
论文:Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task
⭐⭐⭐⭐⭐
EMNLP 2018, arXiv:1809.08887
Dataset: spider
GitHub: github.com/taoyds/spider
一、论文速读
本文提出了 Text2SQL 方向的一个经典数据集 —— Spider 1.0,其难度远大于 WikiSQL,包含了 200 个数据库,覆盖了 138 个不同的领域,平均每个数据库由 27.6 个 columns 和 8.8 个外键,总共由 10,181 个 questions 以及 5,693 个对应的复杂 SQL 查询构成。
1.1 数据集的特点
数据集由 11 名计算机学生构建,在做数据标注时,确保了以下三个方面:
- SQL 模式的覆盖:每个数据库的示例覆盖了常见的 SQL 模式,包含多列的 SELECT 和 aggregation、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT、JOIN、UNION、LIKE 等等,且每个 table 都至少出现在一个 query 中。
- SQL 一致性:有些 question 可能有多种 SQL 查询写法,该工作设计了标注协议,当存在多个等效 query 时,所有标注者都选择相同的 SQL 查询模式。
- 问题清晰化:不会创建模糊有歧义的问题,比如“最受欢迎”这种没有明确定义的问题;也没有需要数据库之外的常识才能回答的问题,因为这脱离了“语义解析”的训练目标。
标注工作可以借助 sqlite-web 来打开数据库并查看。
1.2 任务的定义
模型将被在不同的复杂 SQL、复杂数据库、复杂 domains 上被测试,要求模型能够对 question 理解语义,并对新的数据库有泛化能力。
任务不评估模型生成 value 的能力,因为这个 benchmark 侧重评估预测出正确的 SQL 结构和 columns,数据集中也被排除了需要常识推理和数学计算的 querys。
论文工作还对数据库的 table names 和 column names 做了清洗,让这些名字清晰且自成一体。比如将
stu id
转为
student id
二、评价指标
本论文给出了三个 metrics:Component Matching、Exact Matching 和 Execution Accuracy。
2.1 Component Matching
Component Matching 衡量的是 prediction 和 ground-truth SQL 的不同 component 的平均精确匹配效果。
SQL 中每个 keywords 视为一种 component,并将其分解为含有多个 sub-component 的 bag。比如
SELECT avg(col1), max(col2), min(col1)
被分解为一个 bag:
(avg, min, col1), (max, col2)
,然后查看 prediction 和 ground-truth SQL 的 bag 是否相同。
keywords 指的是包括所有不带 column name 和 operatiors 的 SQL 关键字,如 SELECT、WHERE 等。
被分解后,每一个 component 被分解为一个 bag,这个 bag 中的每一个元素对应一个 sub-component,这个 sub-component 也是被分解为一个 bag。
为了报告一个 model 在每个 component 上的整体表现,我们会计算每个 exact set matching 的 F1 score。
2.2 Exact Matching
Exact Matching 衡量的是两个 SQL 是否整体上等同。按照上一节的描述,只有当两个 SQL 在所有 component 上都精确匹配的情况下,这个样本预测才算做正确。
2.3 Execution Acc
Execution Acc 比较的两个 SQL 执行的结果集是否相同。
- Exact Matching 可能会产生 false negative
- Execution Acc 可能会产生 false positive
三、数据集示例
根据 SQL component 数量、conditions 等等,将 SQL queries 分成了四个难度:easy、medium、hard 和 extra hard。
下图展示了四个 level 的示例:
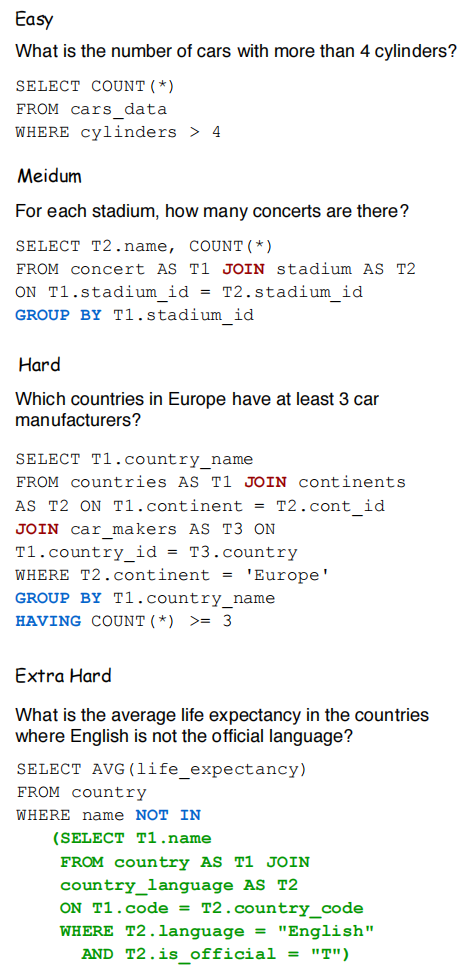
当时论文测试了已有的几个 Text2SQL 模型,也发现都没有表现很好,也说明了 Spider 数据集的难度较高。
四、实验结论
论文使用 SQLNet、TypeSQL 等模型测试了一波,发现以下整体的结论:
- 所有模型的整体表现都很低,说明 Spider 具有挑战性,尤其是 WHERE 子句的预测,因为 WHERE 子句更有可能有多个 columns 和 operators。
- 目前的模型在 test split 上拓展到新数据库时都表现较差,这说明 Spider 为模型泛化到新的数据库提出了挑战。
- 数据库的模式复杂性也会影响模型的性能,实验也发现,随着数据库的外键数量增多,表现也会下降。
五、代码
GitHub 首页中给出了 example 的格式,也给出了用于评估的脚本
evaluation.py
。
版权归原作者 yubinCloud 所有, 如有侵权,请联系我们删除。