
- 摘要:联邦学习 - 将模型训练任务部署在移动边缘设备,参与者只需将训练后的本地模型发送到服务器参与全局聚合而无须发送原始数据,提高了数据隐私性.- 解决效率问题是关键 - 设备与服务器之间的通信消耗——通信——通信 具体来说:从边缘协调与模型压缩的角度讨论分析了通信优化方案- 模型收敛速率——训练 从设备选择、资源协调、聚合控制与数据优化4个方面讨论分析了训练优化方案- 移动边缘网络中存在的安全与隐私风险——安全隐私 从安全与隐私的角度讨论分析了联邦学习的保护机制- 基于边缘计算的思想提出了边缘化的联邦学习解决方案- 创新理念和未来展望 - 在数据优化- 自适应学习- 激励机制- 隐私保护- 传统以云为中心的深度学习的问题 - 网络负担- 数据隐私
- 联邦学习背景概述 - 深度学习模型 - 卷积神经网络CNN(多用于图像识别?)- 循环神经网络RNN(多用于自然语言处理?)- 生成式对抗网络GAN(多用于图像生成、转换、合成等领域)- 边缘计算 - 从联邦学习的设置来看,在移动设备上进行本地模型训练,服务器进行模型聚合,将主要的学习任务卸载到移动设备,这种基于边缘端以保护用户隐私的深度学习方式也顺应了边缘计算的模式。- 联邦学习与边缘计算之问还存在3方面的联系与相互作用: - 移动边缘网络中产生的数据需要联邦学习充分发挥其价值- 边缘计算可以利用大量的资源(包括计算资源!)丰富联邦学习的应用场景- 人工智能面向用户需要结合边缘计算和联邦学习作为基本架构- 深度学习中的隐私保护 - 差分隐私技术 - 方式:在模型训练过程添加一定的随机噪声- 缺点:保护数据隐私的同时模型精度会有所影响- 同态加密 - 方式:密文上做运算,运算结果解密后与明文运算的结果相同- 缺点:对于存在大量的非线性计算的深度学习模型,算法的计算开销十分高昂- 多方安全计算 - 方式:假设有多个参与方,它们拥有各自的数据集,在无可信第三方的情况下,通过计算一个约定函数,要求每个参与方除了计算结果外不能得到其他参与方的任何输入信息- 缺点:多次传输,通信开销较大- 联邦学习 - 概念与架构 - 本地训练本地模型- 上传参数聚合(平均算法FedAvg)- 更新全局模型- 将新的全局模型作为新一轮的共享模型发送到参与设备迭代训练- 联邦学习分类 - 根据数据不同的特点分类安全验证 - 知乎 - 横向
 - “横向”表示数据是横向(按行)划分的,特征不变- 不同地区的银行,业务(特征空间)很相似,但是用户(样本ID)的交集非常小- 纵向
- “横向”表示数据是横向(按行)划分的,特征不变- 不同地区的银行,业务(特征空间)很相似,但是用户(样本ID)的交集非常小- 纵向  - 纵向表示数据是纵向(按列)划分的,样本的ID空间不变- 同一地区的银行和电子商务公司,两者业务(特征)不同,但由于处于同一地区,用户(样本ID空间)基本都是一样的。- 迁移
- 纵向表示数据是纵向(按列)划分的,样本的ID空间不变- 同一地区的银行和电子商务公司,两者业务(特征)不同,但由于处于同一地区,用户(样本ID空间)基本都是一样的。- 迁移 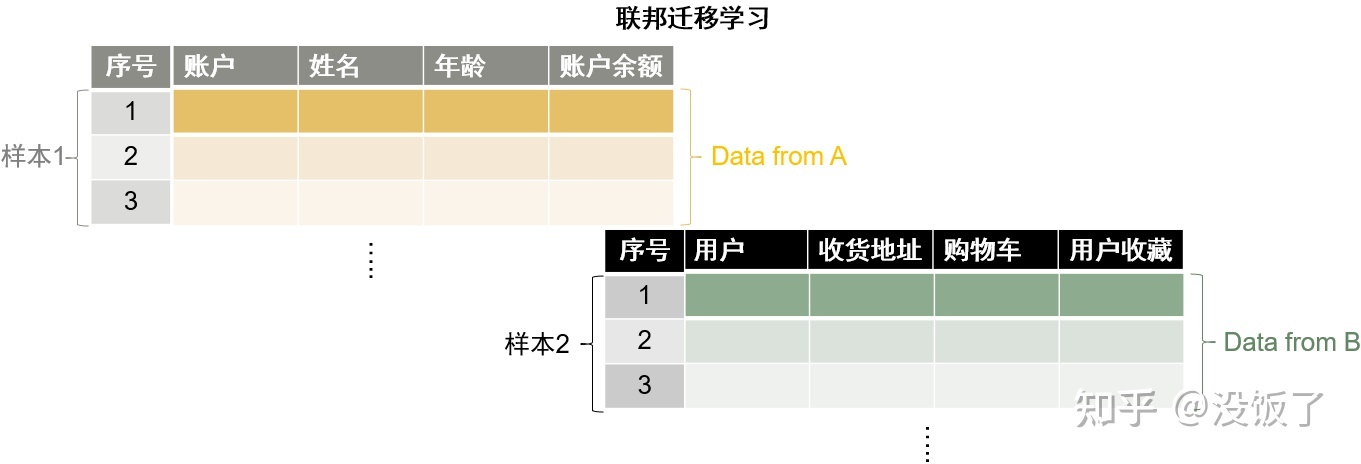 - 是纵向联邦学习的一种特例- 两个或多个数据集在特征空间(X)和样本ID空间(Y)上都没有相同点- 不同地区的银行和电子商务公司,业务(特征)和用户(样本ID空间)都没有交集。- 联邦学习的三种特性 - 通信环境不稳定- 资源约束- 安全与隐私问题
- 是纵向联邦学习的一种特例- 两个或多个数据集在特征空间(X)和样本ID空间(Y)上都没有相同点- 不同地区的银行和电子商务公司,业务(特征)和用户(样本ID空间)都没有交集。