

1、认识模型融合🌸
- 在机器学习竞赛界,流传着一句话:当一切都无效的时候,选择模型融合。这句话出自一位史上最年轻的Kaggle Master之口,无疑是彰显了模型融合这一技巧在整个机器学习世界的地位。如果说机器学习是人工智能技术中的王后,集成学习(ensemble Learning)就是王后的王冠,而坐落于集成学习三大研究领域之首的模型融合,则毫无疑问就是皇冠上的明珠,熠熠生辉,夺人眼球。
- 为什么模型融合如此受学者们青睐呢?模型融合在最初的时候被称为“评估器结合”,与集成算法(狭义)一样,它也是训练多个评估器、并将多个评估器以某种方式结合起来解决问题的机器学习方法。我们都知道,集成算法(狭义)是竞赛高分榜统治者,但在高分榜上最顶尖的那部分战队一定都使用了相当丰富的模型融合技巧,因为模型融合能够在经典集成模型的基础上进一步提升分数,使用模型融合技巧后、融合算法的效果常常可以胜过当前最先进的单一集成算法。正是这一有效的提分能力,让模型融合在竞赛界具有很高的地位。也因此,模型融合是提分的最终手段。
2、模型融合和集成算法的区别🌹
- 直观印象:训练的基础不同> 集成算法(狭义):青铜算法+人海战术> > > - 以Bagging和Boosting代表的集成算法(狭义)可以说是使用青铜算法+人海战术。在集成时,我们一般使用数百棵决策树、甚至树桩这样的弱评估器,构成强大的学习能力。 > - 在这个过程中,由于评估器数量很多,因此每个评估器贡献自己的一小步(Boosting)、或者一小点意见(Bagging),没有任何弱评估器可以在数据集上直接给出优秀的结果。因此从本质上来说,集成算法还是一个算法,弱评估器本身不具备有效预测能力。 > > 模型融合:王者算法+精英敢死队> > > - 模型融合则使用王者算法+精英敢死队战术。在融合时,我们往往构建最多数十个Xgboost、神经网络这样的强评估器,再设计出强大的规则来融合强评估器的结果。或者,我们使用少数几个很强的学习器处理特征,再让将新特征输入相对较弱的学习器,以此来提升模型表现。 > - 在这个过程中,由于评估器很少,所以每个评估器的贡献都很大,即便不融合,单一评估器也可以直接在数据集上给出优秀的结果。因此从本质上来说,模型融合是囊括多个算法的技巧,而并非一个算法。
不难发现:通过集成,我们让算法从弱到强,但通过融合,我们让算法从强到更强。面对同样的预测任务,集成算法会努力获得一个好结果,而模型融合则是将许多好结果融合在一起,得到更好的结果。
- 统计方面:假设空间不同,泛化能力不同> 集成算法(狭义):一维假设空间> > > - 每个算法都是一套独一无二的、从数据到结论的计算流程,这一流程在统计学上被称为是“对样本与标签关系的假设”。例如,KNN假设,相同类别的样本在特征上应该相似。Boosting算法假设令单一损失函数最小的树一定可以组成令整体损失最小的树林。 > - 我们可以有不同的假设,但在有限的训练数据集上,我们很难看出哪个假设才是对贴近于真实样本标签关系的假设。这就是说,我们无法保证现在表现好的算法在未知数据集上表现也一定会好。因此使用单一假设/单一算法的缺点就很明显:****虽然在当前数据集上当前假设表现最好,但如果其他假设才更贴近数据真实的情况,那当前选择出的模型的泛化能力在未来就无法得到保证了。 > > 模型融合:高维假设空间> > > - 相对的,如果能够将不同的假设结合起来,就可以降低选错假设的风险。最贴近数据真实状况的假设,即便在当前数据集上表现并不是最好的,但在融合之后可以给与融合的结果更强大的泛化能力。 > - 同时,假设真正的数据规律并不能被现在的数据代表,那融合多个假设也能够拓展假设空间,不同假设最终能够更接近真实规律的可能性也越大。
因此,从统计学的角度来说,模型融合能够:**(1) 降低选错假设导致的风险、(2)提升捕捉到真正数据规律的可能性、(3)提升具有更好泛化能力的可能性**。
- 计算方面:起点数量不同,模型表现不同> 集成算法(狭义):只有一组起点,最终只能得到一个局部最小值> > > - 许多算法在搜索时都会陷入局部最优解,即便有足够多的训练数据,我们也无法判断能否找到理论上真实的最小值。一般在算法训练时,我们把搜索出的局部最小值当作是真实最小值的近似值,但我们却无法估计真实最小值与局部最小值之间有大多的差异。但由于我们只有一个局部最小值,真实最小值在哪里完全没有头绪。 > > 模型融合:多组不同的起点,最终得到一个局部最小值的范围> > > - 模型融合过程中,每个算法都会有自己的起点、并最终获得多个不同的局部最小值。虽然这些局部最小值当中,没有任意一个等于真正的最小值,但真正的最小值很大可能就在这些局部最小值构成的范围当中。通过结合局部最小值,可以获得更接近真实最小值的近似值,从而提升模型的精度。
因此,从计算方面来看,模型融合能够:**(1)降低选错起点假设的风险、(2)降低局部最小值远远偏离真实值的风险、(3)提升算法结果更接近真实最小值的可能性**。
