
文章目录
数据可视化第二版-拓展-网约车分析案例
竞赛介绍
本文是和鲸社区的一个数据分析竞赛,比赛链接如下:【2023春节限定】网约车运营分析
这是数据科学开源社区和鲸社区的春节传统节目,也是和鲸社区与接地气的陈老师联合举办的【商业分析训练营】系列第一期,旨在用真实的分析场景,带同学们利用春节假期体验真实的数据分析工作,提升求职与数据分析工作能力。
接地气的陈老师是创业公司数据总监,公众号“接地气的陈老师”主理人,豆瓣评分 9.0 的《商业分析全攻略》一书作者,担任本活动出题人与评委。
假设你是某打车APP的商业数据分析师,为某大区提供日常数据报表。现在大区领导表示:希望你从日常数据监测中,发现问题和机会点,并做出建议。请你认真研究手头报表数据,给出报告。数据如下:
真实的商业分析就是这样:日常工作 80% 是重复的,枯燥的日报、周报、月报,这些监控报表和临时取数。可是,业务部门,领导们又希望你能从简单的监控中发现问题,做出洞察。那么
如何在日常数据里看出门道?
怎么在没有标准答案的情况下,自己找到标准?
怎么基于数据说出一二三,又能让人信服?这是对商业分析师的重大考验。
通过这个案例,可以让同学们体验到真实工作状态,从期初的迷茫,到逐步清晰,到顿悟,到能够驾驭数据,驱动业务,需要很多年历练。今天带大家迈出第一步。
数据介绍
数据为某大区内五个城市,1周分时段运营数据
字段:时段,代表一天时间,0代表0点~1点,以此类推
冒泡:打车APP中,乘客选择起点、终点,APP提示可选车型&价格,为一次“冒泡”
呼叫:乘客看到冒泡信息后,点击“呼叫”按钮,为一次呼叫
应答:司机看到乘客呼叫后,接单,为“应答”
完单:司机完成订单,乘客付款为“完单”
司机在线:每个时段内司机在线人次
为降低分析难度,假设如下:
订单在时段内完成,不考虑跨时间段场景
司机在线为时间段内所有司机,不考虑时间段内波动
冒泡→呼叫→应答→完单,可简单视为一个流程转化率
1等奖作品-IT从业者张某某的作品
参考:【2023 春节限定】网约车运营分析报告
结论
- 确定关键指标:
完单数和完单率 (因为城市不一样,完单数体现城市的盈利能力,完单率体现运营效果的可改进空间)
- 按城市维度分析:
AED 属于大城市大城市中 D 的 APP 运行效果最好,其次是 E,最后为 A,但 A 为该区最大城市。其中 A 的各个时间段完单率均较差,初步排除受交通关系,应该与 A 城市的整体运营或是竞争有关系,对于大城市 A,整体完单数较多,是重要的赢利点,A 市需要重点优化,存在较大机会。
BC 属于 中小城市 中小城市的完单率 均较好,C 城市的白天完单率最好,但夜晚 0-5 点完单率较差,C 城市 0-5 点司机的数量少,最少为 284 人,占白天峰值 30000 的 1% 左右,可以提升司机数量,增加 C 城市乘客用户好感度。3 点数据举例冒泡 1148 呼叫 452 应答 248 完单 212 从指标相关性分析:
完单数量与司机在线数量相关性最大,说明司机多,也就是说明城市大,完成的订单数量更多,这样可以 重点关注大城市,A 市司机最多,但整体完单数没有比 C 市多。可以参考 A 市的订单价格与 C 市的订单价格进行比较,看是否存在 A 市是因为城市大,导致更多的远途用户采取了地铁等方式。
完单率 与 司机接单数量和司乘比(司机单位小时完成订单数) 相关性最大,说明可以通过 提升司机主动接单,来提升完单率> 司机接单数量与司乘比(司机单位小时完成订单数)呈强正相关,说明 提升司机的主动接单积极性,可以提升司机的接单数量,提升呼叫到接单到完单的比率。
- 从单个指标上分析
从转化率角度来看,A 市转化率小,完成最后支付的人相对较少,也就是 A 市可以重点提升,CBD 的完单数均高于 A 和 E
从完单数看,A 和 E 的完单数最小,与城市规模,司机数量不匹配
从漏斗图上可以看出 A 城市的冒泡 - 呼叫 - 应答,流失人数最多,其中其它城市呼叫到应答大约存在 10-30w 的差,而 A 城市存在 70W 的差。
- 分析结论
- 持续维持 BC 城市的用户满意度度和 app 依赖性,比如在 C 城市,提升 0-5 点的司机数量和司机应答积极性,减少 C 城市的整体呼叫与应答流失人数。
- 改进 A 城市的转化率过低
从漏斗查看,是冒泡数 1134W 与呼叫数 470W 差别较多,可以改进车型选择或价格推荐。
运营方案优化可以包含路线,可以进一步优化路线,同时可以考虑提供优惠券,提升转化率。另外可以看出,A 城市的司机很多,但呼叫数没有明显偏多,说明用户的依赖性不强,要提升用户的依赖性。
在工作日的 18 点是呼叫的高峰期,但在线司机数量下降了约 4000 千,而同期的大城市 D 市在线司机数量呈现上升趋势,可以优化这个时间段的在线司机数量。
过程数据和思考
数据处理
数据介绍
数据为某大区内五个城市,1 周分时段运营数据
字段:时段,代表一天时间,0 代表 0 点~1 点,以此类推
冒泡:打车 APP 中,乘客选择起点、终点,APP 提示可选车型 & 价格,为一次 “冒泡”
呼叫:乘客看到冒泡信息后,点击 “呼叫” 按钮,为一次呼叫
应答:司机看到乘客呼叫后,接单,为 “应答”
完单:司机完成订单,乘客付款为 “完单”
司机在线:每个时段内司机在线人次
为降低分析难度,假设如下:
订单在时段内完成,不考虑跨时间段场景
司机在线为时间段内所有司机,不考虑时间段内波动
冒泡→呼叫→应答→完单,可简单视为一个流程转化率
去除脏数据:第九列、第十列的数据为空,所以删除这两列的数据:

数据探索
转化率:完单数 / 冒泡数,用户选择起点终点到完成订单的概率
司乘比:完单数 / 司机在线,完单数代表真正的乘客数量,司机在线数代表司机的数量,表示司机的单位时间接单数量,是很重要的司机收入依据**
司机接单:应答数 / 司机在线 ,表示司机的接单意愿,
工作日: 1 表示周一到周五的工作日,0 表示周六和周日
为原始数据添加转化率、司乘比、工作日三列数据,为后续数据分析做准备
数据分析方法选择
对比分析:对比各城市之间司机数量、订单数量、高峰期情况等,分析城市的好坏并给出解决方案
趋势分析:通过观察事物的发展趋势,可以推理出产生此现象的原因、给出解决方案
数据分析
相关性分析
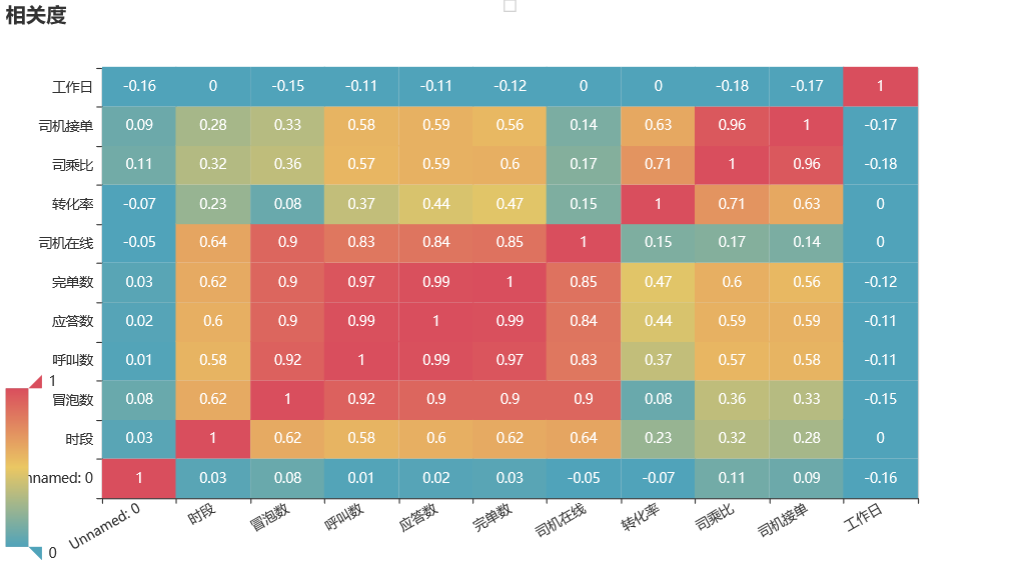
使用 corr 函数计算各指标之间的相关度,绘制热力图进行展示:
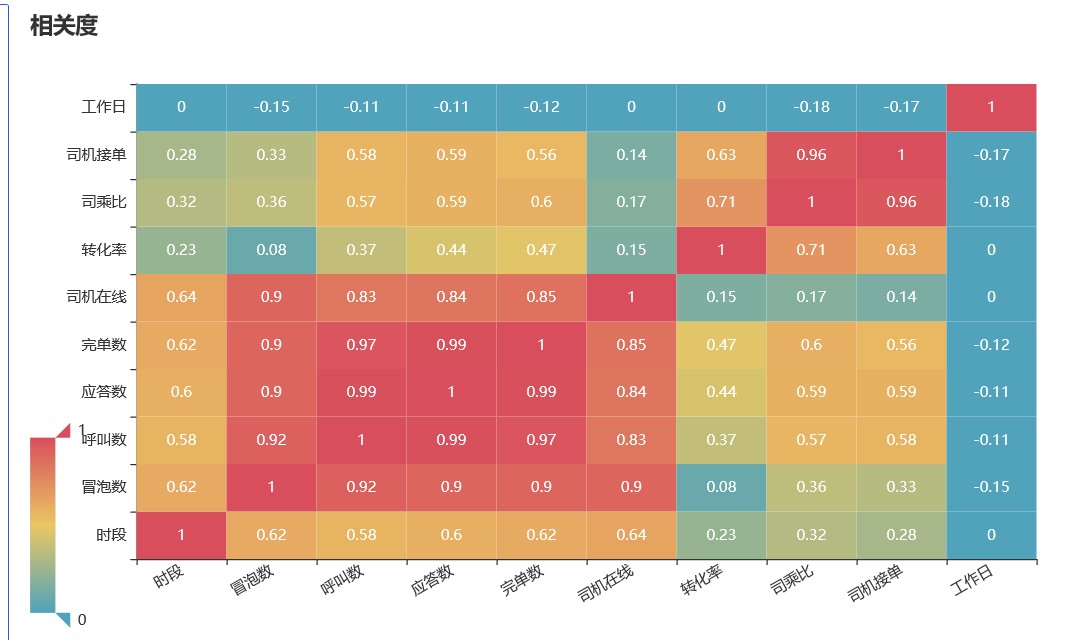
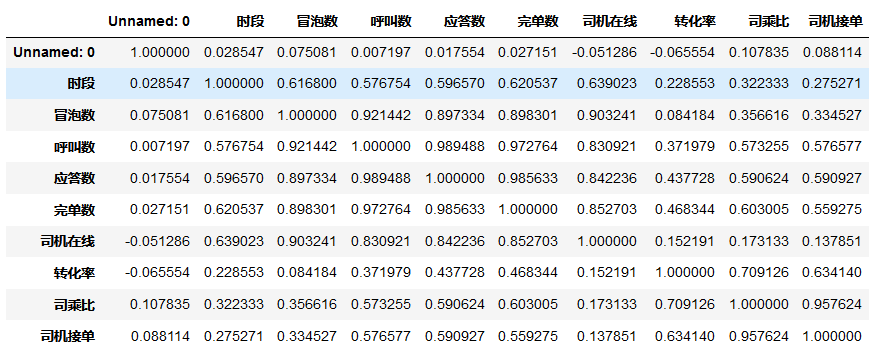
由上图可知:
从冒泡数、呼叫数到应答数,与完单数的相关度依次升高,此外,完单数与司机在线数有强烈的关系,与时段也有明显关系
司机在线数与时段具有明显关系,可见,在某些时段,司机在线数较多,某些时段较少
冒泡数、呼叫数、应答数与完单数与时段有明显的正相关,可见,在某些时段的订单多,而某些时段里订单少
转化率与司乘比呈较强的正相关,可见,司机数量与订单完成率有较强的关系
工作日与司乘比呈较弱正相关
司乘比与司机接单正相关,说明司机实际每天应答数量与司机每天完单高度相关。如果想提升完单率,可以尽可能的提升司机的应答数量。
目的是为了这个 app 提升收益:
北极星指标就是完单数量,完单数量意味着盈利 ,
如何提升完单数量,
对于 ADE 城市来说,可以尝试多提升呼叫数和应答数
优化路线,提供优惠券增加呼叫数,
提供接单任务奖励提高应答数,
对司机进行培训提升完单数
对于 BC 城市来说,暂时来说,继续保持的,同时考虑 中午的接单数
完单率是可以优化的空间
转化率分析
各城市从冒泡到完成订单的概率如下图所示:
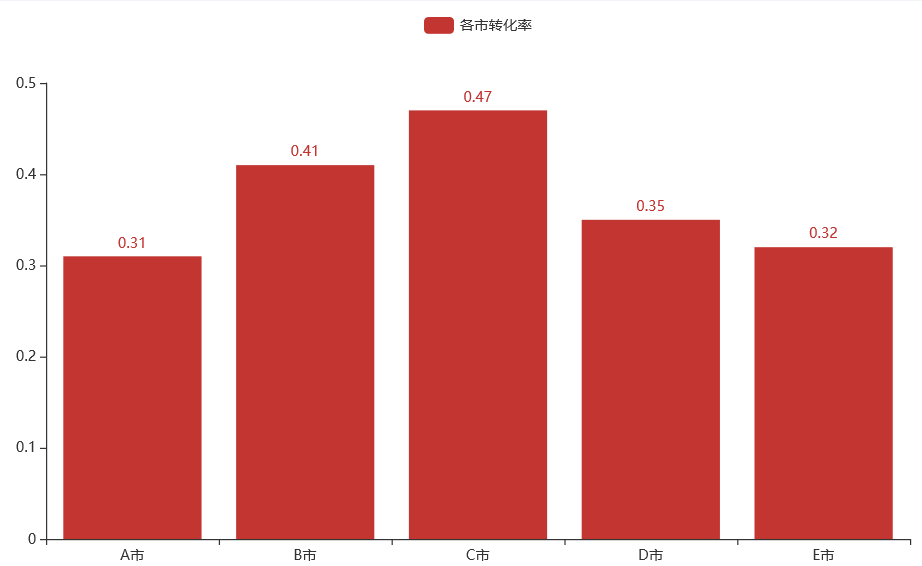
可见,C 市的转化率最高,而 A 市的转化率最低,可以重点研究 A 市:
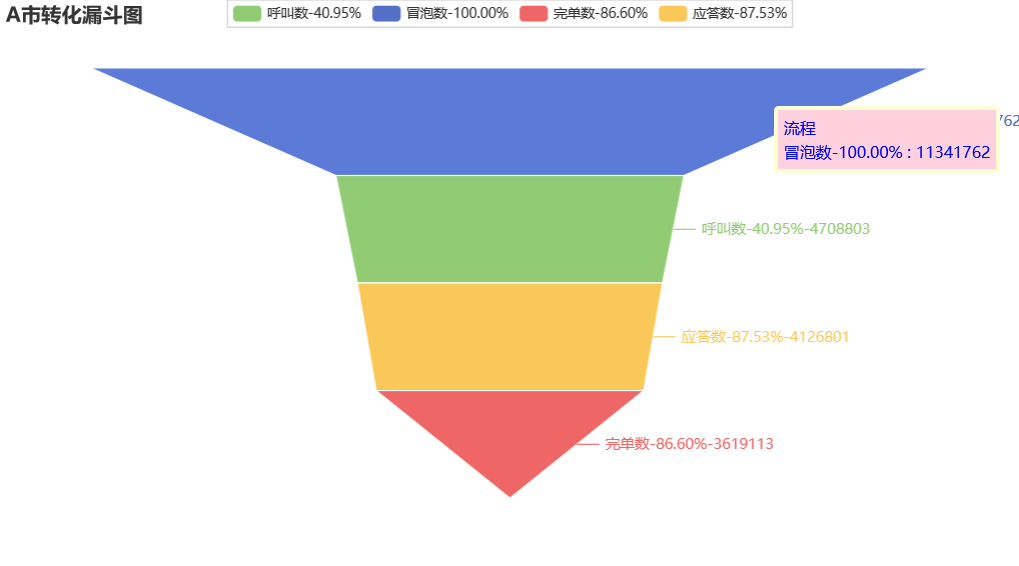
绘制 A C 市订单流程的漏斗图:
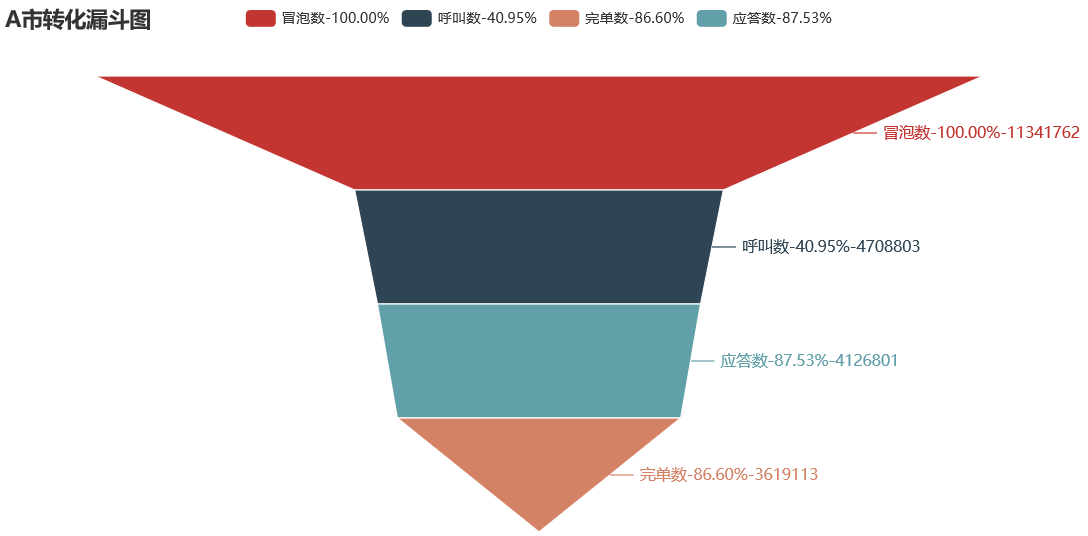
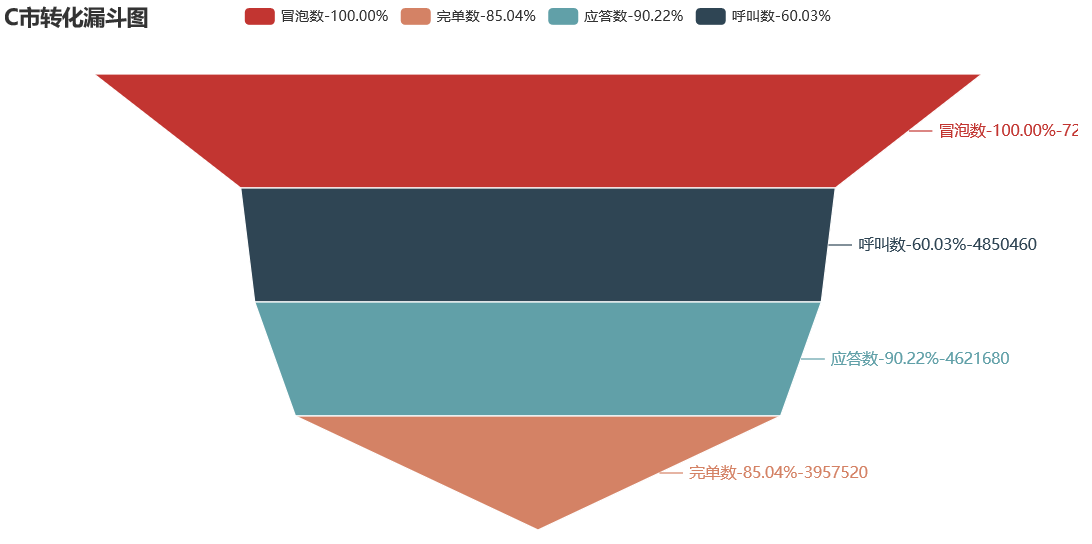
可见 A 市在冒泡到呼叫之间客户的流失量最大,从呼叫数到应答数之间的流失量也很大
分析结论
应该重点考虑 A 市的运营问题,可以增加在冒泡到呼叫步骤之间留存用户的措施,比如发放优惠券、优化最短路线,推荐合适车型和价格,对推荐的车型和价格进行 AB 测试等。 也要关注为什么下了订单却无法完成结账的问题,可以考虑司机绕路、司机无法在规定时间内到达起始地点等原因,需要根据更多的数据指标进一步探索
完单数量分析
分析结论
订单数量与司机在线数量相关性最大,说明司机多,也就是说明城市大,完成的订单数量更多,这样可以重点关注大城市,A 市司机最多,但 A 市在高峰期的在线司机数量存在下滑,可能存在一个司机采用多个网约车平台有关,提升司机的平台依赖性。对比工作日的 D 市,D 市晚间完单数较多,A 市白天的完单数较多。
司机数量分析
绘制多重折线图,各城市每日的司乘比如下图所示:
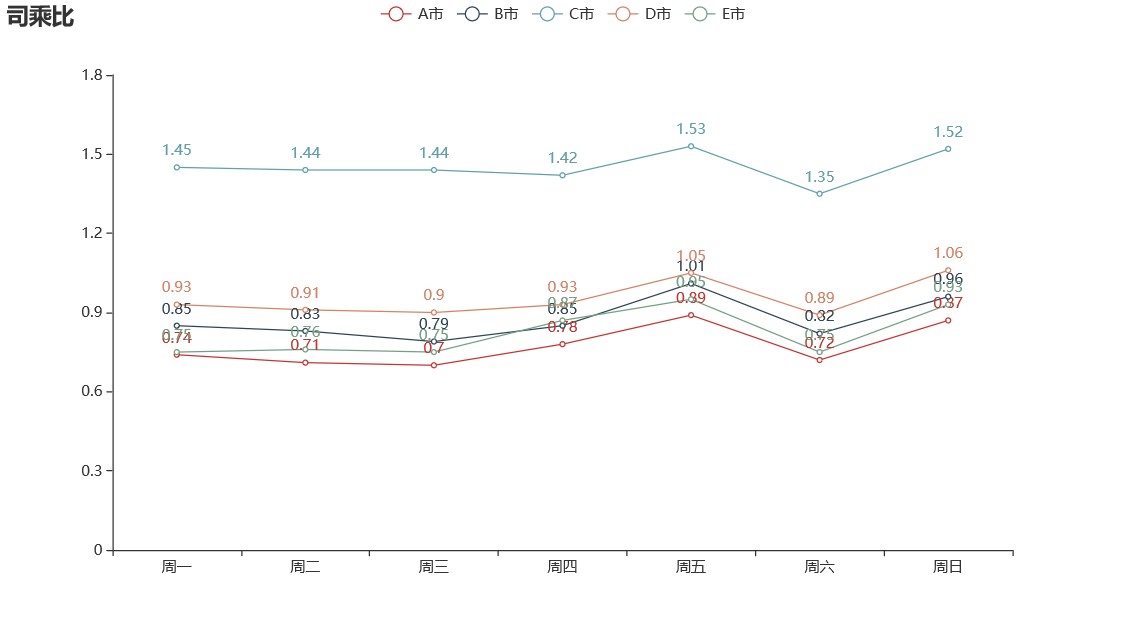
由上图可知:
C 市的司机是订单较多的,司机的主动性会更好,粘性更大,其余城市,均有提升空间
绘制各城市的订单流程数量折线图: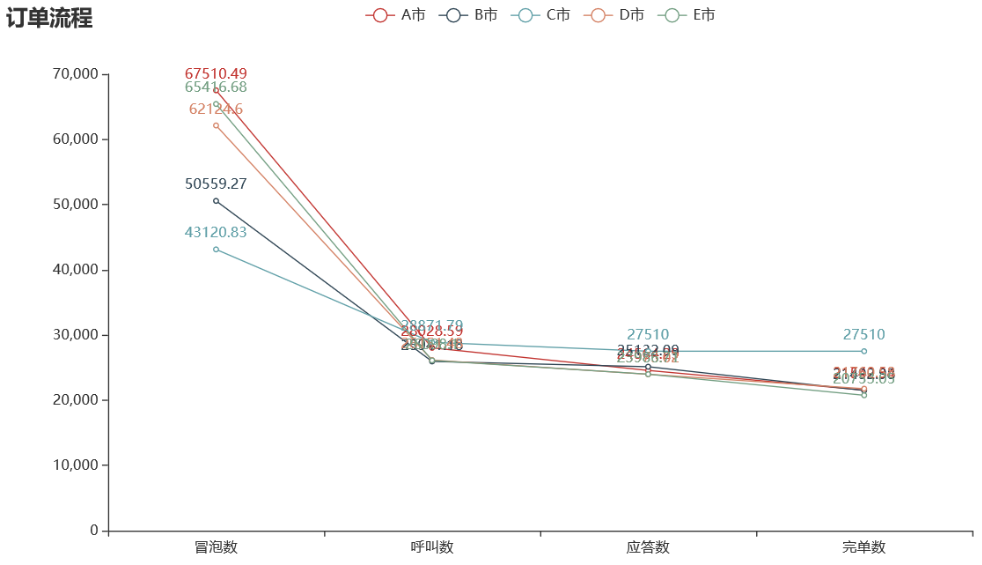
分析结论
C 城市虽然冒泡数最少,但是呼叫数、应答数直到完单数都是最多的
从周一到周日,C 市的订单数是最多的,但是在线的司机数却是最少的。A 市虽然冒泡最多,但是最终完成订单的数量较少,所以 A 市 是最需要关注的城市。其次是 E,再次是 D。 冒泡多 但完单少,可能是运营问题,也可能是竞争问题,也可能是交通问题。
时间分析
每日订单分析
绘制各市每日的完单数量折线图: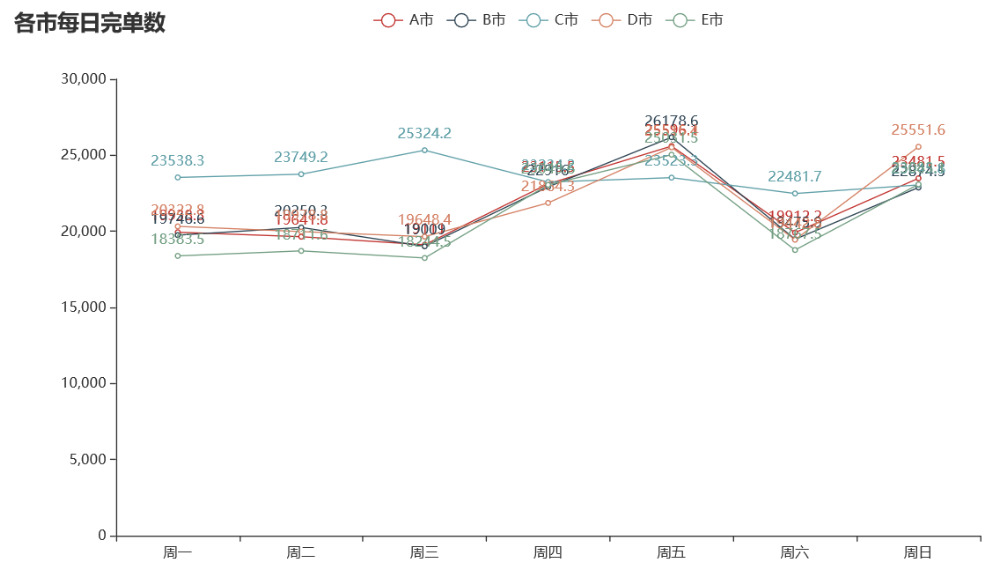
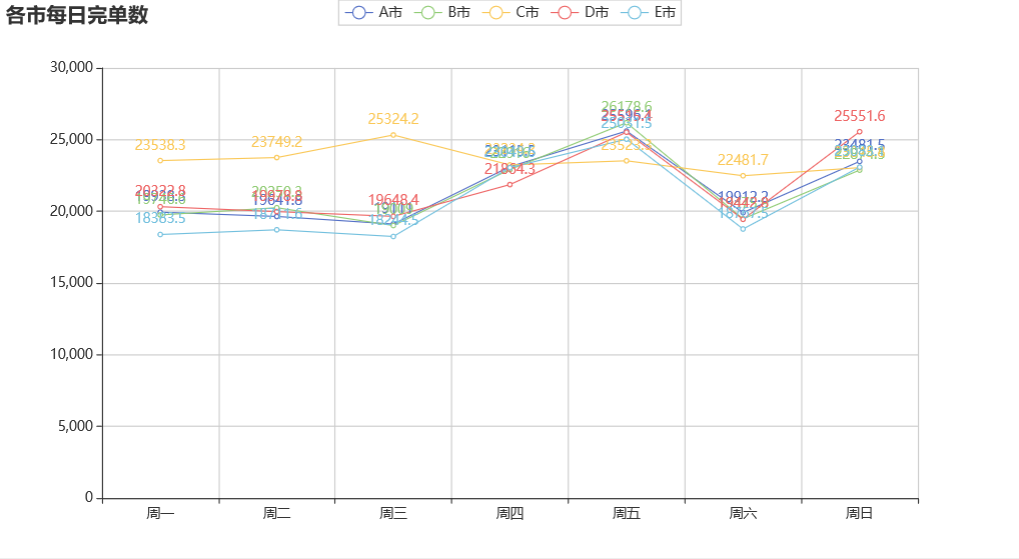