- 联邦学习的三种特性 - 通信环境不稳定- 资源约束- 安全与隐私问题 - 联邦学习优化问题 - 联邦学习的三个步骤中,通信问题是影响联邦学习效率的主要因素- 通信 联邦学习的通信消耗远远大于计算消耗 - 边缘计算协调 - 利用边缘计算的优势,可以把更多的计算任务卸载到边缘设备- 增加本地训练迭代次数或更多的计算- 使用更合理的模型聚合方式或更快速的模型收敛方法,也可以减少通信次数- 模型传输消耗 - 模型压缩- 梯度量化和梯度稀疏化技术- 训练 - 移动设备异构 - 联邦学习协议 - 联邦学习整体的训练过程受到训练时问最长的设备的影响- 新的联邦学习参与者选择协议- 服务器聚合频率 - 全局聚合的传统方法是同步方法- 种选择性聚合:尽可能聚合正确的本地模型- 数据质量 - 解决移动设备上数据的non—iiD问题是非常关键的- non—iiD(非独立同分布) - 不独立同分布- 独立不同分布- 不独立也补同分布- 模型收敛 - SGD,随机梯度下降- MGD,动量梯度下降法- MFL,动量联邦学习- 自适应调整的FedProx算法 - 如果损失较大,则在聚合之前对本地模型再次进行训练,以提高学习效率.- 安全和隐私 - 中毒攻击 - 数据中毒.恶意参与者可以通过创建脏标签数据来训练模型,以产生错误的参数,降低全局模型的准确性。- 模型参数中毒.攻击者可以直接修改模型的参数。- 后果 - 用户不再信任联邦学习服务器
- 现有的方案 - 通信优化 - 增加边缘端的计算 - 两种方式 - 增加任务并行性,每一轮选择更多的设备- 增加设备的计算,每一个设备执行更多的训练任务- FedAvg算法 - 将本地的一次梯度计算改进为多次,即设备进行多次本地训练- 有最大平均偏差(maximum mean discrepancy,MMD)的双流联邦学习模型 - 可以使参与设备在每一轮的本地训练中保留全局模型作为参考- 通过最小化全局模型与本地模型之问的损失来保证设备学习到其他设备数据之外的特征,从而加快模型收敛的进程,减少通信的轮数- 将深度强化学习技术和联邦学习框架与移动边缘系统相结合,以对MEC、缓存和通信进行优化. - 设计了一个"In—Edge—AI"框架, - 实现动态的优化和增强效果,同时减少不必要的系统通信负载.此框架通过深度强化学习来共同管理与优化边缘通信和计算资源,并通过联邦学习来分布式地训练深度强化学习代理- 引入了MEC平台作为联邦学习的中问层.该文作者提出了一种分层的联邦学习架构用来减少用户和云之间的通信轮数- HierFAVG分层联邦学习平均算法 - 利用边缘层节点的计算能力,在联邦学习服务器全局聚合前,使边缘服务器聚合多个设备的本地模型,以减少设备的通信连接次数.- 模型压缩 - 提出了基于通信效率的CE—FedAvg算法 - 结合均匀量化和指数量化2种方法来减少每轮训练上传的总数据量与通信的次数- 优势在于能够以更少的通信轮次来使模型达到收敛,同时压缩了上传的数据,大大减少了通信损耗- 模型剪枝与联邦学习相结合的方法 - 剪枝包括在服务器上对初始模型剪枝和在设备上对本地模型的剪枝,其他部分与传统的联邦学习过程保持一致.- 当模型训练和剪枝同时反复进行后,最终会得到一个小尺寸的模型.- 基于模型压缩的思想提出了结构化更新和概略化更新2种方法 - 结构化更新的目的是使本地模型在具有较少变量的有限空间结构(例如低秩或随机掩码)上进行更新与训练- 概略化更新指的是在与服务器通信之前,结合量化、随机旋转与子采样等压缩形式对模型进行编码,然后在服务器聚合之前对模型解码的方法- 基于边缘随机梯度下降(edge stochasticgradient descent,eSGD)的方法 - 首先,eSGD确定哪些梯度坐标是重要的,并且只将重要的梯度坐标传输给云进行同步.- 其次,使用动量残差累积来跟踪过期的残差梯度坐标,以避免稀疏更新导致的低收敛速度.- 利用了梯度稀疏化- 有损压缩技术- 联邦Dropout技术- 稀疏三元压缩(sparse ternary compression,STC)- 归纳总结 - 设计权衡通信消耗与模型收敛的算法来提高联邦学习整体的效率仍然是重要的研究点.- 训练优化 - 设备选择 - FedCS - 该协议基于MEC框架- 根据设备的资源状况动态地选择设备参与并有效地执行联邦学习- 是尽可能多地选择性能强大的参与设备- 基于多标准的联邦学习设备选择方法,并预测设备是否能够执行联邦学习任务- 在保证模型的测试精度的前提下选择最佳的设备参加训练- 联邦学习设备选择和带宽分配制定了一个随机优化问题- 从最小模型交换时间的角度研究联邦学习中的设备选择方案,并使用动态队列量化设备的参与率.