
一、目的
以波士顿房价数据集为对象,理解数据和认识数据,掌握**梯度下降法**和**回归分析**的初步方法,掌握**模型正则化**的一般方法,对回归分析的结果解读。
二、背景知识与要求
1、背景知识
波士顿房价数据集是20世纪70年代中期波士顿郊区房价的中位数,统计了当时城市的13个指标与房价的数据,试图能找到那些指标与房价的关系。
在数据集中包含506组数据,本文将前406个作为训练和验证集,剩下的100组数据作为测试集。数据在python的sklearn库的datasets中可以load_boston直接调用,也可以在下面的地址中下载。
数据集下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/。
数据集中各特征的含义如下:

我们所说的**回归**一般指的是**线性回归**(Linear regression)。回归能用来做什么呢?我们做回归是想找到变量与变量之间的关系,比如销售量与运输距离的关系,或者次品数量与机床使用时长之间的关系,或者寻找名人的离婚率与年龄之间的关系。
回归的目的就是预测数值型的目标值,假如你要预测一台汽车功率的大小,可能会写出如下方程:
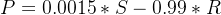
其中,P代表功率,S代表年薪,R代表你收听电台的时长,这就是**回归方程**(regression equation),其中0.0015和-0.99称为**回归系数**(regression weights)或者说每个自变量影响因变量的权重,当然也有非线性回归,比如认为是S与R的乘积,我们这里所说的回归是线性回归,线性回归的一般方程如下,当然也包括Y的初始值(截距),如果没有即为0:

输入的数据存放在矩阵X中,回归系数存放在向量W中,那么我们所要做的就是求出W,怎么求出W呢?最常用的就是找出误差最小下的W,这里所说的误差指的是预测值与真实值之间的误差,如果二者相减所得的值再求和就会出现正值与负值相抵消的情况,所以采用平方误差,即:
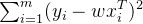
我们所要做的就是使其最小,也即找到最优的w估计值,这是统计学中最常见的问题,有很多方法如最小二乘估计或者最优化方法中的梯度下降法等,本文着重于梯度下降法,其他的这里就不一一列举。
回归的一般步骤如下:
(1)收集数据:采用任意方法
(2)准备数据:回归需要的是数值型数据,标称型数据需要转换成二值型数据,如果有多个类别可以考虑采用独热编码(one-hot)
(3)分析数据:如果可以的话,绘出数据可视化的二维图像有助于对数据做出分析和理解与前后对比
(4)训练算法:找到回归系数,可以运用多种方法。
(5)测试算法:采用决定系数
或者预测值与数据的拟合度作为定量评判的标准
(6)使用算法:使用建立好的回归方程对于输入的变量进行预测,给出一个预测值。
我们要找到平方误差的最小值,采用的方法是**梯度下降法**,也被叫做梯度上升法,该方法的思想是:要找到某函数的最小值(最大值),最好的方法是沿着**梯度**方向探寻,那么梯度是什么呢?如果是关于x的一元函数,那么梯度就是它的导数,在数学上,梯度的定义如下:
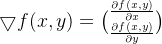
我们把梯度记为,梯度总是指向函数值增长最快的方向(反方向即减小最快的方向),但这里梯度仅仅指示方向,而未说明沿着这个方向走多少距离,我们用记作走的距离,即**步长**,那么梯度下降算法的迭代公式就很容易写出来:
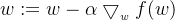
该公式被一直运行直到到达某个条件为止(如误差小于某个值时)。梯度上升算法只需要把中间的-号改成+号就行,梯度上升算法被用来求函数的最大值,而梯度下降被用来求最小值。
刚刚我们说到,我们循环迭代梯度下降算法的目的就是让平方误差最小(或者小于一定范围),而我们把平方误差除以样本数量m。即:
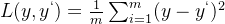
这被称为均方误差(MSE),也有另一种为平均绝对误差(MAE):
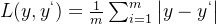
线性回归中,MSE(L2损失)计算简便,但MAE(L1损失)对异常点有更好的鲁棒性。当预测值和真实值接近时,误差的方差较小;反之误差方差非常大,相比于MAE,使用MSE会导致异常点有更大的权重,因此数据有异常点时,使用MAE作为损失函数更好,而RMSE就是在MSE的基础上再开根号。
** 损失函数(loss function)就是用来度量模型的预测值来表示,损失函数越小,模型的拟合程度就越好。正则化**(Regularization)就是在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性(比如模型为了使损失函数最小,拟合出来的函数并不光滑,导致过拟合),具体方法就是不让损失函数中高次变量的参数大小不能太大,下面给出了一个例子:
假设我的回归方程是:,那么为了使高次变量的参数大小不能太大,我们可以把损失函数写作如下形式:

为了使损失函数最小,我们只能让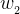极小,这样就实现了正则化,那么一般我们把前面的系数1000记作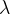,而各个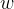有正有负,所以我们取平方,这样就有了损失函数的一般形式:
![L(y,y^{`})=\frac{1}{2m}[\sum_{i=1}^{m}(y-y^{`})^{2}+\lambda \sum_{j=1}^{n}w_{j}^{2}]](https://latex.csdn.net/eq?L%28y%2Cy%5E%7B%60%7D%29%3D%5Cfrac%7B1%7D%7B2m%7D%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D%28y-y%5E%7B%60%7D%29%5E%7B2%7D+%5Clambda%20%5Csum_%7Bj%3D1%7D%5E%7Bn%7Dw_%7Bj%7D%5E%7B2%7D%5D)
