
语音识别是通用人工智能的重要一环!可以说是AI的耳朵!
它可以让机器理解人类的语音,并将其转换为文本或其他形式的输出。
语音识别的应用场景非常广泛,比如智能助理、语音搜索、语音翻译、语音输入等等。
然而,语音识别也面临着很多挑战,比如不同的语言、口音、噪音、专业术语等等,都会影响语音识别的准确性和鲁棒性。
为了解决这些问题,OpenAI开源了语音识别系统: Whisper
目前在开源网站上已收获5w星!
它号称其英文语音辨识能力已达到人类水准,且它亦支持其它98种语言的自动语音辨识。
** Whisper是什么?**
Whisper是由研发出ChatGPT的OpenAI的研究团队开发的,OpenAI的研究成果也经常引起广泛的关注和讨论,比如GPT系列的预训练语言模型、DALL-E的图像生成模型、CLIP的图像分类模型等等。
Whisper的主要作者是Jong Wook Kim,他是OpenAI的研究科学家,他的研究兴趣是语音处理、自然语言处理和机器学习。
Whisper 架构是一种简单的端到端方法,以编码器-解码器 Transformer 的形式实现。输入音频被分成 30 秒的块,转换为对数梅尔频谱图,然后传递到编码器。
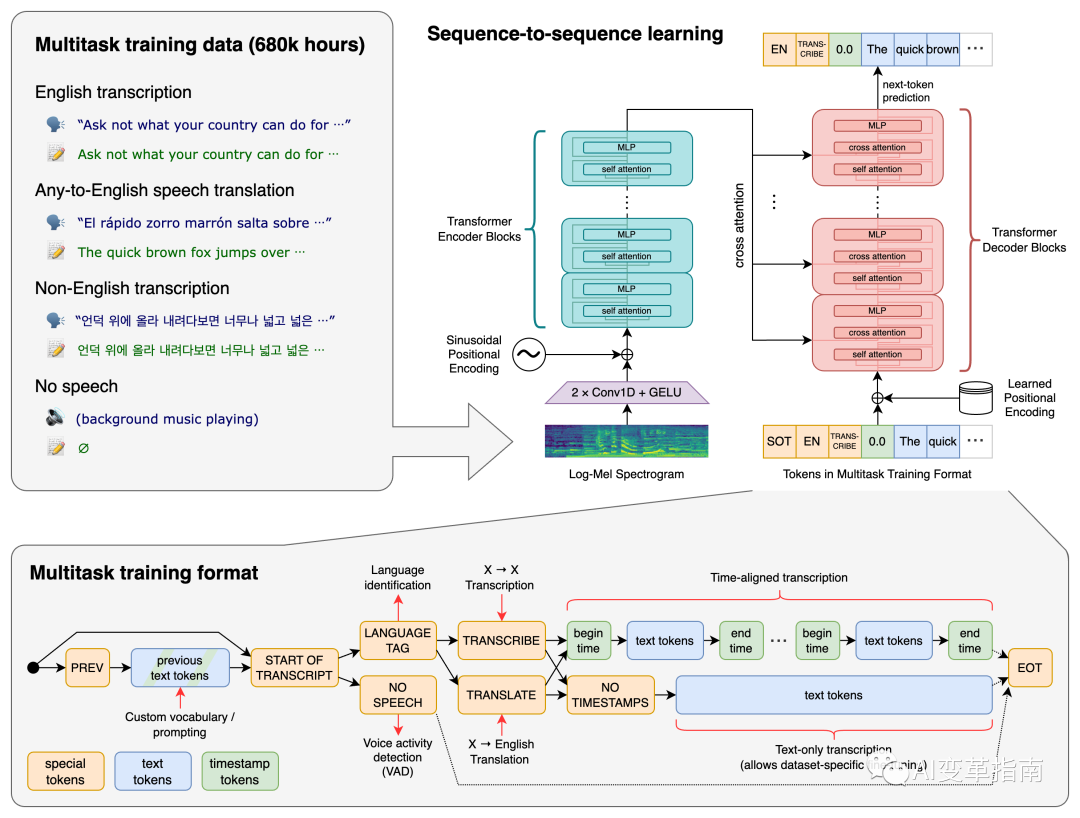
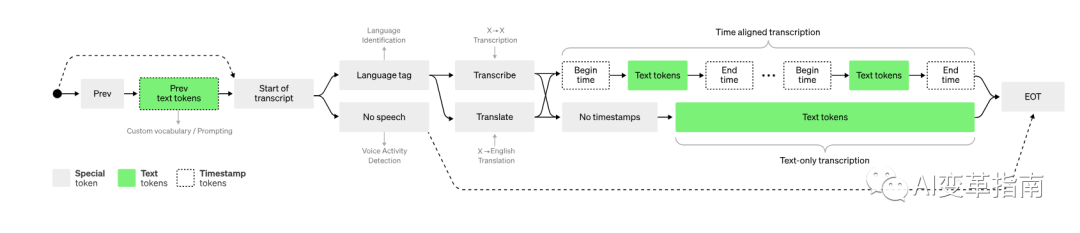
解码器经过训练来预测相应的文本标题,并与特殊标记混合在一起,指导单个模型执行语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。
Whisper的惊艳功能
Whisper的最大特点是它的多语言和多任务能力,它可以同时处理多种语言和多种任务,而不需要针对每种语言或任务单独训练或调整模型。Whisper目前支持的语言有99种,包括英语、中文、日语、法语、德语、西班牙语等等,覆盖了世界上大部分的人口和地区。
Whisper目前支持的任务有四种,分别是:
多语言语音识别(Multilingual Speech Recognition):将语音转换为与语音相同语言的文本,比如将英语语音转换为英语文本,或者将中文语音转换为中文文本。