分析结论
C 城市虽然冒泡数最少,但是呼叫数、应答数直到完单数都是最多的
从上图可以看出,从周一到周四,C 市的完单数均高于其他城市,但是在周五,其他城市的完单数均高于 C 市
工作日各时段分析
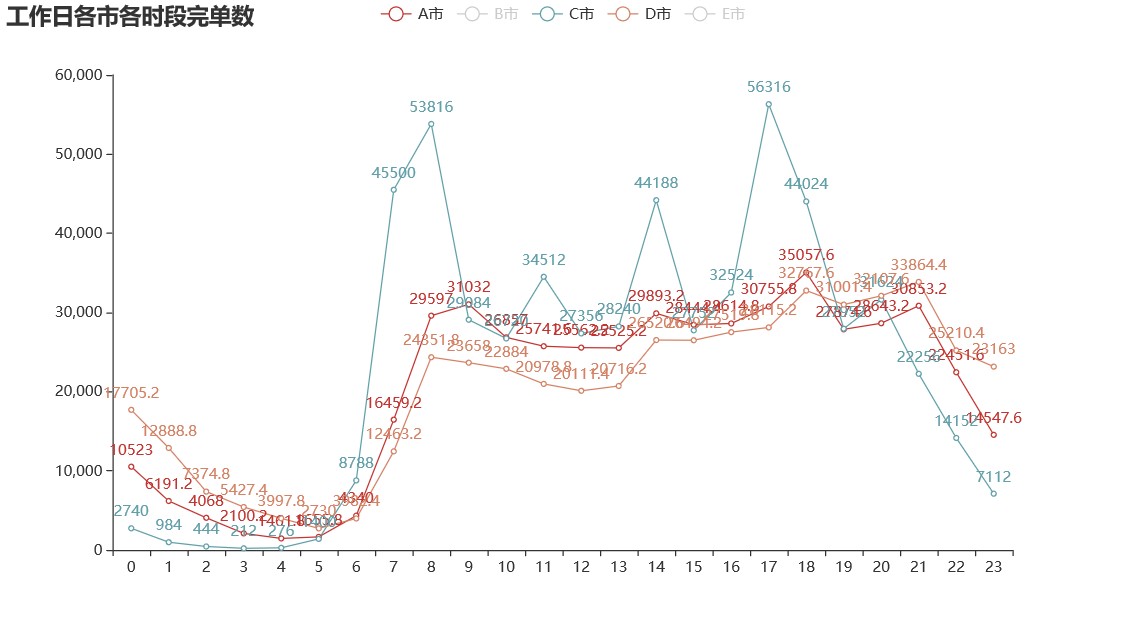
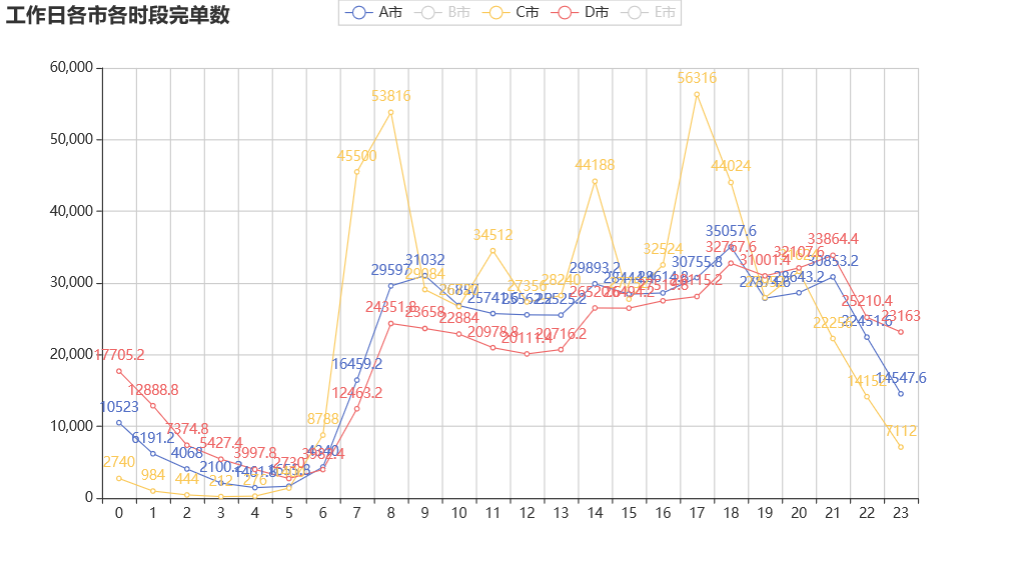
绘制工作日各城市各时段完单数的折线图: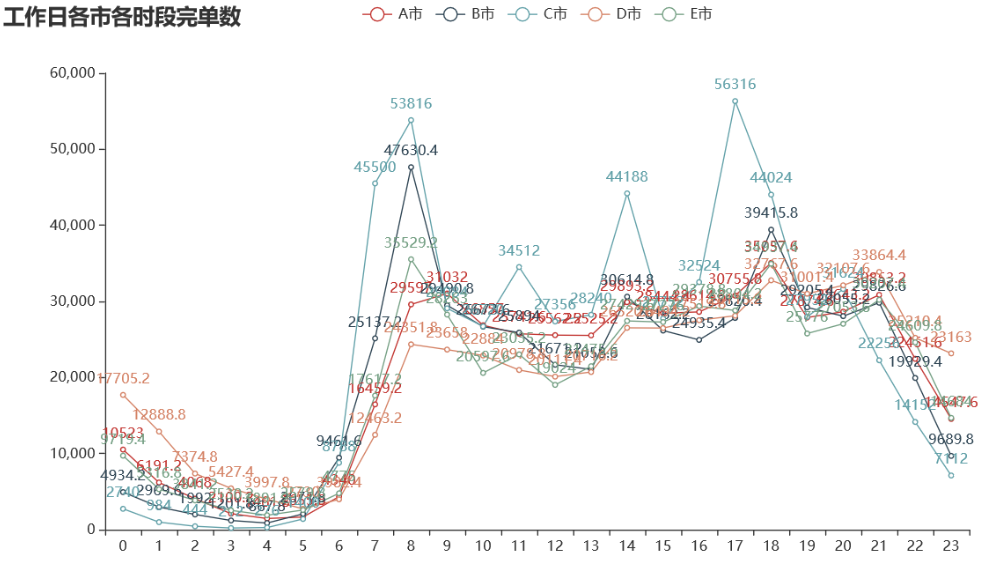
网约车的高峰期在 7 到 9 点、17 到 19 点,属于上下班和上下学的时间点。 中间 11 和 14 时间段有一个较大的波动,尤其是 C 市,原因是中午去吃饭和吃完饭对打车的需求比较大。
绘制周六日各城市各时段完单数的折线图
绘制工作日各城市各时段司机在线数的在折线图:
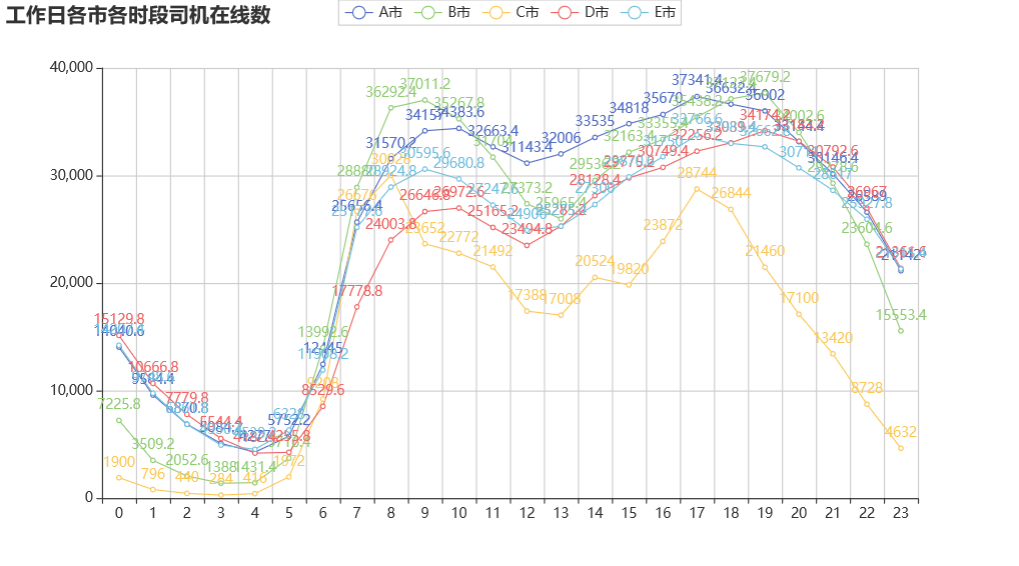
由上图可知,工作日司机的数量在 19 时达到最高峰,而此时的完单数已经降低,所以应该提早增加司机的数量。
周六日各时段分析
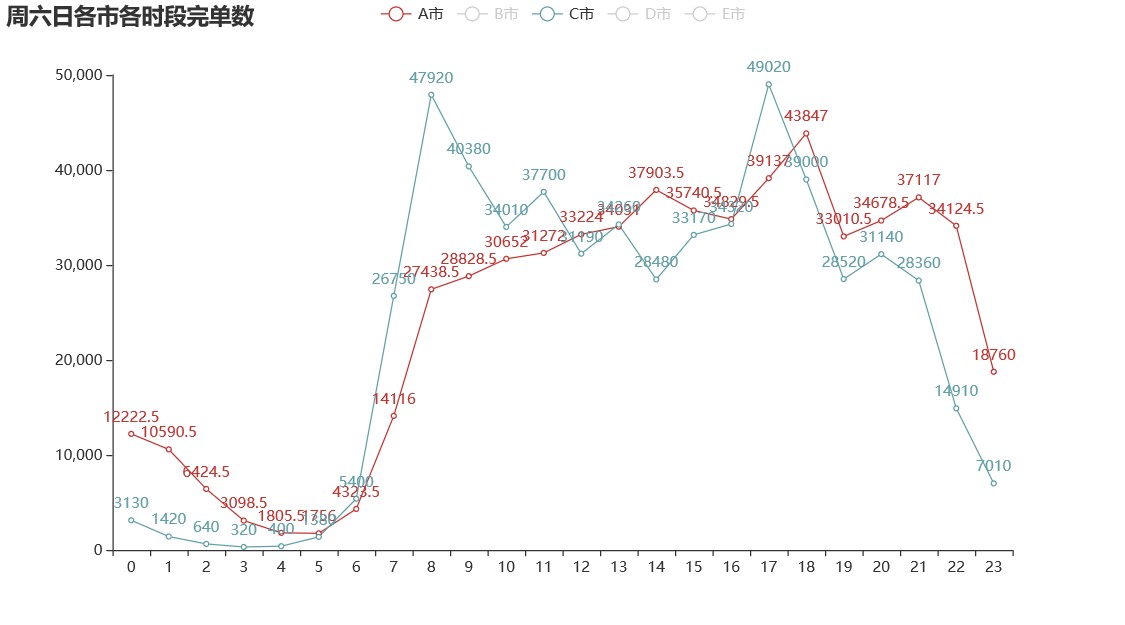
绘制周六日各城市各时段完单数的折线图: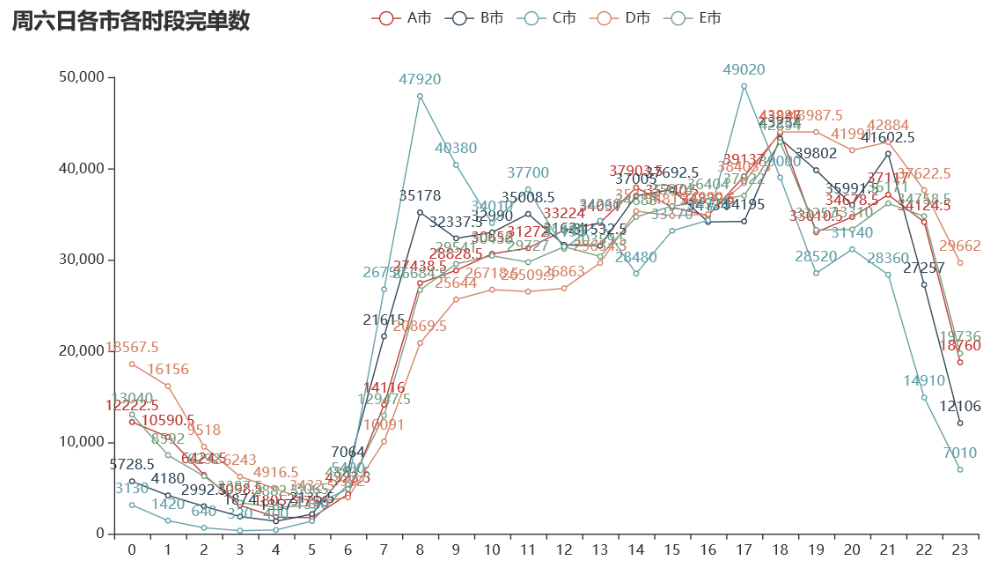
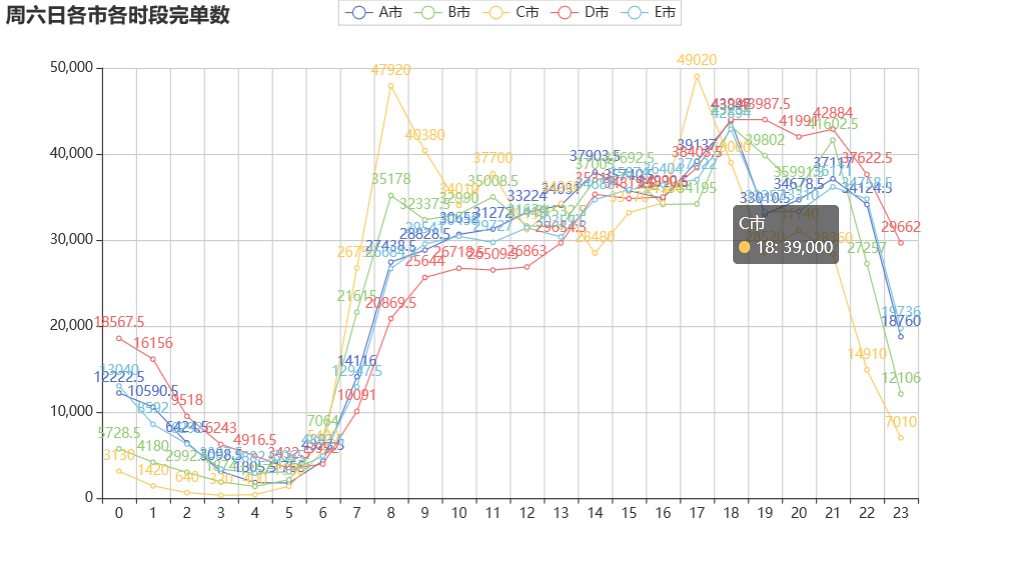
周六日网约车的高峰期在 7 到 10、16 到 20 时。期间,部分是由加班造成,也符合周末人们出行游玩的时间点。 不同于工作日的是,在 16 到 17 之间,完单数呈持续上升趋势,原因是周末人们出行时间更自由,在这些时间段里,外出和回家的人更多,导致网约车订单数量增多。* 周末没有固定回家的时间,因此周六日晚上的高峰期要更晚一些,一直持续到 20 至 21 时。
绘制周六日各城市各时段司机在线数的折线图: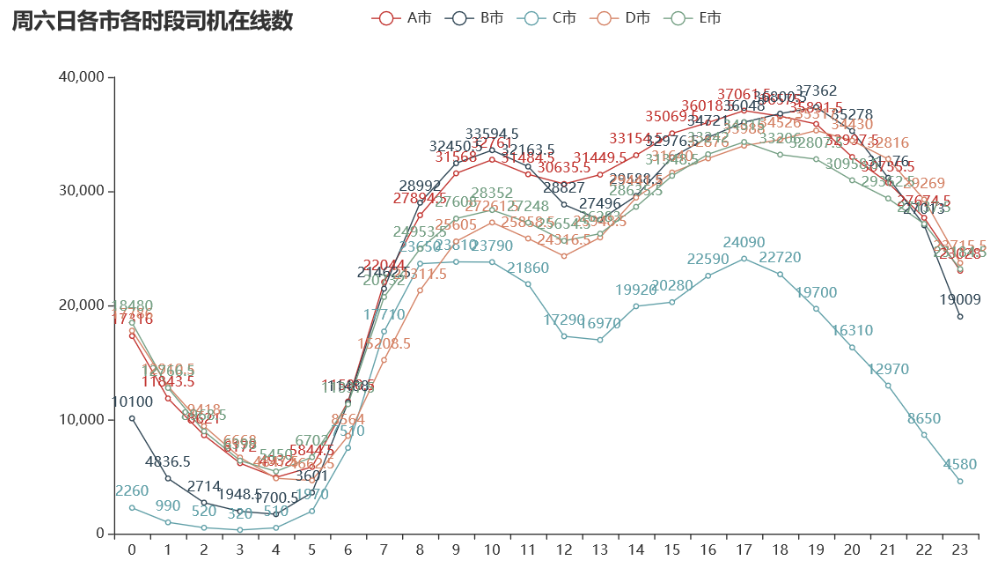
由上图可知,周六日司机在线数在 18、19 时达到最高峰,而此时的完单数已呈降趋势,所以应该提早增加司机数量 。
分析结论
应该根据工作日和周末的高峰时间不同需求,增加高峰期的司机数量,采取时段奖励等多种运营手段。
代码
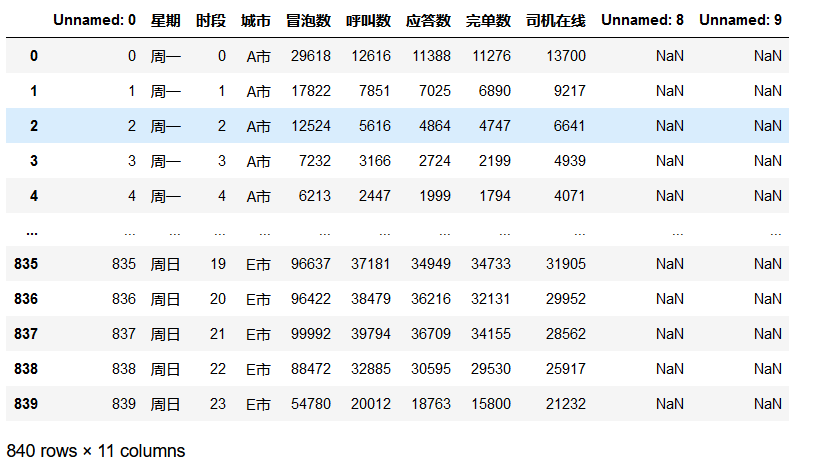
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Bar, Line, HeatMap, Funnel
rawdata = pd.read_csv('/home/mw/input/car_hailing9900/ride-hailing_data.csv',
encoding='gb2312')# rawdata.drop(['Unnamed: 8','Unnamed: 9'],axis=1,inplace=True)
rawdata.head()
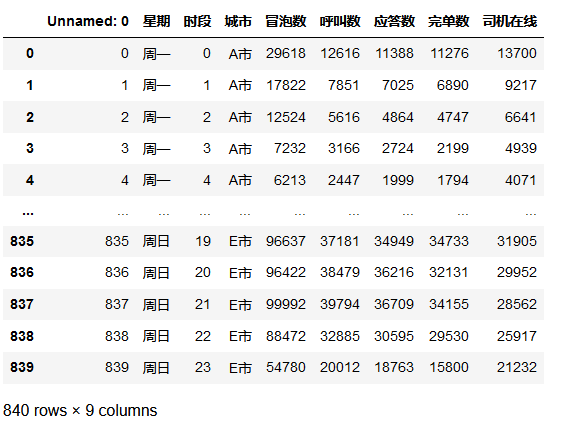
rawdata.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 840 entries, 0 to 839
Data columns (total 8 columns):
星期 840 non-null object
时段 840 non-null int64
城市 840 non-null object
冒泡数 840 non-null int64
呼叫数 840 non-null int64
应答数 840 non-null int64
完单数 840 non-null int64
司机在线 840 non-null int64
dtypes: int64(6), object(2)
memory usage: 52.6+ KB
# 最大显示行数
pd.set_option('display.max_rows',10)
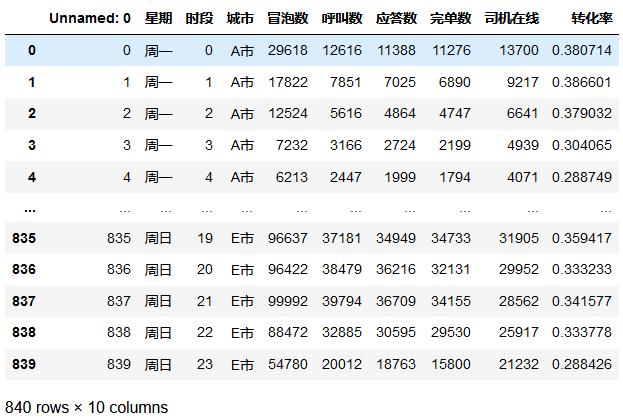
# 转化率
change_rate = rawdata['完单数']/ rawdata['冒泡数']
data = pd.concat([rawdata, change_rate], axis=1).rename(columns={0:'转化率'})
data
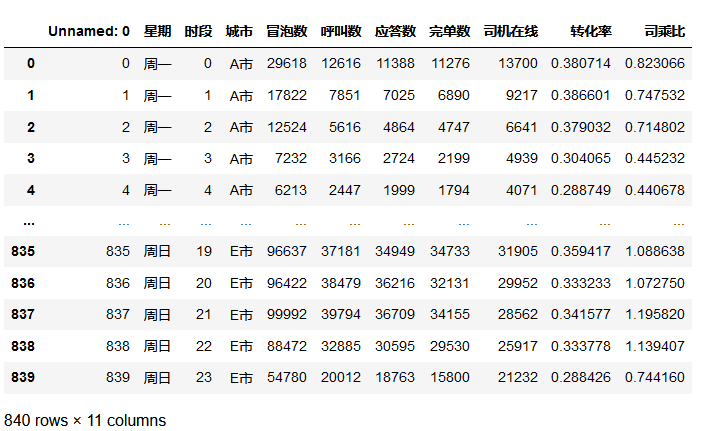
# 司乘比 在线的司机数 每天的平均接单数量
rate =(data['完单数']/data['司机在线'])
data = pd.concat([data, rate], axis=1).rename(columns={0:'司乘比'})
data
# 司机接单意愿
rate =(data['应答数']/ data['司机在线'])
data = pd.concat([data, rate], axis=1).rename(columns={0:'司机接单'})
data
# 相关性计算
cor = data.corr()
cor
# 生成工作日特征
data['工作日']=data.apply(lambda x:1if((x.星期=='周一')|(x.星期=='周二')|(x.星期=='周三')|(x.星期=='周四')|(x.星期=='周五'))else0,axis=1)
data
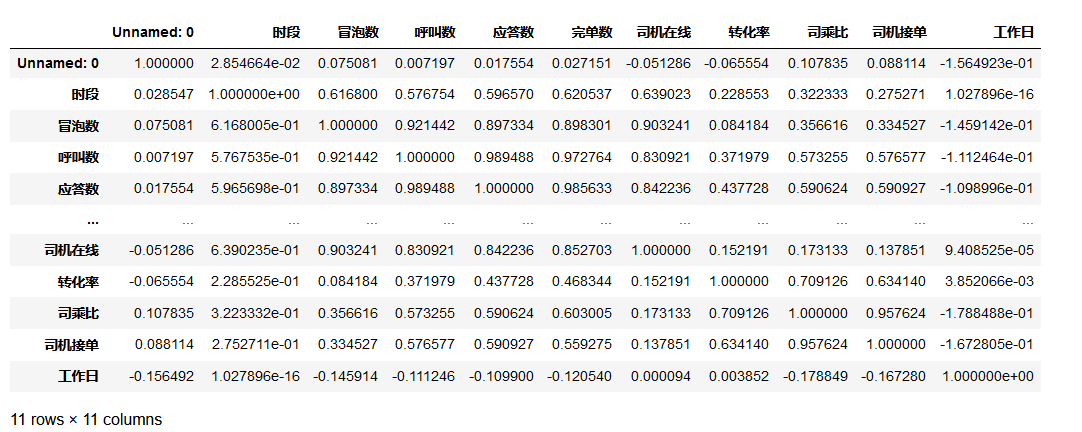
# 相关性可视化
cor = data.corr()
cor
# 相关性可视化
cor = data.corr()
value =[[x, y,round(cor.values[x][y],2)]for x inrange(11)for y inrange(11)]
heatmap = HeatMap(init_opts=opts.InitOpts())
heatmap.add_xaxis(list(cor))
heatmap.add_yaxis("",list(cor),
value,
label_opts=opts.LabelOpts(
is_show=True,
position="inside"))
heatmap.set_global_opts(
title_opts=opts.TitleOpts(title="相关度"),
visualmap_opts=opts.VisualMapOpts(max_=1),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)))
heatmap.render_notebook()
从冒泡数、呼叫数到应答数,与完单数的相关度依次升高,此外,完单数与司机在线数有强烈的关系,与时段也有明显关系
司机在线数与时段具有明显关系,可见,在某些时段,司机在线数较多,某些时段较少
冒泡数、呼叫数、应答数与完单数与时段有明显的正相关,可见,在某些时段的订单多,而某些时段里订单少
转化率与司乘比呈较强的正相关,可见,司机数量与订单完成率有较强的关系
工作日与司乘比呈较弱正相关
司乘比与司机接单正相关,说明司机实际每天应答数量与司机每天完单高度相关。如果想提升完单率,可以尽可能的提升司机的应答数量。
目的是为了这个 app 提升收益
北极星指标就是完单数量,完单数量意味着盈利 ,
如何提升完单数量,
对于 ADE 城市来说,可以尝试多提升呼叫数和应答数
优化路线,提供优惠券增加呼叫数,
提供接单任务奖励提高应答数,
对司机进行培训提升完单数
对于 BC 城市来说,暂时来说,继续保持的,同时考虑 中午的接单数
完单率是可以优化的空间
# 各市转化率
x_data = data["城市"].drop_duplicates().to_list()
y_data = data.groupby('城市')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
bar = Bar()
bar.add_xaxis(x_data)
bar.add_yaxis("各市转化率", y_data)
bar.render_notebook()
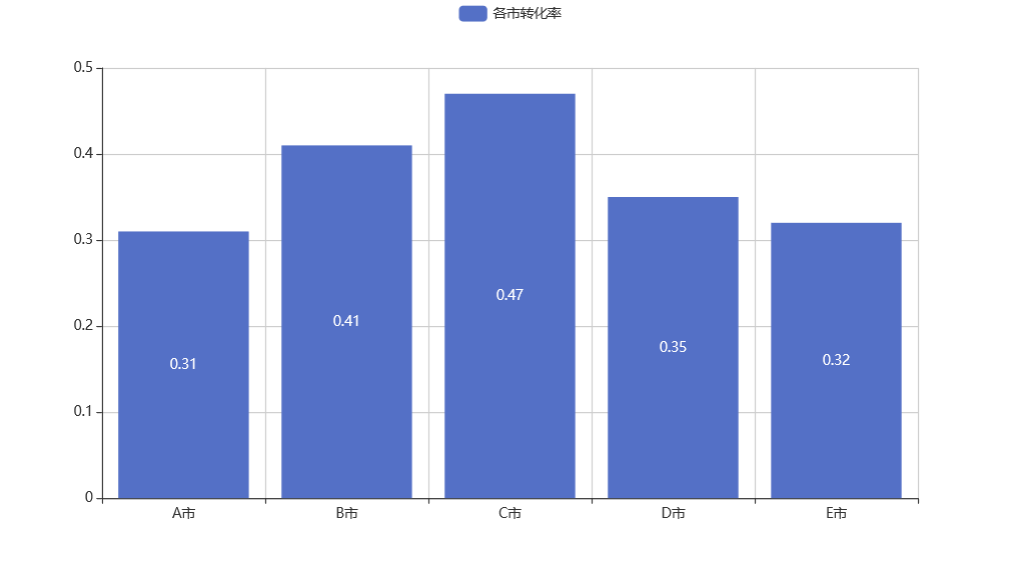 BC 城市转化率较好
BC 城市转化率较好
ADE 城市转化率有提升空间
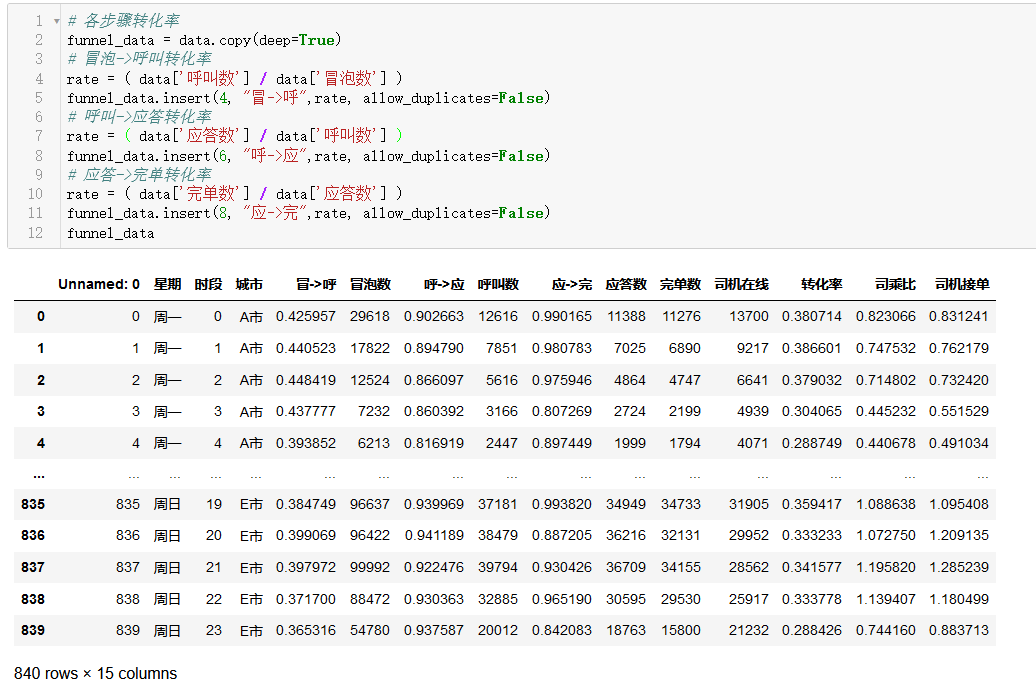
# 各步骤转化率
funnel_data = data.copy(deep=True)# 冒泡->呼叫转化率
rate =( data['呼叫数']/ data['冒泡数'])
funnel_data.insert(4,"冒->呼",rate, allow_duplicates=False)# 呼叫->应答转化率
rate =( data['应答数']/ data['呼叫数'])
funnel_data.insert(6,"呼->应",rate, allow_duplicates=False)# 应答->完单转化率
rate =( data['完单数']/ data['应答数'])
funnel_data.insert(8,"应->完",rate, allow_duplicates=False)
funnel_data
# A市漏斗转换图函数deffunnel_show(funnel_data, city_name):
change_df = data[data['城市']== city_name][['冒泡数','呼叫数','应答数','完单数']].sum()
change_data =[list(z)for z inzip(
change_df.index.tolist(),
change_df.values.tolist())]
change_rate = funnel_data[funnel_data['城市']==
city_name][['冒->呼','呼->应','应->完']].mean()
