
倾向得分匹配(PSM),是一种模仿RCT随机对照试验随机化分组,提高组间均衡性,进而达到降低混杂因素影响目的一种数据处理策略。PSM在计量研究,临床医学等领域有着广泛的应用。
1.案例背景与分析策略
1.1 案例背景介绍
某企业想评价专项培训的效果,现收集到78位员工的个人及工作成绩信息,包括性别、年龄、教育年、初始工作成绩与当前工作成绩、工作经验、工作时间、职位类别、是否参加培训等数据。
数据上传SPSSAU后,在 “我的数据”中查看浏览原始数据,前5行数据如下:

图1 “我的数据”查看浏览数据集
1.2 明确目的与分析策略
已经参加过培训的有17人,其余61人没有参加过培训。研究培训的效果,我们似乎可以直接比较两组员工的工作成绩有无差异。
考虑到性别、年龄、工作经验、参加工作时间等本身会影响工作成绩,当两组人群不在一个起跑线起跑时,如果贸然直接对比当前工作成绩的差异,可能受到其他因素的干扰。
因此,我们应该寻找一批和参加培训员工基本情况类似,各关键指标特征接近的、未参加过培训的员工组成对照/控制组,然后进行组间差异的对比,从而判断培训效果。
倾向评分匹配,正是这样一种可以匹配对照,让处理组和对照组达到均衡的数据处理手段。SPSSAU在“计量经济研究”栏目下提供了【倾向得分匹配】功能。
完成匹配后,以当前工作成绩数据作为结果变量,是否培训为分组数据来探讨培训效果。
2.协变量选择与基线分析
倾向评分匹配PSM,首先需要构造PS评分概率数据,然后利用PS数据按某种匹配算法从所有待选的对照样本中选择合适对象完成匹配过程。
SPSSAU默认采用logistic回归模型构造PS数据,而用户则需要指定哪些数据作为协变量参与logistic回归计算PS值。
协变量的选择不是随意的,具体选择依据目前有多种观点。一般来说,协变量会影响结果变量,而且在干预组、对照组上也存在差异。当然专业知识、既往研究结论也可作为参考。
SPSSAU中协变量表述为特征项,本案例后面对协变量的描述统一采用特征项。
2.1 匹配前连续型特征项差异检验
已收集的特征项中,年龄、教育年、初始工作成绩、工作经验、工作时间,这5个为连续型数据。我们先考察培训组、未培训组在这些数据上是否基线无差异。
在SPSSAU“通用方法”栏目中执行【t检验】。结果如下:

图2 匹配前连续型数据t检验
由上表结果可知,两组员工在初始工作成绩、工作经验上存在统计学差异(均P值<0.05)。而在年龄、教育年、工作时间上无差异。
2.2 匹配前分类型特征项差异检验
同理,对性别、职位类别两个分类数据,做交叉表卡方检验,以考察匹配前两组员工在二者的分布差异。
在SPSSAU“通用方法”栏目中执行【交叉/卡方】。结果如下:

图3 匹配前分类型数据交叉表卡方检验
由上表结果可知,两组员工在职位类别的分布上存在统计学差异(P值<0.05),而性别分布上无差异。
2.3 特征项/协变量选择
综合基线分析、专业认知、既往研究结论,本案例拟将初始工作成绩、工作经验、职位类别共3个指标认定为本次PSM的特征项(协变量)。
以此3个特征项,通过logistic回归构造PS数据,从而实现匹配。
3.倾向得分匹配
3.1 匹配算法选择
倾向评分匹配算法有很多种,较常用的是最近邻匹配。SPSSAU提供了两种匹配算法,分别是最近邻匹配和半径匹配。前者是指PS值距离最近的进行匹配,后者需先指定卡钳值,在卡钳值范围内进行匹配。
原则上两种算法的匹配结论大致一样,可以根据匹配均衡性来选择,本例选择半径匹配。卡钳值采用多次遍历的形式,最终确定为0.05。具体理由文末有总结说明。
3.2 SPSSAU具体操作
在SPSSAU“计量经济研究”栏目下选择【倾向得分匹配】,首先将“是否培训”拖拽至【研究变量】框内,它将作为logistic回归的二结局因变量,特别注意水平编码,要求是1表示处理组,0表示对照组。
“初始成绩”、“工作经验”、“职位类别”拖拽至【特征项】框。

图4 SPSSAU倾向评分匹配具体操作
同时,本例建议将结果变量“当前成绩”拖拽至【结果变量】框。此操作展现了SPSSAU的特有优势,可以帮我们一步到位,既实现匹配,同时也完成匹配后数据的效果分析。
匹配算法选择半径匹配,卡钳值0.05。为方便理解,采用不放回策略。同时勾选【保存信息】,即要求输出匹配指示数据。具体操作见图4,最后点击“开始分析”即可。
4.倾向评分匹配结果解读
4.1 匹配概况
参加培训员工17人,因此需要匹配个数为17。采用卡钳值0.05的半径匹配后,匹配成功16人,SPSSAU此时进行的是1:1匹配,因此匹配后的数据总人数为32人。
通俗讲,匹配算法从未参加培训的61人中寻找到16人一一匹配给参加过培训的员工。
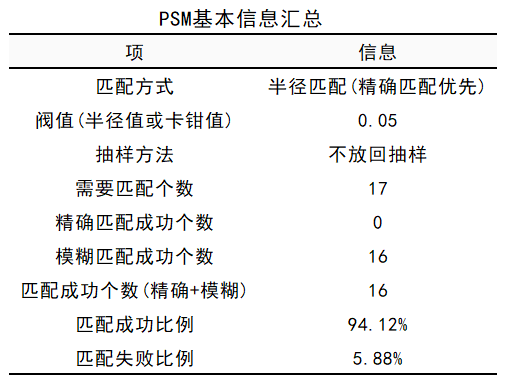
图5 PSM匹配概括
4.2 均衡性评价
匹配后,一定要进行均衡性、或平衡性评价,满足均衡条件后才表示匹配成功,如果均衡性不达标,应当返回重新进行匹配,直到满意为止。
在SPSSAU中,至少可以完成四项平衡性评价,本案例选择其中三项进行重点解读。
首先来看第一项:标准化偏差变化条形图