相应的,梯度的公式也会随之变化,为了更好的计算梯度,在求导的时候可以约简,这里把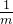写成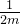,对于整体来说无太大影响,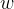的更新函数如下,即对上式求梯度再乘以(往梯度方向走步):
![w=w-\alpha [\frac{1}{m}(wx^{T}x-y^{T}x)-w\frac{\lambda }{m}]](https://latex.csdn.net/eq?w%3Dw-%5Calpha%20%5B%5Cfrac%7B1%7D%7Bm%7D%28wx%5E%7BT%7Dx-y%5E%7BT%7Dx%29-w%5Cfrac%7B%5Clambda%20%7D%7Bm%7D%5D)
2、要求
要求回答以下问题:
- 模型的错误率如何?以MSE,RMSE为例。
- 随着梯度下降法迭代的进行,错误率是如何变化的?画图表示。
- 模型的正则化项对模型结果的影响如何?请画图(用横坐标表示正则化项的权重,纵坐标表示MSE)说明是如何选择正则化项的。
- 怎么对输入特征进行预处理(特征选择、行归一化、列归一化)。
- 编写程序实现模型的训练和测试,不使用SPSS或者调用其它机器学习的工具包实现。
三、python代码实现
首先导入相关库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
先把数据存成csv格式并简单的查看一下数据:
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston['target']
df.to_csv('./boston.csv', index=None)
data = pd.read_csv(r'./boston.csv')
data.head()
结果如下: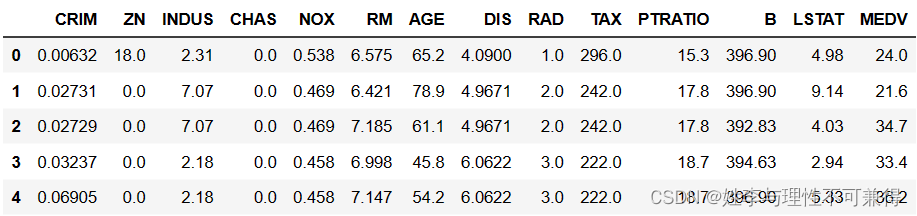
查看数据是否存在空值:
data.isnull().sum()
发现不存在空值。
查看一下数据的行列数:
data.shape
可以看出数据是506行*14列,由于各个特征值之间的量纲不同,为了消除量纲的影响,进行数据的规范化处理,有三种规范化方法:最大最小规范化、标准差规范化和十进制规范化。
各个规范化的代码如下表示:
(data - data.min())/(data.max() - data.min()) #最小-最大规范化
(data - data.mean())/data.std() #标准差规范化
data/10**np.ceil(np.log10(data.abs().max())) #十进制规范化
本文选择采用标准差规范化,规范化完成之后对训练集和测试集进行划分,选取前400行作为训练集,剩余的106行作为测试集:
cols = data.shape[1] # cols为data的列数
# 选取前400作为训练集
train_x = data.iloc[:400,:cols-1] # 选取前13列作为因变量
train_y = data.iloc[:400,cols-1:cols]# 选取最后一列作为自变量
