
文章目录
基于逻辑回归实现乳腺癌预测
# 基于逻辑回归实现乳腺癌预测from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,test_size=0.2)
model=LogisticRegression(max_iter=10000)
model.fit(X_train,y_train)
train_score=model.score(X_train,y_train)
test_score=model.score(X_test,y_test)print('train_score:{train_score:.6f};test_score:{test_score:.6f}'.format(train_score=train_score,test_score=test_score))
train_score:0.960440;test_score:0.964912
#预测测试集
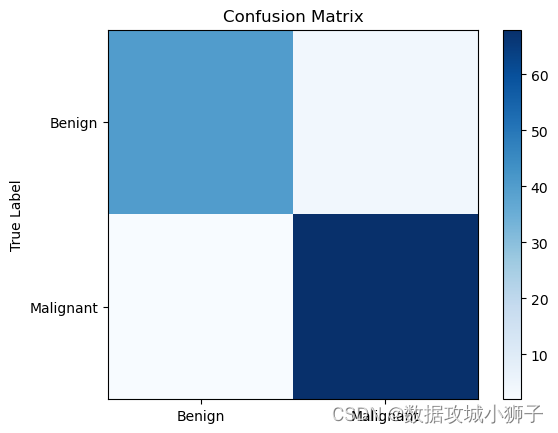
y_pred=model.predict(X_test)#绘制混淆矩阵
cm=confusion_matrix(y_test,y_pred)
plt.imshow(cm,cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
plt.xticks([0,1],['Benign','Malignant'])
plt.yticks([0,1],['Benign','Malignant'])
plt.ylabel('True Label')
plt.show()
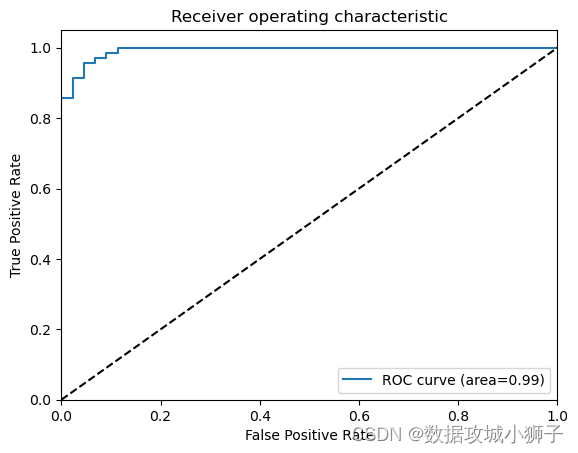
#绘制ROC曲线
fpr,tpr,thresholds=roc_curve(y_test,model.predict_proba(X_test)[:,1])
roc_auc=auc(fpr,tpr)
plt.plot(fpr,tpr,label='ROC curve (area=%0.2f)'%roc_auc)
plt.plot([0,1],[0,1],'k--')
plt.xlim([0.0,1.0])
plt.ylim([0.0,1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
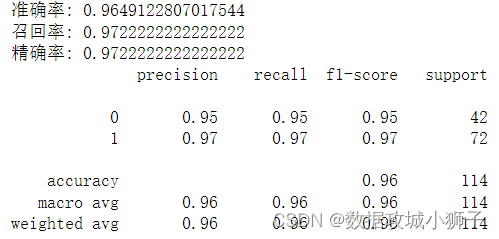
# 模型评估from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
y_pred=model.predict(X_test)
accuracy_score_value=accuracy_score(y_test,y_pred)
recall_score_value=recall_score(y_test,y_pred)
precision_score_value=precision_score(y_test,y_pred)
classification_report_value=classification_report(y_test,y_pred)print("准确率:",accuracy_score_value)print("召回率:",recall_score_value)print("精确率:",precision_score_value)print(classification_report_value)
基于k-近邻算法实现鸢尾花分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier as KNN
iris=load_iris()
x_train,x_test,y_train,y_test=train_test_split(iris.data[:,[1,3]],iris.target)
model=KNN()# 默认n_neighbors=5
model.fit(x_train,y_train)
train_score=model.score(x_train,y_train)
test_score=model.score(x_test,y_test)print("train_score",train_score)print("test_score",test_score)
train_score 0.9553571428571429
test_score 0.9736842105263158
基于决策树实现葡萄酒分类
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
wine=load_wine()
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target)
clf=DecisionTreeClassifier(criterion="entropy")
clf.fit(x_train,y_train)
train_score=clf.score(x_train,y_train)
test_score=clf.score(x_test,y_test)print("train_score",train_score)print("test_score",test_score)
train_score 1.0
test_score 0.9333333333333333
基于朴素贝叶斯实现垃圾短信分类
# 加载SMS垃圾短信数据集withopen('./SMSSpamCollection.txt','r',encoding='utf8')as f:
sms=[line.split('\t')for line in f]
y,x=zip(*sms)
# SMS垃圾短信数据集特征提取from sklearn.feature_extraction.text import CountVectorizer as CV
from sklearn.model_selection import train_test_split
y=[label=='spam'for label in y]
