
目录
最近在网上看到这样一篇非常离谱但不完全离谱的文章,文章标题为:torch.manual seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision,作者提出:尽管不同随机种子之间的效果标准差很小,但是仍然能够发现一些“异常点”,也就是使得模型表现相较于平均值特别好或者特别差的随机种子。
也就是说,现在立马把你模型的随机种子改成3407或者你自己的生日,即
torch.manual seed(3407)
,也许会得到一个奇妙而有趣的魔法效果。文章已收录至霍格沃茨的《魔法药剂与药水》(误)。
原文链接:https://arxiv.org/pdf/2109.08203.pdf
关于测试随机生成器种子对计算机视觉中普遍存在的深度学习模型结果的影响。他提出以下问题:
- 随机种子的不同导致的模型效果分布是怎样的?
- 是否有黑天鹅,即产生截然不同结果的种子?
- 对较大数据集进行预训练是否可以减少由选择种子引起的差异性?
针对以上问题,在CIFAR 10 数据集上,作者选取了10000个随机种子,每个随机种子进行30s的时间进行训练和测试,总耗时将近83小时。模型架构采用的是9层的ResNet,优化器SGD。为了保证部分实验中,模型是接近收敛的,因此作者对其中500次的结果训练时长延迟至1分钟。
另外,在ImageNet大型数据集上很难快速进行实验,因此作者使用预训练好的网络,然后仅对最后一层分类层进行初始化并从头训练。每次实验模型训练时间两小时,测试50秒。
一、收敛的不稳定性
首先选取500个随机种子在CIFA 10数据集上进行实验,效果如下图所示: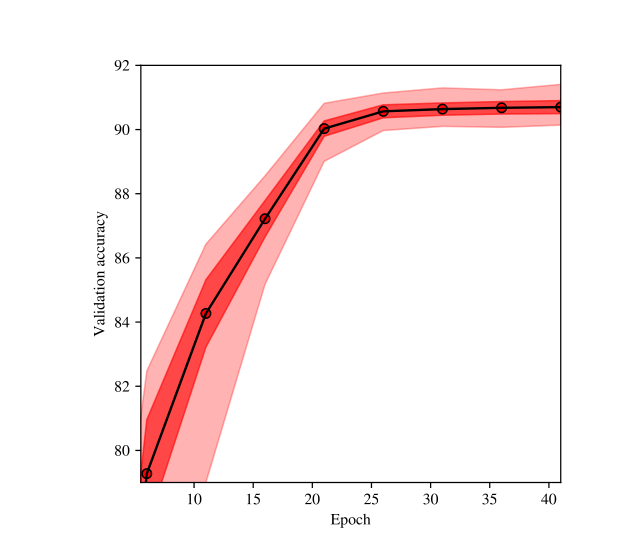
图1显示的是模型训练过程中的准确率趋势,实线表示超过500个种子的平均值,深红色区域对应一个标准偏差,浅红色对应最大值和最小值。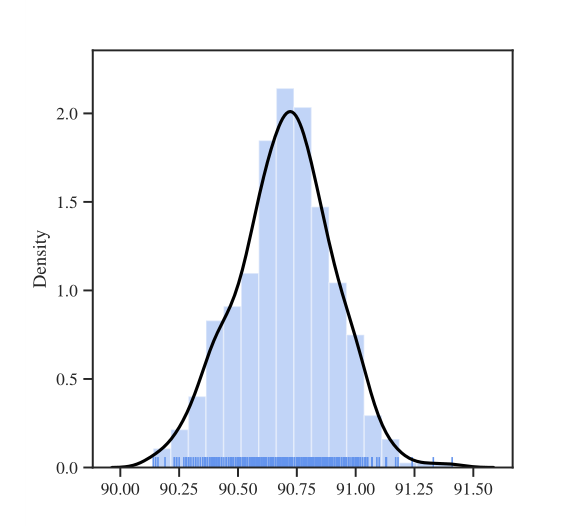
图2显示的是超过500个种子的CIFAR 10最终验证精度的柱状图和密度图。