# 选取后106行作为测试集
test_x = data.iloc[400:,:cols-1]
test_y = data.iloc[400:,cols-1:cols]
数据的收集和准备工作已经做好了,接下来建立线性回归模型,定义一个线性模型的类:
class linearRegression:
"""python语言实现线性回归(梯度下降法)"""
def __init__(self, alpha, times, l):
"""初始化方法
参数解释:
alpha:float
步长,也被叫做学习率(权重调整的幅度)
times: int
循环迭代的次数,达到一定次数终止迭代
l: int
正则化参数
"""
self.alpha = alpha
self.times = times
self.l= l
# 损失函数
def CostFunction(self, x, y, w):
inner = np.power(y-(w*x.T).T, 2)
return np.sum(inner)/(2*len(x))
# 正则化损失函数
def regularizedcost(self, x, y, w):
reg = (self.l/(2*len(x))) * (np.power(w, 2).sum())
return self.CostFunction(x, y, w) + reg
def fit(self,x,y):
"""建立模型
参数解释:
x:自变量,特征矩阵
y:因变量,真实值
"""
# 将数据转换成numpy矩阵
x = np.matrix(x.values)
y = np.matrix(y.values)
# 添加截距列,值为1,axis=1 添加列
x = np.insert(x,0,1,axis=1)
# 创建权重向量W,初始值默认为0,长度比特征数量多1(多出的一项为截距)。
self.w_ = np.zeros(x.shape[1])
# 创建损失列表,用来保存每次迭代后的损失值。
self.loss_ = []
#进行times次数的迭代,在每次迭代过程中,计算损失值,不断调整权重值,使得损失值不断下降。
for i in range(self.times):
# 计算正则化损失函数值:
loss = self.regularizedcost(x, y, self.w_)
#加入到损失列表
self.loss_.append(loss)
# 根据步长调整权重w_
self.w_ = self.w_ - (self.alpha / len(x)) * (self.w_ * x.T * x - y.T * x) - (self.alpha * self.l / len(x)) * self.w_
def predict(self, x):
"""根据参数传递的样本,对样本数据进行预测
参数解释:
x:测试样本。
返回值:
result:预测结果。
"""
x = np.asarray(x)
x = np.insert(x,0,1,axis=1)
result = np.dot(x, self.w_.T)
return result
建立线性回归模型,设置初始参数,求出错误率(误差值):
alpha=0.001