- 资源协调 一般情况下,移动边缘网络环境是动态的、不确定的,设备所拥有的资源时刻都在变化 - 文献76: 移动群组机器学习的高效培训管理:一种深度强化学习方法 Anh T,Luong N,Niyato D,et a1.Efficient trainingmanagement for mobile crowd-machine learning:A deepreinforcement learning approach[J]. IEEE WirelessCommunications Letters,2019,8(5):1345—1348 - 基于移动群体机器学习(mobilecrowd-machine learning,MCML)的联邦学习模型- 基于双深度Q—Network[77]的算法,允许服务器在不具备任何网络动态先验知识的情况下学习并找到最优决策- 文献78 公平的资源分配-深入学习 Li Tian,Sanjabi M,Smith V.Fair resource allocation infederated learning EJ].arXiv preprint,arXiv:1905.10497,2019 - 不可知的联邦学习框架- 提出了公平联邦学习(q—fair federated learning,q—FFL)资源分配的优化目标- 为了解决q-FFL问题,文献E78]的作者相应地设计了一种适合于联邦学习的高效率方案q—FedAvg- 文献79 用于低延迟联邦边缘学习的宽带模拟聚合 Zhu Guangxu,Wang Yong,Huang Kaibin.Broadbandanalog aggregation for low—latency federated edge learning[J].IEEE Transactions on Wireless Communications,2020,19(1):491-506 - 基于空中计算的带宽模拟聚合技术(broad—band analog aggregation,BAA)的联邦学习框架- 文献81 联合边缘学习的能量高效传输资源分配 Zeng Qunsong,Du Yuqing,Leung K,et a1.Energy-efficientradio resource allocation for federated edge 1earning[c/OL]//Proc of the 26th IEEE Int Conf on CommunicationsWorkshops.Piscataway,NJ:IEEE,2020[2021-09—08]. - 提出了一种高效节能的带宽分配和调度策略 - 该策略将更多的带宽资源分配给那些信道较弱或计算能力较差的调度设备- 封闭式的调度优先级函数对具有更好的信道状态和计算能力的设备具有优先偏向- 结论 - 实验证明了所提出的策略能够降低大量的能耗,同时保证了模型训练的速率- 文献82 边缘计算中带宽分割的联合学习 Li Jun,Shen Xiaoman,Chen Lei,et a1.Bandwidth slicing toboost federated learning in edge computing[J].arXivpreprint,arXiv:1911.07615,2019 - 引入了带宽切片来支持联邦学习- 聚合控制 - 文献83 地理空间应用的异步联合学习 Sprague M,Jalalirad A,Scavuzzo M,et a1.Asynchronousfederated learning for geospatial applications[c]//Proc ofthe 26th Joint European Conf on Machine Learning andKnowledge Discovery in Databases.Berlin:Springer,2018:21-28 - 