
颠覆性突破 | 斯坦福推出“TTT新架构”,超越Transformer与Mamba,让模型{学会学习}!
原创 AI产品汇 AI产品汇 *2024年07月09日 *
“ 在应用为王的中国,可能很多人只听说过Transformer架构,并不知道还存在其它更有架构,也认为Transfor mer就是终极最优解!对于短的上下文而言,它的表现还不错;但是在大的上下文场景下,它的扇出、效率和内存就成为了性能瓶颈!当前阶段的AIGC还处于起步阶段,仅仅在某些领域有了一些成果,距离终极AGI还有很长的路要走!然而,长上下文才是我们需要重点考虑的问题,终极AGI终会存在很多这样的场景。本文小编给大家推荐一种由UC伯克利提出的TTT新架构** ,作者提出了一类新的序列建模层,它具有线性复杂性和可表达的隐藏状态。关键思想是使隐藏状态本身成为机器学习模型,更新规则成为自监督学习的一个步骤。由于隐藏状态甚至在测试序列上也通过训练来更新,因此该层被称为测试时间训练(TTT)层。”**
代码链接-https://github.com/test-time-training/ttt-lm-jax
论文链接-ht**tps://arxiv.org/pdf/2407.04620
01-主流大模型架构梳理
01.01-Transformer架构
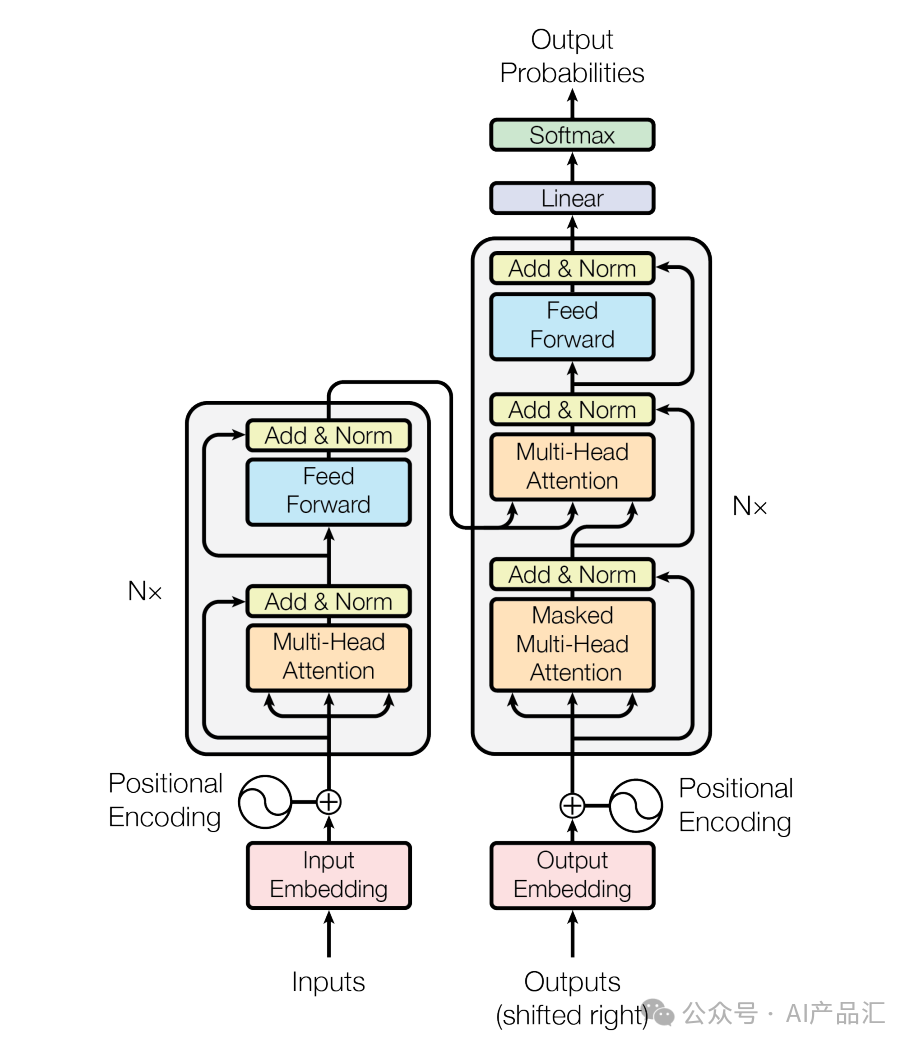
Transformer架构是一种用于序列建模的深度学习架构,最初由Vaswani等人在2017年提出,并广泛应用于自然语言处理(NLP)任务中。它引入了自注意力机制(self-attention)来捕捉输入序列中元素之间的依赖关系,并在大规模数据集上取得了显著的性能提升。以下是Transformer架构的主要组成部分:
自注意力机制(Self-Attention):自注意力机制是Transformer的核心组件之一。它允许模型在输入序列中的每个位置上根据其他位置的信息进行加权聚合。通过计算每个位置与其他位置之间的相对重要性,模型可以更好地理解序列中不同元素之间的依赖关系。
编码器(Encoder):编码器是Transformer的基本模块,用于将输入序列转换为上下文感知的表示。编码器由多个相同的层堆叠而成,每个层都包含自注意力机制和前馈神经网络(Feed-Forward Network)。自注意力机制用于捕捉输入序列内部的依赖关系,而前馈神经网络则提供非线性变换和特征映射。
