
C 题 空气质量预测与预警
空气污染对人类健康、生态环境、社会经济造成危害,其污染水平受诸多因素的影响, 如 PM2.5、PM10、CO、气温、风速、降水量等,探究 PM2.5 等污染物浓度的因素,更精准的预测 PM2.5 浓度和 AQI 指数等是科学界和决策者共同关心的问题,对于解析污染影 响因素和有效制订控制策略具有重要意义。
为了健全和针对完善重污染天气的应对处置机制,提高重污染天气预防预警、应急响应能力和环境精细化管理水平,消除重度及以上污染天气,作为突发环境事件应急预案体系的重要组成部分,某地发布污染天气应急预案,该预案将加强监测预警和节能减排,最大程度降低污染天气的影响。其预警等级划分为四级应急响应:
蓝色预警:预测日 AQI>150 或日 AQI>100 持续 48 小时及以上。
黄色预警:预测日 AQI>200 或日 AQI>150 持续 48 小时及以上。
橙色预警:预测日 AQI>200 持续 48 小时或日 AQI>150 持续 72 小时及以上。
红色预警:预测日 AQI>200 持续 72 小时且日 AQI>300 持续 24 小时及以上。 请参赛团队根据问题要求,完成以下问题(任务):
问题一:根据附件 1 和附件 2,对数据进行分析和处理,筛选出与 PM2.5 浓度变化有关的因素,并说明筛选出的因素对 PM2.5 浓度影响的程度。
本题是典型的时间序列分析问题,问题一中明确指出要利用两个附件的数据:
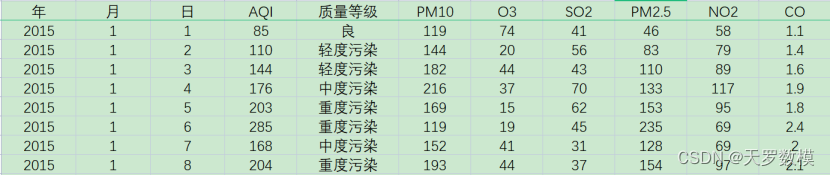
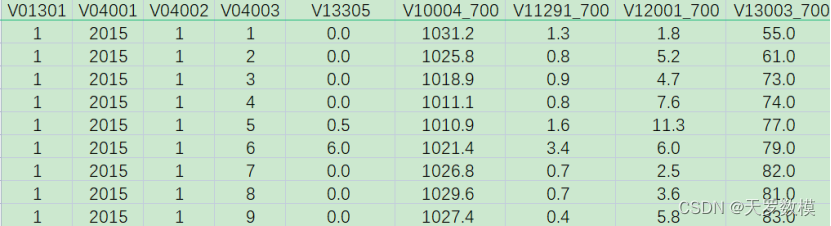
本道题应该至少存在前两个步骤:
一、数据观测与数据预处理
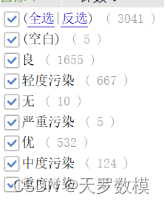
观察数据的结果,显然附件二中的第一列都是1,第二列是年份,第三列是月份,第四列是日期。第一列的常数对预测没有价值,可以直接剔除。
质量等级是一个字符串型的数据,除了空白以外,分别有七种取值,这里可以使用数字0-6分别表示七种文本。更进一步,可以对数字变量做one-hot编码,衍生成新的7个0-1特征,更适配神经网络。
当然,也需要对数据进行预处理和特征检验。例如缺失值处理、异常值处理等等。
二、相关性分析
本题的相关性分析不仅需要找出与PM2.5的相关的变量,还需要量化相关性的大小。
最简单的方法是pearson相关系数,在数据不满足正态分布的前提下,可以使用spearman相关系数。
三、回归和机器学习
在此基础上,常见的回归分析都可以讨论自变量对因变量的影响程度。将全部数据归一化消除量纲的影响以后,可以带入回归模型、机器学习,利用多元线性回归分析的标准化系数、机器学习模型的特征重要性来判断。利用这些可以度量的数据,可以直观反映影响的大小。
四、attention机制和transformer
