
引言
OpenAI最新发布的Sora效果惊为天人,除了阅读研究原文(openai.com/research/video-generation-models-as-world-simulators)之外,其引用的32篇参考文献也是了解对应技术路线的重要信息。借此机会,也顺便探索一下整个AI论文的工作应该是什么样子的?AI可以如何帮助我们快速地获取、总结并复现论文。
不瞒你说,春节放大假当我还沉浸在老头环的世界里面时,我大概是被Sora一下子给拍醒了的,才又想起来自己有多少在AI领域想要探索的事情还没搞完。所以接着Sora的热度,干脆来一波论文信息整理,同时探索一下AI论文阅读的工作流。
AI论文阅读工作流
一位开智同学在群里说到:
目前使用GPT(s)阅读学术论文时会发现,没有很好的工具帮助你阅读和总结内容。即使同时用上GPT4,Scholar GPT等效果都不是很好。总结内容空泛,抓不住重点。
的确如此,就算上传了原文,读取也是成功的,我们依然很难完全依赖AI去读论文,但我觉得可以缩短读一篇论文,或者分析多篇论文的时间。那一篇论文的阅读来举例,AI领域的论文多数涉及到所用的数据集、算法、算法验证效果等内容。因此单篇论文的AI工作流相对容易跑通。输入单篇论文,无需解决复杂难搞的文件格式的前提下,先对论文进行总结,分析QA,提取公开数据集和程序集,再进一步用伪代码或真代码来复现论文所作研究。进一步直接在本地机器将找到的数据集和代码抓取下来,通过intrepretor写出程序并试运行。若站在信息分析角度来看,更需要的是批量分析。比如说30多篇论文的作者分布,关键词分布,则需要借助更多文献计量领域的工具来配合使用。
因此这篇文章展开的逻辑如下:
首先,以Sora这篇研究原文为样板,尝试跑通从参考文献列表到Zotero这一步;
第二,从输入到输出分析其中可自动化的部分;
第三,以单片论文为样板,尝试建立一个稳定的工作流;
第四,复盘整个过程,想想到底应该如何让AI辅助我们更好地阅读论文
第一步:论文全文获取
输入:
期望结果:自动下载所有原文pdf
更进一步:自动导入Zotero
操作路径分两种:
- 引文导入Zotero,通过Zotero的功能来自动找到并下载原文
- 通过AI工具去检索并找到原文,批量拖入Zotero之后再提取元数据
第一种路径看似更完善,需要手动操作的不多,但引文导入Zotero并没有想象中简单。需要先利用GPT将非规范的参考文献转换成Zotero RDF格式,利用插件找到对应DOI(只找到了其中6篇),有了DOI之后使用Find Available PDF从Sci-Hub下载文献。此操作参考:https://zhuanlan.zhihu.com/p/112391476
第二种路径的尝试如下
尝试1:将以上ref塞入perplexity.ai让其自动帮我找到所有原文链接不太理解,基本只能找到前四篇,然后循环生成了回答。
![[Pasted image 20240217091826.png]]
尝试2:使用GPTs提取原文
- Consensus 无法帮助找到原文pdf
- Scholar GPT - 第一轮对话只找到前两篇- 回复Continue之后陆续找到了5-12篇,13-17篇论文链接,继续回复Continue又从第一篇论文开始检索了,对于需要批量操作而言不太理想
整合perplexity和Scholar GPT给到的原文再塞进Zotero里面去重后,得到24个条目,还缺了13,14,18,21,22,24,25,30这八篇。
其中除了Attention is All You Need这篇经典之外,其余7篇中的6篇从预印本网站arxiv.org都能找到,但arxiv自带的搜索实在有点拉胯,有时候直接贴入bing中检索反而会更准确。
总的来说,还是直接拿到原文再放入Zotero的操作会相对简便,元数据更齐全,也不用考虑多轮批量操作之后还需要去重等操作,特别是去重时涉及到不同的条目类型还得一个个去整合,非常麻烦。
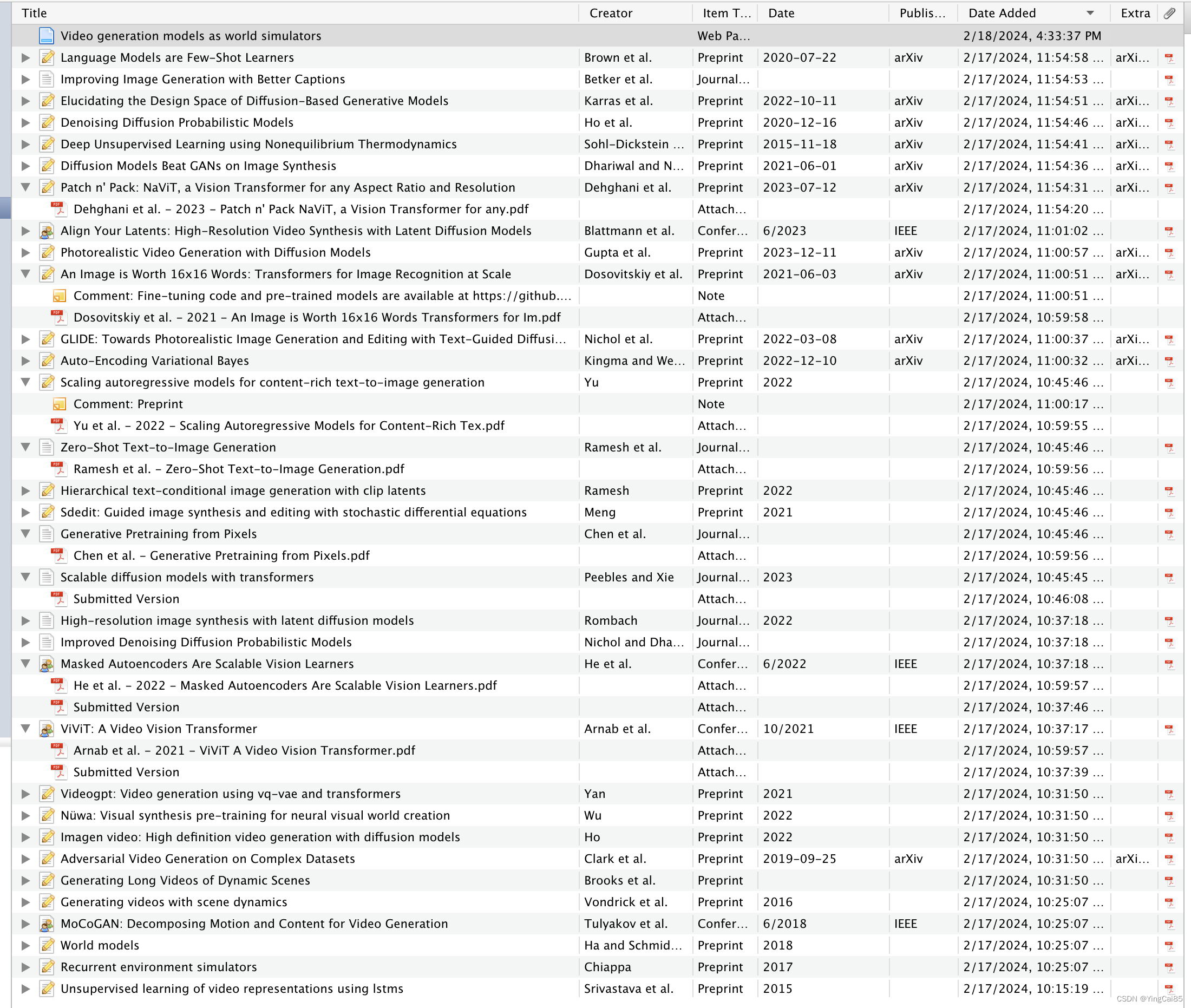
第二步:AI总结
我们在Research原文中找到这一段引用较多的说明:
Sora is a diffusion model21,22,23,24,25; given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer.26 Transformers have demonstrated remarkable scaling properties across a variety of domains, including language modeling,13,14 computer vision,15,16,17,18 and image generation.27,28,29
其中可以看出Diffusion扩散模型相关的论文是 21/22/23/24/25
Diffusion Transformer的论文是 26
关于Transformer语言建模能力是 13/14
关于Transformer计算机视觉能力是 15/16/17/18
关于Transformer图像生成能力是 27/28/29
先拍个脑袋猜出大概的论文重要优先级,然后使用月之暗面来帮忙总结论文内容。
优先级:
26-单独分析
15/16/17/18-成组分析
27/28/29-成组分析