解码器(Decoder):解码器也是由多个相同的层堆叠而成,与编码器类似,但还包括额外的自注意力机制层,用于对编码器的输出进行进一步的上下文感知。解码器常用于生成目标序列,如机器翻译任务中将源语言句子翻译成目标语言句子。
位置编码(Positional Encoding):由于Transformer中没有使用递归或卷积操作,模型需要一种方式来处理输入序列中的位置信息。位置编码是一种将位置信息嵌入到输入序列中的方法,使模型能够区分不同位置的元素。通常使用正弦和余弦函数生成位置编码。
多头注意力机制(Multi-Head Attention):为了增强模型的表达能力和建模能力,Transformer中的自注意力机制被扩展为多个并行的注意力头。每个注意力头可以关注序列中不同的相关性和特征,然后将它们的输出进行拼接或加权平均。
Transformer架构的突出特点是其并行性和全局视野能力,允许模型在处理长序列任务时保持高效。它在许多NLP任务中取得了巨大成功,如机器翻译、文本生成、问答系统等。同时,Transformer的思想也被广泛应用于其他领域,如计算机视觉和语音处理,取得了显著的成效。
01.02-Mamba架构
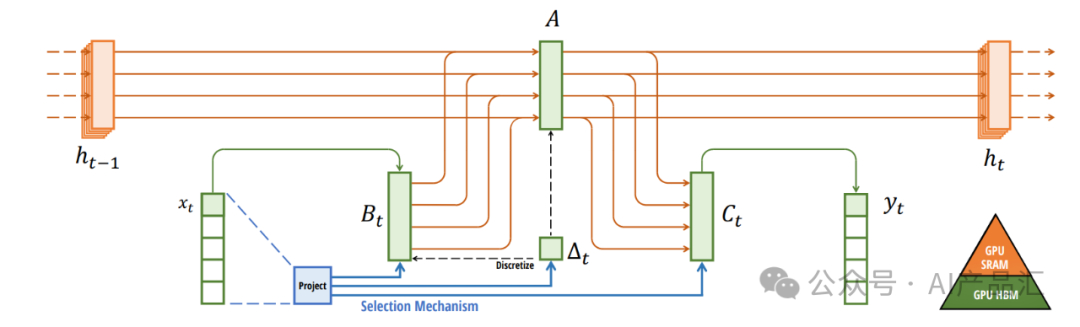
** Mamba是一种新的状态空间模型体系结构,在信息密集的数据(如语言建模)上表现出了良好的性能,而以前的次二次模型无法达到Transformers的性能。**它基于结构化状态空间模型的发展路线,受到FlashAttention的的启发进行了高效的硬件感知设计和实现。
尽管基础模型现在为深度学习中大多数令人兴奋的应用程序提供动力,几乎普遍基于Transformer架构及其核心注意力模块。为了以解决Transformers在长序列上的计算效率低下的问题,学者们已经相继开发了许多次二次时间架构,如线性注意力、门控卷积和递归模型以及结构化状态空间模型(SSM),但它们在语言等重要模态上的表现不如关注。作者发现这种模型的一个关键弱点是它们无法执行基于内容的推理,并进行了一些改进。
首先,简单地用输入函数来作为SSM参数,就可以用离散模态来解决它们的弱点,允许模型根据当前令牌沿着序列长度维度选择性地传播或忘记信息。
其次,尽管这种变化阻止了高效卷积的使用,但作者在递归模式下设计了一种硬件感知的并行算法。并将这些选择性SSM集成到一个简化的端到端神经网络架构中,而无需注意力机制,甚至无需MLP块(Mamba)。