有基础的同学可以使用神经网络+attention的做法,attention也可以展示神经网络算出的因变量对自变量的重视程度,而且可以预见使用的人较少,如果能实现无疑是一个亮点。
问题二:自行划分训练集和测试集,根据附件 1 和附件 2,基于问题一构建 PM2.5 浓度多步预测模型,分别使用均方根误差(RMSE)对 3 步、5 步、7 步、12 步预测效果进行评估,其结果请用表 1 格式在正文中具体给出,并对测试集及其预测结果进行可视化。 同时,用该模型预测附件 3 所给定时间的 PM2.5 浓度,其结果请用表 2 格式在正文中具体给出。


本题需要使用问题一中找出的和PM2.5极其相关的变量、可以是正相关和负相关,以它们做自变量,PM2.5的含量做因变量构建时间序列分析模型进行预测。
一、数据预处理。
本题是一个多元时间序列分析模型,需要注意的是,传统的ARIMA是一元时间序列分析,因此,在这里无法使用。
第二问中的数据预处理是重中之重,参考时间序列分析的思想,我们需要对数据进行改进。时间序列分析的思想是:用相关的后几个数据预测下一个数据,那么参考这一中心思想,我们将数据集进行改进,将同一个变量的上一个数据作为新的变量。
比如,假设因变量y,对自变量x1进行改进。对于第n个样本的y,将第n-1、n-2、...、n-m个x1作为m个新的变量(m是由前多少个数据预测下一个数据的时间,自定)。这样,就得到了回归分析的新的数据集,即可开始预测。
二、多元线性回归分析
这里的多元线性回归实际上是改进的、和时间有关的多元线性回归分析,将修改好的数据集带入回归模型,直接预测即可。
想要预测几步,实际上都是通过往后预测一步实现,先往后预测一步,然后将预测的数据加入数据集,再往后预测一步即可得到预测两步的结果。
三、机器学习回归
和统计方法类似的思路,但是,使用机器学习毫无疑问可以大幅度提升精度,也更加有竞争力
四、RNN、LSTM、GRU和transformer
处理序列数据的神经网络毫无疑问是最佳的方法,在时间序列分析上也展现了传统统计和机器学习无可匹敌的卓越性能,利用tensorflow或pytorch搭建深度神经网络是最佳的方法,一般结果远好于统计分析和机器学习。
问题三:构建 AQI 多步预测模型,使用均方根误差(RMSE)对建模效果进行评估,并对测试集及其预测结果进行可视化。同时,用该模型预测附件 3 所给定时间的 AQI,并给出每天空气质量的预警等级,其结果请用表 3 和表 4 格式在正文中具体给出。
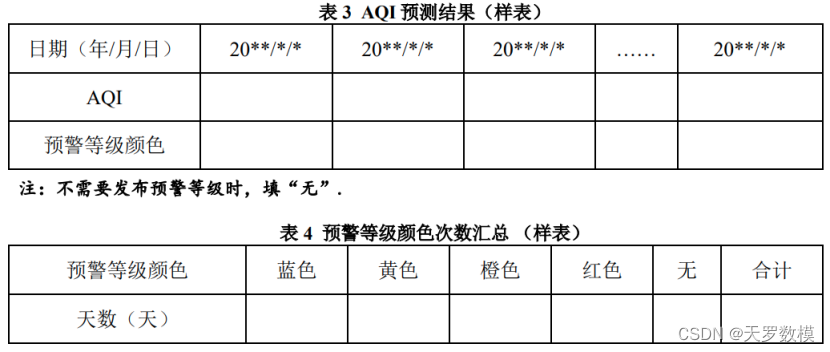
本题实际上是重复第一问和第二问对pm2.5的建模过程,只是将预测PM2.5改成了预测AQI和整型变量AQI。
代码会在群内公布,可以加入以下群聊:
群聊
版权归原作者 天罗数模 所有, 如有侵权,请联系我们删除。