- 模型在25个epoch后准确率就不增加了,说明训练收敛了。然而,准确率的标准差并没有收敛(红色区域并没有变小),说明训练更久不会减少随机种子带来的差异。(收敛前的浅红色区域减小并不能说明问题)
- 模型准确率大多集中在90.5%至91.0%左右,也就是说,如果不去刻意选取特别好或者特别差的随机种子的话,不同随机种子带来的准确率差异普遍为0.5%。
因此,第一个问题的答案为:随机种子的不同导致的模型效果分布是类似正态集中的。
二、寻找黑天鹅
作者同时设置长距离和短距离训练,在cifar 10得出准确率
然后设置扫描大量种子,去获得更高或更低的极端值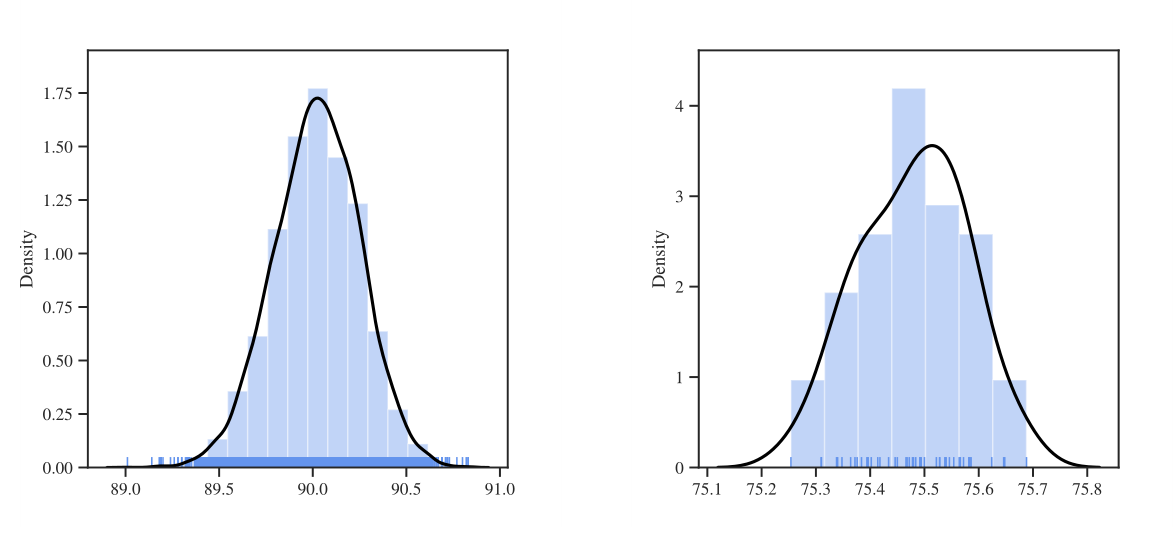
得到:
- 模型训练长比训练时间短效果更好。此外,在短训练时间条件下,准确率最小值和最大值相差为1.82%——可以说在深度学习领域里差距比较大了。
- 确实有一些种子能够产生足够好的分数(分别是坏的),被计算机视觉社区视为显著的进步(分别是降级)。
回到问题二,答案为深度学习中的黑天鹅确实存在,确实有种子表现得比较好或者比较差,这是一个比较令人担忧的结果,因为当前深度学习社区内,大多文章都是追求模型效果的,而这种较好的效果可能仅仅是由于随机种子引起的。
三、大规模数据集
根据在更大的数据集上进行预训练是否能减少由选择种子引起的差异性的问题
作者使用在Imagenet上对预处理模型进行微调和评估,以查看结合预处理模型使用更大的训练集是否可以减轻因选择种子而导致的分数随机性。得到结果如下:
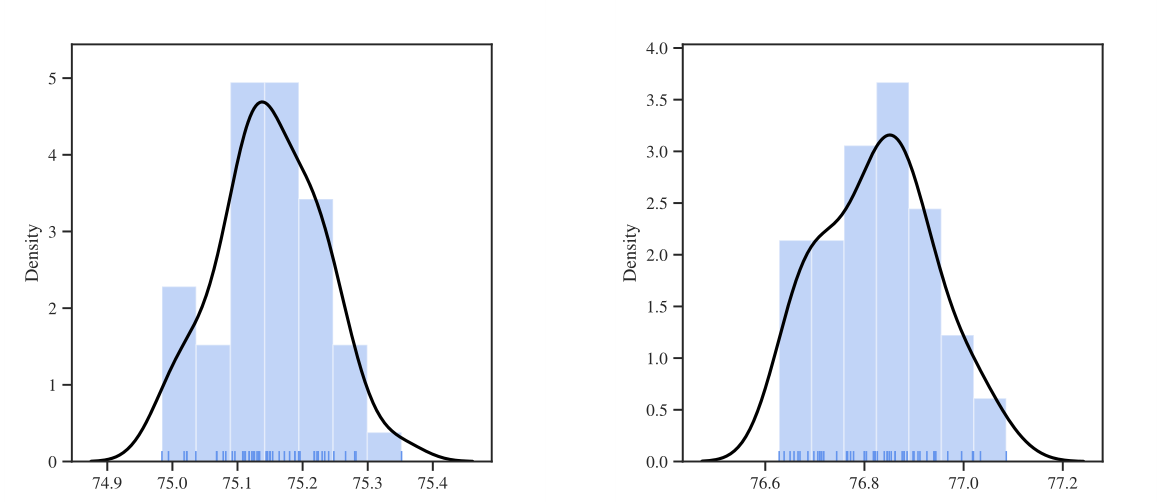
作者得出:大数据集的上的结果标准差是比CIFA 10小得多的,根据上表还是能够观察到大约0.5%的结果提升——这仅仅是由于随机种子引起的。然而,0.5%的准确率提高在CV领域已经可以算是很明显的提升了。
第三个问题的答案是复杂的:在某种意义上,是的,使用预处理模型和较大的训练集可以减少种子选择引起的变化。但是,对于计算机视觉社区所认为的改进来说,这种变化仍然是显著的。这是一个令人担忧的结果,尤其是因为预处理模型被大量使用的时候。
四、结论
