
摘要:在本文中,我们提出了一个新的注意模块,与大多数现有模型相比,该模块不仅实现了最佳性能,而且参数更少。由于其轻巧的特性,我们的注意力模块可以轻松地与其他卷积神经网络集成。双多尺度注意网络 (DMSANet) 的网络由两部分组成: 第一部分用于提取各种尺度的特征并将其聚合,第二部分并行使用空间和通道注意模块来自适应地集成本地特征及其全局依赖性。我们对我们的网络性能进行了基准测试,以在ImageNet数据集上进行图像分类,在MS COCO数据集上进行对象检测和实例分割。
引言
卷积神经网络的局部感受野。在著名的InceptionNet (Szegedy等人,2016) 中使用的多尺度体系结构聚合来自不同大小的卷积核的多尺度信息。注意网络最近引起了很多注意,因为它允许网络只关注重要方面,而忽略那些无用的方面 (Li等人,2019) 、 (Cao等人,2019) 和 (Li等人,2019)。
在计算机视觉中使用注意机制已经成功解决了许多问题,例如图像分类,图像分割,对象检测和图像生成。大多数注意机制可以大致分为两种类型,通道注意和空间注意,这两种类型都通过聚合来自不同维度的信息来增强原始特征 (Zhang等,2021)。
一些工作将这两种机制结合在一起并获得了更好的结果 (Cao等人,2019) 和 (Woo等人,2018)。通过 (Wang等人,2020) 使用有效的信道注意和1 × 1卷积来减少计算负担。最受欢迎的关注机制是挤压和激励模块 (Hu等人,2018b),它可以以相当低的成本显著提高性能。使用 “通道shuffle” 运算符 (Zhang和Yang,2021) 来实现两个分支之间的信息通信。它使用分组策略,该策略将输入特征图沿通道维度划分为组。
相关工作
有两个主要问题阻碍了这一领域的进展: 1) 空间和通道注意力以及使用两者结合的网络只使用本地信息,而忽略了远程通道依赖性,2) 以前的体系结构无法捕获不同尺度的空间信息。这两个挑战分别由 (Duta等人,2020) 和 (Li等人,2019) 解决。这些体系结构的问题在于参数的数量大大增加。
金字塔分裂注意力 (PSA) (Zhang等人,2021) 具有在多个尺度上处理输入张量的能力。多尺度金字塔卷积结构用于在每个通道特征图上集成不同尺度的信息。提取了多尺度特征图的逐通道注意力权重,因此完成了长距离通道依赖性。