3、常见模型融合方式🍁
当算法出现统计学方面的问题时,模型一般表示为高方差、低偏差(更换数据之后模型表现非常动荡)。当算法出现计算方面的问题时,模型一般表示为高偏差、低方差(无论换什么数据,局部最小值都远离真正的最小值)。因此,理论上来说,模型融合这一技巧的上限非常高:我们可以同时降低方差和偏差、找到方差-偏差均衡的最优点。
现在,使用比较广泛的融合方式有如下4种:
- 均值法Averaging:适用于回归类算法,将每个评估器的输出做平均,类似于Bagging中回归的做法。
- 投票法Voting:适用于分类算法,按每个评估器的输出进行投票,类似于Bagging中分类的做法。
- 堆叠法Stacking:使用一个或多个算法在训练集上输出的某种结果作为下一个算法的训练数据。其中比较著名的是gbdt+lr,其中逻辑回归lr使用gbdt输出的树结构数据作为训练数据。
- 改进堆叠法Blending:一种特殊的stacking,使用一个或多个算法在验证集上输出的某种结果作为下一个算法的训练数据。
4、投票法Voting🌿
投票法是适用于分类任务的模型融合方法,也是在直觉上来说最容易理解的方法。简单来说,投票法对所有评估器输出的结果按类别进行计数,出现次数最多的类别就是融合模型输出的类别
4.1、不同的投票方法🌴
相对多数投票 vs 绝对多数投票> 相对多数投票就是上面所提到的少数服从多数,即只要有一个备选类别占比较多即可。与之相对的是绝对多数投票:> > 绝对多数投票要求至少有50%或以上的分类器都输出了同一类别,否则就拒绝预测。例如在5个分类器中,至少要有2.5个分类器都输出同一类别,样本才能够进行输出具体类别,否则则输出“不确定”,相当于增加一类输出类别。在机器学习当中,绝对多数投票可以帮助我们衡量当前投票的置信程度。票数最多的类别占比越高,说明融合模型对当前样本的预测越有信心。当票数最多的类别占比不足50%时,重新投票对于机器学习来说效率太低,因此我们往往会选择另一种方案:我们可以使用相对较弱的学习器进行绝对多数投票融合、并将绝对多数投票中被输出为“不确定”的样本交由学习能力更强的模型进行预测,相当于将“困难样本”交由复杂度更高的算法进行预测,这也是一种融合方式。
硬投票 vs 软投票> 大多数分类模型的模型输出结果可以有两种表示方式:> > > - 表示为二值或多值标记,即算法输出值为[0,1]或[1,2,3]这样的具体类别。 > - 表示为类别概率,即算法输出值为(0,1)之间的任意浮点数,越靠近1则说明算法对当前类别预测的置信度越高。我们需要规定阈值、或使用softmax函数的规则来将浮点数转换为具体的类别。 > > 基于此,我们可以将投票分成两种类型:> > 硬投票:将不同类别的出现次数进行计数,出现次数最多的类别就是投票结果> > 软投票:将不同类别下的概率进行加和,概率最高的类别就是投票结果。基于概率的软投票可以衡量投票的置信程度,某一类别下的概率越高,说明模型对该类别的预测结果越有信心。
- 软投票和硬投票得出的结果可能不同,这是因为软投票有一种“窥探心灵”的能力(也就是衡量置信度的能力)。
- 在实际进行投票法融合时,我们往往优先考虑软投票 + 相对多数投票方案,因为软投票方案更容易在当前数据集上获得好的分数。然而,如果我们融合的算法都是精心调参过的算法,那软投票方案可能导致过拟合。因此具体在使用时,需要依情况而定。
- 加权投票> 除了基于概率、基于类别进行投票、以及使用绝对多数、相对多数进行投票之外,还有一种可以与上述方式结合的投票方法,即加权投票。加权投票是在投票过程中赋予不同分类器权重的投票,具体表现在:> > > - 对于硬投票,加权投票可以改变每一个分类器所拥有的票数。> - 对于软投票,加权投票可以改变每一个分类器所占的权重,令概率的普通加和变成加权求和。
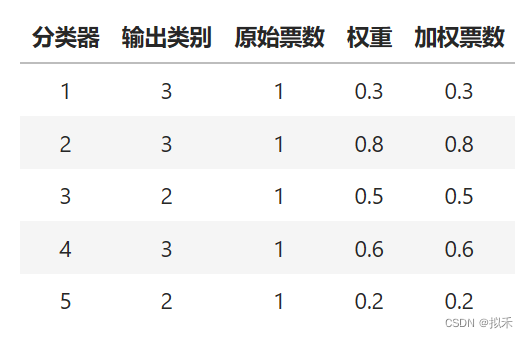
具体来看,硬投票情况下,现在,我们再按照类别进行计数,类别3的票数为(0.3 + 0.8 + 0.6 = 1.7票),而类别2的票数为(0.5 + 0.2 = 0.7)票,因此票数占比更多的是类别3,融合模型输出类别3。

不难发现,当调整权重之后,最终输出的结果依然是类别2,但是加权之后整体算法对于类别2的置信度是降低的、对于类别3的置信度是提升的。因此,修改权重很可能会影响融合模型最终的输出。通常来说,我们会给与表现更好的分类器更多的权重,但并不会给与它过多的权重,否则会过拟合。
大多数时候,我们可能会主观地认为,加权后的模型比未加权的模型更强大,因为加权求和比普通求和更复杂、加权平均也比普通平均更复杂。但事实上,无论是从实验还是理论角度,加权方法并没有表现出比一般普通方法更强的泛化能力。在某些数据上,加权会更有效,但如果强评估器之间的结果差异本来就不大,那加权一般不会使模型结果得到质的提升。
今天好冷。小年快乐。
版权归原作者 拟 禾 所有, 如有侵权,请联系我们删除。