
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
1. 项目简介
本项目利用网络爬虫技术从某蔬菜网采集所有农产品的价格数据,包括北京、上海、安徽、湖北等全国所有省和直辖市的农产品价格数据,解析后存储到数据库中。 建立农产品价格数据仓库,以web交互形式对外提供检索服务,并利用 echarts 实现农产品的可视化分析。
2. 功能组成
基于大数据的农产品价格信息监测分析系统的主要功能包括:
- 使用Scrapy框架爬取多个农产品价格交易网站进行采集;
- 将爬取到的农产品价格信息等多个重要数据如:品类、产地、时间、价格等存储到数据库中,农产品种类至少20种。
- 使用python/kettle工具对多方数据进行合并清洗整理,建立数据仓库
- 使用echart+web对数据进行可视化检测与分析
- 创建web界面能够注册登录网页,可在爬取到的众多农产品中使用查询产地、查询产品名称等方式搜索和点击选择一种农产品进行分析图查看。
- 具体分析图有:价格变化折线图、产地均价、最高、最低、平均、产品种类和价格关系图、数量分布图、产地价格对比图等10个左右,具体图表内容可以协商。
- 采用机器学习中的回归算法根据大豆和玉米的时间价格对猪肉进行预测。
- 爬虫能自动定时爬取数据添加到数据仓库中。
3. 农产品数据采集
针对某农产品信息网站,利用 request + beautifulsoup 编写原生网络爬虫,完成数据的采集和清洗,并存储到数据库或文件系统中:
for alink in alinks:
sheng_urls = {}
for sheng in sheng_code:
product_url = 'http://www.xxxxxx.com/{}/m12d-1cta{}by-1p{}.html'.format(alink['href'], sheng_code[sheng], '{}')
sheng_urls[sheng] = product_url
product = alink.text[:-2]
product_sheng_urls[product] = sheng_urls
for product in product_sheng_urls:
for sheng in product_sheng_urls[product]:
pro_sheng_count = 0
print('抓取 {} {} 的价格数据'.format(sheng, product))
base_url = product_sheng_urls[product][sheng]
for page in range(1, 1000):
try:
url = base_url.format(page)
resp = requests.get(url)
resp.encoding = 'utf8'
soup = BeautifulSoup(resp.text, 'lxml')
table = soup.select('table.m_t_5')[0]
table = table.find('table')
trs = table.find_all('tr')
for tr in trs:
tds = tr.find_all('td')
name = tds[0].text
low_price = float(tds[2].text[1:].strip())
high_price = float(tds[3].text[1:].strip())
mean_price = float(tds[4].text[1:].strip())
pub_time = tds[5].text
product_info = [product, sheng, name, low_price, high_price, mean_price, pub_time]
insert_product_infos.append(product_info)
pro_sheng_count += 1
if len(insert_product_infos) % 10 == 0:
cursor.executemany(insert_sql, insert_product_infos)
conn.commit()
insert_product_infos.clear()
except:
pass
# 获取最多的页数
try:
max_page = int(soup.find('div', attrs={'id': 'pager'}).span.b.text)
if max_page == page:
break
time.sleep(0.5)
except:
break
print('共计 {} 条'.format(pro_sheng_count))
4. 基于大数据的农产品价格信息监测分析系统
4.1 系统首页注册登录
4.2 全国各地区不同农产品价格数据分析

4.3 不同农产品价格价格对比分析

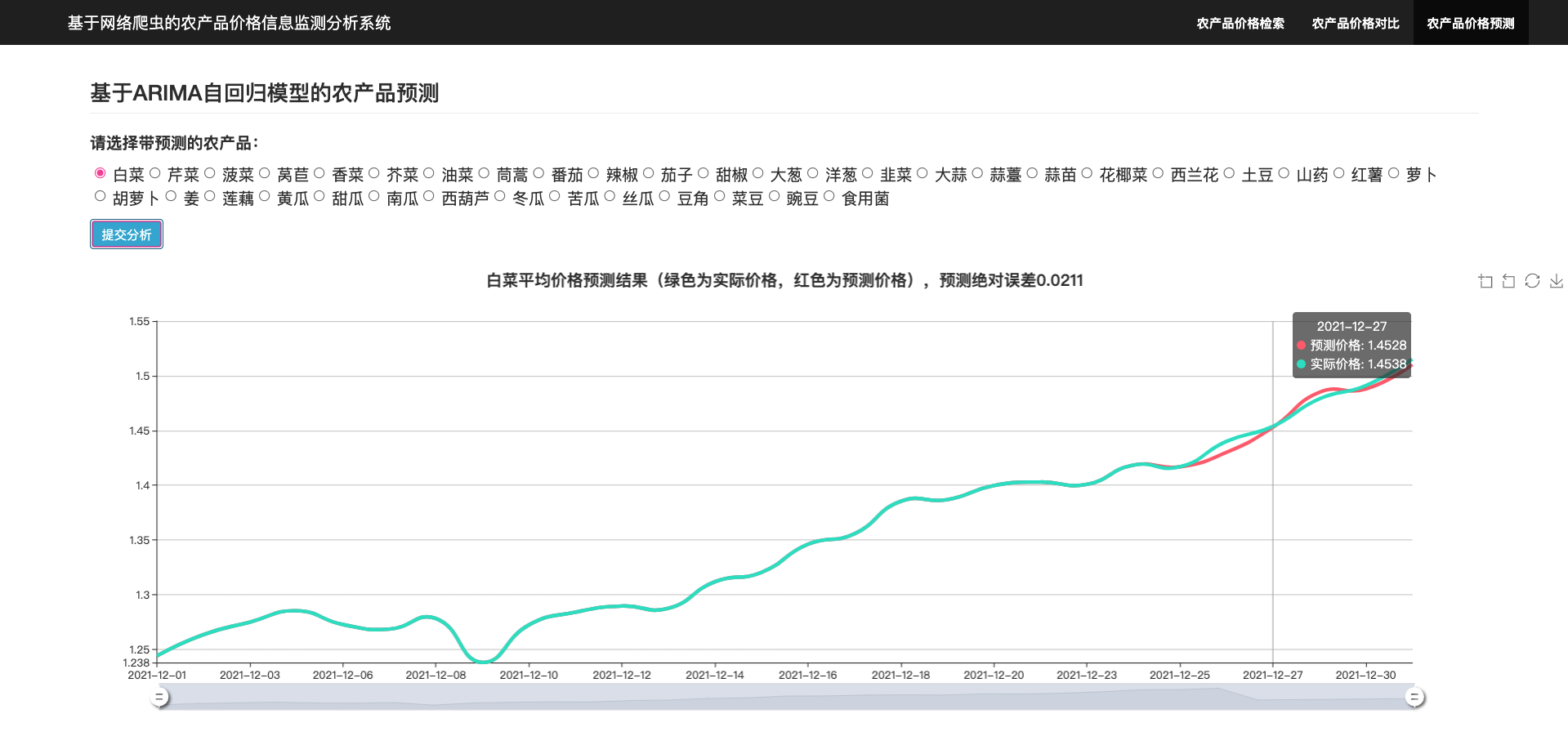
4.4 基于ARIMA自回归模型的农产品预测
5. 总结
本项目利用网络爬虫技术从某蔬菜网采集所有农产品的价格数据,包括北京、上海、安徽、湖北等全国所有省和直辖市的农产品价格数据,解析后存储到数据库中。 建立农产品价格数据仓库,以web交互形式对外提供检索服务,并利用 echarts 实现农产品的可视化分析。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例

本文转载自: https://blog.csdn.net/andrew_extra/article/details/125625816
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。