- 问:关于随机种子选择的分数分布是什么?答:随机种子变化时的精度分布相对尖锐,这意味着结果相当集中于平均值。一旦模型收敛,这种分布就相对稳定,这意味着有些种子本质上比其他种子好。
- 问:是否有黑天鹅,即有些种子会产生截然不同的结果?答:是。在对104个种子的扫描中,作者获得了接近2%的最大和最小精度差异,这高于计算机视觉社区通常使用的重要阈值。
- 问:对较大数据集的预处理是否减轻了种子选择引起的变异?答:是,它当然减少了由于使用不同种子而产生的差异,但并没有抹去这种差异,在Imagenet上,最大和最小准确度之间的差异仍然有0.5%
后面作者也提出了自己的一些想法和嘲讽(误)
学术上来讲,严谨的实验应该进行随机性研究:随机取初始值,数据集分割,在其上建立多个模型,测效果,然后展示最小值和最大值,做均值和标准差。
五、实操Pytorch中的随机种子设置
话虽如此,但是我们也不妨试试随机种子在实验中的魔力。
训练模型过程中,会遇到很多的随机性设置,设置随机性并多次实验的结果更加有说服力。为了随机初始化权重(weight)和偏置(bias)等参数,但是现在发论文越来越要求模型的可复现性,这时候不得不控制代码的随机性问题。我们需要在训练模型之前进行随机种子的设定。如果种子设定为相同的,那么得到的初始权重就是一样的。
相关函数:
torch.manual_seed(number):为CPU中设置种子,生成随机数;
torch.cuda.manual_seed(number):为特定GPU设置种子,生成随机数;
torch.cuda.manual_seed_all(number):为所有GPU设置种子,生成随机数;
如果随机种子相同,每次运行随机函数生成的结果应该都是一样的,那么我们使用3407作为我们的随机种子:
import torch
torch.manual_seed(3047)print(torch.rand(1))
torch.manual_seed(3047)print(torch.rand(1))
输出为:
tensor([0.6995])tensor([0.6995])
版权归原作者 中杯可乐多加冰 所有, 如有侵权,请联系我们删除。