新的异步联邦学习算法,只要设备的本地训练完成,即可上传本地模型. - 该异步模型允许参与设备在联邦学习训练过程中,只要训练完本地模型就可以立即上传到服务器进行聚合- 该异步具有鲁棒性(Robust)- 文献84 资源受限边缘计算系统中的自适应联合学习[J].IEEE通信选择领域杂志 Wang Shiqiang,Tuor T,Salonidis T,et a1.Adaptivefederated learning in resource constrained edge computingsystems[J]. IEEE Journal on Selected Areas inCommunications,2019,37(3):1205—1221 - 基于梯度下降的训练方法,提出了一种自适应的全局聚合方案- 该算法能够确定本地更新和全局参数聚合之间的最佳折中,- 全局聚合前可以多进行边缘聚合,找到最平衡的一点- 文献85 缓解联合学习的通信开销 Wang Luping,Wang Wei,Li Bo.CMFL:Mitigatingcommunication overhead for federated learning It]/Proc ofthe 39th IEEE Int Conf on Distributed Computing Systems.Piscataway,NJ:IEEE,2019:954—964 - 提出了一种提高联邦学习通信与训练效率的模型选择性聚合算法CMFL(communication-mitigated federated learning) - .关键思想是识别和排除有偏差的、与全局收敛不相关的本地更新.- 判断相关性,相关性低的直接丢弃- 文献86 无线计算联合学习 Yang Kai,Jiang Tao,Shi Yuanming,et a1.Federatedlearning via over-the—air computation[J].IEEE Transactionson Wireless Communications,2020,19(3):2022-2035 - 提出了基于空中计算的快速全局模型聚合方法.- 该方法通过设备选择和波束成形设计来实现,能够在满足模型聚合的均方误差要求下最大化所选参与联邦学习的设备数量- 数据优化 - 文献87 联合学习与客户额外机制以降低通信成本 Yao Xin,Huang Tianchi,Wu Chenglei,et a1.Federatedlearning with additional mechanisms on clients to reducecommunication costs[J].arXiv preprint,arXiv:1 908.05891,2019 - 首先采用基于最大平均差异算法的联邦双流模型FedMMD(federated maximum mean discrepancy),以解决在传统联邦学习设置下,设备上训练单一本地模型的不足- 者进一步提出了具有特征融合机制的联邦学习算法(federated learning feature fusion,FedFusion),以降低通信成本.- 文献88 设备上的通信效率机器学习:非IID私有数据下的联合蒸馏和增强 Jeong E,Oh S,Kim H,et a1.Communication—efficient on—device machine learning: Federated distillation andaugmentation under non—IID private data[J].arXivpreprint,arXiv:1811.11479,2018 - 联邦扩展(federated augmenta-tion,FAug)方案,其中每个设备共同训练一个生成模型,每个设备可以使用生成模型生成缺失的数据样本,从而将其本地数据扩展为一个liD数据集. - 所谓的目标标签,并通过无线链路将这些目标标签的少数种子数据样本上传到服务器.服务器对上传的种子数据样本进行过采样,从而训练出一个GAN模型.