以下均为月之暗面整理内容
26-Scalable Diffusion Models with Transformers
AI创作分界线
这篇论文的标题是《Scalable Diffusion Models with Transformers》,作者是William Peebles和Saining Xie,来自加州大学伯克利分校和纽约大学。论文探讨了基于Transformer架构的一类新型扩散模型(Diffusion Transformers,简称DiTs),这些模型用于训练图像的潜在扩散模型,并用Transformer替换了常用的U-Net架构作为模型的骨干网络。研究的主要内容包括:
- 研究背景:Transformer架构在自然语言处理和视觉领域取得了巨大成功,但在图像生成模型中的应用相对较少。尽管扩散模型(Diffusion Models)在图像生成领域取得了显著进展,但它们通常采用卷积U-Net架构。作者旨在探索Transformer在扩散模型中的应用,并提供实证基准,以促进未来生成模型研究。
- DiTs架构:DiTs遵循Vision Transformers(ViTs)的最佳实践,这些模型在视觉识别任务中比传统卷积网络更有效地扩展。DiTs在潜在空间(latent space)中训练,通过变分自编码器(VAE)的潜在空间来训练扩散模型,而不是直接在像素空间训练。
- 模型设计:DiTs包括“patchify”层,将空间表示(来自VAE的噪声潜在表示)转换为一系列令牌(tokens),然后通过一系列Transformer块进行处理。这些块可以处理噪声时间步长、类别标签等条件信息。作者探索了四种不同的Transformer块设计,包括上下文条件(in-context conditioning)、交叉注意力(cross-attention)、自适应层归一化(adaLN)和adaLN-Zero。
- 实验设置:在ImageNet数据集上训练了不同配置的DiT模型,包括256×256和512×512分辨率的图像。使用AdamW优化器进行训练,没有权重衰减和学习率预热。评估指标包括Fréchet Inception Distance(FID)、Inception Score、sFID和Precision/Recall。
- 实验结果:DiT模型在ImageNet 256×256和512×512分辨率的类条件图像生成任务上取得了最先进的FID结果。特别是,DiT-XL/2模型在256×256分辨率上达到了2.27的FID,这是该任务的最佳成绩。此外,DiT模型在计算效率上也优于基于U-Net的扩散模型。
- 结论:DiTs展示了Transformer架构在扩散模型中的有效性和可扩展性。未来的工作应该继续扩展DiTs到更大的模型和更多的令牌计数。DiTs也可能作为文本到图像模型(如DALL·E 2和Stable Diffusion)的替代骨干网络进行探索。
论文还提供了详细的模型实现细节、训练损失曲线、VAE解码器的消融研究以及扩散U-Net模型的复杂度比较。
研究者William Peebles和Saining Xie做了一项研究,他们想要探索一种新的人工智能模型,这种模型可以帮助电脑生成更逼真的图片。在人工智能领域,生成图片的模型就像是画家,它们可以根据给定的信息(比如一个类别标签,比如“猫”)来画出相应的图片。以前,这种类型的模型主要使用一种叫做U-Net的结构,但这次,他们尝试用一种叫做Transformer的结构来替代U-Net。
Transformer是一种特别强大的工具,它在处理语言和图像识别任务时表现出色。研究者们想知道,如果用Transformer来生成图片,效果会不会更好。他们设计了一系列的实验,用不同的Transformer模型来生成图片,并观察这些模型的表现。
他们发现,使用Transformer的模型(他们称之为DiTs)在生成图片的质量上确实有所提升,尤其是在处理高分辨率图片时。他们的最大模型DiT-XL/2在生成256×256分辨率的图片时,达到了当时最好的成绩,FID(一种衡量生成图片质量的指标)降到了2.27。这就像是在画画比赛中,他们的“画家”画出的画更接近真实世界的照片。
最关键的成果是,他们证明了Transformer不仅在处理语言和图像识别任务上有优势,而且在生成图片方面也有很大的潜力。这为未来的研究提供了新的方向,比如可以用Transformer来改进现有的图像生成模型,或者开发新的应用,比如根据文字描述生成图片的系统。
总的来说,这项研究展示了Transformer在图像生成领域的强大能力,并为未来的人工智能研究提供了新的思路。
尽管这项研究取得了显著的成果,但任何科学研究都有其局限性,这篇论文也不例外。以下是一些可能的局限性:
- 模型复杂性:DiTs模型在生成高质量图片方面表现出色,但这些模型通常非常复杂,需要大量的计算资源。这可能导致训练和部署这些模型的成本较高,尤其是在没有高性能计算资源的情况下。
- 训练数据依赖:DiTs模型的性能很大程度上依赖于训练数据的质量和多样性。如果训练数据存在偏差或者不够多样化,生成的图片可能无法准确反映现实世界的多样性。
- 泛化能力:虽然DiTs在ImageNet数据集上表现出色,但这并不意味着它们在其他类型的图像生成任务上也能同样出色。模型的泛化能力,即在未见过的数据上的表现,是评估其实用性的重要指标。
