
11.2 技术架构
在本项目中构建了一个可以用自然语言回答用户问题的系统,本项目使用的是SQuAD 2.0数据集,然后使用BERT的压缩版本模型MobileBERT进行处理,最后使用Tensorflow.js实现机器学习开发。
11.2.1 Tensorflow.js
TensorFlow.js是一个开源的基于 WebGL 硬件加速技术的 JavaScript 库,用于训练和部署机器学习模型,其设计理念借鉴于目前广受欢迎的 TensorFlow 深度学习框架。谷歌推出的第一个基于 TensorFlow 的前端深度学习框架是 deeplearning.js,使用 TypeScript 语言开发,2018 年 Google 将其重新命名为 TensorFlow.js,并在TypeScript内核的基础上增加了 JavaScript 的接口以及 TensorFlow 模型导入等工程,组成了TensorFlow.js深度学习框架。
1. 安装**Tensorflow.js **
在JavaScript项目中,有两种安装TensorFlow.js的方法:一种是通过script标签引入,另外一种就是通过npm进行安装。
(1)通过JavaScript标签引入
通过使用如下脚本代码,可以将TensorFlow.js添加到我们的HTML文件中。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js"></script>
(2)从NPM安装
可以使用 npm cli 工具或 yarn安装 TensorFlow.js,具体命令如下:
yarn add @tensorflow/tfjs
或:
npm install @tensorflow/tfjs
TensorFlow.js 可以在浏览器和Node.js中运行,并且在两个平台中都具有许多不同的可用配置。每个平台都有一组影响应用开发方式的独特注意事项。在浏览器中,TensorFlow.js 支持移动设备以及桌面设备。每种设备都有一组特定的约束(例如可用 WebGL API),系统会自动为您确定和配置这些约束。
**2. **环境
在执行TensorFlow.js程序时,将特定配置称为环境。环境由单个全局后端以及一组控制 TensorFlow.js细粒度功能的标记构成。
**3. **后端
TensorFlow.js支持可实现张量存储和数学运算的多种不同后端,在任何给定时间内,均只有一个后端处于活动状态。在大多数情况下,TensorFlow.js会根据当前环境自动为您选择最佳后端。但是,有时必须要知道正在使用哪个后端以及如何进行切换。
要确定使用的后端,请运行以下代码:
console.log(tf.getBackend());
如果要手动更改后端,请运行以下代码:
tf.setBackend('cpu');
console.log(tf.getBackend());
(1)WebGL后端
WebGL后端 'webgl' 是当前适用于浏览器的功能最强大的后端,此后端的速度比普通 CPU 后端快 100 倍。张量将存储为 WebGL 纹理,而数学运算将在WebGL着色器中实现。在使用WebGL后端时需要了解如下所示的实用信息:
- 避免阻塞界面线程
当调用诸如 tf.matMul(a, b)等运算时,生成的 tf.Tensor会被同步返回,但是矩阵乘法计算实际上可能还未准备就绪,这意味着返回的 tf.Tensor只是计算的句柄。当调用x.data()或x.array()时,这些值将在计算实际完成时解析。这样,就必须对同步对应项 x.dataSync()和 x.arraySync()使用异步 x.data()和 x.array()方法,以避免在计算完成时阻塞界面线程。
- 内存管理
在使用WebGL后端时需要显式内存管理,浏览器不会自动回收 WebGLTexture(最终存储张量数据的位置)的垃圾。要想销毁 tf.Tensor的内存,可以使用dispose()方法实现:
const a = tf.tensor([[1, 2], [3, 4]]);
a.dispose();
在现实应用中将多个运算链接在一起的情形十分常见,保持对用于处置这些运算的所有中间变量的引用会降低代码的可读性。为了解决这个问题,TensorFlow.js 提供了tf.tidy()方法,可以清理执行函数后未被该函数返回的所有tf.Tensor,这类似于执行函数时清理局部变量的方式:
const a = tf.tensor([[1, 2], [3, 4]]);
const y = tf.tidy(() => {
const result = a.square().log().neg();
return result;
});
注意:在具有自动垃圾回收功能的非WebGL环境(例如 Node.js 或 CPU 后端)中使用 dispose() 或 tidy() 没有弊端。实际上,与自然发生垃圾回收相比,释放张量内存的性能可能会更胜一筹。
- 精度
在移动设备上,WebGL可能仅支持16位浮点纹理。但是,大多数机器学习模型都使用 32 位浮点权重和激活进行训练。这可能会导致为移动设备移植模型时出现精度问题,因为16位浮点数只能表示 [0.000000059605, 65504] 范围内的数字。这意味着应注意模型中的权重和激活不超出此范围。要想检查设备是否支持 32 位的纹理,需要检查 tf.ENV.getBool('WEBGL_RENDER_FLOAT32_CAPABLE') 的值,如果为 false,则设备仅支持 16 位浮点纹理。可以使用 tf.ENV.getBool('WEBGL_RENDER_FLOAT32_ENABLED')检查 TensorFlow.js当前是否使用 32 位纹理。
- 着色器编译和纹理上传
TensorFlow.js 通过运行WebGL着色器程序的方式在 GPU上执行运算,当用户要求执行运算时,这些着色器会迟缓地进行汇编和编译。着色器的编译在 CPU 主线程上进行,可能十分缓慢。TensorFlow.js 将自动缓存已编译的着色器,从而大幅加快第二次调用具有相同形状输入和输出张量的同一运算的速度。通常,TensorFlow.js 应用在应用生命周期内会多次使用同一运算,因此第二次通过机器学习模型的速度会大幅提高。
TensorFlow.js会将 tf.Tensor 数据存储为 WebGLTextures。在创建 tf.Tensor时不会立即将数据上传到GPU,而是将数据保留在CPU上,直到在运算中使用到 tf.Tensor 为止。当第二次使用 tf.Tensor 时,因为数据已位于 GPU上,所以不存在上传成本。在典型的机器学习模型中,这意味着在模型第一次预测期间会上传权重,而第二次通过模型则会快得多。
如果开发者在意通过模型或 TensorFlow.js 代码执行首次预测的性能,建议在使用实际数据之前先通过传递相同形状的输入张量来预热模型。例如:
const model = await tf.loadLayersModel(modelUrl);
//在使用真实数据之前预热模型
const warmupResult = model.predict(tf.zeros(inputShape));
warmupResult.dataSync();
warmupResult.dispose();
//这时第二个predict()会快得多
const result = model.predict(userData);
(2)Node.js TensorFlow后端
在TensorFlow Node.js 后端 'node' 中,使用 TensorFlow C API 来加速运算。这将在可用情况下使用计算机的可用硬件加速(例如 CUDA)。
在这个后端中,就像 WebGL 后端一样,运算会同步返回 tf.Tensor。但与 WebGL 后端不同的是,运算在返回张量之前就已完成。这意味着调用 tf.matMul(a, b) 将阻塞 UI 线程。因此,如果打算在生产应用中使用,则应在工作线程中运行 TensorFlow.js 以免阻塞主线程。