- 每个设备可以下载经过训练的GAN生成器使每个设备能够补充目标标签,直到得到一个平衡的IID数据集.- 文献89 .非IID数据的联合学习 Zhao Yue,Li Meng,Lai Liangzhen,et a1.Federatedlearning with non—IID data[J].arXiv preprint,arXiv:1806.00582.2018 - 对于高度倾斜的non—IID数据集训练的神经网络,最高会使联邦学习的精度降低55%左右.该文作者进一步证明了这种精度下降可以用权值散度来解释- 通过创建一个在所有边缘设备之间全局共享的数据子集来缩小每个模型之间的距离,从而改进对non—IID数据的训练效果.- 文献90 无线网络中使用非IID数据的合作学习机制 Yoshida N,Nishio T,Morikura M,et a1.Hybrid—FL:Cooperative learning mechanism using non—IID data inwireless networks[J].arXiv preprint,arXiv:1905.07210,20]9 - 提出一个新颖的学习机制Hybrid—FL- 服务器使用从隐私敏感度低的设备收集的数据来构造部分IID数据- 服务器利用构造的数据训练模型并聚合到全局模型中来更新模型,- 文献92 异步联合优化LJJ.arXiv预打印 Xie Cong, Koyejo S, Gupta I.Asynchronous federatedoptimization LJJ.arXiv preprint,arXiv:1903.03934,2019 - 提出了基于non-IID数据集的异步联邦优化FedAsync算法- 提出了一个混合超参数来控制由延迟影响的模型权重.每个新接收的本地更新根据时效性自适应加权,时效性定义为当前训练迭代与所接收更新所属迭代的差值.- 文献93 克服非IID数据联合学习中的遗忘 Shoham N,Avidor T,Keren A,et a1.Overcomingforgetting in federated learning on non—IID data[J].arXivpreprint,arXiv:1910.07796,2019 - 在损失函数中加入一个惩罚项,迫使所有本地模型收敛到一个共享最优值.- 归纳总结 - non—IID数据仍是影响模型收敛最重要的因素,要想保证模型训练的准确度,就必须优化数据的non—IID问题- 安全与隐私保护 - 安全 - 文献94 针对联合学习系统的数据中毒攻击 Tolpegin V,Truex S,Gursoy M,et a1.Data poisoningattacks against federated learning systems[c]//Proc of the24th European Symp on Research in Computer Security.Berlin:Springer,2020:480—501 - 即使有一小部分恶意参与者,此类数据中毒攻击也会导致分类准确度和召回率的大幅下降.- 文献95 缓解梅毒感染的学习中毒 Fung C,Yoon C,Beschastnikh I.Mitigating sybils infederated learning poisoning[J].arXiv preprint,arXiv:1808.04866.2018 - 基于女巫攻击的数据中毒对联邦学习系统的影响- 为了减轻女巫攻击,该文作者提出了一种称为FoolsGold的防御策略. - 该方案的关键思想是可以根据更新的梯度将诚实的参与者与女巫攻击者区分.