- 生成过程的可控性:DiTs模型在生成图片时,可能难以实现对生成内容的精确控制。例如,用户可能希望生成特定风格或情感的图片,但模型可能难以理解这些细微的差别。
- 计算效率:尽管DiTs在生成高分辨率图片方面取得了进步,但它们在计算效率上可能仍有提升空间。在实际应用中,尤其是在资源受限的环境中,如何平衡生成质量和计算效率是一个挑战。
- 模型解释性:Transformer模型通常被认为是“黑箱”模型,这意味着它们的内部工作机制难以解释。这在需要模型可解释性的应用场景中可能是一个问题。
- 潜在的偏见和伦理问题:生成模型可能会无意中复制或放大训练数据中的偏见,这在生成涉及人类形象的图片时尤其值得关注。
这些局限性指出了未来研究的方向,包括如何优化模型以提高计算效率、增强模型的泛化能力、提高生成内容的可控性,以及确保模型的公平性和可解释性。
OpenAI提到的技术报告中提到的两个重点(1)将所有类型的视觉数据转化为统一的表示形式,以及(2)对Sora模型的能力和局限性进行定性评估,确实与DiTs论文中探讨的一些概念相呼应。特别是,DiTs论文中提到了使用Transformer架构来处理图像数据,并在潜在空间中训练生成模型,这与OpenAI报告中提到的“将视觉数据转化为统一表示”的目标相似。
然而,仅凭这些信息,我们不能确定Sora的技术路径是否直接借鉴了DiTs的方法。OpenAI的报告指出模型和实现细节没有包含在内,这意味着他们可能采用了与DiTs相似的概念,但在实际的模型设计、架构、训练方法等方面可能有所不同。在人工智能领域,研究者经常会受到其他研究的启发,但具体的实现可能会根据项目的需求和目标进行调整。
为了确定Sora是否确实借鉴了DiTs的方法,我们需要查看OpenAI发布的更详细的技术文档或研究论文,这些文档通常会提供更具体的模型架构、训练过程和实验结果。如果OpenAI在后续的研究中明确提到了DiTs或其方法,那么我们可以更有信心地说Sora的技术路径受到了DiTs的影响。
15/16/17/18-Vision Transformer
附件中的论文集主要探讨了Vision Transformer(ViT)及其变体在计算机视觉领域的应用和扩展。以下是对这些内容的总结:
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE:- 提出了Vision Transformer(ViT),这是一种直接应用于图像分类任务的纯Transformer模型。- 通过在大规模数据集上预训练,ViT在多个图像识别基准测试中取得了与卷积神经网络(CNN)相媲美或更好的结果。- ViT通过将图像分割成小块(patches),并将这些小块线性嵌入到Transformer的输入序列中,类似于自然语言处理(NLP)中的词嵌入。- 在ImageNet、CIFAR-100和VTAB等数据集上的实验表明,ViT在预训练规模足够大时,能够实现优秀的性能。
- ViViT: A Video Vision Transformer:- 提出了ViViT,这是一种基于Transformer的视频分类模型,它从输入视频中提取时空令牌(spatiotemporal tokens)。- ViViT通过一系列Transformer层对这些令牌进行编码,以处理视频数据。- 为了提高效率,ViViT提出了几种方法来分解模型的空间和时间维度。- 在Kinetics 400和600、Epic Kitchens、Something-Something v2和Moments in Time等视频分类基准测试中,ViViT取得了最先进的结果。
- Masked Autoencoders Are Scalable Vision Learners:- 介绍了一种名为Masked Autoencoder(MAE)的自监督学习方法,它通过遮蔽输入图像的随机块并重建缺失像素来训练模型。- MAE采用了非对称的编码器-解码器架构,其中编码器仅处理可见的图像块,而轻量级的解码器则从潜在表示和遮蔽令牌重建原始图像。- MAE在ImageNet-1K数据集上展示了其可扩展性,通过预训练,可以在下游任务中实现优于监督预训练的结果。
- Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution:- 提出了NaViT(Native Resolution ViT),这是一种灵活的Vision Transformer,可以在训练过程中处理任意分辨率和宽高比的输入。- NaViT通过“Patch n’ Pack”技术,将来自不同图像的多个块打包成一个序列,从而在保持宽高比的同时实现可变分辨率。- NaViT在大规模监督和对比图像-文本预训练中展示了改进的训练效率,并在图像和视频分类、目标检测和语义分割等下游任务中取得了优异的结果。
这些论文展示了Vision Transformer在图像和视频理解任务中的潜力,以及通过自监督学习和灵活的模型设计来提高效率和性能的方法。ViT及其变体正在推动计算机视觉领域向更灵活、更高效的模型发展。
OpenAI的最新研究提到了"Sora",这是一个基于视觉块(visual patches)的模型,它与大型语言模型(LLMs)中的文本标记(text tokens)相对应。这里提到的视觉块(patches)在之前的四篇论文中都有涉及,特别是在Vision Transformer(ViT)的背景下。以下是OpenAI研究与这四篇论文之间的具体关系分析:
- 与ViT的关联:- OpenAI的研究提到视觉块(patches)作为有效表示,这与ViT的核心概念相呼应。ViT通过将图像分割成小块(patches),并将这些小块作为输入序列的标记(tokens)来处理图像数据。这表明OpenAI的研究可能借鉴了ViT在图像处理方面的成功经验。
- 与ViViT的关联:- ViViT是专门为视频分类设计的Vision Transformer,它处理视频数据的方式是通过提取时空块(spatiotemporal tokens)。OpenAI的研究提到在视频和图像上训练生成模型,这可能意味着Sora模型在处理视频数据时采用了类似ViViT的方法,即通过分析视频的时空特征。
- 与MAE的关联:- MAE通过遮蔽图像的随机块并重建缺失像素来训练模型,这与OpenAI提到的使用视觉块(patches)进行训练有相似之处。MAE展示了视觉块在自监督学习中的有效性,这可能为OpenAI在生成模型中使用视觉块提供了理论基础。
- 与NaViT的关联:- NaViT通过在训练过程中处理任意分辨率和宽高比的输入,展示了视觉块在处理多样化视频和图像数据中的可扩展性和有效性。OpenAI的研究提到Sora在视频和图像上的表现,这表明Sora可能采用了类似NaViT的灵活性,以适应不同分辨率和宽高比的输入。
总的来说,OpenAI的最新研究在视觉表示和处理方面与这四篇论文有紧密的联系。Sora模型可能结合了ViT、ViViT、MAE和NaViT中的视觉块(patches)表示和处理方法,以实现在多样化视频和图像数据上的有效训练和生成。这些论文为OpenAI提供了关于如何利用视觉块进行有效视觉表示和处理的宝贵经验。
27/28/29-text-to-image
附件中的论文主要介绍了三个不同的研究项目,它们都与图像生成和视觉表示学习有关。以下是对每篇论文内容的总结:
- Generative Pretraining from Pixels:- 作者: Mark Chen, Alec Radford, Rewon Child, Jeff Wu, Heewoo Jun, David Luan, Ilya Sutskever- 摘要: 这篇论文探讨了在图像领域应用无监督表示学习的方法,特别是通过训练一个序列Transformer来自回归地预测像素。尽管在没有标签的低分辨率ImageNet数据集上进行训练,但模型(GPT-2规模)能够学习到强大的图像表示,这通过线性探测、微调和低数据分类得到了验证。在CIFAR-10数据集上,使用线性探测达到了96.3%的准确率,超过了监督的Wide ResNet。在ImageNet上,通过VQ-VAE编码替换像素,达到了69.0%的准确率,与自监督基准相当。- 方法: 研究者们提出了一种预训练阶段,然后进行微调阶段的方法。预训练阶段探索了自回归和BERT目标。Transformer架构被用来预测像素而不是语言标记。通过微调,模型可以适应图像分类任务。此外,还使用了线性探测来评估表示质量。- 结果: 实验表明,更好的生成模型(以保留数据上的验证损失为衡量标准)也学习到了更好的表示。在CIFAR-10和CIFAR-100数据集上,模型在低数据分类任务上的表现超过了现有的方法。在ImageNet上,模型在微调后达到了66.3%的准确率。
- Zero-Shot Text-to-Image Generation:- 作者: Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever- 摘要: 这篇论文描述了一个基于Transformer的方法,用于零样本文本到图像生成。该方法通过自回归地模拟文本和图像标记作为单一数据流。通过足够的数据和规模,该方法在零样本评估中与特定领域的模型竞争。- 方法: 研究者们提出了一个两阶段训练过程。第一阶段使用离散变分自编码器(dVAE)将图像压缩为图像标记的网格。第二阶段,将文本标记与图像标记连接起来,训练一个自回归Transformer来模拟文本和图像标记的联合分布。- 结果: 该系统在MS-COCO数据集上实现了高质量的图像生成,零样本评估中,人类评估者在90%的情况下更喜欢该模型生成的图像。此外,该模型还能够执行图像到图像的翻译等复杂任务。
- Scaling Autoregressive Models for Content-Rich Text-to-Image Generation:- 作者: Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, Yonghui Wu- 摘要: 这篇论文介绍了Pathways Autoregressive Text-to-Image (Parti)模型,该模型能够生成高保真度的逼真图像,并支持内容丰富的合成,涉及复杂的组合和世界知识。Parti将文本到图像生成视为序列到序列的建模问题,使用图像标记序列作为目标输出。- 方法: Parti模型基于Transformer架构,使用ViT-VQGAN图像分词器将图像编码为离散标记序列。通过扩大模型规模(高达20B参数),实现了一致的质量提升,MS-COCO上的零样本FID得分为7.23,微调后的FID得分为3.22。- 结果: Parti模型在MS-COCO和Localized Narratives数据集上展示了强大的泛化能力,特别是在处理更长描述时。此外,研究者们还引入了PartiPrompts (P2),这是一个包含超过1600个(英语)提示的全面基准,用于衡量模型在不同类别和难度方面的性能。