Mamba具有快速推理(比Transformers高5倍的吞吐量)和序列长度的线性缩放,其性能在高达百万长度的真实数据序列上得到了提高。作为通用序列模型的主干,Mamba在语言、音频和基因组学等多种模式中实现了最先进的性能。在语言建模方面,Mamba-3B模型在预训练和下游评估方面都优于相同大小的Transforme rs,并与两倍于其大小的Transformer相匹配。
01.03-RWKV架构
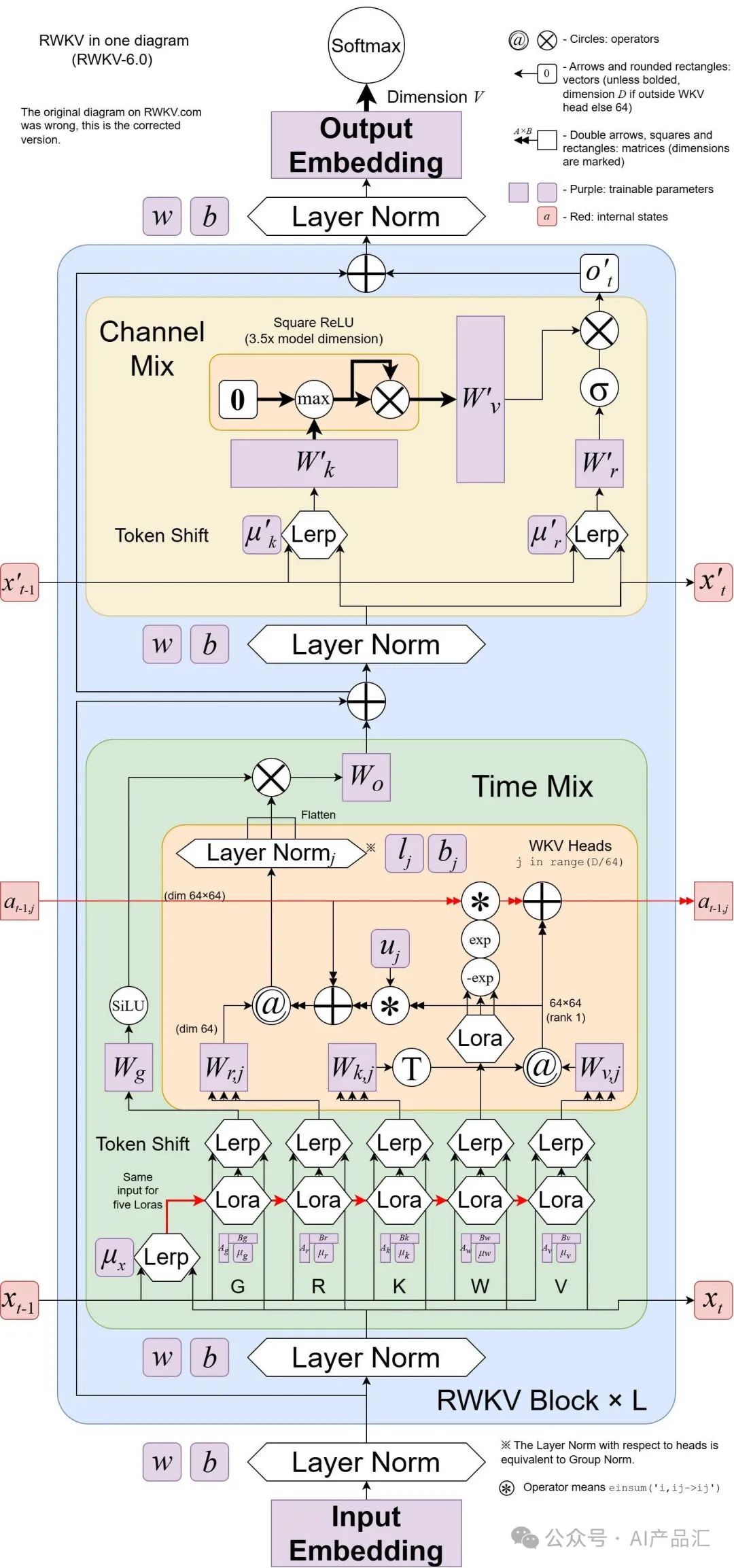
** RWKV(发音为RwaKuv)是一种具有GPT级LLM性能的RNN,也可以像GPT转换器一样直接训练(可并行化)**。 它结合了RNN和transformer的优点,具有出色的性能、快速推理、快速训练、节省VRAM、“无限”ctxlen和自由文本嵌入。
作者提出了Eagle(RWKV-5)和Finch(RWKV-6),它们是在RWKV(RWKV-4)架构的基础上改进的序列模型。**该架构设计的改进点包括多头矩阵值状态和动态递归机制,它们在保持RNN的推理效率特性的同时提高了表达能力。**
除此之外,作者介绍了一个新的多语言语料库,其中包含1.12万亿个标记和一个基于贪婪匹配的快速标记器,以增强多语言性。**作者训练了四个Eagle模型,参数从4.6亿到75亿不等,以及两个Finch模型,参数分别为16亿和31亿,**发现它们在各种基准中都取得了有竞争力的性能。
02-TTT背景简介
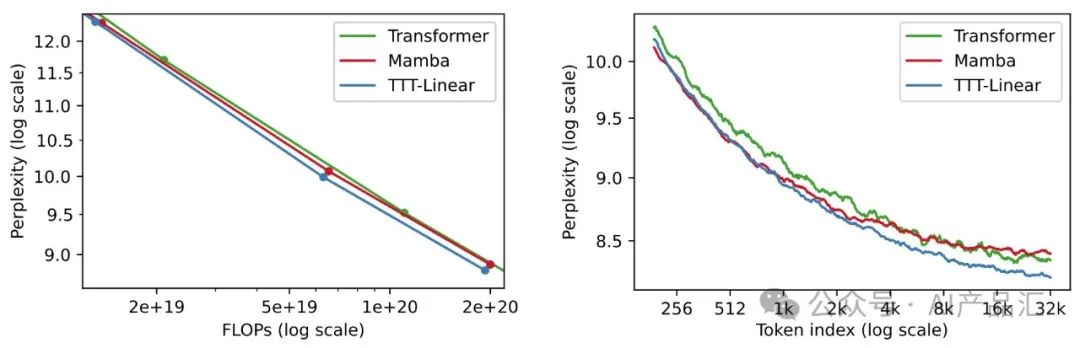
2020年,OpenAI缩放定律论文表明,LSTM(一种RNN)不能像Transformers那样进行缩放,也不能有效地使用长上下文。
如上图所示,在左边,我们观察到Mamba,当今最受欢迎的RNN之一,它的规模与强大的Transformer相似,显示出自2020年LSTM以来的巨大进步。然而,在右边,我们观察到**Mamba的问题与Kaplan等人对LSTM的问题相同。序列中较晚的令牌平均来说应该更容易预测,因为它们以更多的信息为条件Transfor mer的情况确实如此,其在每个令牌索引处的平均困惑度在整个32k上下文中都会降低。**相比之下,Mamba在16k后也出现了同样的指标平稳期。
这个结果代表了现有RNN的尴尬现实。一方面,**RNN(与Transformer相比)的主要优点是其线性(与二次型)复杂性**。这种渐近优势只有在长上下文的实践中才能实现,长上下文是在8k之后。**另一方面,一旦上下文足够长,现有的RNN(如Mamba)就很难真正利用所依赖的额外信息。**