- 文献96 防范协作式深度学习系统中的中毒攻击 Shen Shiqi, Saxena P.AUROR:Defending againstpoisoning attacks in collaborative deep learning systems[C]//Proc of the 32nd Annum Conf on Computer SecurityApplications.New York:ACM,2016:508—519 - 提出了一个检测恶意用户并生成准确模型的系统,用户不再向服务器传送模型梯度而是上传伪装特征,并设计了一种基于这些伪装特征的自动统计机制来抵御数据中毒攻击- 文献97 通过对抗性视角分析强化学习 Bhagoji A,Chakraborty S,Mittal P,et a1.Analyzingfederated learning through an adversarial lens[J].arXivpreprint,arXiv:1811.12470,2018 - 提出了一些防止全局模型受到恶意本地模型影响的解决方案 - 第1种解决方案,根据移动设备共享的更新模型,服务器可以检查共享模型是否有助于提高全局模型的性能;- 第2种解决方案是移动设备上的互相比较- 文献98 移动网络的可靠联合学习 Kang Jiawen,Xiong Zehui,Niyato D,et a1.Reliablefederated learning for mobile networks EJ].IEEE WirelessCommunications,2020,27(2):72-80 - 引入了信誉的概念作为度量指标,以防止设备发送不可靠或恶意的模型更新等危险行为- 文献99 联合学习中的异常客户行为检测口 Li Suyi,Cheng Yong,Liu Yang,et a1.Abnormal clientbehavior detection in federated learning口].arXiv preprint,arXiv:1910.09933,2019 - 利用预先训练好的异常检测模型来检测移动边缘网络中存在异常行为的设备,及时消除恶意用户对全局模型以及联邦学习系统产生的不利影响.- 隐私保护 - 文献100 c]/Proe联合学习的用户级隐私泄露 Wang Zhibo,Song Mengkai,Zhang Zhifei,et a1.Beyondinferring class representatives: User-level privacy leakagefrom federated learning Ec]/Proe of the 38th IEEE Conf onComputer Communications(INFOCOM 2019).Piscataway,NJ:IEEE,2019:2512—2520 - 将服务器设置成恶意的,当进行全局模型聚合时,通过利用设备发送到服务器的本地模型,结合GAN网络模型共同推断并精准地伪造出受害者设备上的一些隐私数据- 文献101 关于计算机和通信安全的深度学习 Abadi M,Chu A,Goodfellow I,et a1.Deep learning withdifferential privacy[c]/Proc of the 23rd ACM SIGSACConf on Computer and Communications Security.NewYork:ACM,2016:308-318 - 介绍了一种称为差分隐私的随机梯度下降技术- 文献102 具有差分隐私的安全联合平均算法 Li Yiwei,Chang T,Chi C.Secure federated averagingalgorithm with differential privacy[C/OL]/Proc of the30th IEEE Int Workshop on Machine Learning for SignalProcessing.Piscataway,NJ:IEEE,2020[2021—09—08].https://ieeexplore.ieee.org/document/9231531 - ]将差分隐私技术应用到联邦学习环境,关键思想是在模型参数发送到服务器之前,在移动设备上部署差分隐私技术,在训练后的本地参数上添加一些噪声- 文献103 《不同的私人联合学习:客户层面的视角》 Geyer R,Klein T,Nabi M.Differentially private federatedlearning:A client level perspective EJ].arXiv preprint,arXiv:1712.07557,2017 - 提出了一种更全面的隐私保护方案.对于每个训练轮次,服务器首先选择随机数量的参与者以训练全局模型,然后进一步在模型参数上添加噪声
