
One-shot就能做事件抽取?ChatGPT在信息抽取上的强大应用
0. 前言
近期,OpenAI发布的chat GPT可谓是各种刷屏,很多人都在关注这种模式是否可以应用于搜索引擎,这给做搜索的朋友们带来了很大的危机感。然而,我尝试用它做信息抽取,也得到了让我感到非常害怕的结果。本文就结合一个简单的例子,来聊一聊chat GPT在信息抽取上的使用。
1. 灵感
事情的起因是Blender Lab的一篇论文,《CODE4STRUCT: Code Generation for Few-Shot Structured Prediction from Natural Language》,做的是事件论元抽取(EAE,Event Argument Extraction),我看到这个题目的时候,第一反应就是应该跟UIE的前身Text2Event (Lu et al., 2021)比较相似,果然在大概读了一下这篇论文之后,发现论文对比的工作主要就是这三个:
- DEGREE (Hsu et al., 2022)
- BART-Gen (Li et al., 2021)
- Text2Event (Lu et al., 2021)
其中,后两者我都读过论文,也实验过,第一个DEGREE暂时还没有了解。另外值得一提的是本文的作者也是BART-Gen的作者。
说回这篇论文,目的就是通过一个生成式的模型,实现从非结构化的文本,到“伪结构化”的文本,然后再解码出事件,主要创新点在于,没有直接用template+text组合的范式作为输入文本,而是把输入写到了代码的注释里,借助OpenAI的CODEX (Chen et al., 2021) ,去生成一段代码,其中代码里的内容是事件的论元。
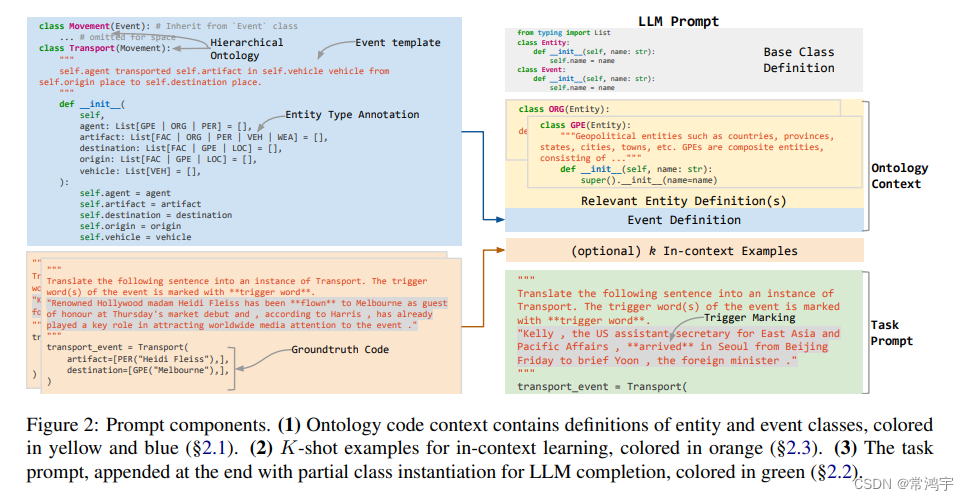
从图中可以看出,code4structure的输入会非常长,包括了schema的定义,给出的例子,以及写在注释里的原文。
整篇论文浏览下来,发现作者似乎并没有提出创新性的模型,只是在任务范式上进行了转换,在模型上完全是调用了Codex的API。在之前的博客《(杂谈)世界上本没什么prompt,有的只是加权平均——关于NLP中embedding的一点思考》中,我们探索了prompt在做什么,其本质是prompt中提供了若干“锚点”,以学习其他token的表征。所以这篇文章做的工作,在我看来是显而易见能够收到这样一个结果的,因为这个模型已经训练的足够强大。
那么说回这个Codex,我之前对它完全没有了解,去查了一下发现也是openAI做出来的,其模型也是采用的GPT-3,训练样本主要是GitHub里的一些开源项目。
那么问题来了,如果Codex可以用来做事件抽取,那chatGPT应该也没有问题吧?