语音翻译(Speech Translation):将语音从一种语言翻译成另一种语言的文本,比如将英语语音翻译成中文文本,或者将中文语音翻译成英语文本。
语言识别(Language Identification):识别语音中的语言类型,比如判断语音是英语还是中文,或者是其他语言。
语音活动检测(Voice Activity Detection):检测语音中的活动区域,即语音中有人说话的部分,和没有人说话的部分。
Whisper的创新之处在于,它可以让人工智能学习和使用语境,从而提高和人类的沟通质量。Whisper的工作原理是,它会根据人类的输入,生成一个语境向量,这是一个包含了语境信息的数学表示。
然后,它会用这个语境向量来指导人工智能的输出,使其更加符合人类的期望。Whisper的优点是,它可以和任何类型的人工智能模型配合使用,无论是文本,图像,音频,视频,还是其他的形式。Whisper还可以让人工智能适应不同的语境,比如不同的场景,不同的任务,不同的用户,不同的风格,等等。
** Whisper的性能**
Whisper的这些功能不仅强大,而且准确和鲁棒。Whisper的英文语音识别的准确率已经达到了人类的水平,甚至在一些嘈杂的环境中,还超过了人类的水平。Whisper的多语言语音识别和语音翻译的准确率也非常高,甚至在一些零样本的情况下,也能够表现出色。
Whisper 的性能因语言而异。下图显示了按语言large-v3和模型的性能细分,使用在 Common Voice 15 和 Fleurs 数据集上评估的large-v2WER(单词错误率)或 CER(字符错误率,以斜体显示)。
与其他模型和数据集相对应的其他 WER/CER 指标可以在论文的附录 D.1、D.2 和 D.4 中找到,以及附录 D 中的 BLEU(双语评估研究)翻译分数。
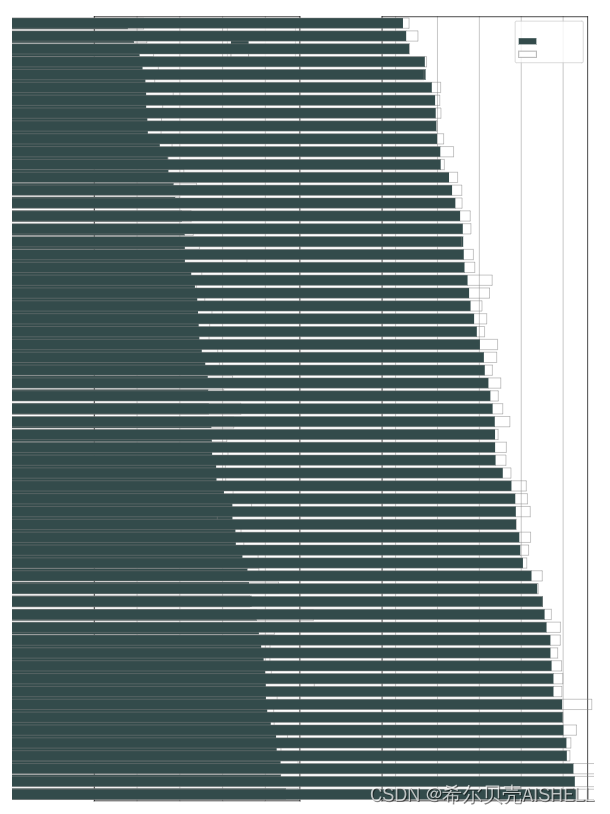
Whisper的性能不仅在实验室的环境中得到了验证,也在实际的应用场景中得到了证明。Whisper已经被应用在了OpenAI的一些项目中,比如GPT-4的语音输入,CLIP的语音分类等等。
代码地址:
论文地址:
博文地址:
版权归原作者 希尔贝壳AISHELL 所有, 如有侵权,请联系我们删除。