这些论文展示了在图像生成和视觉表示学习领域的最新进展,特别是在利用大规模数据集和模型规模来提高生成图像质量和多样性方面。
Transformer模型最初是为处理序列数据设计的,特别是在自然语言处理(NLP)领域取得了巨大成功。然而,其核心优势在于其自注意力(self-attention)机制,这使得模型能够处理长距离的依赖关系,并且能够并行处理序列中的所有元素。这些特性使得Transformer模型不仅适用于语言,也适用于其他类型的序列数据,包括图像数据。
在图像生成任务中,图像可以被视为一个二维的像素序列。通过将图像像素转换为序列(例如,通过将图像分割成小块或使用像素级别的编码),Transformer就可以利用其自注意力机制来捕捉像素之间的复杂关系,从而生成新的图像内容。这种方法在图像生成、图像修复、风格迁移等任务中都显示出了潜力。
至于Transformer架构与Diffusion模型的区别,主要体现在它们生成图像的方式上:
- Transformer架构:- Transformer模型通常用于序列到序列(Seq2Seq)的任务,如文本到图像生成。在这种设置中,模型接收一个文本描述作为输入序列,并生成一个图像序列作为输出。- Transformer模型通过自注意力机制来捕捉输入序列(文本)和输出序列(图像)之间的复杂关系。- 在图像生成任务中,Transformer模型通常需要一个额外的图像编码器(如VQ-VAE或dVAE)来将图像转换为离散的标记,然后模型就可以处理这些标记序列。
- Diffusion模型:- Diffusion模型是一种基于概率过程的生成模型,它通过模拟一个从已知数据分布(如噪声)逐渐“扩散”到目标数据分布(如图像)的过程。- Diffusion模型通常从一个简单的噪声分布开始,然后逐步添加信息,直到生成最终的图像。这个过程可以通过学习一个逆过程来实现,即从噪声中恢复出图像。- Diffusion模型在生成高质量、高分辨率的图像方面表现出色,尤其是在没有明确图像标记的情况下。
简而言之,Transformer模型通过处理序列数据来生成图像,而Diffusion模型则通过模拟一个从简单到复杂的扩散过程来生成图像。两者都是强大的生成模型,但它们在生成过程中的机制和侧重点有所不同。
在附件的论文《Scalable Diffusion Models with Transformers》中,研究者们将Transformer架构与扩散模型(Diffusion Models)结合起来,创造了一种新的生成模型,称为Diffusion Transformers(DiTs)。这种结合的关键在于利用Transformer的自注意力机制来处理图像数据,同时采用扩散模型的生成过程。下面是这种结合的具体方式:
- 图像表示:首先,研究者们将图像转换为序列数据。这可以通过将图像分割成小块(patches)并线性嵌入到序列中来实现。这样,每个小块(或称为令牌)都可以被视为序列中的一个元素,从而可以被Transformer处理。
- 自注意力机制:Transformer的核心是自注意力机制,它允许模型在处理序列时考虑序列中所有元素之间的关系,无论它们之间的距离有多远。在DiTs中,这种机制使得模型能够捕捉到图像中不同区域之间的复杂依赖关系,这对于生成高质量的图像至关重要。
- 扩散过程:DiTs在潜在空间中训练,这意味着它们首先学习如何从噪声中恢复出图像的潜在表示,然后再将这些潜在表示解码成实际的图像。这个过程类似于扩散模型中的“去噪”过程,但DiTs通过Transformer的自注意力机制来优化这一过程。
- 生成图像:在训练过程中,DiTs学习如何预测在每一步扩散过程中应该添加或去除多少噪声。在生成新图像时,模型从完全的噪声状态开始,逐步减少噪声,最终生成清晰的图像。
- 可扩展性:研究者们发现,通过增加Transformer的深度、宽度或输入令牌的数量(即增加计算量),DiTs的性能(以Fréchet Inception Distance, FID衡量)会提高。这表明DiTs具有良好的可扩展性,可以通过增加计算资源来进一步提升生成图像的质量。
总的来说,DiTs通过将Transformer的自注意力机制与扩散模型的生成过程相结合,实现了一种新的图像生成方法。这种方法不仅能够生成高质量的图像,而且具有很好的可扩展性,为未来的图像生成研究提供了新的方向。
第三步:分析及结论
经过以上分析可大致知道OpenAI这一次发布的关键突破点大概是在哪些方面。
- 将Transformer和Diffusion的结合——“将所有类型的视觉数据转换成统一表示的方法”,这是可以进行大规模数据量训练的重要前提。
- 同理token与LLM的关系的是patch与视觉模型的关系,来源于NaViT(Native Resolution ViT)的实现方式,可将不同图像的多个块打包成一个序列,在保持宽高比的同时实现可变分辨率。这是统一数据输入的重要前提。
- 当使用视频进行训练时,并不需要将视频分解到每一帧来训练,而是分解为patch。可以想象在一个patch里面的各帧是连续的,这也就解释了为什么OpenAI给出的演示视频里面的角色、环境、物品等在运镜时依然可以保持一致。