funnel_value = change_rate.values.tolist()
funnel_value.insert(0,1)
attr_trans =[
change_df.index.tolist()[i]+"-"+"%.2f%%"%(funnel_value[i]*100)for i inrange(4)]
funnel =(
Funnel().add("流程",[list(z)for z inzip(attr_trans, change_df)],
label_opts=opts.LabelOpts(
font_size=13, position="right", formatter="{b}-{c}"),
tooltip_opts=opts.TooltipOpts(trigger='item',
formatter="{a} <br/>{b} : {c}",
background_color="#ffd1df",
border_color="#ffffd4",
border_width=4,
textstyle_opts=opts.TextStyleOpts(font_size=14, color='blue'),)).set_global_opts(title_opts=opts.TitleOpts(title=city_name+"转化漏斗图")))return funnel
funnel_show(funnel_data,"A市").render_notebook()
funnel_show(funnel_data,"B市").render_notebook()
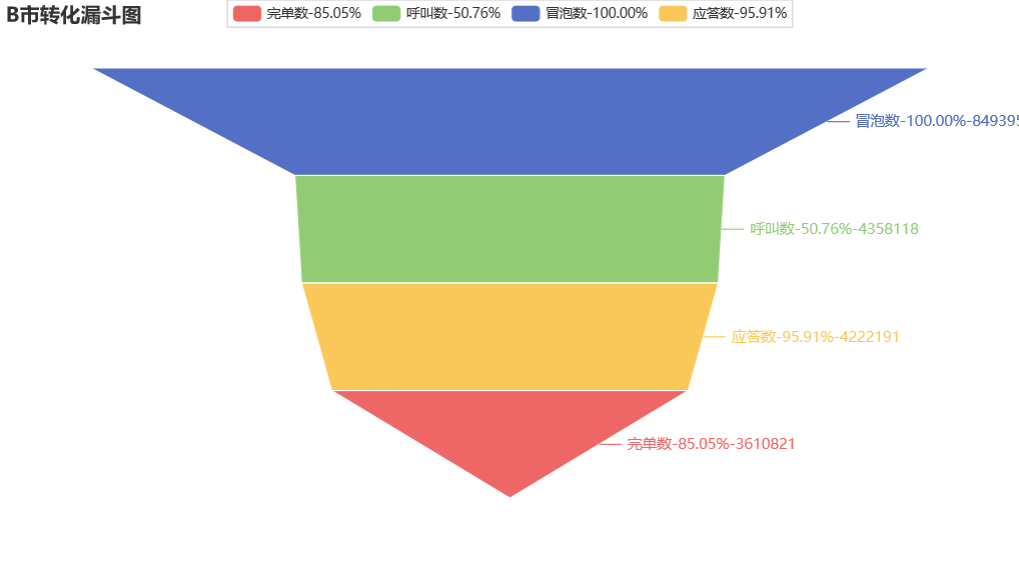
funnel_show(funnel_data,"C市").render_notebook()
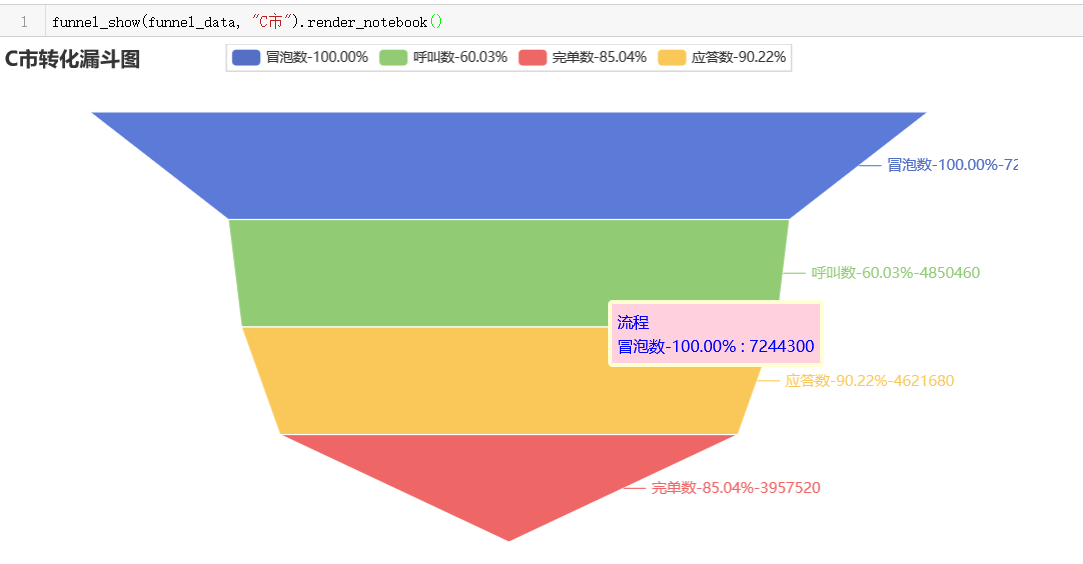
funnel_show(funnel_data,"D市").render_notebook()
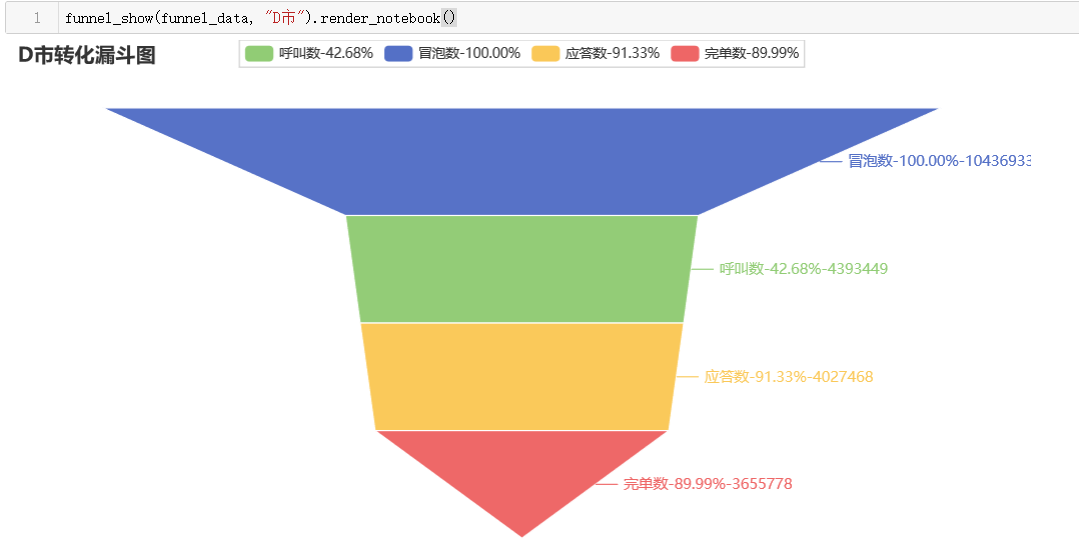
funnel_show(funnel_data,"E市").render_notebook()
# 各城市司乘比
x_data = data["城市"].drop_duplicates().to_list()
y_data = data.groupby('城市')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
x_data
y_data
bar =(
Bar().add_xaxis(x_data).add_yaxis('各市司乘比', y_data))
bar.render_notebook()
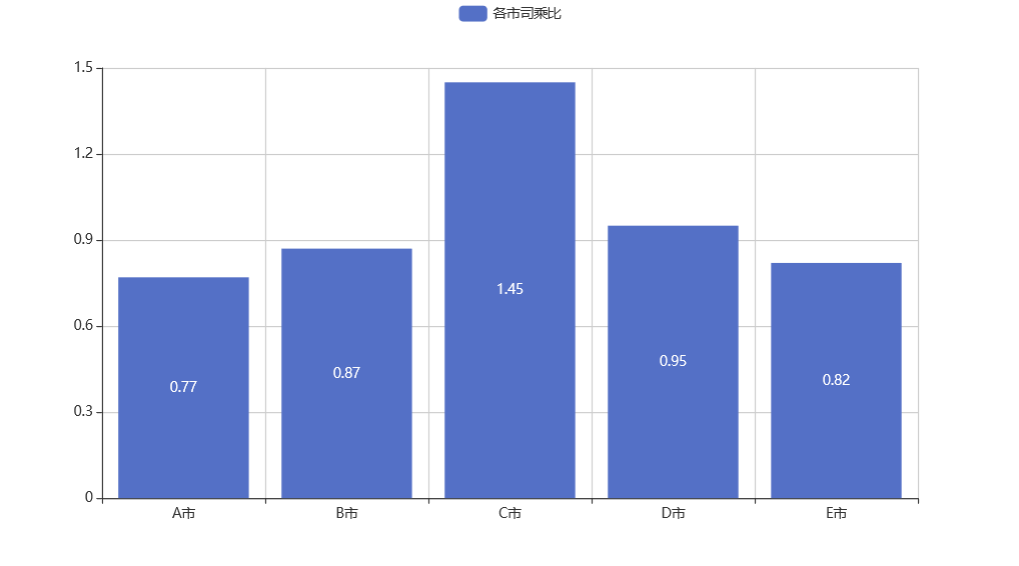
说明 C 市 每位司机 每小时接单量最多
# 各市每日司乘比
x_data =['周一','周二','周三','周四','周五','周六','周日']
y1 = data[data['城市']=='A市'].groupby('星期')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
y2 = data[data['城市']=='B市'].groupby('星期')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
y3 = data[data['城市']=='C市'].groupby('星期')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
y4 = data[data['城市']=='D市'].groupby('星期')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
y5 = data[data['城市']=='E市'].groupby('星期')['司乘比'].mean().apply(lambda x:round(x,2)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="司乘比")))
line.render_notebook()
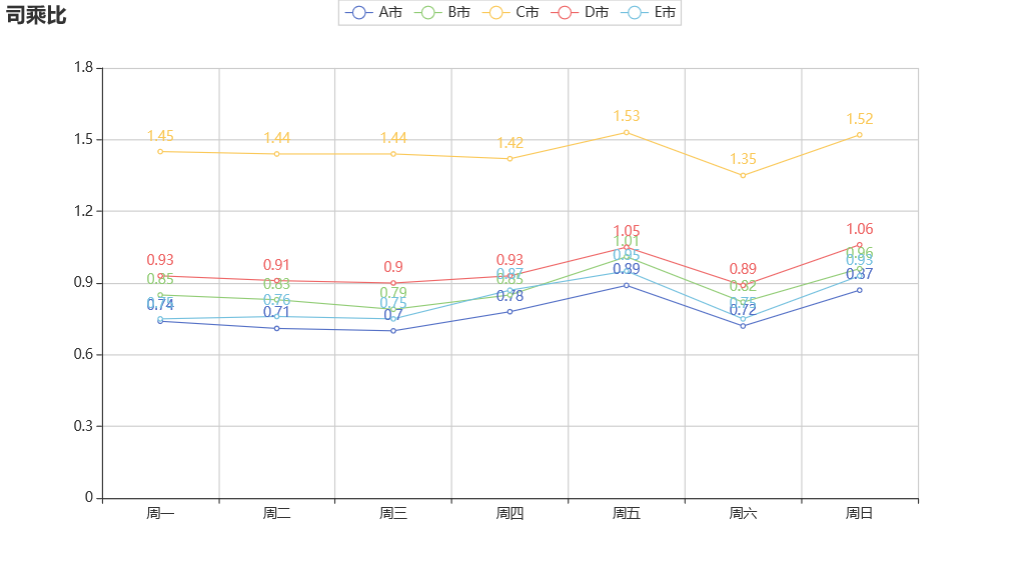
由上图可知:
周五和周日的司乘比最多,司机的接单量增加,
从周一到周日,C 市的司乘比最多,说明 C 市的司机接单意愿和实际接单数最好,说明运营和区 app 使用量较好
x_data =['冒泡数','呼叫数','应答数','完单数']
y1 =[round(data[data['城市']=='A市']['冒泡数'].mean(),2),round(data[data['城市']=='A市']['呼叫数'].mean(),2),round(data[data['城市']=='A市']['应答数'].mean(),2),round(data[data['城市']=='A市']['完单数'].mean(),2)]
y2 =[round(data[data['城市']=='B市']['冒泡数'].mean(),2),round(data[data['城市']=='B市']['呼叫数'].mean(),2),round(data[data['城市']=='B市']['应答数'].mean(),2),round(data[data['城市']=='B市']['完单数'].mean(),2)]
y3 =[round(data[data['城市']=='C市']['冒泡数'].mean(),2),round(data[data['城市']=='C市']['呼叫数'].mean(),2),round(data[data['城市']=='C市']['应答数'].mean(),2),round(data[data['城市']=='C市']['应答数'].mean(),2)]
y4 =[round(data[data['城市']=='D市']['冒泡数'].mean(),2),round(data[data['城市']=='D市']['呼叫数'].mean(),2),round(data[data['城市']=='D市']['应答数'].mean(),2),round(data[data['城市']=='D市']['完单数'].mean(),2)]
y5 =[round(data[data['城市']=='E市']['冒泡数'].mean(),2),round(data[data['城市']=='E市']['呼叫数'].mean(),2),round(data[data['城市']=='E市']['应答数'].mean(),2),round(data[data['城市']=='E市']['完单数'].mean(),2)]
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="订单流程")))
line.render_notebook()
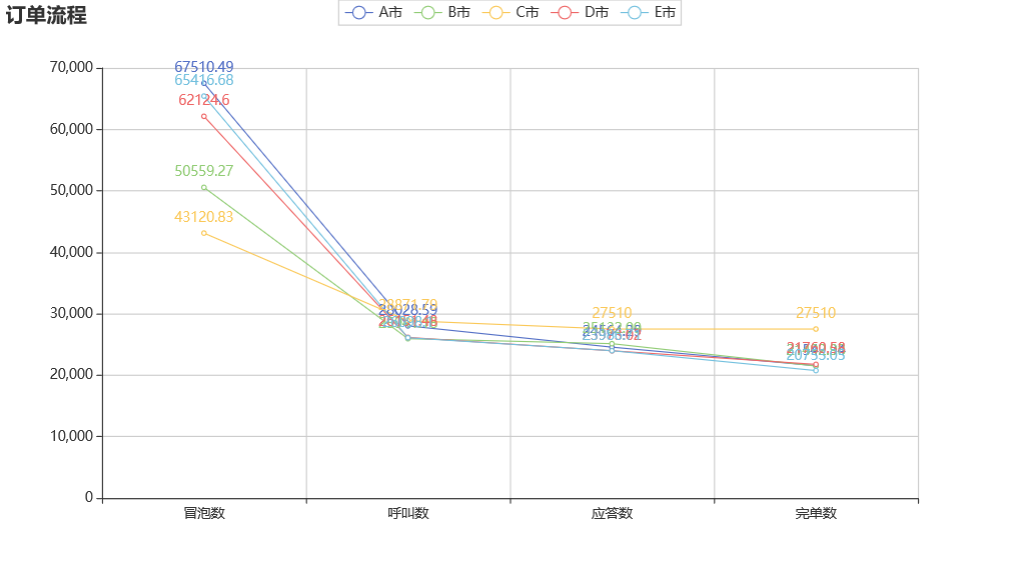
C 城市虽然冒泡数最少,但是呼叫数、应答数直到完单数都是最多的
从周一到周日,C 市的订单数是最多的,但是在线的司机数却是最少的。因此,要增加 C 市司机的数量。 A 市虽然冒泡最多,但是最终完成订单的数量较少,所以 A 市 是最需要关注的城市。其次是 E,再次是 D。 冒泡多 但完单少,可能是运营问题,也可能是竞争问题,也可能是交通问题。
#各市每日完单数
x_data =['周一','周二','周三','周四','周五','周六','周日']
y1=data[data['城市']=='A市'].groupby('星期')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y2=data[data['城市']=='B市'].groupby('星期')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y3=data[data['城市']=='C市'].groupby('星期')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y4=data[data['城市']=='D市'].groupby('星期')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y5=data[data['城市']=='E市'].groupby('星期')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
line=(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市",y_axis=y1).add_yaxis(series_name="B市",y_axis=y2).add_yaxis(series_name="C市",y_axis=y3).add_yaxis(series_name="D市",y_axis=y4).add_yaxis(series_name="E市",y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="各市每日完单数")))
line.render_notebook()
#工作日各市各时段完单数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1=data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y2=data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y3=data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y4=data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y5=data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
