
文章目录
写在前面
新的一周开始啦,本周博主给大家带来《机器学习与人工智能实战:基于业务场景的工程应用》,感兴趣的小伙伴快来看看吧!
机器学习
下面是一个使用Python实现简单线性回归模型的代码示例:
import numpy as np
import matplotlib.pyplot as plt
classSimpleLinearRegression:def__init__(self, learning_rate=0.01, iterations=1000):
self.learning_rate = learning_rate
self.iterations = iterations
self.weights =None
self.bias =None
self.costs =[]deffit(self, X, y):
n_samples, n_features = X.shape
self.weights = np.zeros(n_features)
self.bias =0for i inrange(self.iterations):
y_pred = np.dot(X, self.weights)+ self.bias
cost =(1/ n_samples)* np.sum((y_pred - y)**2)
self.costs.append(cost)
dw =(2/ n_samples)* np.dot(X.T,(y_pred - y))
db =(2/ n_samples)* np.sum(y_pred - y)
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
defpredict(self, X):
y_pred = np.dot(X, self.weights)+ self.bias
return y_pred
# 使用样本数据演示简单线性回归模型
X = np.array([[1],[2],[3],[4],[5]])
y = np.array([3,5,7,9,11])# 创建模型实例并进行训练
regressor = SimpleLinearRegression()
regressor.fit(X, y)# 使用模型进行预测
y_pred = regressor.predict(X)# 绘制训练数据和拟合线性回归模型的图像
plt.scatter(X, y)
plt.plot(X, y_pred, color='red')
plt.show()
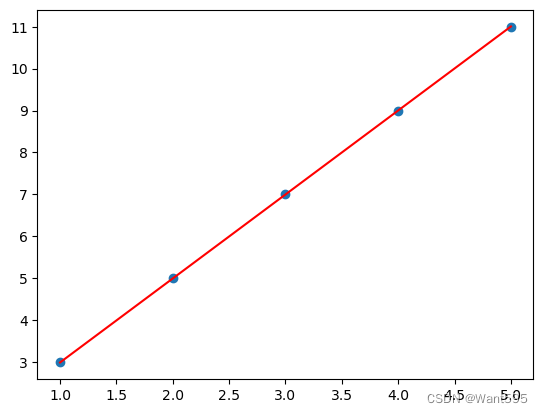
在上面的代码中,
SimpleLinearRegression
类是我们实现的简单线性回归模型。在
fit
方法中,我们使用最小二乘法进行训练,计算出最佳拟合直线的权重和偏置项。在
predict
方法中,我们使用这些权重和偏置项来预测新的未知数据。
在上述代码中,我们使用了一个简单的样例数据集,其中包含5个样本。我们绘制了这些数据及其线性拟合的模型,可以看到模型可以很好地拟合训练数据。
推荐图书
《机器学习与人工智能实战:基于业务场景的工程应用》
京东直达链接:https://item.jd.com/14101696.html

写给读者
前言
我的一生见证过三次伟大的技术革命,先后是是个人电脑、互联网和智能手机。机器学习(ML)和人工智能(AI)的重要性与这三者比肩,并将对我们的生活产生同样深刻的影响。
记得有一天,信用卡公司打电话给我,向我确认我是不是要购买一条价值700 美元的项链。打那天起,我就对机器学习产生了兴趣。虽然并不是我要买,但我很好奇:“他们是怎么知道那可能不是我的呢?”我在世界各地都使用信用卡,而且要说明的是,我确实会时不时地给我的妻子买些好东西。信用卡公司从没拒绝过合法的刷卡交易,但有几次他们正确标记了信用卡诈骗。此前有一次是巴西某个家伙试图盗刷我的信用卡买机票。这一次不同的是,那家珠宝店距离我家只有2 英里。我试着想象,到底是一种怎样的算法可以在商店里如此靠谱地检测到信用卡欺诈盗刷。没过多久,我就意识到有种东西比单纯的算法更强大,是它在发挥作用。
事实证明,信用卡公司用了一个复杂的机器学习模型来运行每一笔交易,这个模型非常善于检测欺诈行为。有了这个意识之后,我的生活发生了变化,因为这个例子很有说服力,证明ML 和AI 可以使世界变得更美好。此外,了解ML 如何实时分析信用卡交易和筛选出非法交易的同时对合法交易开绿灯,成为我接下来注定要登顶的高峰。
本书面向的读者
最近,我接到某制造公司某位工程主管的电话。他是这样说的:“直到上周,我都不知道ML 和AI 是啥意思。现在,CEO 给我布置了任务,要我弄清楚它们如何赋能我们的业务,而且还要领先于竞争对手之前做到这一点。我现在要从头开始。你能帮忙吗?”