- 其他方面暂且不关注过多,这篇文章主要还是希望探讨通过AI辅助阅读论文的方法以及实际效果。
分析层面还可以使用researchrabbitapp.com来完成文献计量分析的部分工作。现在researchrabbitapp已经支持你直接导入Zotero里一个文件夹里面的所有论文,会非常方便。
导入后则可以看到这几篇论文作者的分布情况: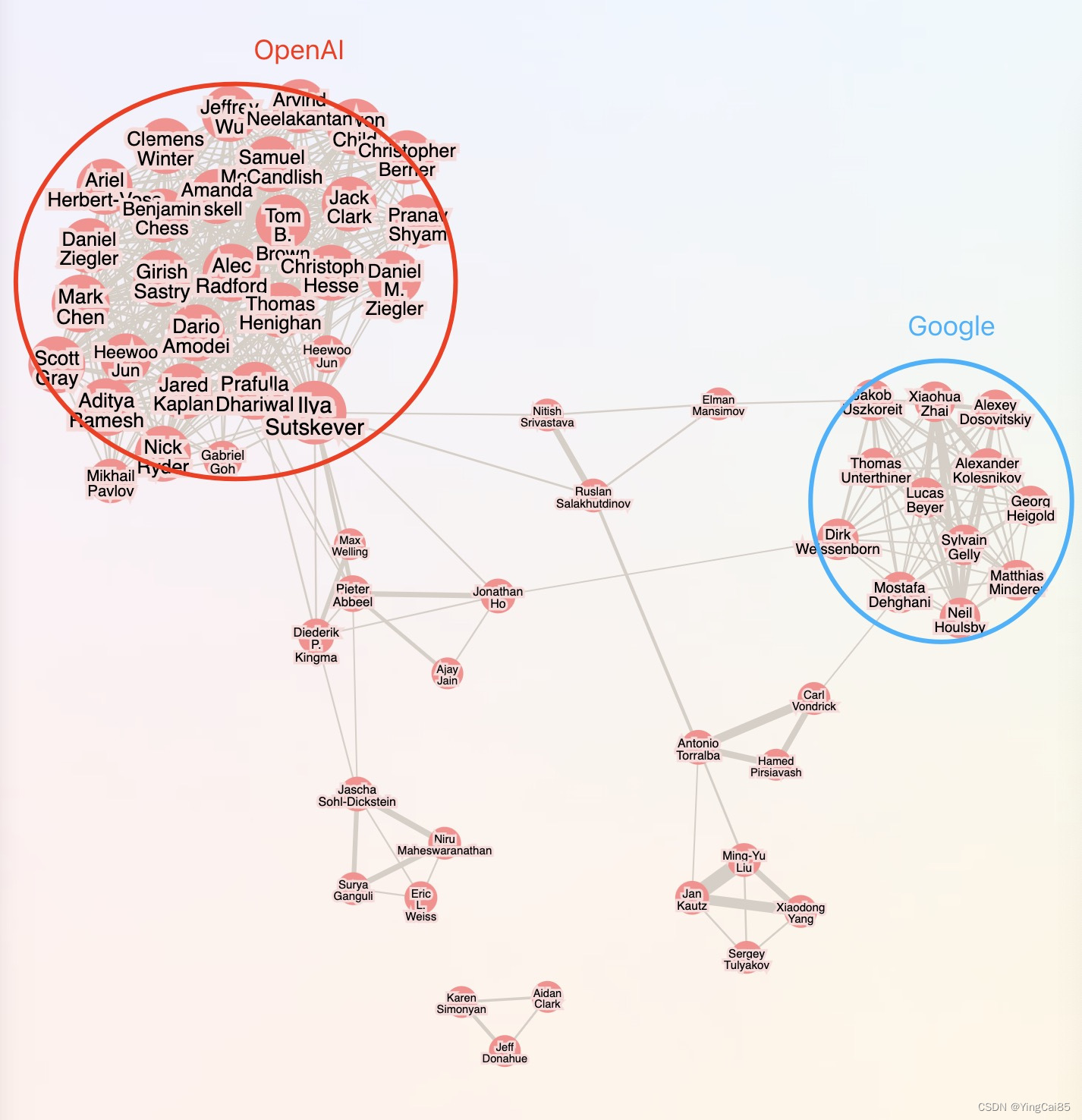
第四部:个人论文阅读分析工作流
工具集
- Zotero
- ChatGPT4.0
- GPTs Scholar GPT
- kimi 月之暗面
工作流
- 获取参考文献(任意格式)
- 使用Scholar GPT检索所有原文,让其提供原文链接
- 使用bing直接搜索arxiv预印本网站
- 使用月之暗面对论文进行总结、分析QA
- 整合内容至GPT4进一步分析QA
- 撰写结论及考虑下一步
下一步是什么?取决于你的分析目的,有时候可能是要做一篇综述,可将一些重要论文的摘要总结写成某一个小节里的概要性描述。有时候可能是要对论文中一些关键内容进行复现,就可以进一步搜寻作者是否有给出相关的代码以及数据集信息,然后再让GPT4实实在在地帮你把论文写出来。
以上过程有哪一些可以通过AI/程序来简化?比如:
- 从参考文献到论文下载,可否借助bing API自动化?
- 文献下载后导入Zotero,可否借助Zotero API自动化?
- 有哪些API可以支持输入pdf文件,并且运行一系列QA返回结果到Zotero卡片或者是Ob?
- 针对不同目标,可能会有不同形式组合的工作流,应该如何考虑呢?
我重新翻看了一下之前做过的几个(最终没用起来的)工作流


之前的工作流都有不少问题,例如:
- 没有使用bing API,而是直接通过http request获取网页内容,返回内容不稳定;
- Zotero API写入时并不能自动执行附件的元数据写入,要通过py代码从pdf里面提取这些信息很繁琐;
- 以前做的工作流都很少从产品角度思考,都是半调子的东西,没有持续做出来。
从目前结合了多个AI工具配合使用的情况来看,想要一下子取代各个环节的工具(Scholar GPT/月之暗面/GPT4),做成一个统一工作流,成本比较高。因此考虑的最小行动是将获取原文(Full Text)作为一个小环节来做,用bing API替代掉不好用的arxiv自带检索。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
import time
import re
inputs = [
'Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. "Unsupervised learning of video representations using lstms." International conference on machine learning. PMLR, 2015',
'Chiappa, Silvia, et al. "Recurrent environment simulators." arXiv preprint arXiv:1704.02254 (2017).',
'Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).',
'Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. "Generating videos with scene dynamics." Advances in neural information processing systems 29 (2016).',
'Tulyakov, Sergey, et al. "Mocogan: Decomposing motion and content for video generation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.',
'Clark, Aidan, Jeff Donahue, and Karen Simonyan. "Adversarial video generation on complex datasets." arXiv preprint arXiv:1907.06571 (2019).',
'Brooks, Tim, et al. "Generating long videos of dynamic scenes." Advances in Neural Information Processing Systems 35 (2022): 31769-31781.',
'Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).',
'Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.',
'Ho, Jonathan, et al. "Imagen video: High definition video generation with diffusion models." arXiv preprint arXiv:2210.02303 (2022).',