提出了非本地块 (Wang等人,2018) 来构建密集的空间特征图并使用非本地操作捕获长距离依赖性。(Li等人,2019) 使用了一种动态选择注意机制,该机制允许每个神经元基于输入特征图的多个尺度自适应地调整其感受野大小。(Fu等人,2019) 提出了一种网络,通过将来自不同分支的这两个注意模块相加,将本地特征与其全局依赖项集成在一起。
多尺度架构已经成功地用于许多视觉问题 。(Fu等人,2019) 通过将来自不同分支的两个注意模块相加,自适应地将局部特征与其全局依赖性相结合。(Hu等人,2018a) 使用空间扩展使用深度卷积来聚合单个特征。我们的网络借鉴了 (Gao等人,2018) 的想法,该想法使用网络来捕获本地跨信道交互。
方法
特征分组
Shuffle注意模块将输入的特征图进行分组,并使用Shuffle单元将通道注意和空间注意集成到每个组的一个块中。子特征被聚合,并且 “channel shuffle” 运算符用于在不同的子特征之间传递信息。

对于给定的特征图X ∈ RC × H × W,其中C,H,W分别表示通道编号,空间高度和宽度,shuffle模块沿通道维度将X分为G组,即X = [X1,XG],Xk ∈ RC/G × H × W。注意模块用于加权每个特征的重要性。Xk的输入沿信道维度Xk1分为两个网络,Xk2 ∈ RC/2G × h × w。所述第一分支用于利用渠道的关系生成渠道关注图,所述第二分支用于利用不同特征的空间关系生成空间关注图。
通道注意力模块
SE注意力
通道注意模块用于选择性地对每个通道的重要性进行加权,从而产生最佳输出特征。这有助于减少网络的参数数量。SE块由两部分组成: 挤压和激励,分别设计用于编码全局信息和自适应地重新校准信道关系。全局平均池 (GAP) 操作可以通过公式1所示的计算

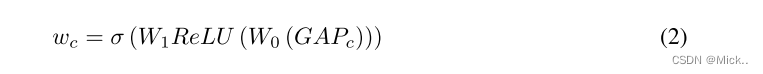
作者提出的

我们从原始特征A ∈ rc × h × w计算通道注意图X ∈ rc × c。我们将A重塑为rc × n,然后在a和A的转置之间进行矩阵乘法。然后,我们应用softmax层来获得通道注意图X ∈ rc × c,如等式3所示
