上样本出现的频数之和。
例1
reviews = pd.read_csv('fandango_scores.csv')
cols =['FILM','RT_user_norm','Metacritic_user_nom','IMDB_norm','Fandango_Ratingvalue']
norm_reviews = reviews[cols]
fig, ax = plt.subplots()
ax.hist(norm_reviews['Fandango_Ratingvalue'])
plt.show()
显示结果: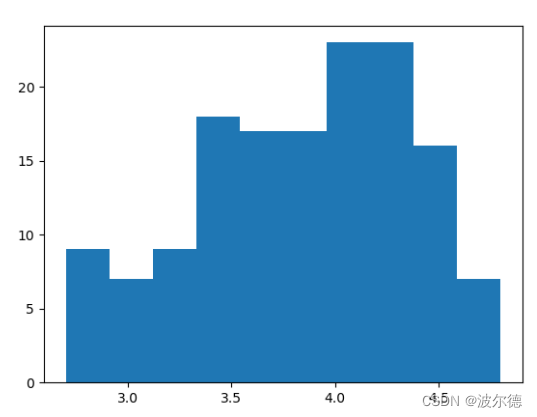
指定参数:bins=20(划分箱子的大小为20),his的type是’step’
reviews = pd.read_csv('fandango_scores.csv')
cols =['FILM','RT_user_norm','Metacritic_user_nom','IMDB_norm','Fandango_Ratingvalue']
norm_reviews = reviews[cols]
fig, ax = plt.subplots()# hist()的作用是把数据按从小到大的值划分到不同的箱子里。
ax.hist(norm_reviews['Fandango_Ratingvalue'],bins=20,histtype='stepfilled')
plt.show()
运行结果为: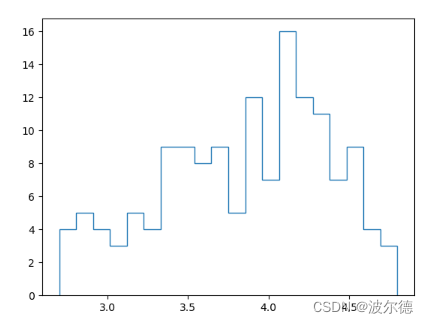
当指定x轴的范围后:
reviews = pd.read_csv('fandango_scores.csv')
cols =['FILM','RT_user_norm','Metacritic_user_nom','IMDB_norm','Fandango_Ratingvalue']
norm_reviews = reviews[cols]
fig, ax = plt.subplots()# hist()的作用是把数据按从小到大的值划分到不同的箱子里。
ax.hist(norm_reviews['Fandango_Ratingvalue'],range=(4,5),bins=20)
plt.show()
运行结果: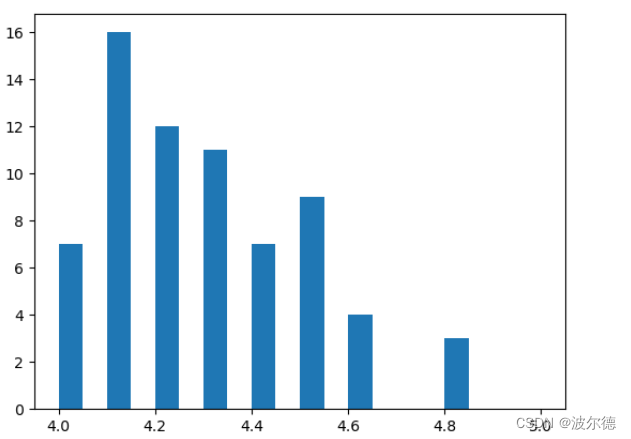
本文转载自: https://blog.csdn.net/weixin_44025103/article/details/125027183
版权归原作者 波尔德 所有, 如有侵权,请联系我们删除。
版权归原作者 波尔德 所有, 如有侵权,请联系我们删除。