'Blattmann, Andreas, et al. "Align your latents: High-resolution video synthesis with latent diffusion models." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.',
'Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).',
'Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).',
'Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.',
'Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).',
'Arnab, Anurag, et al. "Vivit: A video vision transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.',
'He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.',
'Dehghani, Mostafa, et al. "Patch n\'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).',
'Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.',
'Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013).',
'Sohl-Dickstein, Jascha, et al. "Deep unsupervised learning using nonequilibrium thermodynamics." International conference on machine learning. PMLR, 2015.',
'Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.',
'Nichol, Alexander Quinn, and Prafulla Dhariwal. "Improved denoising diffusion probabilistic models." International Conference on Machine Learning. PMLR, 2021.',
'Dhariwal, Prafulla, and Alexander Quinn Nichol. "Diffusion Models Beat GANs on Image Synthesis." Advances in Neural Information Processing Systems. 2021.',
'Karras, Tero, et al. "Elucidating the design space of diffusion-based generative models." Advances in Neural Information Processing Systems 35 (2022): 26565-26577.',
'Peebles, William, and Saining Xie. "Scalable diffusion models with transformers." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.',
'Chen, Mark, et al. "Generative pretraining from pixels." International conference on machine learning. PMLR, 2020.',
'Ramesh, Aditya, et al. "Zero-shot text-to-image generation." International Conference on Machine Learning. PMLR, 2021.',
'Yu, Jiahui, et al. "Scaling autoregressive models for content-rich text-to-image generation." arXiv preprint arXiv:2206.10789 2.3 (2022): 5.',
'Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8',
'Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.',
'Meng, Chenlin, et al. "Sdedit: Guided image synthesis and editing with stochastic differential equations." arXiv preprint arXiv:2108.01073 (2021).'