line=(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市",y_axis=y1).add_yaxis(series_name="B市",y_axis=y2).add_yaxis(series_name="C市",y_axis=y3).add_yaxis(series_name="D市",y_axis=y4).add_yaxis(series_name="E市",y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段完单数")))
line.render_notebook()
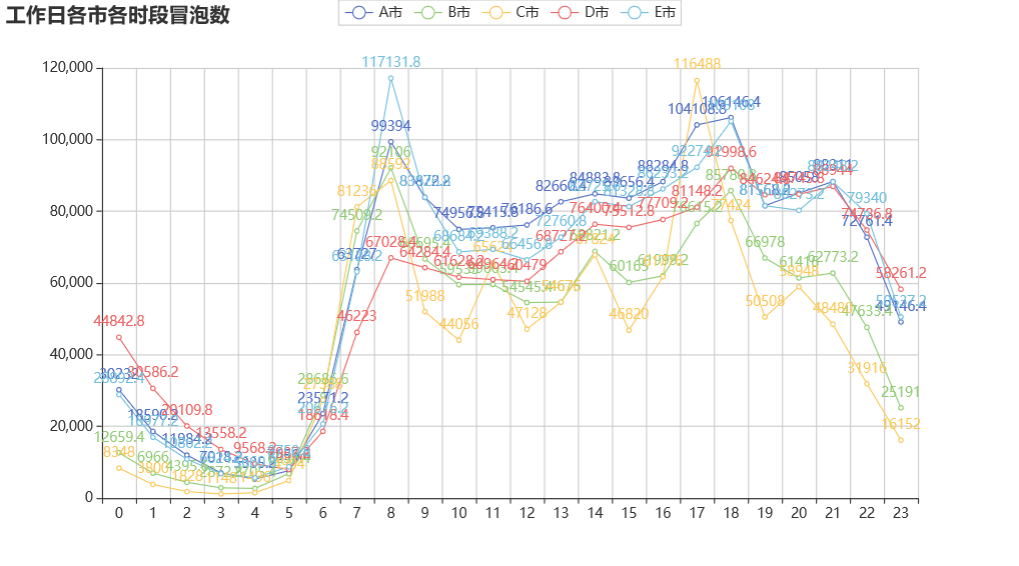
# 工作日各市各时段冒泡数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['冒泡数'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['冒泡数'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['冒泡数'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['冒泡数'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['冒泡数'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段冒泡数")))
line.render_notebook()
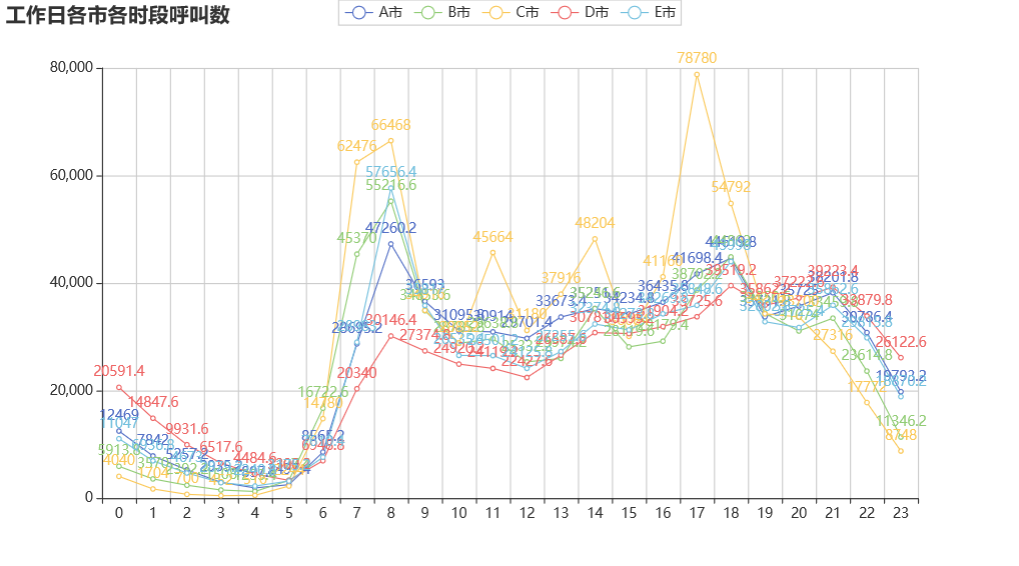
# 工作日各市各时段呼叫数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['呼叫数'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['呼叫数'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['呼叫数'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['呼叫数'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['呼叫数'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段呼叫数")))
line.render_notebook()
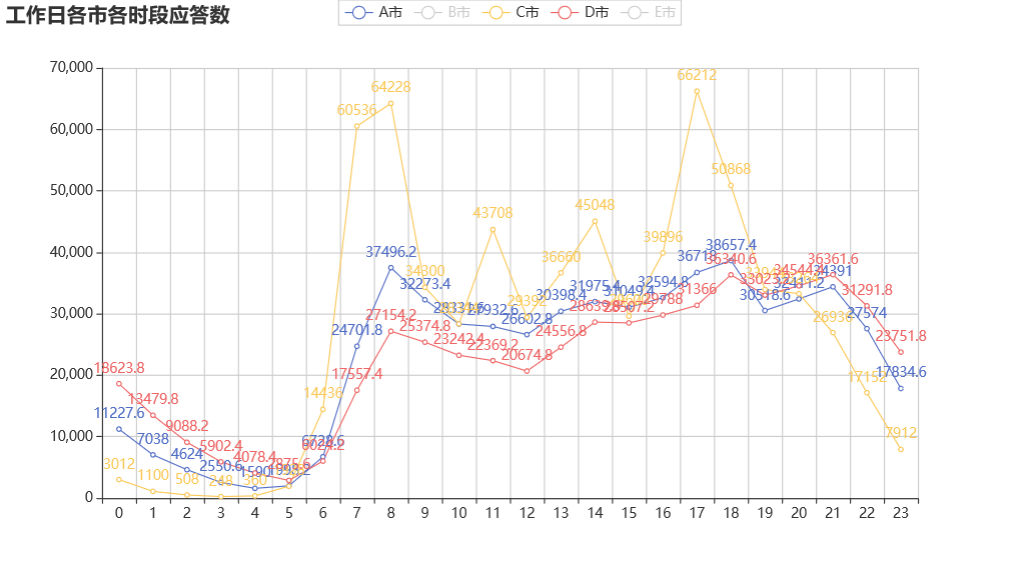
#工作日各市各时段应答数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1=data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['应答数'].mean().apply(lambda x:round(x,1)).to_list()
y2=data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['应答数'].mean().apply(lambda x:round(x,1)).to_list()
y3=data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['应答数'].mean().apply(lambda x:round(x,1)).to_list()
y4=data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['应答数'].mean().apply(lambda x:round(x,1)).to_list()
y5=data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['应答数'].mean().apply(lambda x:round(x,1)).to_list()
line=(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市",y_axis=y1).add_yaxis(series_name="B市",y_axis=y2).add_yaxis(series_name="C市",y_axis=y3).add_yaxis(series_name="D市",y_axis=y4).add_yaxis(series_name="E市",y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段应答数")))
line.render_notebook()
#工作日各市各时段转化率
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1=data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y2=data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y3=data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y4=data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y5=data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
line=(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市",y_axis=y1).add_yaxis(series_name="B市",y_axis=y2).add_yaxis(series_name="C市",y_axis=y3).add_yaxis(series_name="D市",y_axis=y4).add_yaxis(series_name="E市",y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段转化率")))
line.render_notebook()
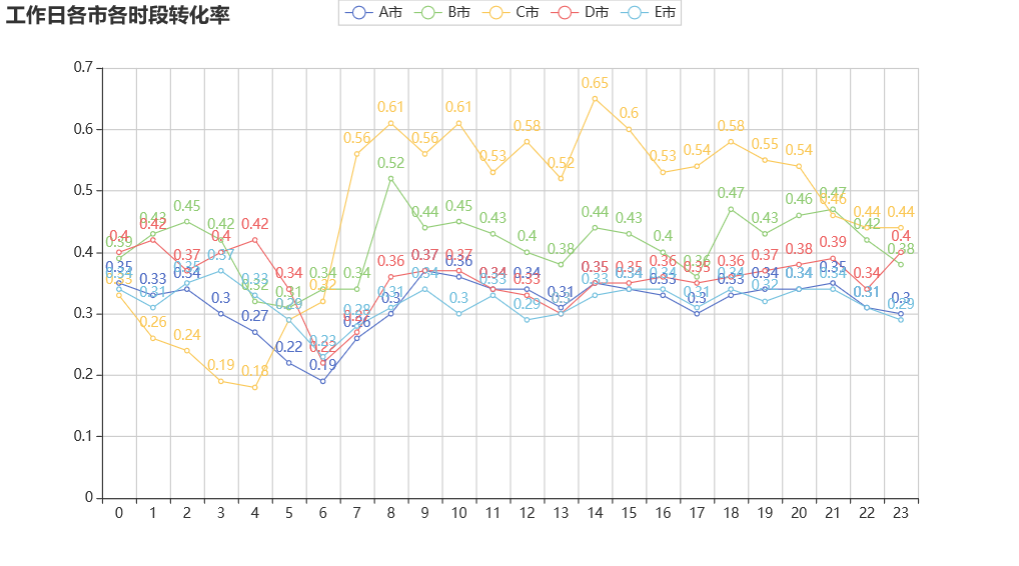
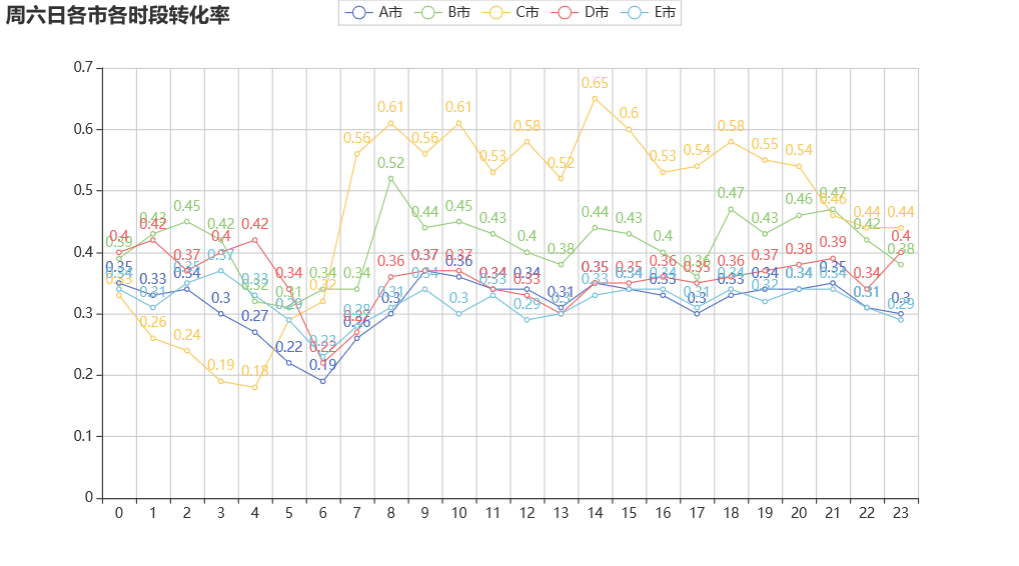
小城市 BC
C 市应该是一个小城市 0-4 点 完单率较低 可以考虑下,这个时间段的冒泡数 呼叫数 应答数 完单数
B 市 各个时间段 完单率都较好 0.4
大城市 ADE
A 市 各个时间段 完单率都较低 说明可能不是市内交通环境 ,而是运营或是竞争的问题 A 市在 9 点早高峰,达到最佳 0.37 说明 A 市是有需求的
D 市 0-5 点 完单率最好 比白天还要好,说明可能是与交通有关
E 市 各个时间段 完单率都较低 说明可能不是市内交通环境 ,而是运营或是竞争的问题
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段司机在线数")))
line.render_notebook()
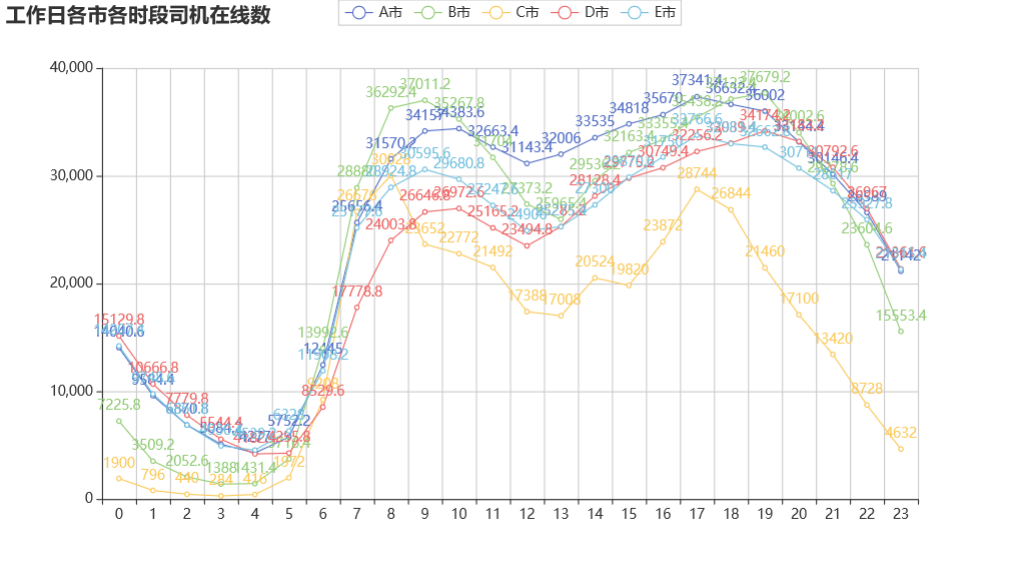
C 城市 夜晚司机太少 可以增加夜晚司机的任务完成奖励
# 周六日日各市各时段完单数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="周六日各市各时段完单数")))
line.render_notebook()
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['司机在线'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="工作日各市各时段司机在线数")))
line.render_notebook()
# 周六日日各市各时段完单数
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1 = data[(data['城市']=='A市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y2 = data[(data['城市']=='B市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y3 = data[(data['城市']=='C市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y4 = data[(data['城市']=='D市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
y5 = data[(data['城市']=='E市')&(data['工作日']==0)].groupby('时段')['完单数'].mean().apply(lambda x:round(x,1)).to_list()
