
t 检验是一种统计技术,可以告诉人们两组数据之间的差异有多显著。它通过将信号量(通过样本或总体平均值之间的差异测量)与这些样本中的噪声量(或变化)进行比较来实现。有许多有用的文章会告诉你什么是 t 检验以及它是如何工作的,但没有太多材料讨论 t 检验的不同变体以及何时使用它们。本文将介绍 t 检验的 3 种变体以及何时使用它们以及如何在 Python 中运行它们。
单样本 t 检验
单样本 t 检验将数据样本的平均值与一个特定值进行比较。最常见的一个例子是可口可乐想要确保装瓶厂在每个罐头中倒入适量的苏打水:他们想要每个罐装 355 毫升,因此可以抽取罐装样品并测量倒入每个罐装的确切毫升数。由于机械过程不精确有些罐头的容量可能超过 355 毫升,而有些罐头的容量可能会变少。通过对罐子样本进行单样本 t 检验,可以测试机器是否向每个罐子中倒入与 355 毫升液体不同的统计学显着量。
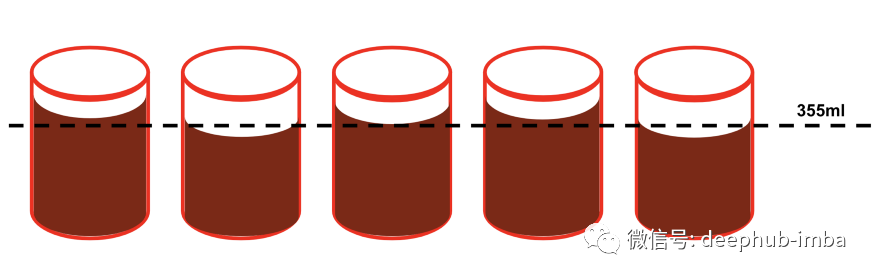
它是如何工作的?
1、陈述原假设和备择假设。原假设 (H0) 将是样本均值与特定值(总体均值)没有差异,而备择假设 (H1) 则表明存在差异。使用上面的示例,它们将类似于:
- H0:平均每罐可乐有355ml。
- H1:平均每罐可乐超过355ml。
注意:由于我选择了一个方向(即“每个罐子里有超过 355 毫升”),这变成了一个单边 t 检验而不是只说数量不是 355 毫升的双边 t 检验。
2、确定显著性水平:显著性水平,通常称为 alpha (α),是在实际为真时拒绝原假设的概率。通常使用 0.05 的 alpha 值,这意味着有 5% 的风险得出结论认为样本之间存在统计学上的显著差异,而这实际上只是由于噪声所导致的。
3、收集数据:要测试的值 (μ)、样本均值 (x̄)、样本标准差 (S)、样本观察次数 (n),并将它们代入以下公式计算 t 统计量:
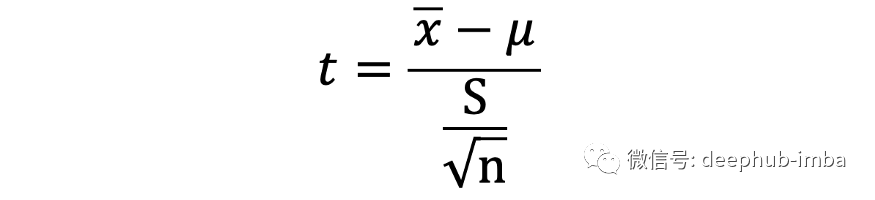
4、将t统计量和自由度代入t表,得到相应的p值。将这个p值与你选择的alpha水平比较,如果它更小,你就可以拒绝原假设。
但是这类测试的有效性需要3个假设:
- 样本是独立的
- 数据近似正态分布
- 随机采样
代码示例
Scipy 的 stats 库有一个方便的 ttest_1samp 方法,当给定数据样本和要比较的总体均值时,该方法将计算 t-stat 和 p-value。下面的代码演示了使用该函数为上述示例运行一个示例 t 检验。
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create fake data sample of 30 cans from 2 factories
factory_a = np.full(30, 355) + np.random.normal(0, 3, 30)
factory_b = np.full(30, 353) + np.random.normal(0, 3, 30)
# Run a 1 sample t-test for each one
a_stat, a_pval = stats.ttest_1samp(a=factory_a, popmean=355, alternative='two-sided')
b_stat, b_pval = stats.ttest_1samp(a=factory_b, popmean=355, alternative='two-sided')
# Display results
print("Factory A- t-stat: {:.2f} pval: {:.4f}".format(a_stat, a_pval))
