
只要一张照片加上音频,就能让你说话唱歌,阿里做到了。
最近,阿里新上线了一款AI图片-音频-视频模型技术EMO,用户只需要提供一张照片和一段任意音频文件,EMO即可生成会说话唱歌的AI视频。以及实现无缝对接的动态小视频,最长时间可达1分30秒左右。
阿里研究团队表示,EMO可以生成具有表情丰富的面部表情和各种头部姿势的声音头像视频,同时,其可以根据输入视频的长度生成任意持续时间的视频。
你可以想象一下,用蒙娜丽莎的画像就可以生成唱歌的视频,或者说用一张高启强的肖像就可以让强哥变身刑法教授在线授课。还可以让坤坤变成真正的rapper!值得一提的是,生成的视频中人物表情非常到位,口型、语速也都能完全匹配。

阿里EMO:输入图片和音频就可生成视频,强哥也能上刑法课了!
论文解读

github链接:https://github.com/HumanAIGC/EMO
论文链接:https://github.com/HumanAIGC/EMO
摘要

我们提出了EMO,一个富有表现力的音频驱动的人像视频生成框架。输入单个参考图像和语音音频,例如说话和唱歌,我们的方法可以生成具有丰富面部表情和各种头部姿势的语音化身视频,同时我们可以根据输入视频的长度生成任意时长的视频。
方法
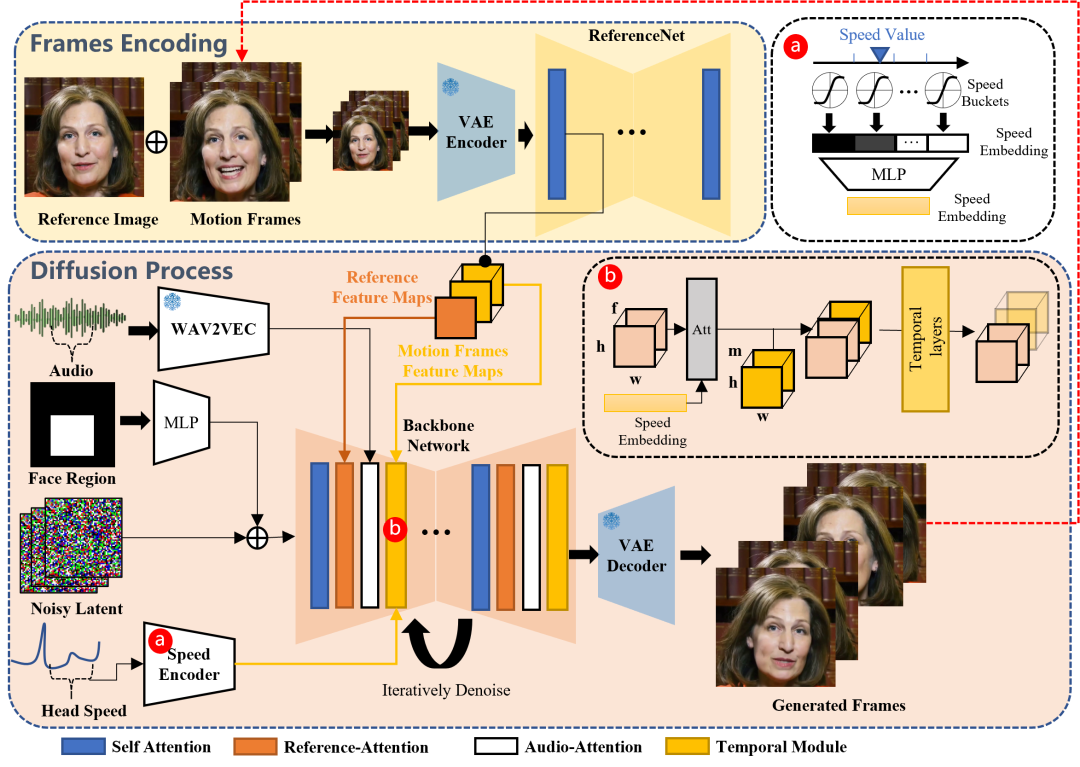
提出的方法概述:框架主要由两个阶段构成。在初始阶段,称为帧编码,使用ReferenceNet从参考图像和运动帧中提取特征。随后,在扩散处理阶段,预训练的音频编码器处理音频嵌入。人脸区域掩模与多帧噪声相结合,控制人脸图像的生成。其次是利用骨干网来简化去噪操作。在骨干网中,采用了两种形式的注意机制:参考注意和声音注意。这些机制对于保留角色的身份和调节角色的动作是必不可少的。另外,利用时间模块来控制时间维度,调整运动速度。
感谢你看到这里,也欢迎点击关注下方公众号,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~
本文转载自: https://blog.csdn.net/xs1997/article/details/136395251
版权归原作者 AIGC Studio 所有, 如有侵权,请联系我们删除。
版权归原作者 AIGC Studio 所有, 如有侵权,请联系我们删除。