长上下文的困难是RNN层固有的,与自我注意力不同,RNN层必须将上下文压缩到固定大小的隐藏状态。作为一种压缩启发式方法,更新规则需要发现数千个或可能数百万个令牌之间的底层结构和关系。在本文中,作者观察到:**自监督学习可以将大量训练集压缩为LLM等模型的权重,LLM通常对其训练数据之间的语义连接表现出深刻的理解,这正是我们所需要的。**
03-TTT算法简介
自注意力机制在长上下文中表现良好,但具有二次复杂性。**现有的RNN层具有线性复杂性,但它们在长上下文中的性能受到其隐藏状态的表达能力的限制。**
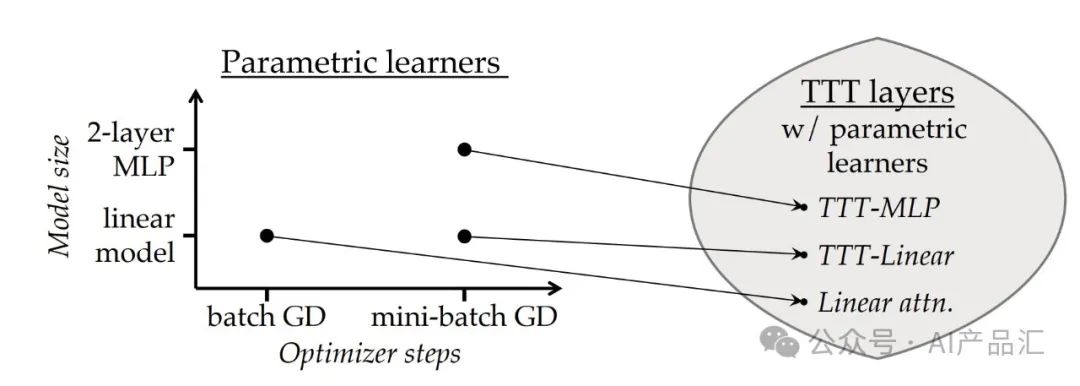
** 本文作者提出了一类新的序列建模层,它具有线性复杂性和可表达的隐藏状态。关键思想是使隐藏状态本身成为机器学习模型,更新规则成为自监督学习的一个步骤。**由于隐藏状态甚至在测试序列上也通过训练来更新,因此该层被称为测试时间训练(TTT)层。
随后,作者考虑了两种实例:**TTT-Linear和TTT-MLP**,它们的隐藏状态分别是线性模型和两层MLP。作者在125M到1.3B参数的范围内评估这些实例的性能,与强大的Transformer和现代RNN Mamba进行了比较。
大量的实验结果表明:**TTT-Linear和TTT-MLP都匹配或超过基线。与Transformer类似,它们可以通过限制更多的代币来不断减少困惑,而Mamba在16k上下文后则不能。**经过初步的系统优化,TTT Linear在8k环境下已经比Transformer更快,并且在wall-clock时间上与Mamba相匹配。
然而,**TTT-MLP在内存I/O方面仍然面临挑战**,但在长上下文情况下显示出更大的潜力,为未来的研究指明了一个有希望的方向。
04-TTT架构详解
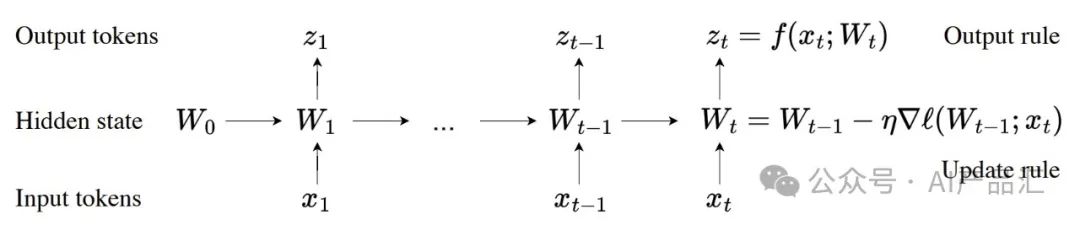
如上图所示,所有的序列建模层都可以表示为根据更新规则转换的隐藏状态。**TTT架构的关键思想是使隐藏状态本身成为权重为W的模型f,并且更新规则是自监督损失上的梯度步长Ş。**因此,在测试序列上更新隐藏状态相当于在测试时训练模型f。这个过程被称为测试时间训练(TTT),被编程到我们的TTT层中。
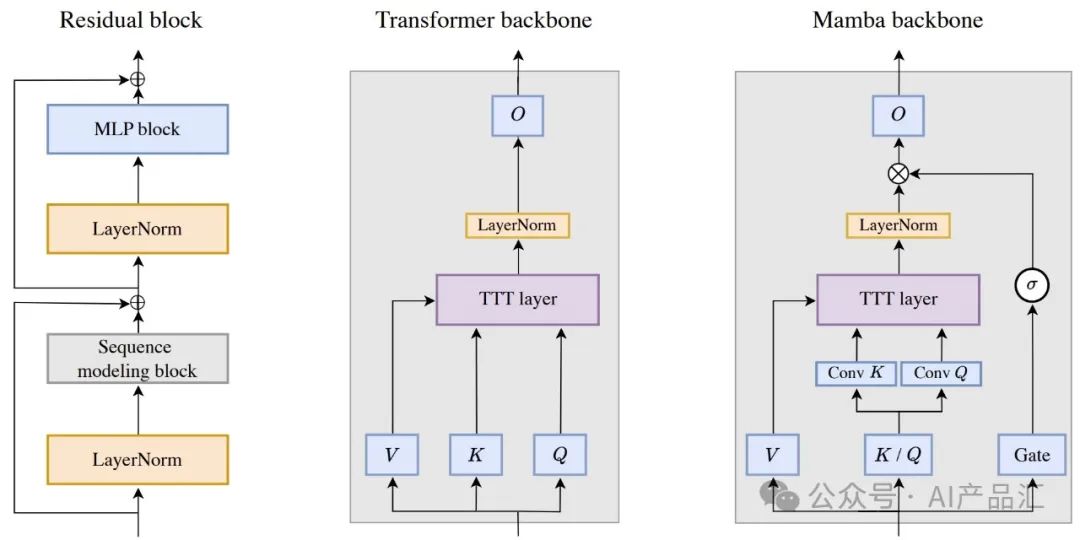