]
subscription_key = '此处填入你的bing API key'
endpoint = 'https://api.bing.microsoft.com' + "/v7.0/search"
mkt = 'en-US'
headers = { 'Ocp-Apim-Subscription-Key': subscription_key }
# CSV用于保留记录,也可以不用
with open('search_a_result.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['input', 'title', 'url', 'brief'])
for article in inputs[0:5]: # 测试前5条
print(f"trying:{article}")
try:
query = f"site:arxiv.org\t\t+{article}"
params = { 'q': query, 'mkt': mkt }
response = requests.get(endpoint, headers=headers, params=params)
# 检查响应状态码
if response.status_code == 200:
json = response.json()
search_results = json['webPages']['value']
print(f"getting:{len(search_results)}")
for result in search_results:
title = result['name']
link = result['url']
summary = result['snippet']
writer.writerow([article, title, link, summary])
time.sleep(1) # 休眠一段时间,遵守Bing的使用条款
else:
print(f"Error: {response.status_code}")
# 校验第一条结果是否符合arxiv可下载论文格式
first_row_name = search_results[0]['name']
first_row_url = search_results[0]['url']
pattern = r'https://arxiv\.org/abs/\d+\.\d+'
# 如符合格式则下载
if re.match(pattern, first_row_url):
pdf_url = first_row_url.replace('abs', 'pdf') + '.pdf'
download_path = f'修改为你的下载路径/{first_row_name}.pdf' # 请根据实际情况调整路径
response = requests.get(pdf_url)
with open(download_path, 'wb') as f:
f.write(response.content)
print(f'文件已下载到:{download_path}')
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
except Exception as e:
print(f"An error occurred: {e}")
这里默认假设我们关注的论文都在arxiv上可直接下载,那么批量的文件获取就会变得相对简单。
更多AI论文工作流相关工具
- Elicit
- https://elicit.com/
可以导入多篇论文提取数据,这个工具的核心优势是将学术常用的一些QA整合为了一个个Column,你可以在这个清单里面点击即可生成对应的内容。

除了常用的总结,主要发现,方法论,结果测量,局限性这些。还有有关实验样本情况,控制变量处理,数据集,统计技术等。对应每一个场景都有相应的QA,并且生成后的Column点击可直接看到原文的描述(如下图),相当不错。

- Perplexity
- https://www.perplexity.ai/
Perplexity最新版本搭配了两个模块,分别是Copilot和RAG。其中Copilot类似提示词优化,会根据问题生成CoT然后再来回复问题。RAG的作用则是辅助在搜索引擎中检索相关内容,以供参考。不过RAG现在最大的问题还是跟搜索引擎本身的使用有关,有大量的使用经验(或者说使用偏好)AI并未能领会。换句话说,就是AI用搜索引擎,目前还不如人类(特别是擅长信息检索的小伙伴)用得好。

总的来说,论文工作流可大致分为找论文、研读论文、整理论文这几步。
找论文AI普遍效果不好,我试了好几个GPTs,ScholarGPT那个已经是最好的了。如果要找的论文大部分在arxiv上面有的话,就比较好办。其他全文确实也费劲,还不如一开始就直接去学术数据库里面找。但ScholarGPT感觉也是做了一点定制RAG的感觉,第一步也是先看搜索引擎能不能找到全文,类似filetype:pdf的操作。
研读论文则要看最终你需要产出的是什么。如果是专业人员要写文献评论,文献综述,复现论文等等这些操作,则还是需要人去认真研究论文,并不能完全依赖AI去帮你完成研究工作。
但对于外行而言,AI辅助解析各种概念,让一个普通人也能像读公众号一样地读懂一篇论文则是会有较大提升。
ChangeLog
- 2024/2/18, 17:24 完成论文导入,AI总结,工作流初步思考
- 2024/2/19, 19:58 脚本批量通过bing API下载论文原文
- 2024/2/20, 16:43 更新两个AI论文辅助工具
版权归原作者 YingCai85 所有, 如有侵权,请联系我们删除。