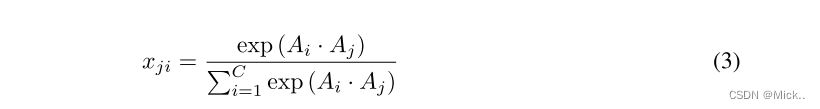
其中xji测量第i个通道对第j个通道的影响

个人的理解:作者首先分析了SEblock,先对空间维度进行压缩得到通道描述符,然后进行自适应重新校准得到各个通道之间的重要程度。作者提出的注意力机制是应用矩阵乘法得到一个C*C的矩阵X,X(i,j)表示第i个通道对第j个通道的影响,然后对其进行softmax归一化到0-1.最后作者用了一个线性变换。
空间注意模块
我们使用Xk2上的实例归一化 (IN) 来获得空间统计信息。Fc() 操作用于增强xk2的表示。通过W2和b2是形状为RC/2G × 1的参数来获得空间注意力的最终输出。之后,将两个分支连接起来,以使通道数等于输入数。
用A ∈ rc × h × w表示的局部特征被馈送到卷积层中以分别生成两个新的特征图B和C,其中B,C ∈ rc × h × w。我们将它们重塑为rc × N,其中N = H × w是像素数。接下来,在C和B的转置之间进行矩阵乘法,并应用softmax层来计算空间注意力图S ∈ rn × n。

个人的理解:这里是将特征图先送入一个卷积层,得到两个特征图,两个特征图进行矩阵相乘,得到空间注意力特征图。
聚合
在网络的最后一部分中,所有子功能都被聚合。我们使用 “channel shuffle” 运算符来启用沿通道维度的跨组信息流。我们模块的最终输出与输入的输出大小相同,使我们的注意力模块非常容易与其他网络集成.

网络结构
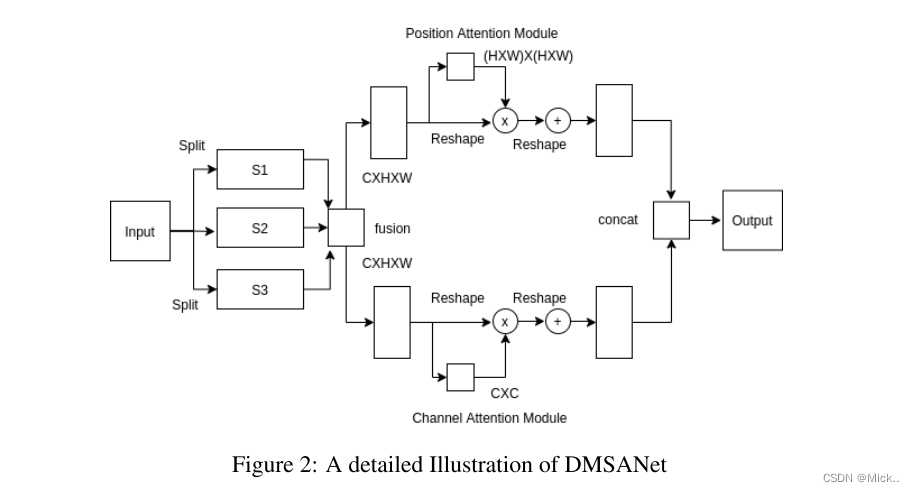
我们提出了DMSA模块,其目标是构建更高效和可扩展的体系结构。我们网络的第一部分借鉴了 (Li等人,2019) 和 (Zhang和Yang,2021) 的思想。输入特征图X与通道尺寸一起分为N个部分。对于每个分裂的部分,它具有C0 = CS数量的公共通道,并且第i个特征映射为Xi ∈ RC0 × h × w。在传递到两个不同的分支之前,将各个特征融合在一起。