2. 实验
带着这个想法,我从同事那里借来了一个openAI的账号,chat GPT能不能完成任务。
在这里我没有直奔主题,直接输入文本让它抽取,因为之前看到有人介绍这个模型是会考虑之前交互的所有内容的,包括你的问题和它给出的答案,所以最好是一步步的引导它。
于是我先问它知不知道事件抽取相关的概念:
回答的挺不错的,然后进一步引导,因为我马上要给schema了,就先让它解释一下schema:
接下来就是主要部分了,以ACE2005中的事件模式为例。我先告诉它,schema是什么,然后给它一个例子,告诉它,我给你这样一句话,你应该给我输出什么,最后把输入文本告诉它,让它给出相应的输出: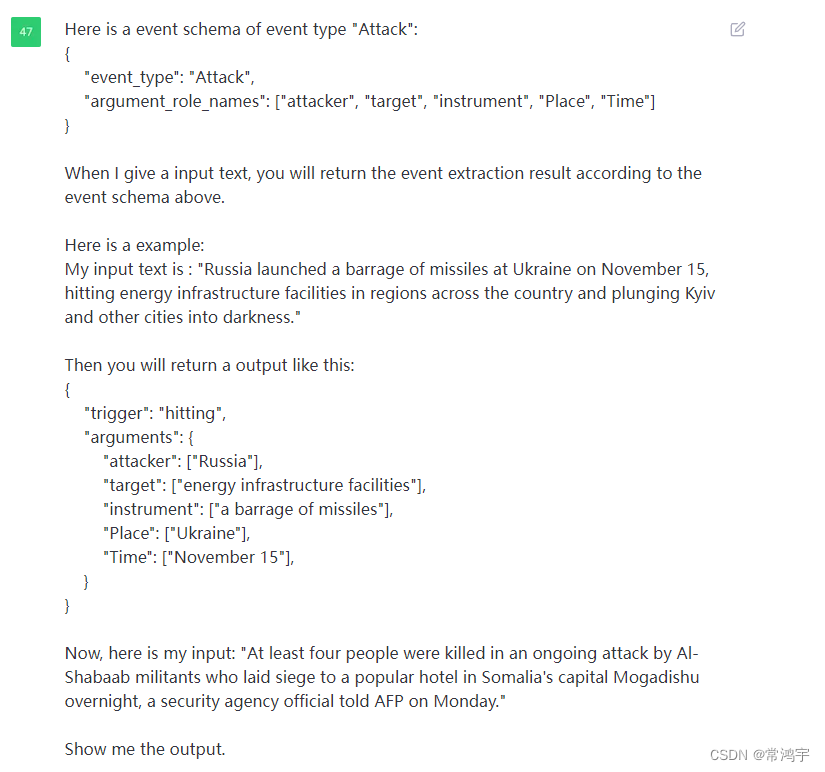
这个模型可以接收的输入挺长的,可以放心给。其实我给的这一场段话,都可以理解为所谓的“prompt”。
这是模型给出的回答,可以看到效果是相当不错的,也就是说,我们完全可以利用chatGPT实现one-shot的事件抽取,这是一件相当可怕的事情,对之前的信息抽取研究简直就是降维打击。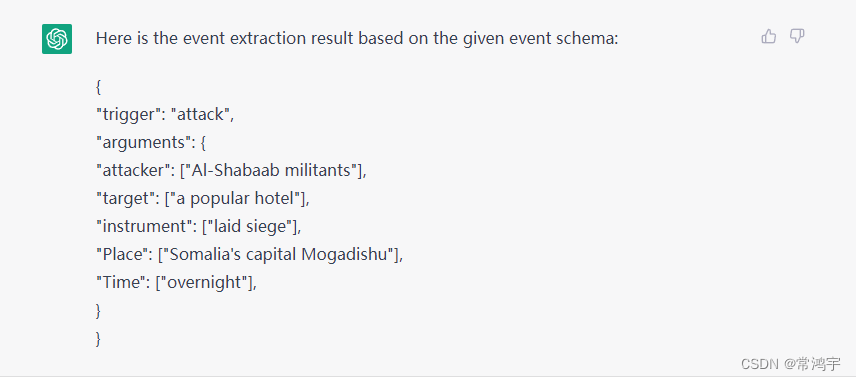
应用在信息抽取中,这个模型可怕的地方,不仅在于one-shot,还有以下两点:
- 它会保留之前的对话信息;
- 它会在与用户的交互中轻松实现纠正。
对于第一点,我在介绍清楚了任务范式之后,接下来的抽取,就不再需要每次描述一遍我的schema了:
可以看到,我给一句话的输入,它直接就给我返回输出结果了。
并且,我觉得Place和target论元它抽取的不太对,好像是对我的例子理解的有问题,因为我只给了它一个例子,在那个例子中,所有的角色都能找到相应的论元。所以我又告诉它,如果哪个角色没有论元的话,你给我保留为空就行:
然后它就很聪明的学会了:
接下来,再来一个例子检验一下:
效果已经很不错了,但是这个opened fire,我认为不是instrument,所以我再跟模型强调一下:
到这里,模型所能够输出的效果,已经比我之前有监督训练的模型更好了,让我忍不住自我怀疑,之前到底训练了个什么东西,在大样本预训练模型面前竟然如此不堪一击。
3. 结论
事件抽取作为信息抽取中比较难的任务,已经很轻松的被chat GPT拿下了,我相信不仅是我,很多从业者,包括这两年在三大顶会上发表过很多文章的大佬,或多或少都会有一些自我怀疑。这也给我们提了个醒,仅仅依靠范式迁移做的所谓创新,其实并没有什么实际价值,从应用层面上已经被大预料大模型吊打,而从模型结构的改进而言,似乎也没有什么征兆显示短期内有什么结构可以取代transformer。
并不是说chatGPT已经是一个非常成熟的应用,马上就要颠覆这个颠覆那个,但是不可否认的是,对于信息抽取这样高度结构化的“简单”任务,大模型是很容易handle的。在prompt的范式下,输入的目标文本中的每个token可以与用户的其他描述性的输入发生更多的交互,而在大模型足够多参数加持下,这一优势似乎会被放大很多。
但是从模型给出的结果可以看出,它除了把我想要的答案给出了之外,还给了一些解释,其实这些解释我是不想要的。那么对于应用来讲,可能需要做一些restructure的工作,或许将来某一天,等大模型更成熟一些,这类restructure的工作也可以省略了。
版权归原作者 常鸿宇 所有, 如有侵权,请联系我们删除。