下一通电话来自一家想要使用机器学习来检测税务欺诈和洗钱行为的政府外包公司。团队对机器学习理论相当精通,但不知道如何以最好的方式建立可以满足其需要的模型。
全球各地的专业人士都意识到,ML 和AI 代表着一场技术海啸,他们试图抢占风口浪尖以免被吞没。本书就是为这些人准备的,他们包括工程师、软件开发人员、IT经理以及其他相关人员。他们想要实际理解ML 和AI 并应用这些知识来解决以前难以甚至不可能解决的问题。本书试图传达一种直观的理解,所以只有在必要时才“祭出”公式。无论你以前有没有听过,但你真的不必成为精通微积分或线性代数的高手,大多数人都能建一个系统来识别照片中的物体(对象或目标),将英语翻译成法语,或者爆光贩毒的人和偷税漏税的人。
我为什么要写这本书
每个作者的内心深处都住着一个小精灵,它让他们知道他们可以用别人不会的方式讲故事。我在30 多年前写了第一本计算机书,20 多年前写了最后一本,原本并不打算再写的。但现在我要讲一个故事。这个故事很重要,每个工程师和软件开发人员都应该听听。我对别人讲这个故事的方式不是完全满意,所以就写了这本书,我希望自己当初学习ML 和AI 时能够有这本书。它从基础知识开始,
带领大家攀登ML 和AI 世界中一座又一座的高峰。最后,让大家明白种种奥秘:信用卡公司如何检测欺诈行为?航空公司如何通过机器学习对喷气发动机进行预测性维护?自动驾驶汽车如何看周围的世界?谷歌翻译如何把文字翻译为另一种语言?面部识别系统如何工作?此外,你还能自己动手构建一个类似的系统或者使用现有的系统,将AI集成到自己写的应用程序中。
如今,最先进的机器学习模型需要在配备图形处理单元(GPU)或张量处理单元(TPU)的计算机上进行训练,而这通常要花费大量时间和费用。本书的一个特点是提供一些例子,这些例子能在没有配备GPU 的普通PC 或笔记本电脑上构建。在讲到识别照片中目标的计算机视觉模型时,我会解释这种模型是如何工作的以及它们如何在GPU 集群上用数以百万计的图像进行训练。但我随后会向大家展示如何使用迁移学习这种技术来重用现有模型以解决领域特有的问题,并在普通的笔记本电脑上训练模型。
本书在很大程度上取材于我在世界各地的公司和研究机构上过的课程和做过的研讨,我喜欢当老师,因为我喜欢看到有人眼里发光,从中得到了启发。在ML 和AI 的课程开始时我经常会说:“我不是来教书的,我是来改变你们的人生的!”希望你们的人生会从读这本书开始变得有一点点不同,有一点点好。
运行本书的示例代码
作为工程师,最好通过动手实践来学习新东西,而不仅仅是读书。本书包含大量代码示例,你可以通过运行这些例子来巩固每一章所学的知识。这些例子中,大多数是用Python 来写的,使用的是流行的开源库,例如Scikit-Learn、Keras 和TensorFlow。所有这些都可以在我专门建的一个GitHub 公共存储库中找到(https://oreil.ly/applied-machine-learning-code)。这是所有代码示例的唯一来源,我会随时保持更新。
有一些机器学习平台允许在不写代码的情况下构建和训练模型。但要想了解这些平台能做什么以及具体如何做,建议你最好还是写写代码。Python 是一种简单的编程语言。很容易学。今天的工程师必须会写代码。你可以通过本书的例子来学习Python,如果已经掌握了Python(以及更常规意义上的编程),那么说明你其实已经领先别人一步了。
若是要在台式计算机或笔记本电脑上运行我在书中提供的例子,则需要安装64 位的Python 3.7 或更高版本。可以从Python.org 下载一个Python 运行时或者可以安装一个Python 发行版,例如Anaconda(https://oreil.ly/4NCqN)。另外,还需要确保已经安装了以下软件包及其依赖项:
- 用于构建机器学习模型的Scikit-Learn 和TensorFlow
- 用于数据处理和可视化的Pandas、Matplotlib 和Seaborn
- 用于图像处理的OpenCV 和Pillow
- 用于调用REST API 和构建网络服务的Flask 和Requests
- 用于开放神经网络交换( Open Neural Network Exchange,ONNX)模型的Sklearn-onnx 和Onnxruntime
- 用于从音频文件生成频谱图的Librosa
- 用于构建面部识别系统的MTCNN 和Keras-vggface
- 用于构建自然语言处理(Natural Language Processing,NLP)模型的KerasNLP、Transformers、Datasets 和PyTorch
- 用于调用Azure 认知服务(Azure Cognitive Services) 的Azurecognitiveservices- vision-computervision、Azure-ai-textanalytics 和Azurecognitiveservices-speech。
可以用 pip install 命令来安装其中大多数包。如果安装了 Anaconda,就表明其中许多包已经安装好了,可以用conda install 命令或类似的命令来安装其余的包。
至于环境,最好是用虚拟Python 环境来防止安装的这些包与其他包发生冲突。如果不熟悉虚拟环境,则可以在 Python.org 上阅读它们的相关信息。如果使用的是Anaconda,那么说明虚拟环境已经就位了。
我的大部分代码示例是为Jupyter 笔记本(Jupyter notebooks)构建的,后者为编写和执行Python 代码提供了一个交互平台。数据科学界经常使用“笔记本”来探索数据和训练机器学习模型。可以通过安装Notebook(https://oreil.ly/ZWQyG)或JupyterLab(https://oreil.ly/5A3Ia)等包在本地运行Jupyter 笔记本,也可以使用Google Colab(https://oreil.ly/RdRBa)等云托管环境。Colab 的优点是不必在自己的电脑上安装任何东西,就连Python 都不用。而且,在我的例子要求GPU的罕见情况下,Colab 也能为你提供GPU。
Python 开发环境难以设置和维护是出了名的,尤其是在Windows 电脑上。如果不想创建这样的环境,或者尝试过但没成功,那么下载一个东西就可以了。我在Docker容器镜像(https://oreil.ly/wzEbA)中打包了一个完整的开发环境,适合运行本书中的所有例子。如果你的电脑上安装了Docker 引擎(https://oreil.ly/XO5GD),那么可以用以下命令启动容器:
docker run -it -p 8888:8888 jeffpro/applied-machine-learning:latest
然后,在浏览器中访问输出结果中显示的URL,就会进入一个完整的Jupyter 环境,里面有我所有的代码示例和运行它们所需的一切。它们存储在一个文件夹中(名为Applied-Machine-Learning),该文件夹是从同名GitHub 存储库中克隆的。不过,使用容器有一个缺点,即所做的更改默认不会保存。补救办法之一是在docker 命令中使用-v 开关,从而绑定到一个本地目录。详情可以参考Docker 文档中的“绑定挂载”(https://oreil.ly/7wgda)。
本书导航
本书分为两部分。
- 第I部分(第1章~第7章)讲解机器学习的基础知识,介绍流行的机器学习算法,比如逻辑回归和梯度提升。
- 第II 部分(第8 章~第14 章)讨论深度学习。作为今天人工智能的代名词,它使用了深度神经网络来实现数学模型和数据拟合。