这两个分支由 (Fu等人,2019) 中提出的用于语义分割的位置注意模块和通道注意模块组成。我们网络的第二部分执行以下操作: 1) 构建空间注意力矩阵,该空间注意力矩阵对特征的任何两个像素之间的空间关系进行建模; 2) 注意力矩阵与原始特征之间的矩阵乘法。3) 对结果矩阵和原始特征进行了逐元素求和运算。
运算符concat和sum用于重塑特征。来自两个并行分支的特征被聚合以产生最终输出。完整的网络架构如图2所示
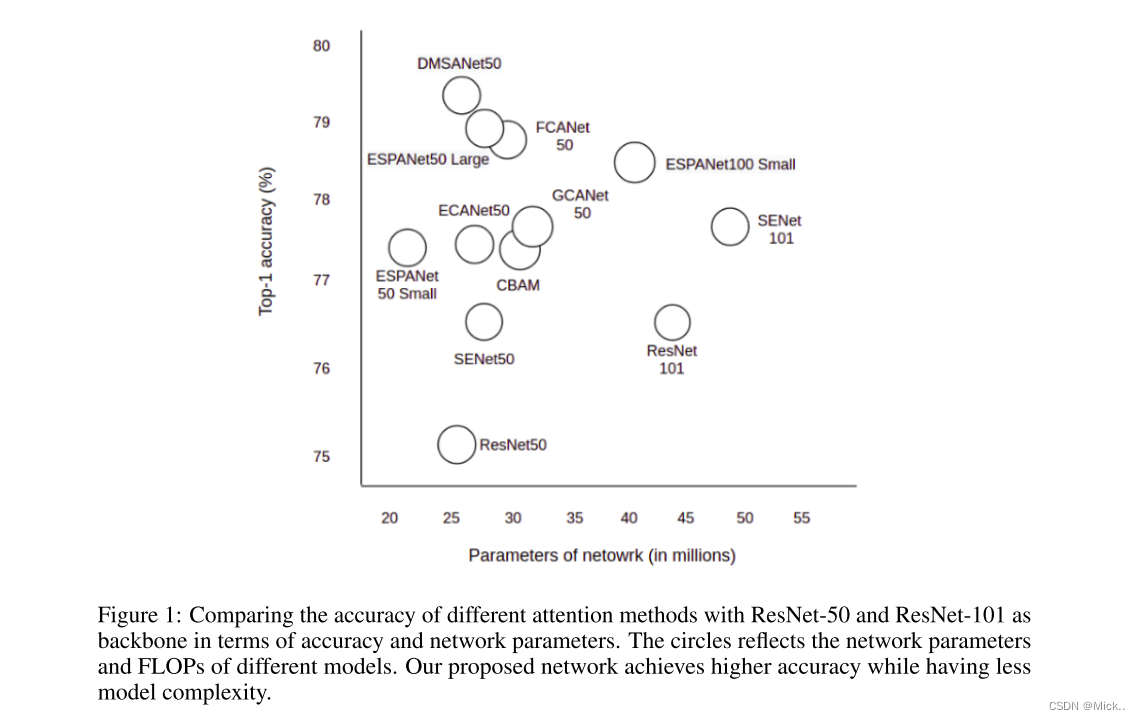
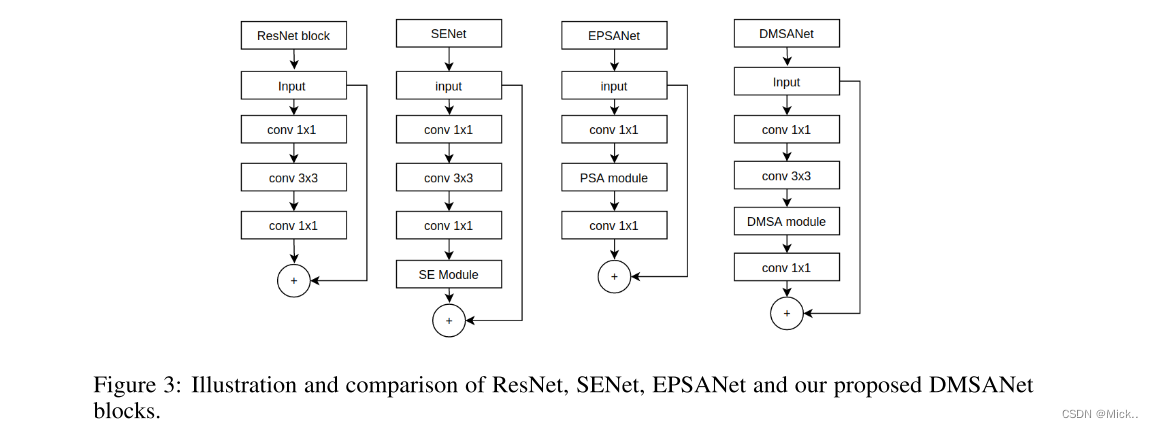
我们将我们的网络体系结构与图3中的Resnet (Wang等人,2017) 、SENet (Hu等人,2018b) 和EPSANet (Zhang等人,2021) 进行比较。我们在3 × 3卷积和1 × 1卷积之间使用DMSA模块。我们的网络能够在通过注意模块之前提取各种规模的特征并汇总这些单独的特征
实现细节
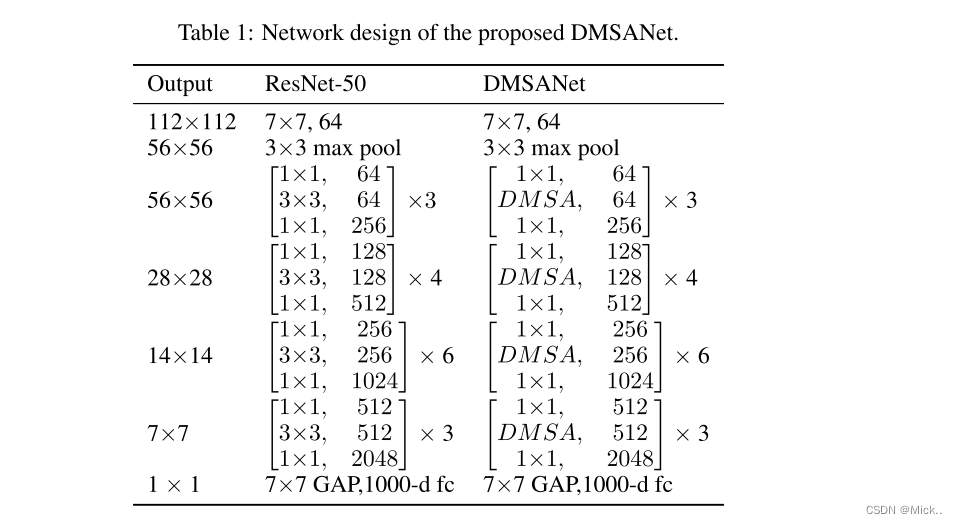
我们使用残差网络 (He等人,2016) 作为在文献中广泛用于Imagenet数据集上的图像分类的主干 (Deng等人,2009)。数据增强用于增加数据集的大小,并且输入张量被裁剪为大小224 × 224。随机梯度下降被用作优化器,其学习率为1e-4,动量为0.9,小批量大小为64。学习率最初设定为0.1,并且在总共50个时期每20个时期之后降低10倍。
我们使用残差网络和FPN作为骨干网 (Lin等人,2017a) 进行对象检测。我们基准的检测器是ms-coco数据集上的更快的RCNN (Ren等人,2015) 、掩模RCNN(He等人,2017) 和RetinaNet (Lin等人,2017b) (Lin等人,2014)。随机梯度下降被用作优化器,权重衰减为1e-4,动量为0.9,批次大小为每GPU 16,持续10个时期。学习率设置为0.01,每10个时期降低10倍。
例如分割,我们使用具有FPN (Lin等人,2017a) 作为主干的掩码RCNN (He等人,2017)。随机梯度下降用作优化器,权重衰减为1e-4,动量为0.9,批次大小为每GPU 4,持续10个时期。学习率设置为0.01,每10个时期降低10倍。
版权归原作者 南妮儿 所有, 如有侵权,请联系我们删除。