line =(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市", y_axis=y1).add_yaxis(series_name="B市", y_axis=y2).add_yaxis(series_name="C市", y_axis=y3).add_yaxis(series_name="D市", y_axis=y4).add_yaxis(series_name="E市", y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="周六日各市各时段完单数")))
line.render_notebook()
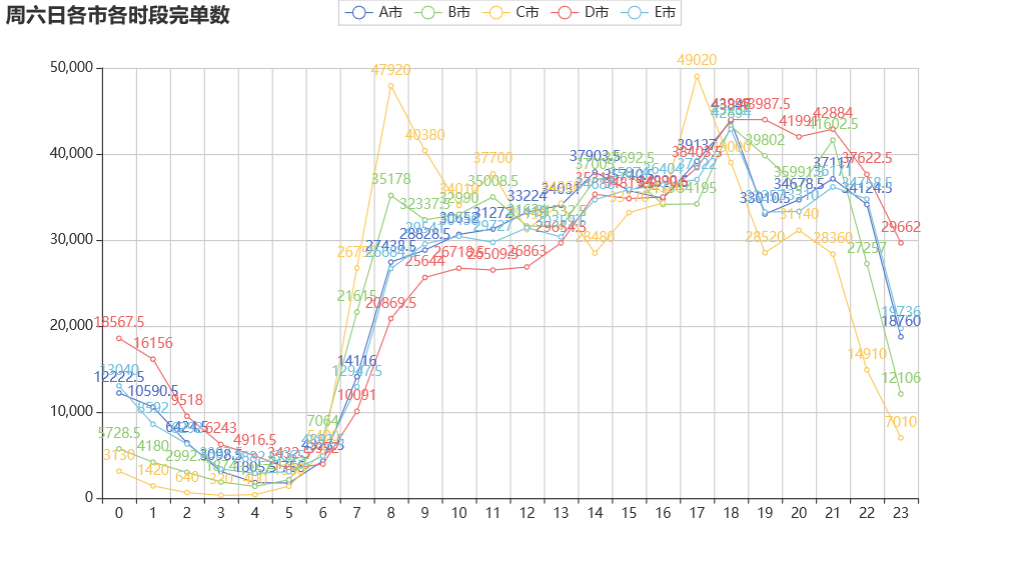
#周六日各市各时段转化率
x_data =['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16','17','18','19','20','21','22','23']
y1=data[(data['城市']=='A市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y2=data[(data['城市']=='B市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y3=data[(data['城市']=='C市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y4=data[(data['城市']=='D市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
y5=data[(data['城市']=='E市')&(data['工作日']==1)].groupby('时段')['转化率'].mean().apply(lambda x:round(x,2)).to_list()
line=(
Line().add_xaxis(xaxis_data=x_data).add_yaxis(series_name="A市",y_axis=y1).add_yaxis(series_name="B市",y_axis=y2).add_yaxis(series_name="C市",y_axis=y3).add_yaxis(series_name="D市",y_axis=y4).add_yaxis(series_name="E市",y_axis=y5).set_global_opts(title_opts=opts.TitleOpts(title="周六日各市各时段转化率")))
line.render_notebook()
1等奖作品-虾虾蟹蟹哈哈的作品
参考:关于网约车数据的探索
引言:背景
🚩 网约车的行业特点:网约车,全称为网络预约出租汽车,是通过互联网平台对接 运力(驾驶员、车辆)和乘客,提供非巡游出租车服务的经营活动。利益关联方主要是平台、司机、车辆和消费者四方。
🚩 网约车平台的目的:
- 通过资源调配(司机和车)实现供需平衡;
- 以最少的成本,最大限度满足乘客需求,才能获得更多的利益。
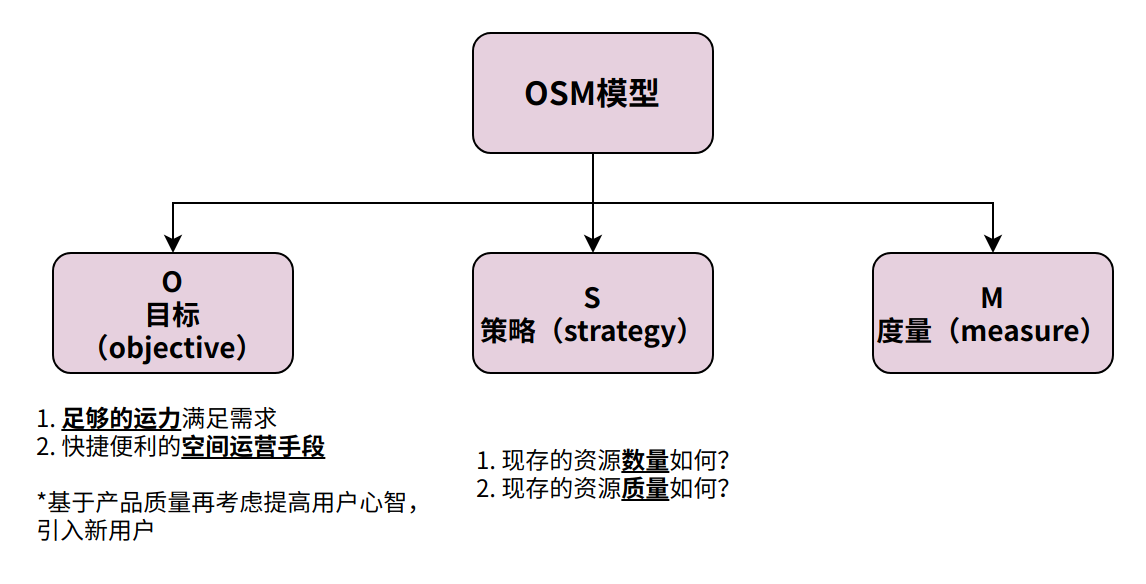
OSM模型参考
度量指标 & 结论
因此【数量】和【质量】两个维度,选取以下数据指标观察网约车运营现状:
数据指标成为关键指标的原因说明【数量】乘客司机比是否有足够的司机数可以满足乘客的需求=1 供需平衡【理想状态】 ;<1 乘客数量多;>1 司机数量多。【质量】完单率运力的空间利用率,直接关系到平台的营利,平台收入 = 佣金 完单数 客单价完单率 = 完单数 / 呼叫数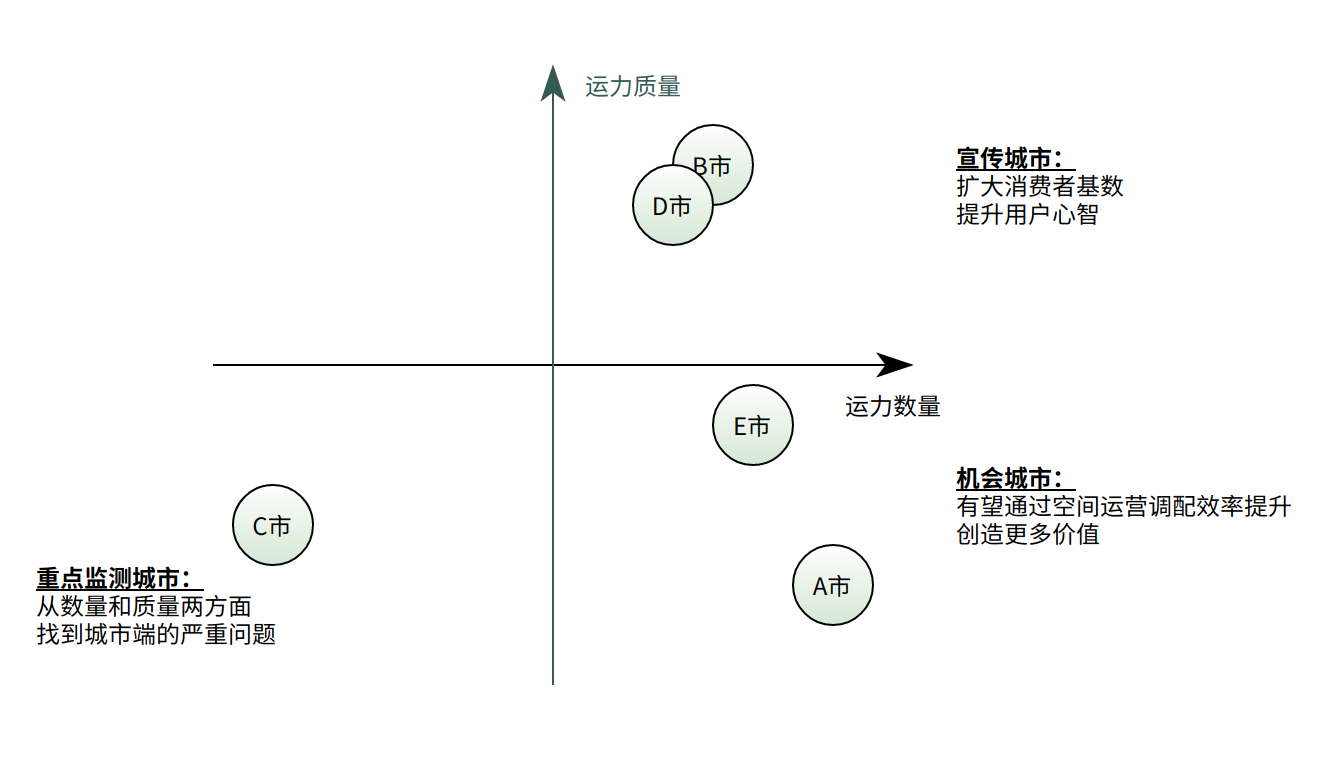
过程数据与思考
一、数据处理
数据底表中没有脏数据,直接查看并新增主要分析字段:
乘客司机比 = 呼叫数 / 司机在线数 = 乘客在线数 / 司机在线数 完单率 = 完单数 / 呼叫数
二、大盘存量数据一览
1. 分城市关键指标变化情况
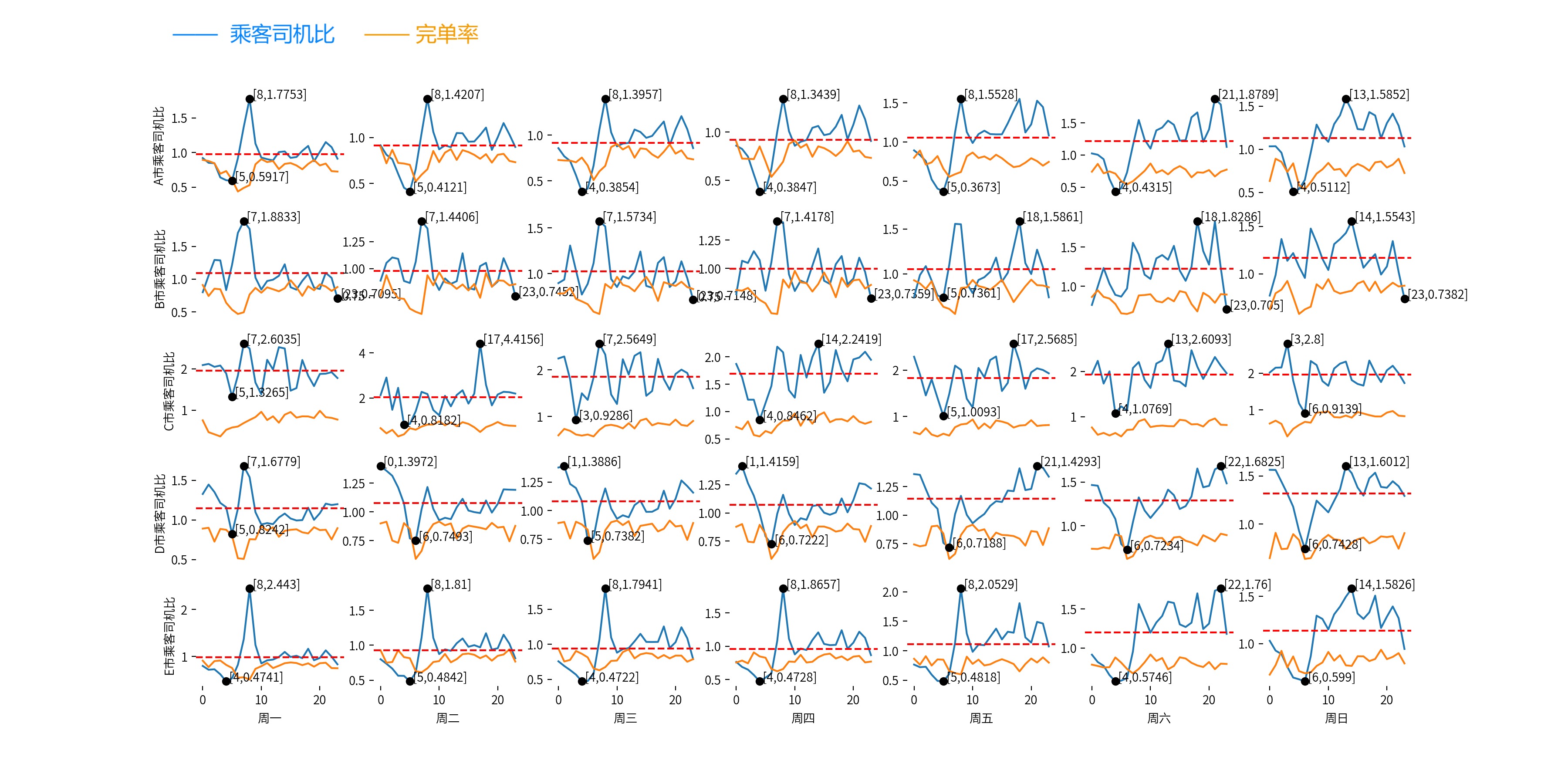
分析结论:
(1)从【乘客司机比】上看:同一城市,工作日与双休日分别呈现出相似的变化,高峰和低谷出现的时间点往往是相近的。因此把工作日和双休日合并进行分析是合理的;
(2)【乘客司机比】与【完单率】之间没有明显的相关性;
(3)白天和傍晚的【乘客司机比】往往也呈现出一定规律性,一般在白天达到最大值,夜晚达到最小值;
(4)C 市的平均【乘客司机比】明显高于其他城市,或作为后续数据分析的重点观测对象。
2. 各项指标相关性分析
新增各步骤的转化率作为分析字段,尝试查看各指标之间的相关性:
呼叫转化率 = 呼叫数 / 冒泡数
应答转化率 = 应答数 / 呼叫数
完单转化率 = 完单数 / 应答数

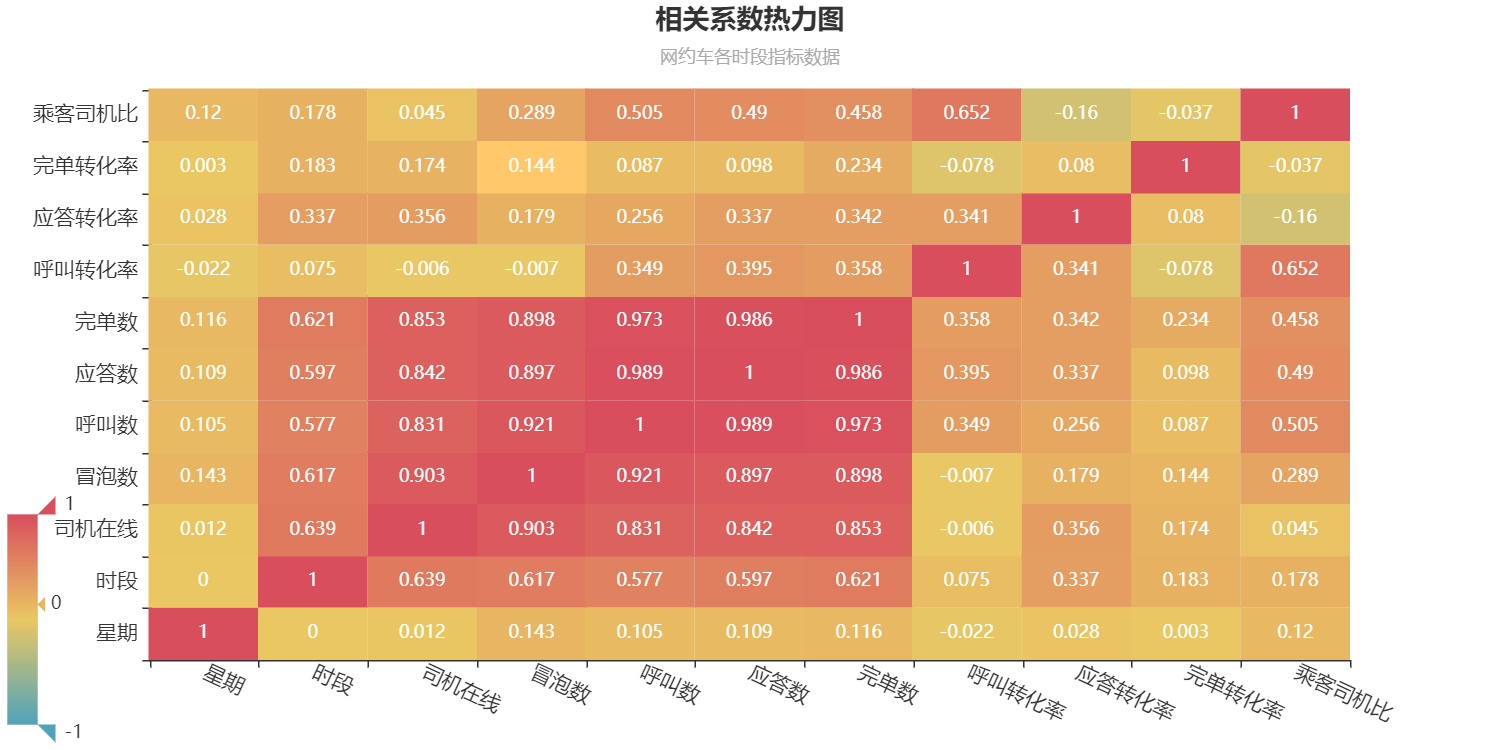
分析结论:
(1)时段和司机在线数呈现出比较强的正相关,根据时间段进行研究有一定合理性;
(2)司机在线数与冒泡数,呼叫数,应答数和完单数呈现出强正相关,证明运力的在线数量对于是否完成交易起到关键性的作用;
(3)但是,司机在线数与呼叫转化率几乎没有相关性,因此并用冒泡数据来计算存量的乘客数以及观察呼叫转化率的价值可能并不大,也验证了使用呼叫数作为乘客在线数的价值,也可以在用户数量多但转化率不高的关键步骤做一些营销动作;
(4)乘客司机比与完单转化率,即数量和质量之间没有相关关系。
三、数量维度分析
1. 城市间比较
1.1 工作日 vs 双休日
区分工作日与双休日,分城市将【乘客司机比】聚合计算平均值,得到以下折线图:
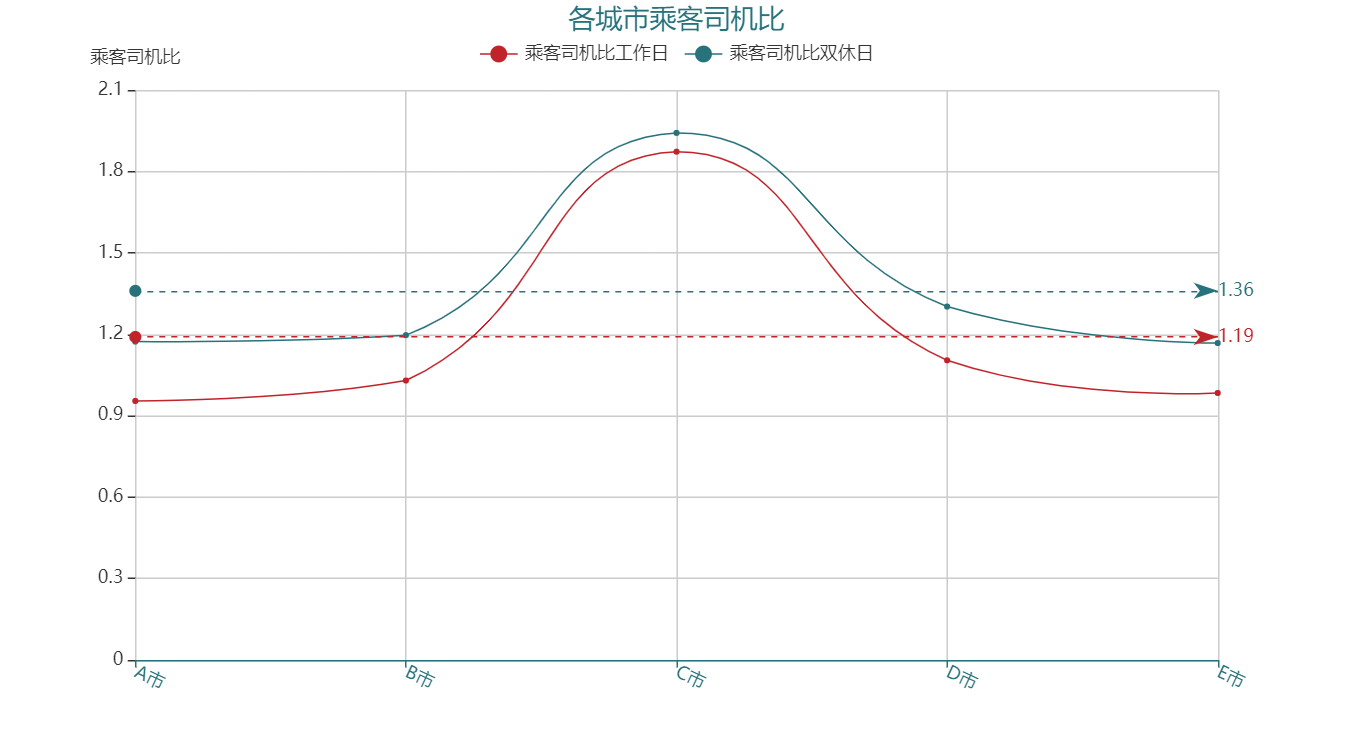
分析结论:
(1)不论从哪个城市来看,双休日的【乘客司机比】明显增加,相较于乘客数,运力数量稍显不足。
(2)五个城市中:
C 市【乘客司机比】工作日与双休日的差距小,但始终高于其他城市并拉高了平均值,日常的运力非常不足;A 市和 E 市的【乘客司机比】较低,工作日平均比值 < 1,说明司机数量比较充足;但工作日与双休日的【乘客司机比】变化幅度大,说明已现有运力承载双休日激增的乘客数量较为困难,不够稳定;* 相较而言,从运力数量及稳定性来看,B 市和 D 市在五个城市中表现较好。运营时,可以首先关注其他城市,将五个城市拉到一个水平线上。
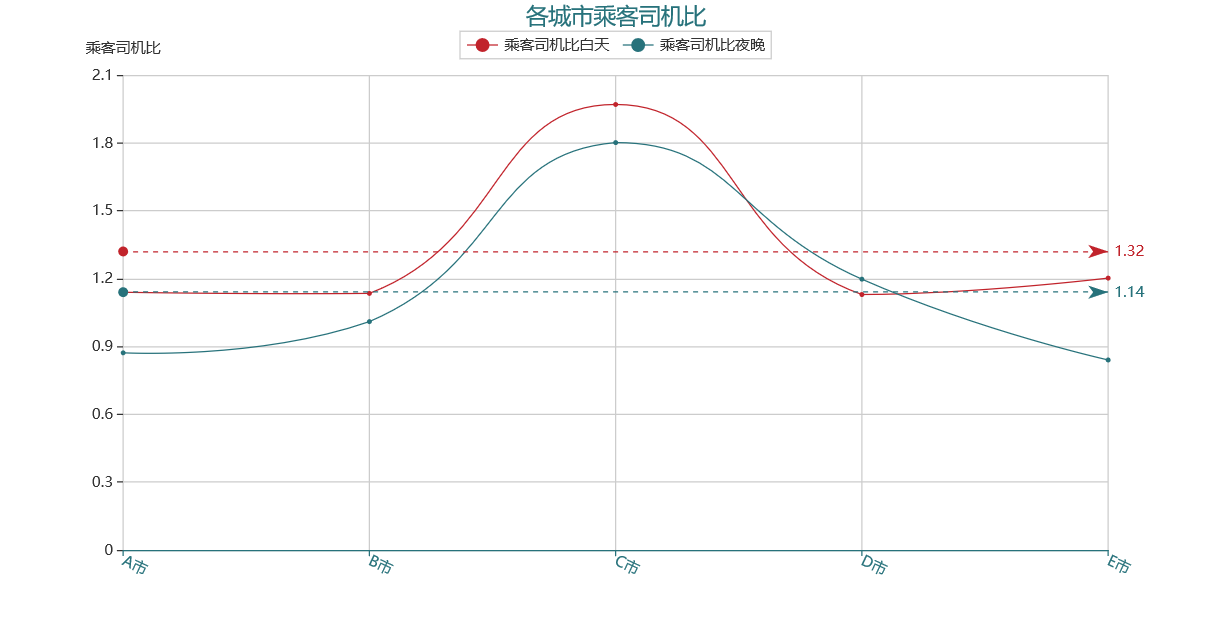
1.2 白天 vs 夜晚
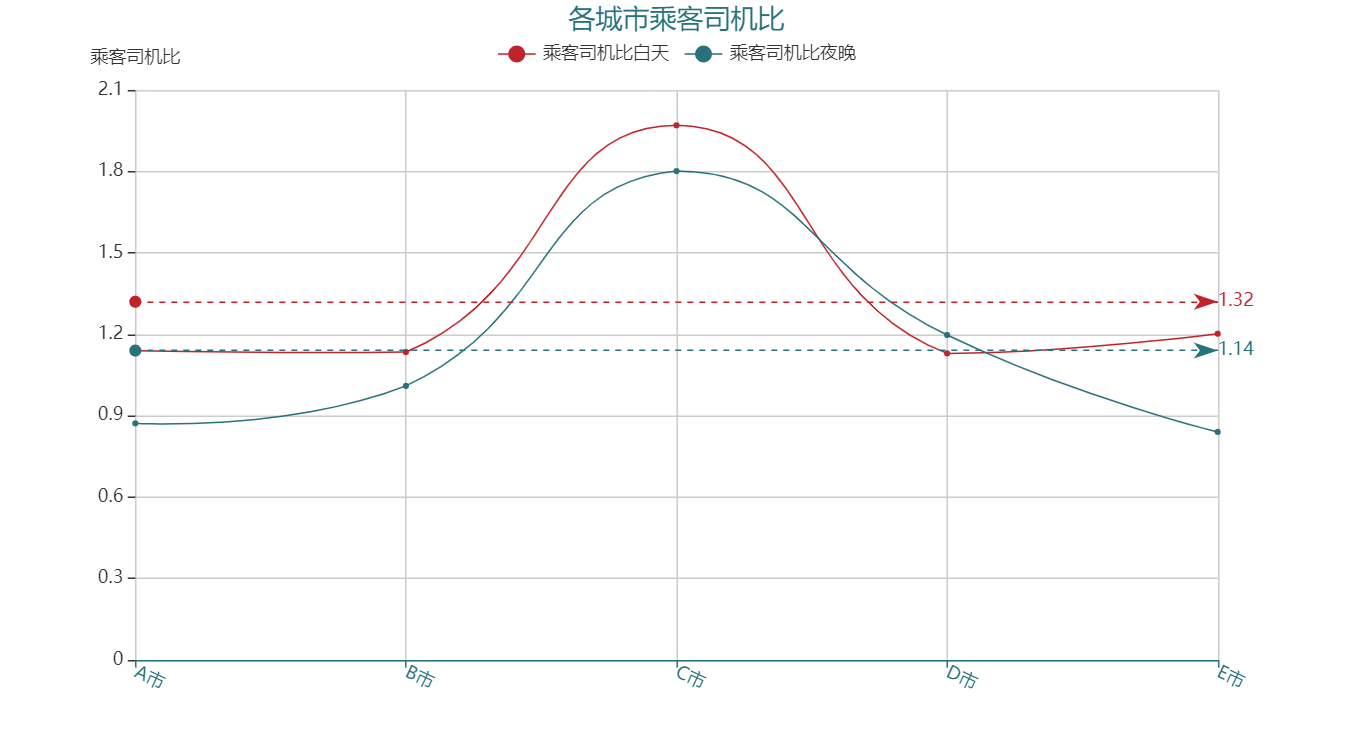
分析结论:
(1)相较于其他四个城市,D 市的夜晚的运力不足以满足乘车需求,或可激励更多的司机夜间上岗,或者分早晚班
(2)同样的,A 市 E 市白天和夜晚的乘客司机比值波动较大,B 市 D 市较为稳定
2. 城市内比较
观察大盘数据,每天大致出现 4-5 个峰值和低谷,各城市内,分别取每日 top5 和 tail5【乘客司机比】时段进行统计,筛选统计数值大于五次的数据:
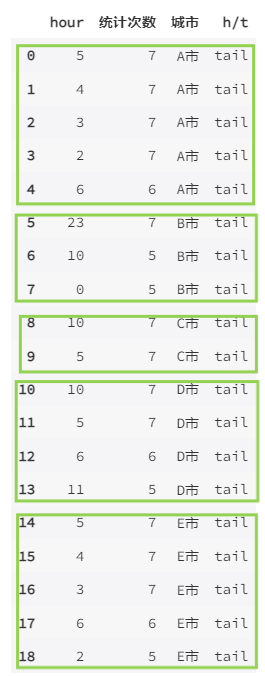
每日【乘客司机比】峰值时段 – 乘客多每日【乘客司机比】低谷时段 – 司机多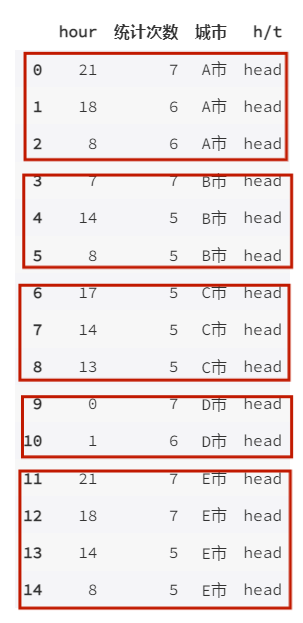
分析结论:
一周七天,有五天以上都在该时段内产生高峰 / 低谷值,说明该时段的问题是一个普遍性的问题,需要通过提前的运营手段加以解决
比较典型的 A 市和 E 市,在每日八点早高峰和晚间下班时段用车乘客数量多,而夜间凌晨时分用车数量少而司机多; D 市则是在凌晨时分没有足够的运力满足乘车需求,而在上午时分运力较用车需求多,分布不均匀B 市常常在 7.8 点迎来用车高峰,而 10 点左右司机运力常为一天内最充足,说明针对运力不足的问题响应较快 。
四、质量维度分析
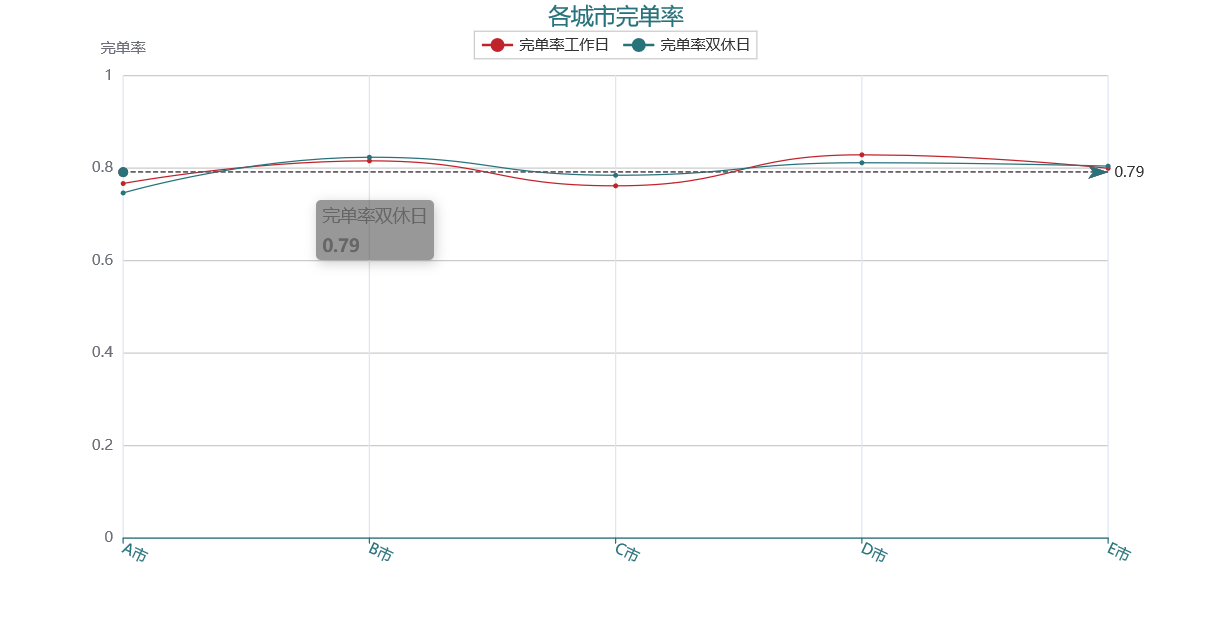
1. 各城市完单率
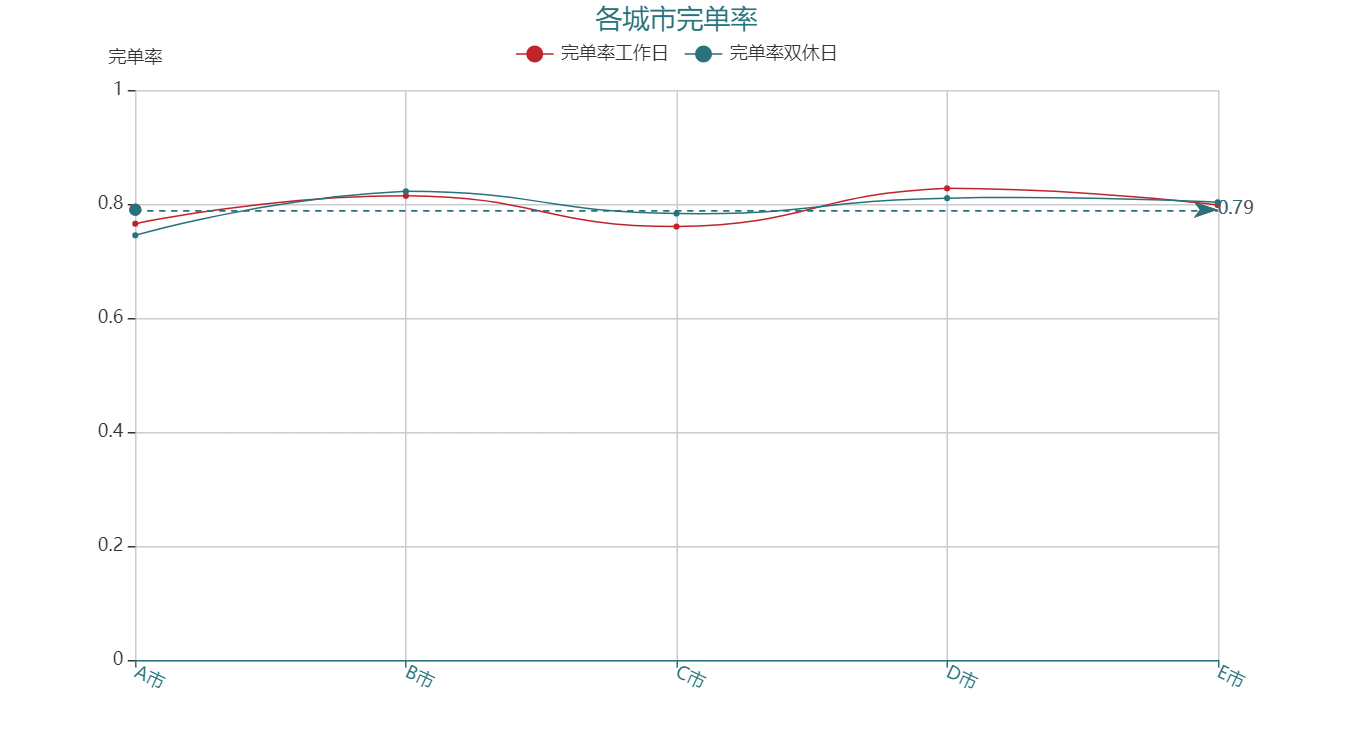
各城市的完单率基本是恒定的,可以看出运力的空间分布效率不受司机数量的影响,五个城市进行比较看出:
- 总的来看 B 市和 D 市的运力分布质量略高于其他的城市;* C 市的空间分布质量最低,可能是受到不充足的运力数量影响;* 但是 A 市和 E 市的运力数量是充足的,反而没有充分利用好运力的优势,使得完单率较低。
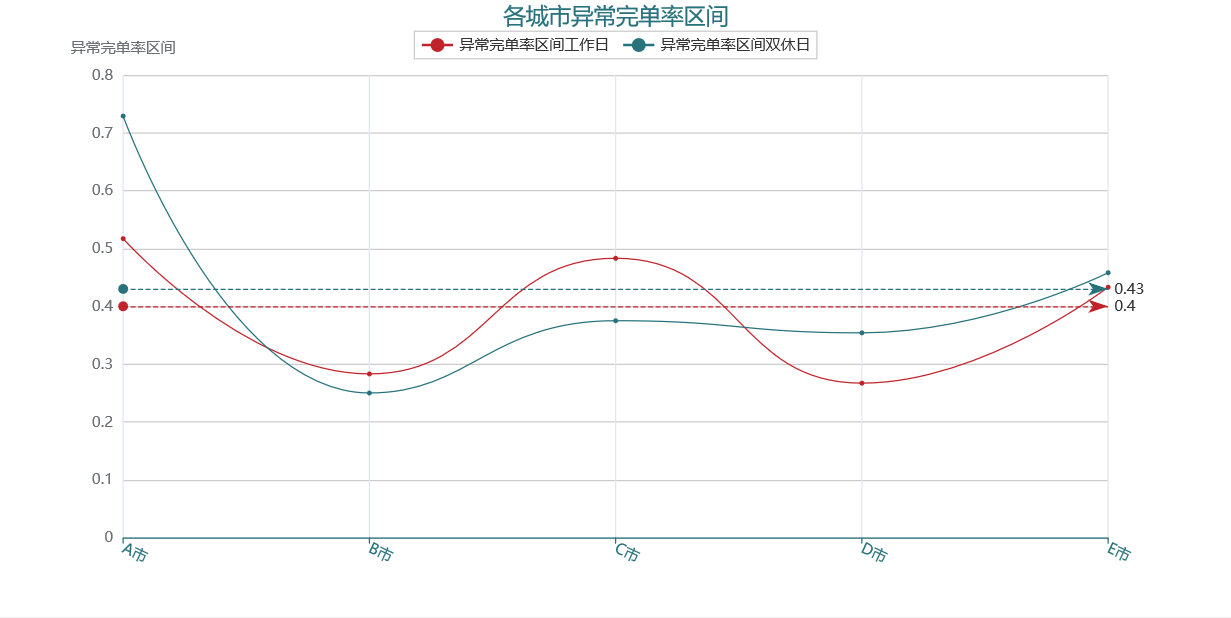
2. 异常区间
各城市的完单率基本在同一区间范围内,而完单率越大说明质量越好,所以取平均值 0.79 的值,限定【完单率 >=0.79 为健康区间】。观察各城市每天有多少时段的完单率是处于异常区间内【完单率 < 0.79】,占比多少,如下图所示:
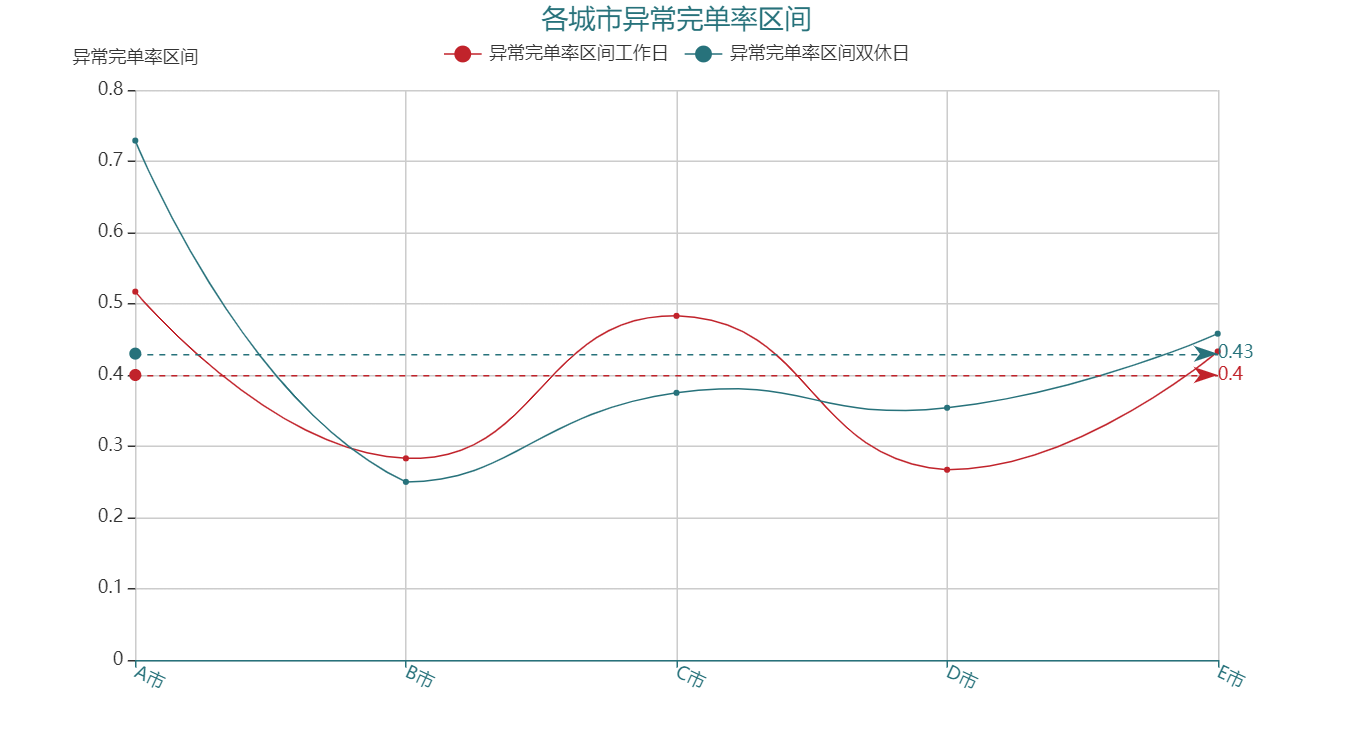
从这里可以明显看出,尤其是 A 市,双休日内完单率低于健康水平的时段占比高达 70%,而平均的异常完单率时段区间约为 40%。从质量上看 B 市和 D 市也是较为稳定的。
五、问题提出与可能的解决方法
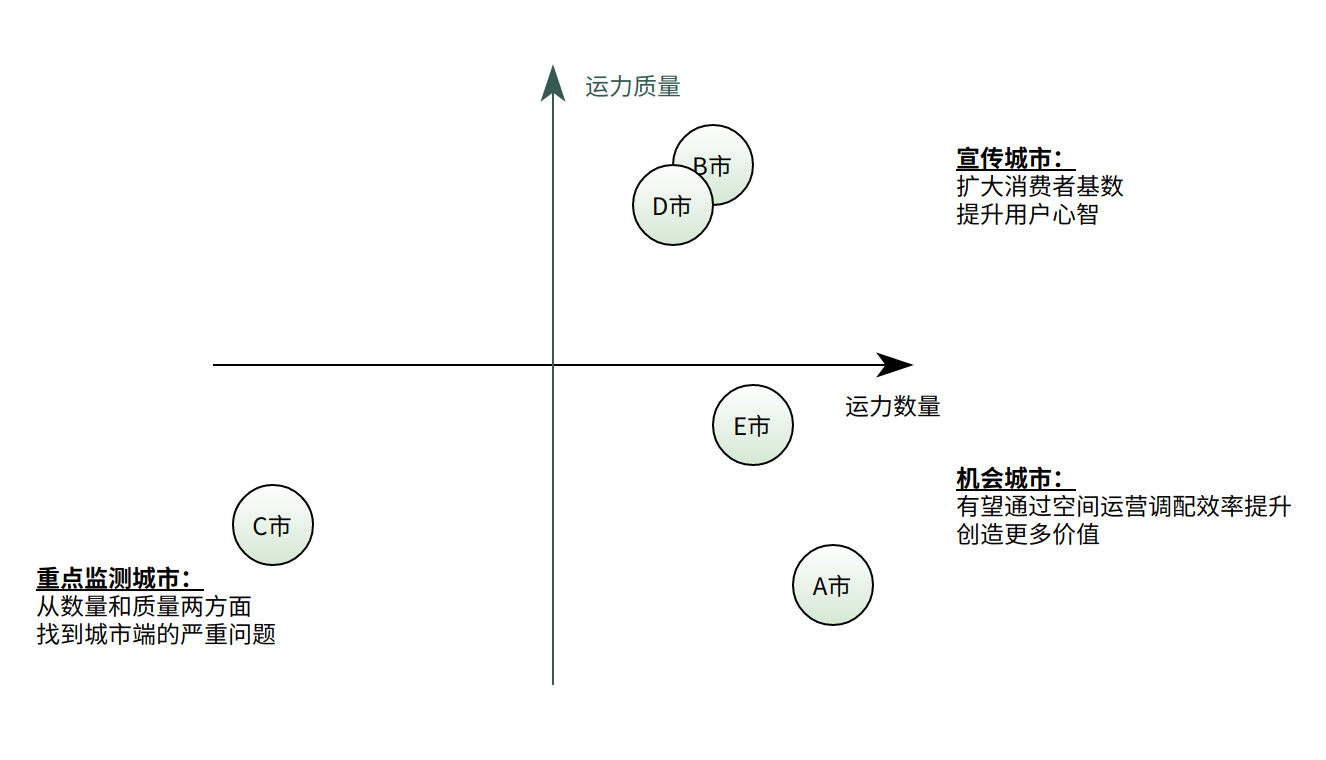
回到开头的结论,把五个城市放到四个象限中去观察现存的问题,这里定义的问题是以数据集里的五个城市为标准的,先把五个城市的运营做到差不多同一个水平线上,再进一步考虑如何优化服务。
从这个角度来说,暂且可以把 B 市设置为标杆,维持目前的运营现状。而比较容易着手的是 A 市和 E 市,它们有充足的运力基础可以作为保障。C 市的问题比较大,是需要重点监测的。实际运营的时候,可以首先招募更多的运力加入作为运营的基础,运营时首先观察时间特征,对于每周固定时段的峰值和低谷进行提前预判,提前 1-2h 调度运力,保证不出现一些超出平均范围的极端值和异常值。
- 感觉还可以做但是没有做的:每天的乘客司机比从最大值回落到 < 1(司机数大于乘客数)的时间,反映运营调配的效率