**将任何RNN层集成到更大架构中的最简单的方法是直接替换Transformer中的自注意力机制,在本文中称为主干。**然而,现有的RNN,如Mamba和Griffin,都使用与Transformer不同的主干。最值得注意的是,它们的主干在RNN层之前包含时间卷积,这可能有助于跨时间收集局部信息。
如上图所示,**左图展示了一个残差块**,它是Transformer的基本构建块。序列建模块被实例化为两个变体:Transformer主干和Mamba主干。**中间的图表示Transfo rmer主干中的TTT层**。O之前的LN来自NormFormer。**右图表示受到Mamba和Griffin的启发,在骨干中的TTT层**。根据这两种架构,σ在这里指的是GELU。为了在不改变嵌入维度的情况下容纳门的额外参数,作者简单地将θK和θQ组合成一个投影。
05-TTT实现细节
05.01-序列建模层

** 如上图所示,所有序列建模层都可以从将历史上下文存储到隐藏状态的角度进行查看。**顶部表示了通用序列建模层,表示为根据更新规则转换的隐藏状态。所有序列建模层都可以被视为该图中三个组件的不同实例化:初始状态、更新规则和输出规则。
底部表示了序列建模层的示例及其三个组件的实例化。初始TTT层如图所示。**自注意力有一种隐藏状态,随着上下文的增长而增长,因此每个令牌的成本也在增长。原生的RNN和TTT层都将不断增长的上下文压缩为固定大小的隐藏状态,因此它们的每个令牌的成本保持不变。**
05.02-TTT高级计算图
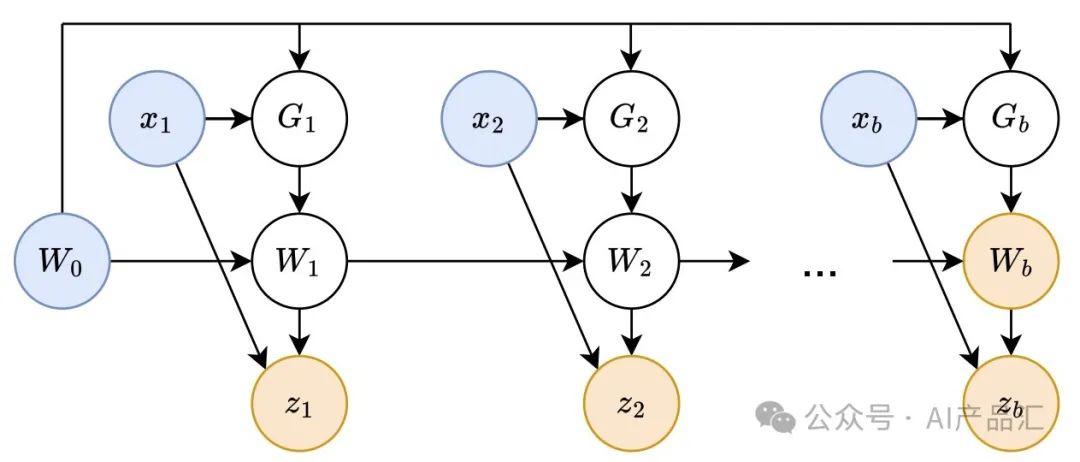
上图展示了第一个TTT小批量的高级计算图,**其中节点表示变量,边表示计算。蓝色节点表示输入变量,黄色节点表示输出变量。****由于G1, ...,Gb之间没有连接,它们之间没有顺序依赖关系,因此它们可以并行计算。**实际上作者并没有具体化白色节点中间的Gs和Ws来计算对偶形式的输出变量。
06-TTT代码及样例实现
06.01-代码实现

**上面的代码按照PyTorch的风格,用线性模型和在线GD实现了TTT层。TTT_Layer可以像其它序列建模层一样被放入更大的网络中。**训练网络将优化TTT_Layer中Task的参数,因为两者都是nn的子类。单元由于学习者不是nn的子类。模块state.model在内部循环中为state.train的每次调用手动更新。为了简单起见,作者有时会将模型重载为model.parameters。
06.02-样例实现
- 、from transformers import AutoTokenizer