(3)WASM后端
TensorFlow.js提供了WebAssembly后端 (wasm),可以实现CPU加速功能,并且可以替代普通的 JavaScript CPU (cpu)和 WebGL后端。用法如下:
//将后端设置为WASM并等待模块就绪。
tf.setBackend('wasm');
tf.ready().then(() => {...});
如果服务器在不同的路径上或以不同的名称提供“.wasm”文件,则需要在初始化后端前使用 setWasmPath。
注意:TensorFlow.js会为每个后端定义优先级并为给定环境自动选择支持程度最高的后端。要显式使用WASM后端,需要调用 tf.setBackend('wasm')函数实现。
(4)CPU后端
CPU后端 'cpu'是性能最低但最简单的后端,所有运算均在普通的JavaScript中实现,这使它们的可并行性较差,这些运算还会阻塞界面线程。CPU后端对于测试或在 WebGL不可用的设备上非常有用。
11.2.2 SQuAD 2.0
SQuAD2.0即斯坦福问答数据集,是一个阅读理解文章的数据集,由维基百科的文章和每篇文章的一组问答对组成。是自然语言处理界最重量级的数据集之一,这个数据集展现了斯坦福大学要做一个自然语言处理的ImageNet的野心。SQuAD2.0很有可能成为自然语言学术界未来至少一年内最流行的数据集。神经学习模型可以很容易的在这个数据集上做出好的成绩,可以让自己的文章加分,也会大大增加被顶会录取的概率。
于此同时,SQuAD2.0数据集也会为工业界做出贡献,意图构建一个类似“ImageNet”的测试集合,会实时在leaderboard上显示分数,这就让这个数据集有如下优势:
(1)测试出真正的好算法:尤其对于工业界,这个数据集是十分值得关注的,因为可以告诉大家现在各个算法在“阅读理解”或者说“自动问答”这个任务上的排名。可以光看分数排名,就知道世界上哪个算法最好,不会再怀疑是作者做假了还是实现的不对。
(2)提供阅读理解大规模数据集的机会:由于之前的阅读理解数据集规模太小或者十分简单,并不能很好的体现不同算法优劣。
纵使SQuAD2.0不会像ImageNet有那么大的影响力,但绝对也会在接下来的几年内对自动问答领域产生深远的影响,并且是各大巨头在自动问答这个领域上的兵家必争之地(IBM已经开始了)。
1.2.3 BERT
Google在论文《BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding》中提出了BERT模型,BERT 模型主要利用了Transformer的Encoder 结构,采用最原始的 Transformer。总的来说,BERT具有以下的特点:
- 结构:采用了 Transformer 的 Encoder 结构,但是模型结构比 Transformer 要深。Transformer Encoder 包含 6 个 Encoder block,BERT-base 模型包含 12 个 Encoder block,BERT-large 包含 24 个 Encoder block。
- 训练:训练主要分为两个阶段:预训练阶段和 Fine-tuning 阶段。预训练阶段与 Word2Vec,ELMo 等类似,是在大型数据集上根据一些预训练任务训练得到。Fine-tuning 阶段是后续用于一些下游任务的时候进行微调,例如文本分类,词性标注,问答系统等,BERT 无需调整结构就可以在不同的任务上进行微调。
- 预训练任务1:BERT 的第一个预训练任务是 Masked LM,在句子中随机遮盖一部分单词,然后同时利用上下文的信息预测遮盖的单词,这样可以更好地根据全文理解单词的意思。Masked LM 是 BERT 的重点,和 biLSTM 预测方法是有区别的,后续会讲到。
- 预训练任务2:BERT 的第二个预训练任务是 Next Sentence Prediction (NSP),下一句预测任务,这个任务主要是让模型能够更好地理解句子间的关系。
