
人的眼睛或者相机的FOV(视场)有限,所以很难将景色尽收眼底,医疗影像设备同样受限于FOV的大小,很难同时扫描整个解剖部位,这时就需要拼接算法将不同角度拍摄的部分图像拼成一幅全景图。
我之前写过一篇关于图像拼接的文章[图像拼接并不像你想的那么简单],其中主要介绍了基于传统算法(opencv中已经对拼接进行了封装)的图像拼接技术,拼接看似简单,实则非常复杂,拼接流程主要分为两部分:①配准,②融合,其中配准相当重要,如果配准不精确,即使融合算法再完美也毫无意义,传统方法大多采用基于特征点匹配方式进行图像配准,特征点的鲁棒性就变得相当重要,但受图像对比度,光照,视场,噪声的影响,检测的特征点质量往往不高,这就给拼接效果带来很大影响。

如上图,整个拼接流程涉及到特征点的检测和匹配,相机成像模型,图像融合,矩阵运算,几何学,概率统计等,为了保证拼接精度和效率,整个流程运用了非常多的优化算法,例如K-D Tree,RANSAC,最大生成树,光束平差法等。
既然传统的拼接算法复杂度这么高,而且非常依赖人的经验,那不妨换个角度,利用人工智能的手段来实现拼接,今天我们就用深度学习来优化拼接算法中的各个流程。
更鲁棒的特征点和特征描述符:
既然传统的方法很难找到鲁棒的特征点,那就通过深度学习来提取特征点,Jiazhen Liu 等人提出的SuperRetina网络用于视网膜图像的特征提取,输入图像经过自编码器提取特征后,特征图分别输入到两个分支网络,Det-Decoder用于输出特征点,特征图P中值为1的代表特征点,优化过程计算损失时,并不是采用交叉熵计算分类损失,而是通过P进一步生成高斯热力图计算回归损失,Des-Decoder用于输出特征点对应的特征描述符,也有的网络只输出特征点坐标,然后通过传统算法计算特征描述符。
有了特征点,就可以利用传统算法进行特征点匹配等后续流程。

https://arxiv.org/pdf/2207.07932v1.pdf
直接计算单应矩阵:
通过深度学习方法虽然提取了特征点,但后续的流程仍然需要传统的算法来做,例如,特征点匹配,当匹配的特征点对非常多时,还需要通过RANSAC提取内点,最后通过内点计算单应矩阵,两幅待拼接的图像,以其中一副图像为基准,另一幅图像经过单应矩阵的变换后,两幅图像配对的特征点位置会重合,进而实现拼接的效果,这些优化方法不是完美的,那能不能直接用深度学习来生成单应矩阵呢?DeTone等人提出了应用卷积神经网络直接计算单应矩阵。
网络的整体架构:

本文的目标是计算单应矩阵H,作者采用两种思路进行计算H,一种是网络的输出端采用回归网络,直接输出单应矩阵中的8个元素的向量形式[H11,H12,H13,H21,H22,H23,H31,H32,H33].
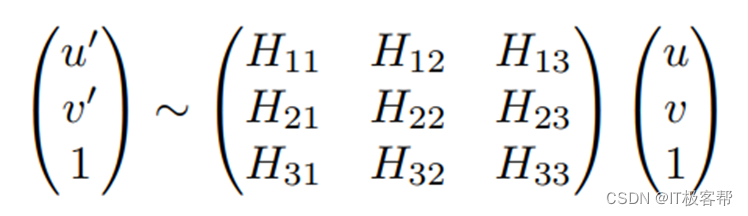

我们知道单应矩阵Homography有8个自由度(8-dof),所以理论上只需要4对匹配点就可以估计出单应矩阵,首先将对单应矩阵的预测转换成对4对匹配点的预测,具体形式是横纵坐标的偏移量,4个点对的偏移量构成的矩阵和单应矩阵是一一对应的,opencv中getPerspectiveTransform()就是通过匹配的点对来计算单应矩阵。

基于上述思想,另一种是输出端采用分类网络,输出对于量化矩阵的分布函数,量化就是把当前点坐标按概率分配给对应点。因为会产生量化误差,所以对每一个角点会生成一个关于偏移量的分布函数。


相比于分类网络,回归网络更容易理解。
无论是采用回归还是分类的方式,网络的训练过程都需要标签H,这个H是怎么来的呢?作者在MS-COCO数据集上通过一种很简单的方式建立了训练样本并且得到了Homography。

①首先在一张图像位置P上随机裁剪出一个正方形区域Patch A,②然后对正方形四个顶点进行随机的扰动,③通过opencv函数getPerspectiveTransform()计算出单应矩阵HAB,计算HBA=(HAB)-1,并调用opencv函数wrapperspective()函数将HBA应用于原图像生成转换后的图像,在位置P裁剪同样的正方形方形Patch B,Patch A和Patch B就是网络的输入数据,HAB是网络的输出。
但这种方式训练的数据是在同一张图像上生成的,现实中,对于拼接图像而言,输入是多张不同角度拍摄的图像,对于训练数据的标注往往会更麻烦一些,可能需要借助OPENCV中的传统的拼接算法计算H作为标签。
https://arxiv.org/pdf/1606.03798v1.pdf
利用GAN直接生成拼接图像:
现在已经能够利用神经网络计算两幅图像的单应矩阵,接下来就可以生成拼接图像了,但现实应用中输入的图像往往不止两幅,对于多幅图像的情况,传统的拼接算法都是先两两进行拼接,那如何选择优先顺序呢?传统方法通过最大生成树来选择优先顺序,采用这种方式有个缺点,计算的单应矩阵可能存在误差,当多幅图像两两拼接时会导致累积误差逐渐升高,导致最终的拼接结果误差会很大,虽然通过光束平差法进行优化,但有的时候效果并不理想,那能不能来点干脆的,让神经网络不再输出中间结果而是直接输出拼接后的图像,不让中间商赚差价,这让人想起了生成模型GAN,只要训练数据足够多,GAN不仅能减少累积误差,而且还能解决传统拼接算法中的融合问题。
但GAN也有缺点,首先它自身存在模式崩塌的问题,也很难量化输出结果的精确度,训练需要大量带标注的数据,数据标签需要先用传统的拼接算法生成,而网络的精度就要依赖拼接算法的精度,所以现实中应用并不多。
本文讲述了利用神经网络去优化传统拼接流程中不同阶段所面临的问题,除了上述方法外,还有很多方法本文没有涉及,例如无监督的方法,半监督的方法等,很多方法基本思想都是一致的。
版权归原作者 人工智能大讲堂 所有, 如有侵权,请联系我们删除。