print("Factory B- t-stat: {:.2f} pval: {:.4f}".format(b_stat, b_pval))
## Output
# Factory A- t-stat: 0.37 pval: 0.7140
# Factory B- t-stat: -3.96 pval: 0.000
在这里,我创建了来自工厂 A 和工厂 B 的 30 个罐头的两个数据样本。对于工厂 A,数据的平均值为 355并添加了噪声项,但对于工厂 B,数据的平均值为 353并添加了噪声。对两者运行单样本 t 检验,我们看到工厂 A 的 p 值为 0.71,工厂 B 的 p 值为 0.0004。工厂 A 的 p 值远高于 0.05 的标准 alpha 水平,但工厂 B 低于该水平 阈值允许我们拒绝原假设。
双样本 t 检验
双样本 t 检验不是将数据样本的平均值与单个值(总体平均值)进行比较,而是比较两个独立数据样本的平均值。还是上面的例子,如果想要比较 A 工厂和 B 工厂的罐装液体的平均量,就可以使用此方法。
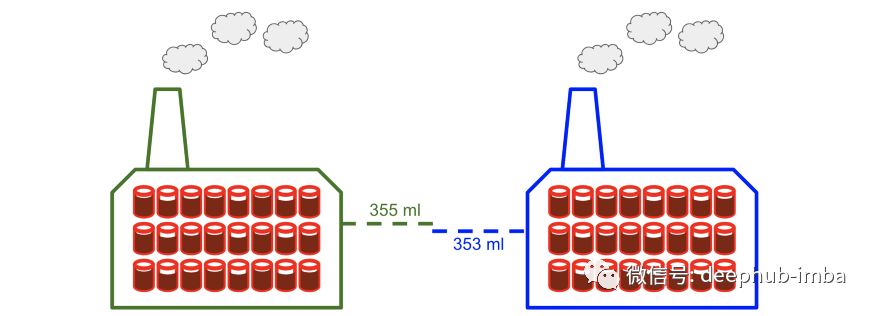
它是如何工作的?
1、与单样本 t 检验类似,我们陈述原假设和备择假设。以两个工厂为例,它们将是:
H0:两家工厂的平均填充量没有显著差异
H1:两家工厂的平均填充量存在显著差异
注意:重要的是要记住,原假设和备择假设总是关于一般人群,而不是从中抽取的样本
2、选择一个显著性水平(我们将再次选择 0.05)
3、计算两个样本的均值(x̄)、标准差(S)和样本量(N),代入下式,得到一个t统计量
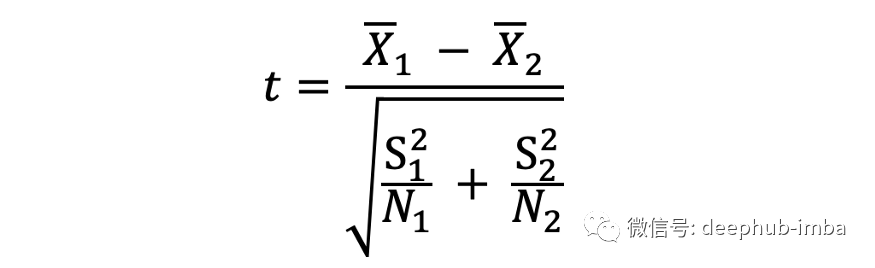
4、将 t 统计量和自由度代入 t 表,得到相应的 p 值。将该 p 值与所选的 alpha 水平进行比较,如果它更小,则可以拒绝原假设。
与单样本 t 检验一样,此检验也必须满足一些假设:
- 两个样本是独立的
- 两个样本近似正态分布
- 两个样本的方差大致相同
代码示例
Scipy 的 ttest_ind 方法接收两个数据样本,并且与 ttest_1samp 类似,从测试中返回一个 t 统计量和相应的 p 值。下面的代码演示了使用该函数来运行上面的示例用例。
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create fake data sample of 30 cans from 2 factories
factory_a = np.full(30, 355) + np.random.normal(0, 3, 30)
factory_b = np.full(30, 353) + np.random.normal(0, 3, 30)
# Run a two sample t-test to compare the two samples
tstat, pval = stats.ttest_ind(a=factory_a, b=factory_b, alternative="two-sided")
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 3.15 pval: 0.0026
由于这个 0.0026 检验的 p 值低于 0.05 的标准 alpha,因此拒绝原假设。
配对 t 检验
配对 t 检验通常比较随时间变化同一实体的两个测量值。例如,如果想要测试装瓶培训计划的有效性,他们可以比较每位员工在接受培训之前和之后的平均装瓶率。