强烈建议在阅读本书时动手练习,以便能对这些内容有更深刻的理解,进而开始思考如何修改我在书中提供的代码,玩一玩“假如…?”(what if?)游戏。
本书采用的约定
本书采用了以下排版约定:
等宽字体(Constant width)
代码清单和段落中出现的程序元素(例如变量、函数、数据库、数据类型、环境变量、语句和关键字等)使用等宽代码字体。例如,from skl2onnx import convert_sklearn
等宽粗体(Constant width bold)
要由用户亲自输入的命令或其他字面值使用加粗的等宽字体。例如,请输入abc
这个视觉元素代表提示或建议
这个视觉元素代表常规的注意事项
这个视觉元素代表警告或提醒
使用代码示例
如前所述,本书的补充材料(代码实例、练习等)可以从https://oreil.ly/appliedmachine-learning-code 下载。
如果有技术问题或者在使用代码示例时遇到问题,请电邮至bookquestions@oreilly.com。
本书的目的是帮助大家完成自己的工作。一般来说,如果书中提供了示例代码,那么你可以在自己的程序和文档中使用。不需要联系我们获得许可,除非要复制代码的很大一部分。例如,写一个用到了本书几处代码的程序不需要许可。销售或分发O’Reilly 书中的示例则需要。引用本书正文和示例代码来回答一个问题不需要许可。将本书大量示例代码纳入你的产品文档,则需要许可。
我们感谢但一般不强求署名。如果要署名,通常应该包括标题、作者、出版商和ISBN。例如,Applied Machine Learning and AI for Engineers by Jeff Prosise(O’Reilly)。Copyright 2023 Jeff Prosise , 978-1-492-09805-8。
如果觉得对代码示例的使用超出了合理使用或上述许可的范畴,请随时联系我们:
permissions@oreilly.com。
推荐理由
《机器学习与人工智能实战:基于业务场景的工程应用》是一本非常实用的机器学习和人工智能方面的实战指南。这本书的推荐理由有以下几点:
- 丰富的实战案例:本书通过多个实际应用场景的案例,详细阐述了机器学习和人工智能的理论和应用,并给出了相应的代码实例,读者可以通过模仿这些实例来掌握机器学习和人工智能的实际应用。
- 专业的知识点讲解:本书通过对机器学习、深度学习、自然语言处理等方面的专业讲解,使读者能够深入了解这些技术的内部原理和工作机制。
- 实用的工具介绍:本书还介绍了一些常用的机器学习和人工智能工具和库,如Python、TensorFlow、Keras等,这些工具的介绍可以帮助读者更好地理解和应用这些技术。
- 面向实战的编程技巧:本书还介绍了一些面向实战的编程技巧,如数据清洗、特征工程、模型评估等,这些技巧可以帮助读者更好地解决实际业务问题。
- 深入浅出的讲解方式:本书的讲解方式非常深入浅出,循序渐进地给出了机器学习和人工智能的相关知识,并没有过多地使用专业术语和数学公式,使得读者可以更轻松地理解和掌握这些技术。
总之,《机器学习与人工智能实战:基于业务场景的工程应用》是一本非常实用的机器学习和人工智能方面的实战指南,适合想要了解和应用机器学习和人工智能的读者阅读。
粉丝福利
Part 1:
- 现在 点赞收藏评论 “人生苦短,python当歌”
- 评论区将随机抽取至多 五名 小伙伴 免费 赠书一本
Part 2:
- 现在关注文末公众号并回复 “抽奖” ,即可增加中奖概率哦
截止日期:2023年11月20日
写在后面
跟着兔子王学python,就选《机器学习与人工智能实战:基于业务场景的工程应用》!

版权归原作者 Want595 所有, 如有侵权,请联系我们删除。