from modeling_ttt import TTTForCausalLM, TTTConfig, TTT_STANDARD_CONFIGS# Initializing a TTT ttt-1b style configuration# configuration = TTTConfig(**TTT_STANDARD_CONFIGS['ttt-1b']) is equivalent to the followingconfiguration = TTTConfig()# Initializing a model from the ttt-1b style configurationmodel = TTTForCausalLM(configuration)model.eval()# Accessing the model configurationconfiguration = model.config# Tokenizertokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-hf')# Prefillinput_ids = tokenizer("Greeting from TTT!", return_tensors="pt").input_idslogits = model(input_ids=input_ids)print(logits)# Decodingout_ids = model.generate(input_ids=input_ids, max_length=50)out_str = tokenizer.batch_decode(out_ids, skip_special_tokens=True)print(out_str)
07-TTT性能评估
07.01-复杂度&FLOP比较
如上图所示,左图展示了在书籍的缩放趋势,在350M~1.3B参数之间放大。在760M和1.3B时,**TTT Linear在使用较少FLOP的困惑方面优于Mamba,在线性插值下优于Transformer。**
右图展示了Transformer和TTT Linear可以在更多Tokens的条件下不断减少复杂度,而Mamba在16k上下文后则不能。所有方法都匹配训练FLOP为Mamba 1.4B。
通过观察与分析,我们可以发现:**与Mamba相比,TTT Linear具有更好的困惑性和更少的FLOP,以及更好地使用长上下文。**
07.02-短上下文性能评估