参考文献
- 网约车业务知识:https://iot.ofweek.com/2022-03/ART-132216-8420-30554335_2.html
- 数据分析与可视化:https://www.heywhale.com/mw/project/63c295841fb7838bd7d2b0ea
代码附录
一、数据查看与数据清洗
import pandas as pd
import numpy as np
from pyecharts.charts import*import pyecharts.options as opts
import collections
rawdata = pd.read_csv('./ride-hailing_data.csv',encoding='utf8')# rawdata.drop(rawdata.columns[[-1,-2]], axis=1, inplace=True) # 删除最后两列脏数据
rawdata
rawdata.describe().T
# 计算离散型变量的统计特征(默认是计算数值型)--传‘all’放在一张表里
rawdata.describe(include=['O']).T #五个城市,每个城市各星期,每小时的运行数据,共5*7*24=840行

# 新增分析字段
rawdata['乘客司机比']=rawdata['呼叫数']/rawdata['司机在线']
rawdata['完单率']=rawdata['完单数']/rawdata['呼叫数']
rawdata
二、 绘图查看城市每天网约车供需趋势
import matplotlib.pyplot as plt
import numpy as np
#查看系统可用字体,在里面找到看起来像中文的字体from matplotlib.font_manager import FontManager
fm = FontManager()
mat_fonts =set(f.name for f in fm.ttflist)print(mat_fonts)
输出为:
{‘Segoe Script’, ‘Script MT Bold’, ‘Sylfaen’, ‘Microsoft NeoGothic’, ‘Perpetua Titling MT’, ‘Tw Cen MT’, ‘DejaVu Sans Display’, ‘Consolas’, ‘Lucida Fax’, ‘DIN Next LT Pro’, ‘STXingkai’, ‘MingLiU-ExtB’, ‘Segoe Print’, ‘Oswald’, ‘Showcard Gothic’, ‘Montserrat’, ‘Rage Italic’, ‘KaiTi’, ‘SimSun-ExtB’, ‘Eras Light ITC’, ‘Informal Roman’, ‘Jokerman’, ‘Old English Text MT’, ‘Century Gothic’, ‘Times New Roman’, ‘DejaVu Serif Display’, ‘Lucida Sans Unicode’, ‘Javanese Text’, ‘STIXSizeFiveSym’, ‘Gill Sans MT Condensed’, ‘FangSong’, ‘STXinwei’, ‘Mongolian Baiti’, ‘Tempus Sans ITC’, ‘Haettenschweiler’, ‘STIXSizeTwoSym’, ‘jdIcoMoonFree’, ‘Niagara Engraved’, ‘Papyrus’, ‘Magneto’, ‘Roboto Condensed’, ‘STXihei’, ‘Bodoni MT’, ‘Microsoft PhagsPa’, ‘Harlow Solid Italic’, ‘MS Mincho’, ‘SimHei’, ‘Snap ITC’, ‘Lucida Calligraphy’, ‘MT Extra’, ‘Tw Cen MT Condensed Extra Bold’, ‘Raleway’, ‘Arvo’, ‘jdIcoFont’, ‘jdiconfontB’, ‘Arial’, ‘Lobster’, ‘Mistral’, ‘cmmi10’, ‘Algerian’, ‘Curlz MT’, ‘Playbill’, ‘Bahnschrift’, ‘jdiconfontD’, ‘Wingdings’, ‘Kunstler Script’, ‘Century’, ‘Gill Sans Ultra Bold Condensed’, ‘Britannic Bold’, ‘Corbel’, ‘Goudy Stout’, ‘Arial Unicode MS’, ‘STSong’, ‘icomoon’, ‘Microsoft MHei’, ‘MV Boli’, ‘Vladimir Script’, ‘Cooper Black’, ‘cmsy10’, ‘Imprint MT Shadow’, ‘STIXSizeFourSym’, ‘Copperplate Gothic Light’, ‘STKaiti’, ‘jdFontCustom’, ‘Bell MT’, ‘Roboto’, ‘Franklin Gothic Medium Cond’, ‘Calibri’, ‘Courier New’, ‘Ravie’, ‘Gigi’, ‘Yu Gothic’, ‘Franklin Gothic Demi’, ‘cmss10’, ‘Segoe UI Emoji’, ‘Franklin Gothic Medium’, ‘Stencil’, ‘Elephant’, ‘jdFontAwesome’, ‘Gloucester MT Extra Condensed’, ‘Californian FB’, ‘Gadugi’, ‘Segoe UI Symbol’, ‘Juice ITC’, ‘Webdings’, ‘SimSun’, ‘Constantia’, ‘Poor Richard’, ‘Gill Sans MT Ext Condensed Bold’, ‘STHupo’, ‘cmb10’, ‘Parchment’, ‘STFangsong’, ‘Modern No. 20’, ‘MS Outlook’, ‘Tahoma’, ‘Eras Medium ITC’, ‘FZShuTi’, ‘Forte’, ‘Leelawadee UI’, ‘High Tower Text’, ‘STCaiyun’, ‘Segoe UI Historic’, ‘Malgun Gothic’, ‘Segoe UI’, ‘Lato’, ‘Perpetua’, ‘DejaVu Sans’, ‘Trebuchet MS’, ‘STIXNonUnicode’, ‘DejaVu Serif’, ‘Lucida Handwriting’, ‘Segoe MDL2 Assets’, ‘Georgia’, ‘Indie Flower’, ‘Nirmala UI’, ‘Chiller’, ‘Harrington’, ‘Verdana’, ‘FZLanTingHeiS-UL-GB’, ‘Matura MT Script Capitals’, ‘Colonna MT’, ‘Berlin Sans FB Demi’, ‘STZhongsong’, ‘Maiandra GD’, ‘Blackadder ITC’, ‘FZCuHeiSongS-B-GB’, ‘Bernard MT Condensed’, ‘Microsoft JhengHei’, ‘OCR A Extended’, ‘Wingdings 2’, ‘Candara’, ‘Berlin Sans FB’, ‘Comic Sans MS’, ‘Segoe WP’, ‘Bauhaus 93’, ‘Bradley Hand ITC’, ‘Century Schoolbook’, ‘French Script MT’, ‘Gill Sans Ultra Bold’, ‘jdiconfontC’, ‘Droid Serif’, ‘MS Gothic’, ‘Lucida Sans’, ‘Microsoft Tai Le’, ‘Gabriola’, ‘Rockwell Extra Bold’, ‘Broadway’, ‘Myanmar Text’, ‘Microsoft Sans Serif’, ‘Lucida Console’, ‘Brush Script MT’, ‘Niagara Solid’, ‘FZYaoTi’, ‘Garamond’, ‘DengXian’, ‘BPG Glaho’, ‘Franklin Gothic Heavy’, ‘STIXSizeThreeSym’, ‘Calisto MT’, ‘Vivaldi’, ‘Agency FB’, ‘STIXSizeOneSym’, ‘Lucida Sans Typewriter’, ‘Rockwell’, ‘DejaVu Sans Mono’, ‘Gill Sans MT’, ‘Monotype Corsiva’, ‘NumberOnly’, ‘Felix Titling’, ‘Dosis’, ‘cmtt10’, ‘Eras Demi ITC’, ‘Edwardian Script ITC’, ‘Microsoft New Tai Lue’, ‘Engravers MT’, ‘Microsoft Himalaya’, ‘Onyx’, ‘Baskerville Old Face’, ‘Marlett’, ‘Copperplate Gothic Bold’, ‘Wingdings 3’, ‘cmr10’, ‘Source Sans Pro’, ‘Tw Cen MT Condensed’, ‘Centaur’, ‘Lucida Bright’, ‘Microsoft YaHei’, ‘Rockwell Condensed’, ‘Eras Bold ITC’, ‘Poiret One’, ‘Impact’, ‘LiSu’, ‘Symbol’, ‘Franklin Gothic Book’, ‘Palatino Linotype’, ‘Ink Free’, ‘Roboto Slab’, ‘Pristina’, ‘Arial Rounded MT Bold’, ‘Ebrima’, ‘HoloLens MDL2 Assets’, ‘Viner Hand ITC’, ‘Sitka Small’, ‘Goudy Old Style’, ‘Castellar’, ‘JdIonicons’, ‘Microsoft Yi Baiti’, ‘Palace Script MT’, ‘Wide Latin’, ‘YouYuan’, ‘Franklin Gothic Demi Cond’, ‘jdiconfontA’, ‘Book Antiqua’, ‘Open Sans’, ‘Footlight MT Light’, ‘STLiti’, ‘DejaVu Math TeX Gyre’, ‘STIXGeneral’, ‘Kristen ITC’, ‘cmex10’, ‘Freestyle Script’, ‘Cambria’, ‘Bookman Old Style’}