x_train,x_test,y_train,y_test=train_test_split(x,y)
counter=CV(token_pattern='[a-zA-Z]{2,}')
x_train=counter.fit_transform(x_train)
x_test=counter.transform(x_test)
from sklearn.naive_bayes import MultinomialNB as NB
model=NB()
model.fit(x_train,y_train)
train_score=model.score(x_train,y_train)
test_score=model.score(x_test,y_test)print("train_score",train_score)print("test_score",test_score)
train_score 0.9925837320574162
test_score 0.9878048780487805
基于支持向量机实现葡萄酒分类
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
wine=load_wine()
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target)
model=SVC(kernel='linear')
model.fit(x_train,y_train)
train_score=model.score(x_train,y_train)
test_score=model.score(x_test,y_test)print("train_score",train_score)print("test_score",test_score)
kernel参数:
- linear:线性核函数
- poly:多项式核函数
- rbf:径向基核函数/高斯核
- sigmod:sigmod核函数
- precomputed:提前计算好核函数矩阵
train_score 0.9924812030075187
test_score 1.0
基于高斯混合模型实现鸢尾花分类
from scipy import stats
from sklearn.datasets import load_iris
from sklearn.mixture import GaussianMixture as GMM
import matplotlib.pyplot as plt
iris=load_iris()
model=GMM(n_components=3)
pred=model.fit_predict(iris.data)print(score(pred,iris.target))defscore(pred,gt):assertlen(pred)==len(gt)
m=len(pred)
map_={}for c inset(pred):
map_[c]=stats.mode(gt[pred==c])[0]
score=sum([map_[pred[i]]==gt[i]for i inrange(m)])return score[0]/m
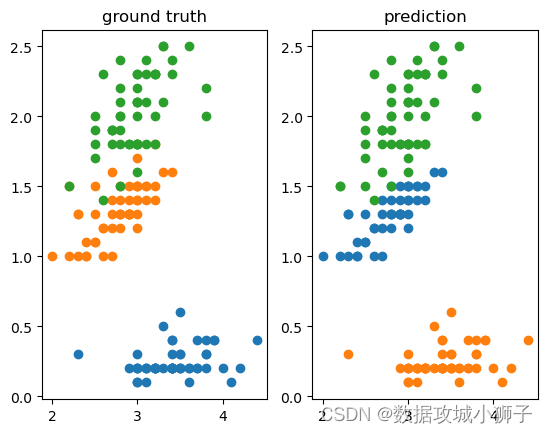
_,axes=plt.subplots(1,2)
axes[0].set_title("ground truth")
axes[1].set_title("prediction")for target inrange(3):
axes[0].scatter(
iris.data[iris.target==target,1],
iris.data[iris.target==target,3],)
axes[1].scatter(
iris.data[pred==target,1],
iris.data[pred==target,3],)
plt.show()
0.9666666666666667
基于主成分分析实现鸢尾花数据降维
# 鸢尾花数据集加载与归一化from sklearn.datasets import load_iris
from sklearn.preprocessing import scale
iris=load_iris()
data,target=scale(iris.data),iris.target
# PCA降维鸢尾花数据集from sklearn.decomposition import PCA
pca=PCA(n_components=2)
y=pca.fit_transform(data)
基于奇异值分解实现图片压缩

import numpy as np
from PIL import Image
classSVD:def__init__(self,img_path):with Image.open(img_path)as img:
img=np.asarray(img.convert('L'))
self.U,self.Sigma,self.VT=np.linalg.svd(img)defcompress_img(self,k:"# singular value")->"img":return self.U[:,:k] @ np.diag(self.Sigma[:k]) @ self.VT[:k,:]
model=SVD('./可莉.jpg')
result=[
Image.fromarray(model.compress_img(i))for i in[1,10,20,50,100,500]]
import matplotlib.pyplot as plt
for i inrange(6):
plt.subplot(2,3,i+1)
plt.imshow(result[i])
plt.axis('off')
plt.show()

本文转载自: https://blog.csdn.net/weixin_46322367/article/details/129309643
版权归原作者 数据攻城小狮子 所有, 如有侵权,请联系我们删除。
版权归原作者 数据攻城小狮子 所有, 如有侵权,请联系我们删除。