11.2.4 知识蒸馏
本章实例使用的神经网络模型是BERT的压缩版本MobileBERT,和前者相比,压缩后的MobileBERT运行速度提高了4倍,模型尺寸缩小了4倍。本项目之所以采用压缩版的MobileBERT,目的是为了提高速度和时间,如果更深入的说,是使用了知识蒸馏技术。
近年来,神经模型在几乎所有领域都取得了成功,包括极端复杂的问题。然而,这些模型的体积巨大,有数百万(甚至数十亿)个参数,因此不能部署在边缘设备上。
知识蒸馏指的是模型压缩思想,通过一步一步地使用一个较大的已经训练好的网络(教师网络)去教导一个较小的网络(学生网络)确切地去做什么。通过尝试复制大网络在每一层的输出(不仅仅是最终的损失),小网络被训练以学习大网络的准确行为。
深度学习在计算机视觉、语音识别、自然语言处理等众多领域取得了令人难以置信的成绩。然而,这些模型中的大多数在移动电话或嵌入式设备上运行的计算成本太过昂贵。显然,模型越复杂,理论搜索空间越大。但是,如果我们假设较小的网络也能实现相同(甚至相似)的收敛,那么教师网络的收敛空间应该与学生网络的解空间重叠。
不幸的是,仅凭这一点并不能保证学生网络收敛在同一点。学生网络的收敛点可能与教师网络有很大的不同。但是,如果引导学生网络复制教师网络的行为(教师网络已经在更大的解空间中进行了搜索),则其预期收敛空间会与原有的教师网络收敛空间重叠。
知识蒸馏模式下的“教师-学生网络”到底如何工作呢?基本流程如下:
(1)训练教师网络:首先使用完整数据集分别对高度复杂的教师网络进行训练,这个步骤需要高计算性能,因此只能在离线(在高性能gpu上)完成。
(2)构建对应关系:在设计学生网络时,需要建立学生网络的中间输出与教师网络的对应关系。这种对应关系可以直接将教师网络中某一层的输出信息传递给学生网络,或者在传递给学生网络之前进行一些数据增强。
(3)通过教师网络前向传播:教师网络前向传播数据以获得所有中间输出,然后对其应用数据增强(如果有的话)。
(4)通过学生网络反向传播:现在利用教师网络的输出和学生网络中反向传播误差的对应关系,使学生网络能够学会复制教师网络的行为。
随着NLP模型的大小增加到数千亿个参数,创建这些模型的更紧凑表示的重要性也随之增加。 知识蒸馏成功地实现了这一点,在一个例子中,教师模型的性能的96%保留在了一个小7倍的模型中。然而,在设计教师模型时,知识的提炼仍然被认为是事后考虑的事情,这可能会降低效率,把潜在的性能改进留给学生。
此外,在最初的提炼后对小型学生模型进行微调,并要求在微调时不降低他们的表现,能够完成我们希望学生模型能够完成的任务。因此,与只训练教师模型相比,通过知识蒸馏训练学生模型将需要更多的训练,这在推理的时候限制了学生模型的优点。
知识蒸馏MobileBERT的结构如图11-1所示。
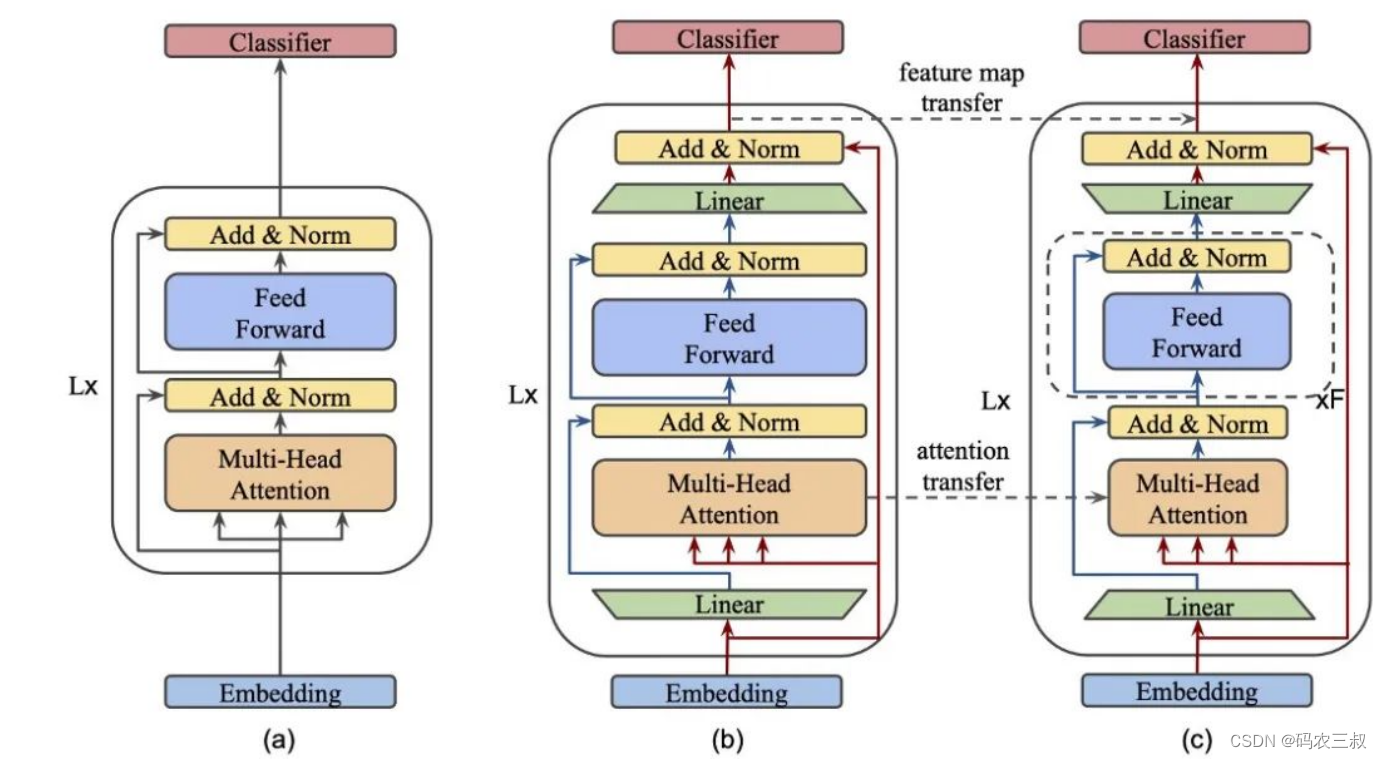
图11-1 MobileBERT的结构
在MobileBERT结构中,(a)表示BERT,(b) 表示MobileBERT教师,(c)表示MobileBERT学生。用“Linear”标记的绿色梯形称为bottlenecks。
1**. **线性层
知识的蒸馏要求我们比较老师和学生的表示,以便将它们之间的差异最小化。当两个矩阵或向量维数相同时,这是很容易的。因此,MobileBERT在transformer块中引入了一个 bottleneck 层。这让学生和老师的输入在大小上是相等的,而他们的内部表示可以不同。这些bottleneck在上图中用“Linear”标记为绿色梯形。在本例中,共享维度是512,而教师和学生的内部表示大小分别是1024和128。这使得我们可以使用BERT-large(参数量是340M)等效模型来训练一个参数量是25M的学生。
此外,由于两个模型的每个transformer块的输入和输出尺寸是相同的,因此可以通过简单的复制将嵌入参数和分类器参数从教师传递给学生!