d=['A市','B市','C市','D市','E市']
dd=['周一','周二','周三','周四','周五','周六','周日',]
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"]=False#正常显示负号
plt.figure(figsize =(18,9),dpi =200)#dpi图片清晰度
k=1for i inrange(5):for j inrange(7):
test=rawdata[(rawdata['城市']==d[i])&(rawdata['星期']==dd[j])]
plt.subplot(5,7,k,frameon =False)
plt.plot(test['时段'],test['乘客司机比'])
plt.plot(test['时段'],test['完单率'])#plt.yticks=(np.arange(0,5))if(k-1)%7==0:#共用一套轴标签
plt.ylabel(d[i]+'乘客司机比')if k>28:
plt.xlabel(dd[j])if((k-1)%7!=0and k<=28)or k in(1,8,15,22):
ax = plt.gca()
ax.axes.xaxis.set_ticklabels([])#隐藏x轴标签
ax.axes.xaxis.set_ticks([])#隐藏x轴刻度# plt.xticks=(np.arange(0,24),rotation=90)
c=np.mean(test['乘客司机比'])#添加平均值线
plt.axhline(y=c,color="red", linestyle='--', label=c)
k+=1#位置定位#循环标记每张图的最大值和最小值点位
y1_min=np.argmin(np.array(test['乘客司机比']))
y1_max=np.argmax(np.array(test['乘客司机比']))
show_min='['+str(y1_min)+','+str(round(float(test[test['时段']==y1_min]['乘客司机比']),4))+']'
show_max='['+str(y1_max)+','+str(round(float(test[test['时段']==y1_max]['乘客司机比']),4))+']'# 以●绘制最大值点和最小值点的位置
plt.plot(y1_min,test[test['时段']==y1_min]['乘客司机比'],'ko')
plt.plot(y1_max,test[test['时段']==y1_max]['乘客司机比'],'ko')
plt.annotate(show_min,xy=(y1_min,test[test['时段']==y1_min]['乘客司机比']),xytext=(y1_min+0.5,test[test['时段']==y1_min]['乘客司机比']))
plt.annotate(show_max,xy=(y1_max,test[test['时段']==y1_max]['乘客司机比']),xytext=(y1_max+0.5,test[test['时段']==y1_max]['乘客司机比']))#Axes.annotate(s, xy, *args, **kwargs)## s:注释文本的内容## xy:被注释的坐标点,二维元组形如(x,y)## xytext:注释文本的坐标点,也是二维元组,默认与xy相同# plt.savefig('sinc_2.png', c = 'c')
plt.show()
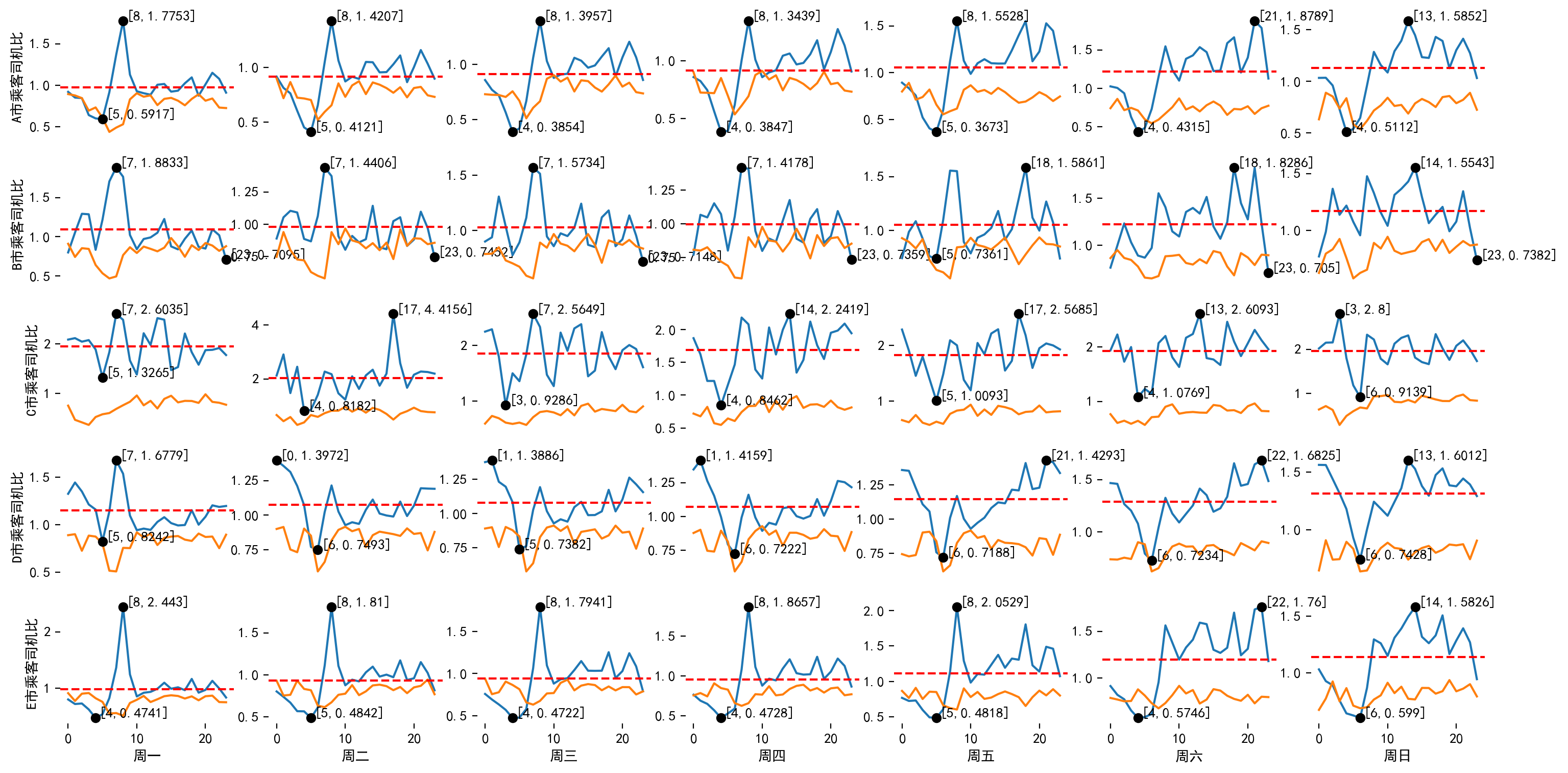
查看各城市的完单率均值,发现在工作日和双休日的差别并不大,因此每日数据作为各城市的完单率均值进行考量。
print('城市',' 完单率均值 ',' 工作日完单率 ',' 双休日完单率 ')print('-------------------------------------------------------------------')for i in d:print(i,rawdata[(rawdata['城市']==i)]['完单率'].mean(),rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['完单率'].mean(),rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周六','周日']))]['完单率'].mean())
输出为: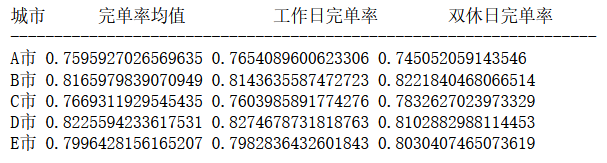
双休日乘客司机比会高一些,五个城市的共性
print('城市',' 乘客司机比均值 ',' 工作日乘客司机比 ',' 双休日乘客司机比 ')print('-------------------------------------------------------------------')for i in d:print(i,rawdata[(rawdata['城市']==i)]['乘客司机比'].mean(),rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['乘客司机比'].mean(),rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周六','周日']))]['乘客司机比'].mean())
输出为: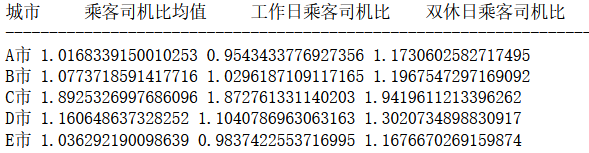
(一)数量
1. 城市间比较
xxx='乘客司机比'
c =(
Line(
init_opts=opts.InitOpts(
theme='infographic',
width=1500,)).add_xaxis([i for i in rawdata['城市'].unique()]).add_yaxis(
xxx+"工作日",[rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['乘客司机比'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).add_yaxis(
xxx+"双休日",[rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周六','周日']))]['乘客司机比'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).set_series_opts(
label_opts=opts.LabelOpts(
is_show=False),).extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}元",),
interval=100)).set_global_opts(
title_opts=opts.TitleOpts(
title='各城市'+xxx,
pos_left='center'),
xaxis_opts=opts.AxisOpts(#name='销量排名区间',
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(rotate=-25),
axistick_opts=opts.AxisTickOpts(is_align_with_label=True,),
is_scale=False,
boundary_gap=False,),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True),
name=xxx
),
legend_opts=opts.LegendOpts(pos_top='5%')#datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(# type_="inside",# pos_bottom=0,# )],))
c.render_notebook()
输出为: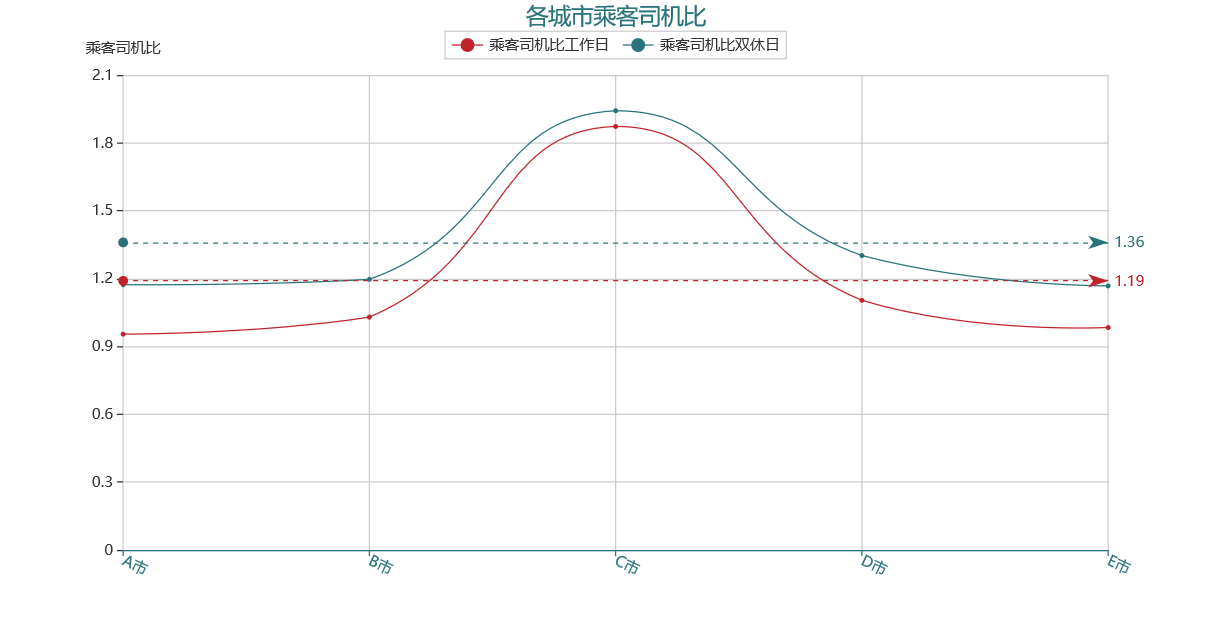
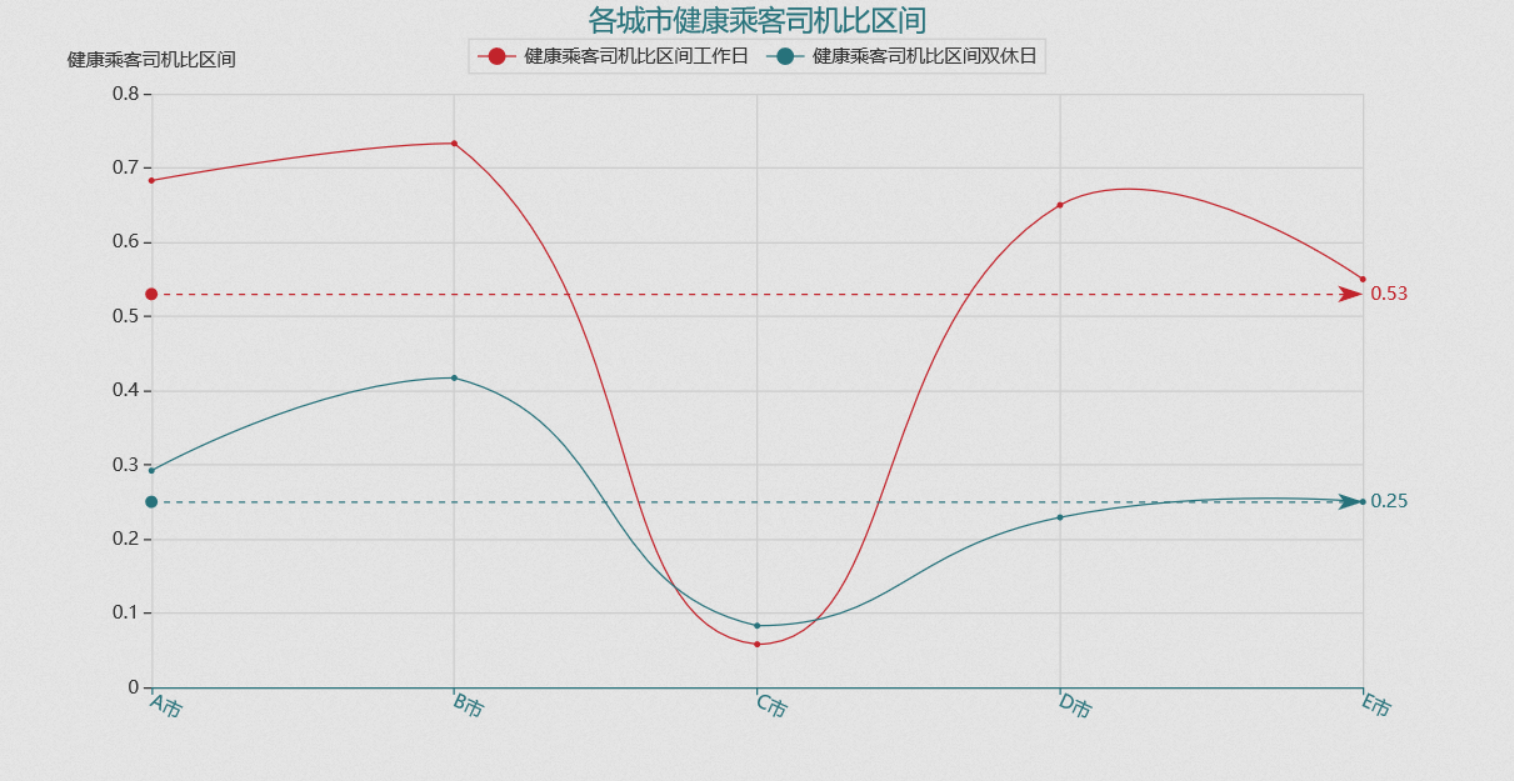
2. 城市内比较:超过标准区间内数值占多少小时
健康乘客司机比区间:根据 A 市和 E 市设置为 [0.8,1.2]
各城市每天处于【健康区间】内的时间有多少?占比全天时间的百分之多少?