上图展示了该算法在Pie上的多个变种架构与Transformer、Mamba在上下文长度为2k和8k情况下的性能评估。通过观察与分析,我们可以得出以下的初步结论 :
- 在2k的情况下,TTT Linear(M)、Mamba和Transformer具有相当的性能,因为线路大多重叠。TTT-MLP(M)在大的FLOP预算下表现稍差。尽管TTT-MLP在每个模型尺寸上都比TTT-Linear有更好的困惑,但FLOP的额外成本抵消了这一优势。
- 在8k的情况下,TTT-Linear(M)和TTT-MLP(M)的表现都明显好于Mamba,而在2k的条件下观察到的情况则相反。即使是带有Transformer主干的TTT-MLP(T)的表现也略好于Mamba,约为1.3B。作者在本文中观察到的一个稳健现象是,随着上下文长度的增长,TTT层相对于Mamba的优势越来越大。
- 在8k的环境下,Transformer在每种型号的尺寸下仍然有很好的(如果不是最好的)复杂度,但由于FLOP的成本,其产品线并没有太大的竞争力。
07.03-长上下文性能评估

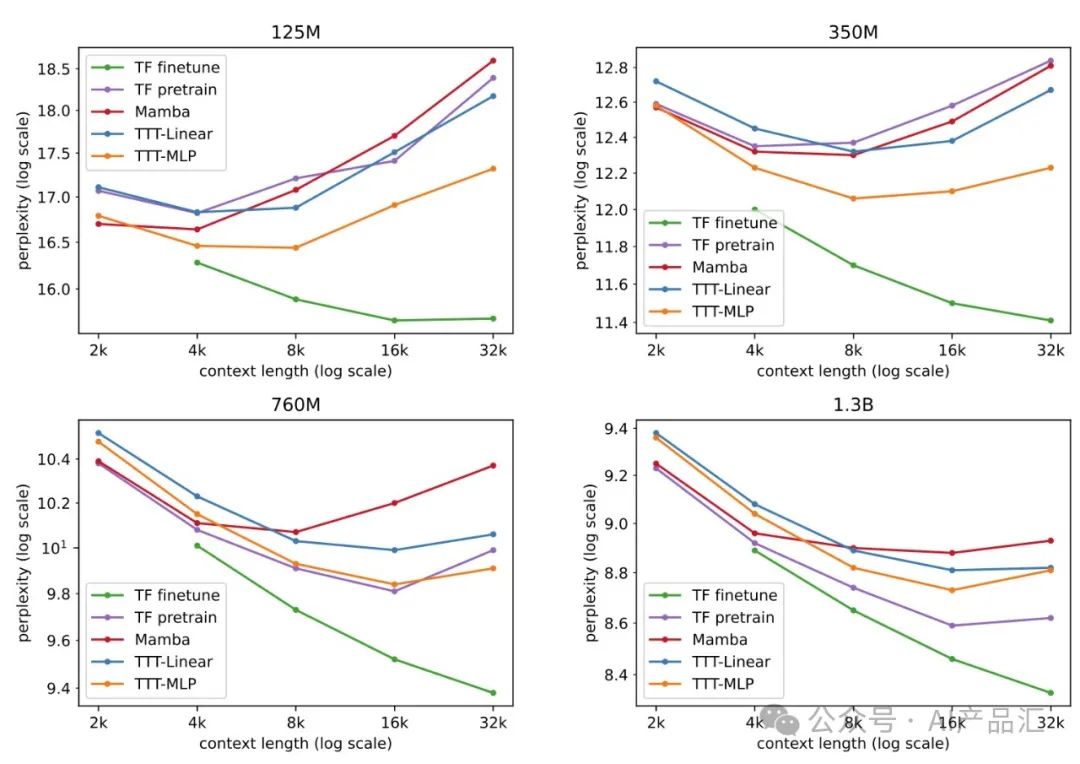
为了评估该架构的长上下文处理能力,作者使用一个名为Books3的流行测试集,按照2×增量对1k到32k的上下文长度进行实验。这里的训练配方与Pile的训练配方相同,TTT层的所有实验都在一次训练中进行。通过观察与分析上图,我们可以得出以下的初步结论:
- 在Books的2k上下文中,来自Pile 2k的所有观察结果仍然成立,除了Mamba现在的表现略好于TTT Linear(而它们的线在桩2k中大致重叠)。
- 在32k的情况下,TTT-Linear(M)和TTT-MLP(M)的表现都优于Mamba,类似于桩8k的观测结果。即使是具有Transformer主干的TTT-MLP(T)在32k上下文中的性能也略好于Mamba。
- TTT-MLP(T)仅略低于1.3B量表下的TTT-MLP(M)。正如所讨论的,由于缺乏干净的线性拟合,很难推导出经验标度律。然而,TTT-MLP(T)的强劲趋势表明,Transformer主干可能更适合我们评估之外的更大模型和更长的上下文。
07.04-Scaling趋势
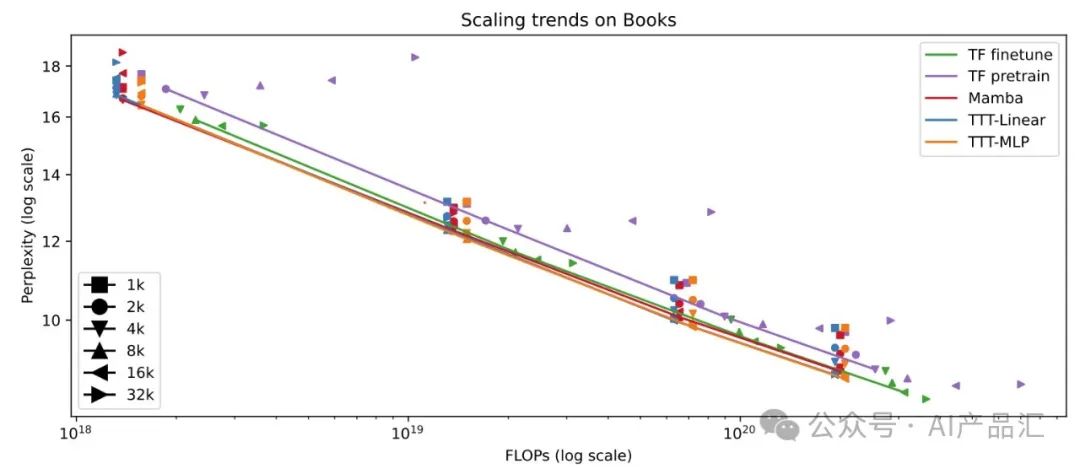