**2. **多头注意力
细心的读者会注意到,多头注意块(MHA)的输入不是先前线性投影的输出。相反,使用初始输入。基本上,我们将迫使模型处理信息的方式分离为两个单独的流,一个流入MHA块,另一个作为跳跃连接。(使用线性投影的输出并不会因为初始的线性变换而改变MHA块的行为,这也是很容易说服自己的。)
**3. **堆叠FFN
为了在这个小的学生模型中实现足够大的容量,作者引入了他们所谓的 stacked FFN,如图中学生模型概述中的虚线框所示。Stacked FFN只是简单的将Feed Forward + Add & Norm blocks块重复了4次,选择这一方式来得到MHA和FFN block之间的良好的参数比例。本工作中的消融研究表明,当该比值在0.4-0.6范围内时,性能最佳。
**4. **操作优化
由于其目标之一是在资源有限的设备上实现快速推理,因此作者确定了他们的架构可以进一步改进的两个方面。
- 把smooth GeLU的激活函数更换为ReLU
- 将normalization操作转换为element-wise的线性变换
5**. **建议知识蒸馏目标
为了实现教师和学生之间的知识转移,作者在模型的三个阶段进行了知识蒸馏:
- 特征图迁移:允许学生模仿老师在每个transformer层的输出。在上面的架构图中,它表示为模型输出之间的虚线箭头。
- 注意力图迁移:这让老师在不同层次上关注学生,这也是我们希望学生学习的另一个重要属性。这是通过最小化每一层和头部的注意力分布(KL散度)之间的差异而实现的。
- 预训练蒸馏:也可以在预训练中使用蒸馏,通过Masked语言建模和下一句预测的任务实现的线性组合。
有了这些目标后,就有了不止一种方法来进行知识的提炼。在此提出如下三种备选方案:
- 辅助知识迁移:分层的知识迁移目标与主要目标(Masked语言建模和下一句预测)一起最小化。这可以被认为是最简单的方法。
- 联合知识迁移:不要试图一次完成所有的目标,可以将知识提炼和预训练分为两个阶段。首先对所有分层知识蒸馏损失进行训练直到收敛,然后根据预训练的目标进行进一步训练。
- 进一步的知识转移:两步法还可以更进一步。如果所有层同时进行训练,早期层没有很好的最小化的错误将会传播并影响以后层的训练。因此,最好是一次训练一层,同时冻结或降低前一层的学习速度。
经过研究发现,通过渐进式知识转移,训练这些不同的MobileBERT是最有效的,其效果始终显著优于其他两个。最终的实验证明:MobileBERT在transformer模块中引入了 bottlenecks,这使得可以更容易地将知识从大尺寸的教师模型中提取到小尺寸的学生模型中。这种技术允许我们减少学生的宽度,而不是深度,这是已知的,以产生一个更有能力的模型。这个模型强调了这样一个事实,它可以创建一个学生模型,它本身可以在最初的蒸馏过程后进行微调。
未完待续
版权归原作者 码农三叔 所有, 如有侵权,请联系我们删除。