fixedmin=rawdata[(rawdata['城市']=='A市')&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['乘客司机比'].mean()
fixedmax=rawdata[(rawdata['城市']=='A市')&(rawdata['星期'].isin(['周六','周日']))]['乘客司机比'].mean()
fixedmax # 1.1730602582717495
[rawdata[(rawdata['城市']== i)&(rawdata['乘客司机比'].between(0.8,1.2))]['时段'].count()/168for i in rawdata['城市'].unique()]
[0.5714285714285714,
0.6428571428571429,
0.06547619047619048,
0.5297619047619048,
0.4642857142857143]
[rawdata[(rawdata['城市']== i)&(rawdata['乘客司机比'].between(0.8,1.2))&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['时段'].count()/120for i in rawdata['城市'].unique()]
[0.6833333333333333, 0.7333333333333333, 0.058333333333333334, 0.65, 0.55]
[rawdata[(rawdata['城市']== i)&(rawdata['乘客司机比'].between(0.8,1.2))&(rawdata['星期'].isin(['周六','周日']))]['时段'].count()/48for i in rawdata['城市'].unique()]
[0.2916666666666667,
0.4166666666666667,
0.08333333333333333,
0.22916666666666666,
0.25]
xxx='健康乘客司机比区间'
c =(
Line(
init_opts=opts.InitOpts(
theme='infographic',
width=1500,)).add_xaxis([i for i in rawdata['城市'].unique()]).add_yaxis(
xxx+"工作日",['%.3f'%(rawdata[(rawdata['城市']== i)&(rawdata['乘客司机比'].between(0.8,1.2))&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['时段'].count()/120)for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).add_yaxis(
xxx+"双休日",['%.3f'%(rawdata[(rawdata['城市']== i)&(rawdata['乘客司机比'].between(0.8,1.2))&(rawdata['星期'].isin(['周六','周日']))]['时段'].count()/48)for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).set_series_opts(
label_opts=opts.LabelOpts(
is_show=False),).extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}元",),
interval=100)).set_global_opts(
title_opts=opts.TitleOpts(
title='各城市'+xxx,
pos_left='center'),
xaxis_opts=opts.AxisOpts(#name='销量排名区间',
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(rotate=-25),
axistick_opts=opts.AxisTickOpts(is_align_with_label=True,),
is_scale=False,
boundary_gap=False,),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True),
name=xxx
),
legend_opts=opts.LegendOpts(pos_top='5%')#datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(# type_="inside",# pos_bottom=0,# )],))
c.render_notebook()
3. 白天夜晚比较
[k for k inrange(7,19)]
# 白天:7-19 晚上:0-6 + 20-24
xxx='乘客司机比'
c =(
Line(
init_opts=opts.InitOpts(
theme='infographic',
width=1500,)).add_xaxis([i for i in rawdata['城市'].unique()]).add_yaxis(
xxx+"白天",[rawdata[(rawdata['城市']==i)&(rawdata['时段'].isin([k for k inrange(7,20)]))]['乘客司机比'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).add_yaxis(
xxx+"夜晚",[rawdata[(rawdata['城市']==i)&(rawdata['时段'].isin([0,1,2,3,4,5,6,20,21,22,23,24]))]['乘客司机比'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).set_series_opts(
label_opts=opts.LabelOpts(
is_show=False),).extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}元",),
interval=100)).set_global_opts(
title_opts=opts.TitleOpts(
title='各城市'+xxx,
pos_left='center'),
xaxis_opts=opts.AxisOpts(#name='销量排名区间',
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(rotate=-25),
axistick_opts=opts.AxisTickOpts(is_align_with_label=True,),
is_scale=False,
boundary_gap=False,),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True),
name=xxx
),
legend_opts=opts.LegendOpts(pos_top='5%')#datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(# type_="inside",# pos_bottom=0,# )],))
c.render_notebook()
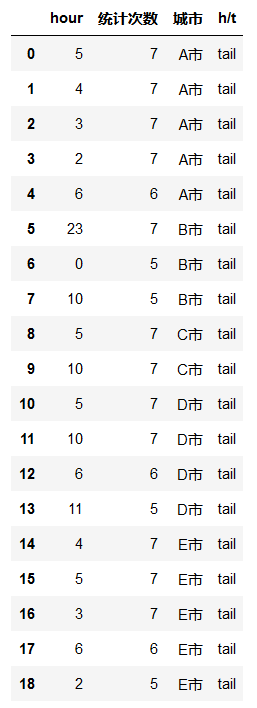
4. 城市内 top N/tail N
df_tail=rawdata.groupby(['城市','星期']).apply(lambda x: x.sort_values('乘客司机比').head(5)).reset_index(drop=True)
df1=pd.DataFrame(df_tail[df_tail['城市']=='A市']['时段'].value_counts()).reset_index()
df1.rename(columns={'index':'hour','时段':'统计次数'},inplace=True)
df1['城市']='A市'for i in d[1:]:
df_tt=pd.DataFrame(df_tail[df_tail['城市']==i]['时段'].value_counts()).reset_index()
df_tt.rename(columns={'index':'hour','时段':'统计次数'},inplace=True)
df_tt['城市']=i
df1=df1.append(df_tt,ignore_index=True)
df1['h/t']='tail'
df1=df1[df1['统计次数']>=5]
df1
df1.reset_index(drop=True)
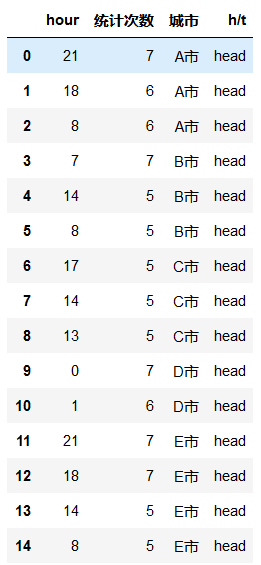
df_head=rawdata.groupby(['城市','星期']).apply(lambda x: x.sort_values('乘客司机比').tail(5)).reset_index(drop=True)
df2=pd.DataFrame(df_head[df_head['城市']=='A市']['时段'].value_counts()).reset_index()
df2.rename(columns={'index':'hour','时段':'统计次数'},inplace=True)
df2['城市']='A市'for i in d[1:]:
df_tt=pd.DataFrame(df_head[df_head['城市']==i]['时段'].value_counts()).reset_index()
df_tt.rename(columns={'index':'hour','时段':'统计次数'},inplace=True)
df_tt['城市']=i
df2=df2.append(df_tt,ignore_index=True)
df2['h/t']='head'
df2=df2[df2['统计次数']>=5]
df2.reset_index(drop=True)
df_head=rawdata.groupby(['城市','星期']).apply(lambda x: x.sort_values('乘客司机比').tail(5)).reset_index(drop=True)
df_head[df_head['城市']=='E市']['时段'].value_counts()

(二)质量
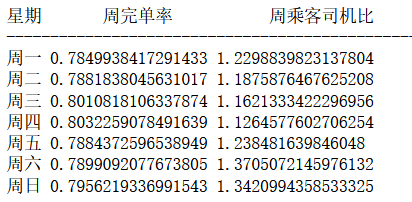
print('星期',' 周完单率 ',' 周乘客司机比')print('-----------------------------------------------')for j in dd:print(j,rawdata[(rawdata['星期']==j)]['完单率'].mean(),rawdata[(rawdata['星期']==j)]['乘客司机比'].mean())
xxx='完单率'
c =(
Line(
init_opts=opts.InitOpts(
theme='infographic',
width=1500,)).add_xaxis([i for i in rawdata['城市'].unique()]).add_yaxis(
xxx+"工作日",[rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['完单率'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).add_yaxis(
xxx+"双休日",[rawdata[(rawdata['城市']==i)&(rawdata['星期'].isin(['周六','周日']))]['完单率'].mean()for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).set_series_opts(
label_opts=opts.LabelOpts(
is_show=False),).extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}元",),
interval=100)).set_global_opts(
title_opts=opts.TitleOpts(
title='各城市'+xxx,
pos_left='center'),
xaxis_opts=opts.AxisOpts(#name='销量排名区间',
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(rotate=-25),
axistick_opts=opts.AxisTickOpts(is_align_with_label=True,),
is_scale=False,
boundary_gap=False,),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True),
name=xxx
),
legend_opts=opts.LegendOpts(pos_top='5%')#datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(# type_="inside",# pos_bottom=0,# )],))
c.render_notebook()
xxx='异常完单率区间'
c =(
Line(
init_opts=opts.InitOpts(
theme='infographic',
width=1500,)).add_xaxis([i for i in rawdata['城市'].unique()]).add_yaxis(
xxx+"工作日",['%.3f'%(rawdata[(rawdata['城市']== i)&(rawdata['完单率']<0.79)&(rawdata['星期'].isin(['周一','周二','周三','周四','周五']))]['时段'].count()/120)for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).add_yaxis(
xxx+"双休日",['%.3f'%(rawdata[(rawdata['城市']== i)&(rawdata['完单率']<0.79)&(rawdata['星期'].isin(['周六','周日']))]['时段'].count()/48)for i in rawdata['城市'].unique()],
is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),).set_series_opts(
label_opts=opts.LabelOpts(
is_show=False),).extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}元",),
interval=100)).set_global_opts(
title_opts=opts.TitleOpts(
title='各城市'+xxx,
pos_left='center'),
xaxis_opts=opts.AxisOpts(#name='销量排名区间',
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(rotate=-25),
axistick_opts=opts.AxisTickOpts(is_align_with_label=True,),
is_scale=False,
boundary_gap=False,),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True),
name=xxx
),
legend_opts=opts.LegendOpts(pos_top='5%')#datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(# type_="inside",# pos_bottom=0,# )],))
c.render_notebook()
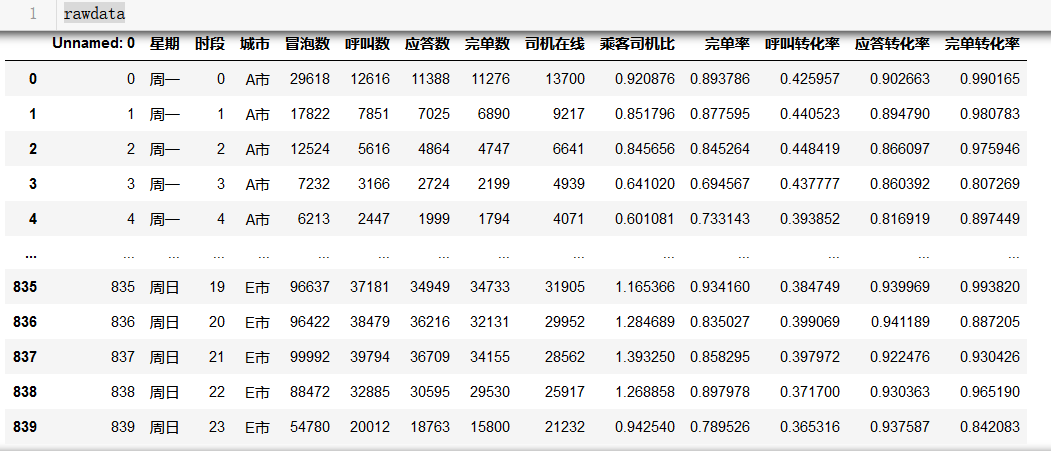
三、求出来三步转化率看一下
1.转换率计算
# 新增分析字段
rawdata['呼叫转化率']=rawdata['呼叫数']/rawdata['冒泡数']
rawdata['应答转化率']=rawdata['应答数']/rawdata['呼叫数']
rawdata['完单转化率']=rawdata['完单数']/rawdata['应答数']
rawdata
rawdata[(rawdata['应答转化率']<rawdata['呼叫转化率'])]

# 异常数据:看一下是哪一步的转化出了问题
rawdata[(rawdata['完单转化率']-rawdata['应答转化率'])<-0.3]#270反之600
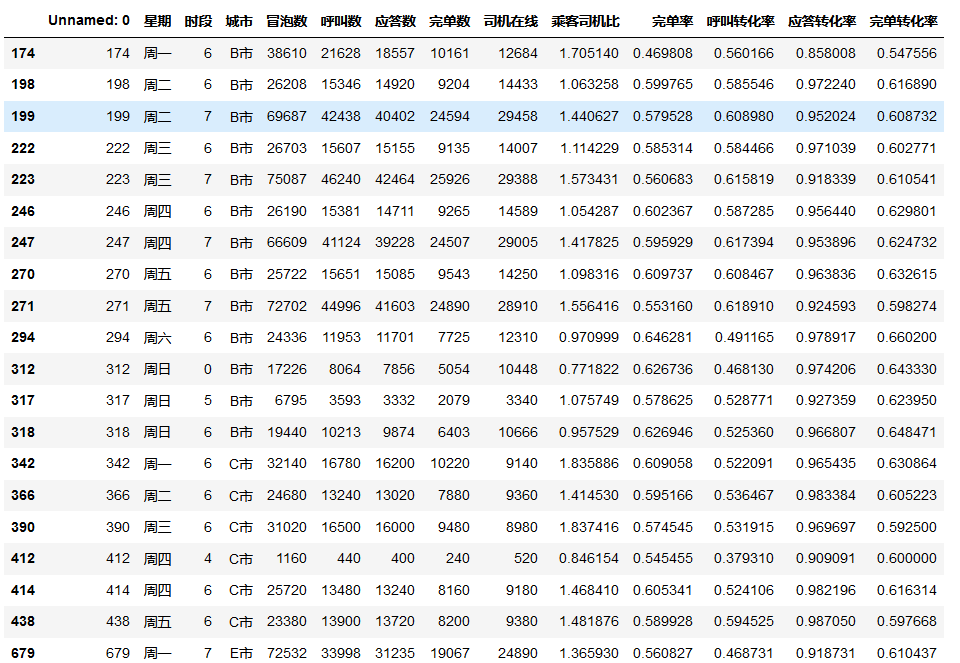
rawdata['完单转化率'].mean()# 0.8662754886794329
rawdata[rawdata['完单转化率']<0.6]
import pandas as pd
import numpy as np
from pyecharts.charts import*import pyecharts.options as opts
import collections
col=['星期','时段','司机在线','冒泡数','呼叫数','应答数','完单数','呼叫转化率','应答转化率','完单转化率','乘客司机比']
rawdata_cor=rawdata[col]# 映射为数值类型
name_to_week ={'周一':1,'周二':2,'周三':3,'周四':4,'周五':5,'周六':6,'周日':7}# rawdata_cor['星期']=rawdata_cor['星期'].map(name_to_week)
rawdata_cor.loc[:,'星期']=rawdata_cor.loc[:,'星期'].map(name_to_week)# 用这种方式会更好
rawdata_cor
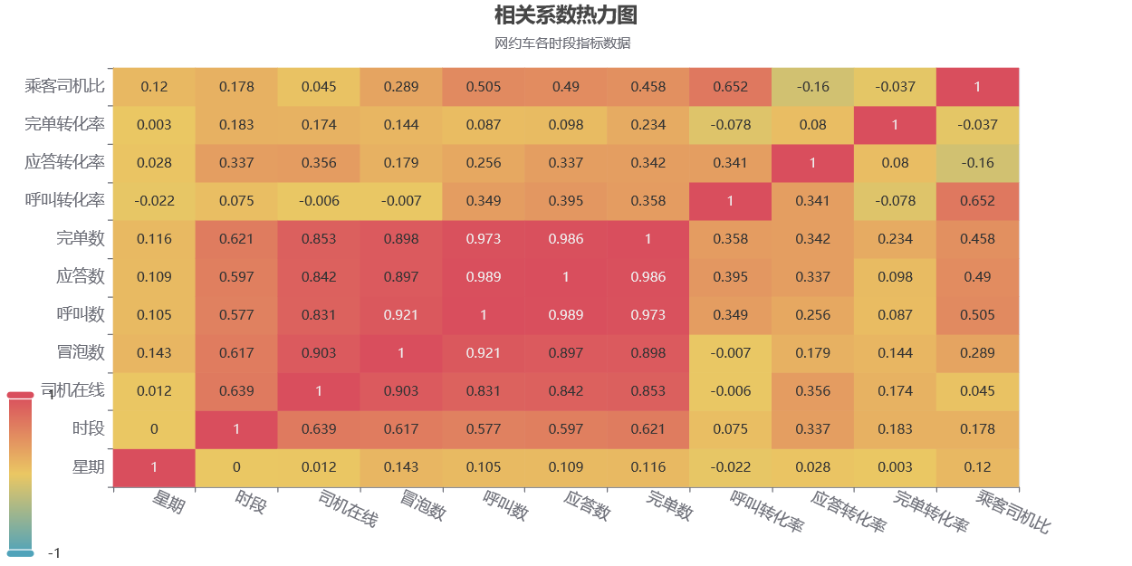
dff_corr=rawdata_cor.corr()
rows = dff_corr.index.size
cols = dff_corr.columns.size
# 热力图所需数据
dff_corr_heatmap =[[i, j,round(float(dff_corr.iloc[i, j]),3)]for i inrange(rows)for j inrange(cols)]
c =(
HeatMap(
init_opts=opts.InitOpts(
width='1000px',)).add_xaxis(dff_corr.index.tolist()).add_yaxis('相关系数',
dff_corr.columns.tolist(),
dff_corr_heatmap,
label_opts=opts.LabelOpts(
is_show=True,
position='inside'),).set_global_opts(
title_opts=opts.TitleOpts(
title='相关系数热力图',
subtitle='网约车各时段指标数据',
pos_left='center'),
legend_opts=opts.LegendOpts(
is_show=False,),
xaxis_opts=opts.AxisOpts(
type_='category',
splitarea_opts=opts.SplitAreaOpts(
is_show=True,
areastyle_opts=opts.AreaStyleOpts(
opacity=1)),
axislabel_opts=opts.LabelOpts(
font_size=14,
rotate=-25,),
interval=0),
yaxis_opts=opts.AxisOpts(
name='',
type_='category',
splitarea_opts=opts.SplitAreaOpts(
is_show=True,
areastyle_opts=opts.AreaStyleOpts(
opacity=1)),
axislabel_opts=opts.LabelOpts(
font_size=14),
interval=0,# position='right'),
visualmap_opts=opts.VisualMapOpts(
min_=-1,
max_=1,# is_show=False,)))
c.render_notebook()
2. 最高点回落速度
rawdata[(rawdata['城市']=='E市')&(rawdata['完单转化率']>0.9)]['乘客司机比'].describe()
count 67.000000
mean 0.982520
std 0.304556
min 0.472162
25% 0.744118
50% 1.017183
75% 1.194638
max 1.759997
Name: 乘客司机比, dtype: float64
版权归原作者 IT从业者张某某 所有, 如有侵权,请联系我们删除。