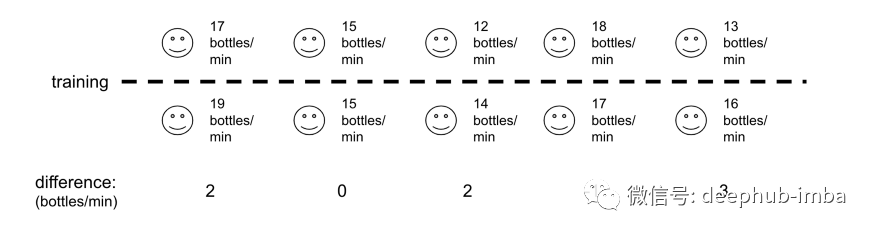
它是如何工作的?
与一样本和二样本 t 检验类似,必须说明原假设和备择假设,选择显着性水平,计算 t 统计量,并将其与 t 表中的自由度一起使用以获得 p 值 . 同样,t 统计量的公式不同,如下所示,其中 d 是每个配对值的差异,n 是样本数。
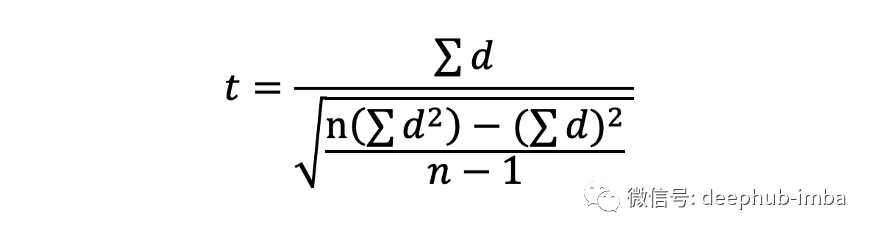
这个检验的另一种描述方式是:配对 t 检验本质上只是对每个配对样本的差异进行单样本 t 检验!在这种情况下,原假设是配对样本差值为零。
代码示例
Scipy 的 ttest_rel 方法接收两个配对数据数组,并且类似于 ttest_1samp 和 ttest_ind 函数,返回一个 t 统计量和相应的 p 值。在下面的代码中,我首先定义了一组员工装瓶率,每分钟随机瓶数介于 10 到 20 之间。然后我使用“apply_training”函数模拟培训,该函数可以将生产率降低 1 瓶/分钟,或者提高最多 4 瓶/分钟。与前面两个示例类似,我将训练前后的生产力数组输入 scipy 的 ttest_rel 函数并打印输出。
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create array of worker bottling rates between 10 and 20 bottles/min
pre_training = np.random.randint(low=10, high=20, size=30)
# Define "training" function and apply
def apply_training(worker):
return worker + np.random.randint(-1, 4)
post_training = list(map(apply_training, pre_training))
# Run a paired t-test to compare worker productivity before & after the training
tstat, pval = stats.ttest_rel(post_training, pre_training)
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 2.80 pval: 0.0091
最后,作为上面描述的总结,这里演示了配对 t 检验如何与配对差异的单样本 t 检验相同。在下面的代码片段中,获取了 post_training 和 pre_training 数组之间的差异,并对总体平均值 0 的差异进行了单样本 t 检验(因为零假设是样本之间没有差异)。正如预期的那样,t 统计量和 p 值与配对 t 检验完全相同!
# Take differences in productivity, pre vs. post
differences = [x-y for x,y in zip(post_training, pre_training)]
# Run a 1-sample t-test on the differences with a popmean of 0
tstat, pval = stats.ttest_1samp(differences, 0)
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 2.80 pval: 0.0091
最后,感谢阅读
作者:Eric Onofrey