图6标准化偏差变化条形图
一般匹配后“标准化偏差”绝对值小于20%,则匹配效果较好。本例中,初始成绩、工作经验、职位类别匹配前的标准化偏差均在55%以上,匹配后,标准化偏差均低于20%,表明匹配后两组人群在这三个特征项上达到均衡。
第二项:核密度图
SPSSAU【倾向评分匹配】并未直接提供该图形,需要我们自己根据另存到原始数据中的匹配指示变量进行绘制。
新增的匹配指示变量中,Weight变量大于0,即匹配成功次数大于0,表明该样本为匹配成功的有效样本。
在SPSSAU的“可视化”栏目下,选择【核密度图】,打开【筛选样本】,输入条件:Weight > 0 ,这样做从数据集中筛选出匹配成功的32人数据,用于绘图。
图7 核密度前筛选匹配成功样本
“是否培训”拖拽至【定类X】框,其他特征项或其他变量可拖入【定类Y】框。
限于篇幅,本案例只展示“初始成绩”特征的匹配后核密度图。由图可见,匹配后两组密度曲线十分相似,能满足均衡要求。
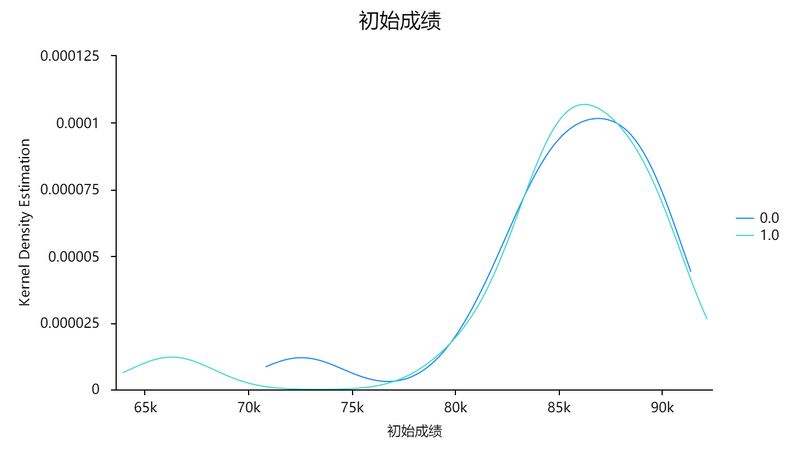
图8 匹配后初始工作成绩核密度图
第三项:匹配后基线分析
匹配前我们已经讨论过基线比较,匹配后也可以继续做基线分析,以判断匹配后两组数据在各特征项上有无差异。
连续型特征项用t检验,类别性特征项用卡方检验,我们直接看结果(t检验、卡方检验汇总后):

图9 匹配后特征项基线分析
如上表所示,匹配后,两组人群在初始成绩、工作经验、职位类别上差异无统计学意义(均P值>0.05)。即,匹配后基线特征由有差异趋于一致、均衡。综合以上三项结果,本例认为匹配后培训组、未培训组两组在特征上达到均衡,匹配效果良好。
5.效果分析
我们已经为17人的培训组,匹配到了一批特征类似,基线一致的对照(未培训组)。
本例的分析目的是考察培训的效果,结果变量“当前工作成绩”为连续型数据,因此执行t检验即可评价培训的效果。
但是我们并不需要去单独做t检验,因为SPSSAU在【倾向评分匹配】中包含了这一项重要工作。我们此前将当前成绩移入【结果变量】框,就是为了直截了当获得该项结果。
在SPSSAU中,这项工作称之为ATT效应分析。本例的结果:
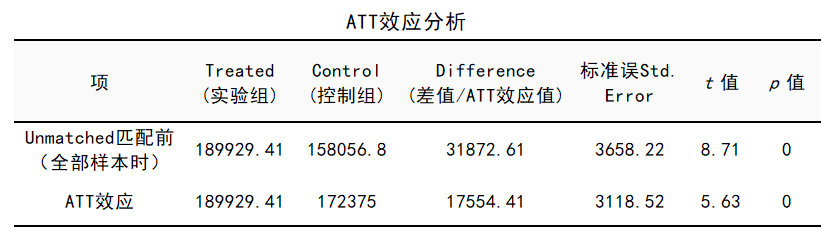
图10 匹配后ATT效应分析
“Unmatched匹配前”第1行数据是指在匹配之前,两组的当前工作成绩有统计学差异。
“ATT效应”第2行数据是指在匹配之后,两组的当前工作成绩存在显著差异(P值<0.05)。
说明在控制了干扰因素后,我们认为培训是有效果的。
6.总结
本例采用半径匹配算法,卡钳值多少合适呢?原则上并没有严格的规定或标准。
可以通过多次遍历的形式,比如第一次执行卡钳值0.3,然后评估匹配后平衡性及样本损失是否满足要求;如果不平衡,则返回调低卡钳值到0.1(或其他值)再进行同样操作,若仍不平衡,继续返回拉低卡钳值,比如0.05,或0.02,直至组间满足平衡要求,而且样本损失也在可接受水平。本例最终设定卡钳值为0.05。最近邻算法在没有卡钳值限定时,处理组样本通常会全部匹配成功,读者可以自行实践。
版权归原作者 spssau 所有, 如有侵权,请联系我们删除。