- 未来研究方向 - 基于更多边缘计算的联邦学习 - 当前大多数都是基于云和端2层学习架构,直接通信会带来更多的能耗和通信成本- 新兴的“边缘智能”成为一种技术趋势 - 三层结构:云——边——端- 充分利用边缘层的价值!!!- 边缘化学习的优势 - 低时延与低能耗- 高安全性与高隐私性- 易管理- 易扩展- 针对联邦学习的数据清洗 - 数据质量是模型快速收敛的关键- 减小本地模型训练的误差,大大提高联邦学习模型的学习效果- 自适应联邦学习 - 自适应通信与训练时间的折中- 自适应本地训练- (自己的理解就是鱼“通信”与熊掌“训练优化方案”不可兼得的情况下,如何最优化平衡两边的分布,达到最好的结果)- 激励机制与服务定价 - 出现两种很不好的情况 - “只进不出”,还受益于训练好的全局模型,但没有对全局模型做出贡献- “互相争抢”,联邦学习服务器可能正在与其他服务器竞争,在极端情况下,服务器可能接收不到设备的本地模型- 需要一种新颖的服务定价机制来考虑用户的服务消耗及其数据贡献的价值- 资源友好的安全与隐私保护 - 目前的联邦学习隐私保护方案依赖于传统的加密与数据扰动的方式 - 差分隐私 - 优点在于添加随机噪声不会造成过高的性能代价- 缺点在于扰动机制将可能使模型精度变差- 同态加密 - 虽然能够保证数据在存储、传输与计算过程中的隐私与安全- 但加密过程涉及大量的复杂计算和密钥传输,对于复杂模型来说,计算和通信的开销都非常大.- 对隐私的保护虽然重要,而对于隐私保护的可行性更为重要- 未来方向研究轻量级的安全与隐私保护策略- 联邦学习与前沿技术结合 - 个性化???- 去中心化 - 基于区块链的联邦学习除了可以实现去中心化,还能避免数据或模型受到攻击,提高效率的同时还能增强系统的稳定性- 联邦学习与智能场景结合 - 计算卸载与缓存(为保护隐私,实现了最优边缘缓存)- 车联网(为保护隐私)- 智能医疗(为保护隐私)
- 思考与总结 - 1、两篇综述结构上的简单对比思考 - 感觉自己上一篇的英文文献的综述真的是层层递进的,经常是下一篇论文的技术是基于上一篇的改进,而这一片综述就比较散- 不知道是这两个领域的技术差别还是论文质量差别?- 2、 本文研究 - 研究的就是在移动边缘网络中,对于联邦学习效率优化的方式 - 通过三个步骤进行优化 - 通信(重中之重!)- 训练- 安全和隐私- 3、目前做的如何 - 通信优化主要是以 - 充分利用边缘计算协调,把更多计算任务卸载到边缘设备,增加本地训练次数,从而减少通信次数- 压缩模型,减少传输消耗- 训练优化主要是以 - 优化联邦学习协议- 优化服务器聚合方式,不再是同步方法而选择性聚合- 解决non-IID数据的问题,提高数据质量- 优化模型收敛的方式- 安全和隐私主要是以 - 预防中毒攻击- 让用户信任联邦学习服务器- 4、尚存的问题也就是未来的研究方向 - 进一步优化通信问题的第一个问题,将基于更多边缘计算,从“云——端”到“云——边——端”。- 进一步压缩模型,针对联邦学习的数据清洗,优化数据质量!- 进一步提高自适应联邦学习的算法,使得通信与训练时间的折中“将两碗水端平”- 进一步优化未来方向研究轻量级的安全与隐私保护策略- 提出了激励机制和服务定价的想法:需要一种新颖的服务定价机制来考虑用户的服务消耗及其数据贡献的价值- 提出了联邦学习与前沿技术结合- 提出了联邦学习与智能场景结合
本文转载自: https://blog.csdn.net/weixin_42303403/article/details/129362801
版权归原作者 Zh1N1an 所有, 如有侵权,请联系我们删除。
版权归原作者 Zh1N1an 所有, 如有侵权,请联系我们删除。