上图展示了在上下文长度从1k到32k的Books上评估的Scaling趋势。作者将上下文长度视为一个超参数,并连接所选的点。由于有从零开始训练和微调的Transfor mer,作者将其标记为TF预训练和TF微调。通过观察与分析,我们可以得出以下的初步结论:
- TTT-Linear和TTT-MLP这两种性能最好的方法几乎完全重叠。
- Mabma和TF微调的线在1020 FLOP之后也大多重叠。
- TF微调的性能明显优于TF预训练,因为它受益于长上下文,而不会在训练FLOP时产生巨大成本。请注意,TF微调和预训练的推断FLOP同样较差,这没有反映在该图中。
- 对于所有从头开始训练的方法(包括TF预训练),一旦上下文长度变得太大,困惑就会变得更糟。下图中强调了这一趋势,作者将对这一趋势的进一步调查留给未来的工作。
08-总结与探讨
08.01-总结
总而言之,本文的主要贡献如下所述:
- 作者提出了TTT层,这是一类新的序列建模层,其中隐藏状态是一个模型,更新规则是自监督学习。作者认为,一层的前向传球本身就包含一个训练循环,这为未来的研究开辟了一个新的方向。
- TTT Linear是TTT层的一个简单实例化,在作者的评估中(从125M到1.3B的参数)优于Transformers和Mamba。
- 作者通过小批量TTT和双重形式提高了TTT层的硬件效率,使TTT Linear已经成为LLM的实用构建块。
08.02-探讨

**在应用为王的中国,可能很多人只听说过Transformer架构,并不知道还存在其它更有架构,也认为Transfor mer就是终极最优解!**对于短的上下文而言,它的表现还不错;但是在大的上下文场景下,它的扇出、效率和内存就成为了性能瓶颈!
** 当前阶段的AIGC还处于起步阶段,仅仅在某些领域有了一些成果,距离终极AGI还有很长的路要走!**然而,长上下文才是我们需要重点考虑的问题,终极AGI终会存在很多这样的场景。
**幸运的是,国内外还是有那么一波人在默默研究并探索者比Transformer更优的一些架构。此处应该有掌声,送给这些在底层架构默默付出的研究员们,你们辛苦了!**很多学者都认为改进版本的RNN才是终极最优解,相继提出了Mamba、RWKV、Jamba、TTT等架构。
在这里,**提醒下那个做LLM硬件架构设计的朋友们,还是要尽可能的考虑到灵活性、可配置性,**保证你们的硬件可以很好的适配后面的新架构,毕竟Transfo rmer并不是最优解,又被其它架构代替的可能性!
关注我,AI热点早知道,AI算法早精通,AI产品早上线!
版权归原作者 AI生成曾小健 所有, 如有侵权,请联系我们删除。