times=10000
l=0
lr = linearRegression(alpha,times,l)
lr.fit(train_x,train_y)
MSE = lr.loss_
RMSE = list(map(lambda num:sqrt(num), lr.loss_))
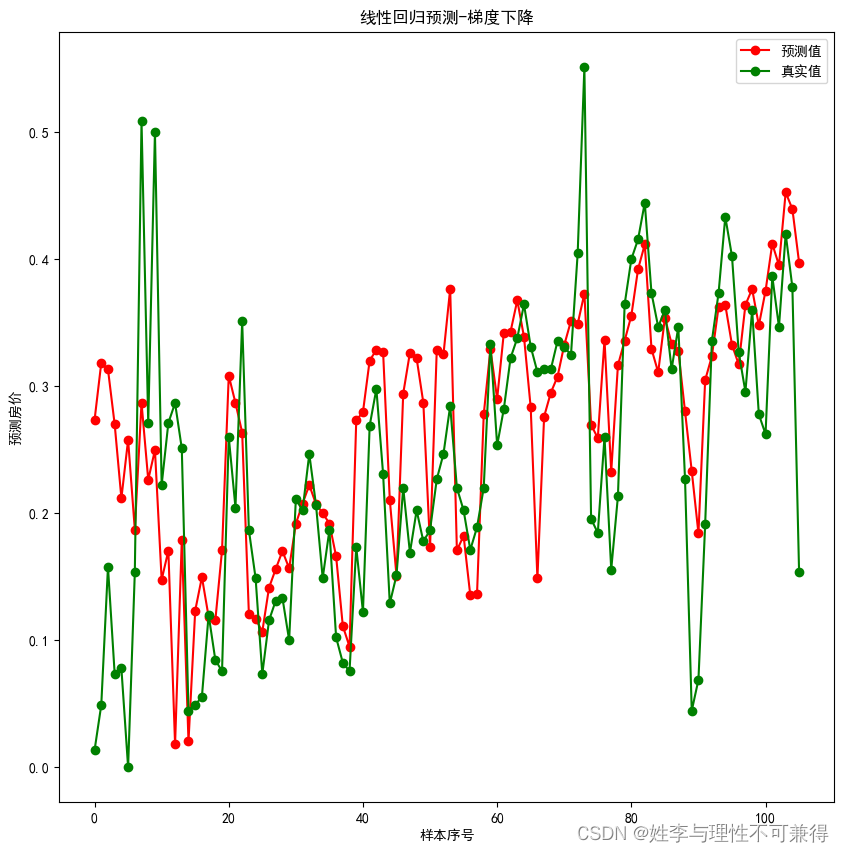
查看一下结果和在测试集上的表现情况:
result = lr.predict(test_x)
# 为了防止画图出现中文乱码设置字体参数
rcParams["font.family"] = "SimHei"
rcParams["axes.unicode_minus"] = False
plt.figure(figsize=(10,10))
plt.plot(result, "ro-", label="预测值")
plt.plot(test_y.values, "go-", label="真实值") # pandas读取时serise类型,我们需要转为ndarray
plt.title("线性回归预测-梯度下降")
plt.xlabel("样本序号")
plt.ylabel("预测房价")
plt.legend()
plt.show()
出错误率(MSE)随迭代次数变化的图象:
fig, ax = plt.subplots(figsize=(20,10))
ax.plot(np.arange(times), MSE, 'r') # np.arange()返回等差数组
ax.set_xlabel('迭代次数')
ax.set_ylabel('错误率(MSE)')
ax.set_title('错误率(MSE)随迭代次数变化的图象')
plt.show()

画出错误率(RMSE)随迭代次数变化的图象:
fig, ax = plt.subplots(figsize=(20,10))
ax.plot(np.arange(times), RMSE, 'r') # np.arange()返回等差数组
ax.set_xlabel('迭代次数')
ax.set_ylabel('错误率(RMSE)')
ax.set_title('错误率(RMSE)随迭代次数变化的图象')
plt.show()

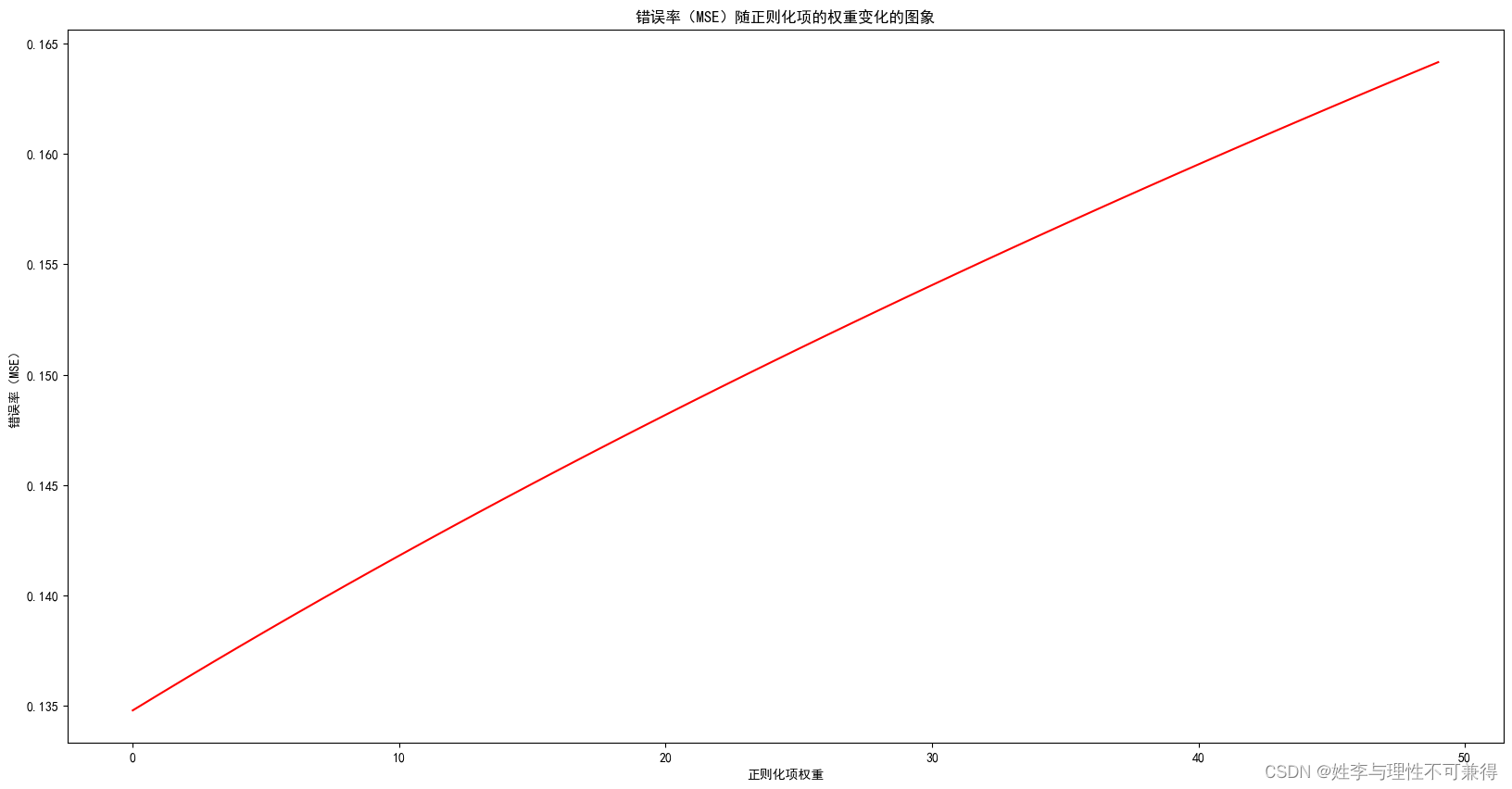
画出错误率(MSE)随正则化项的权重变化的图象:
MSE_ = []
for l_ in range(0,l):
lr = linearRegression(alpha,times,l_)
lr.fit(train_x,train_y)
MSE_.append(lr.loss_[-1])
fig, ax = plt.subplots(figsize=(20,10))
ax.plot(np.arange(l), MSE_, 'r') # np.arange()返回等差数组
ax.set_xlabel('正则化项权重')
ax.set_ylabel('错误率(MSE)')
ax.set_title('错误率(MSE)随正则化项的权重变化的图象')
plt.show()
大功告成。
本文转载自: https://blog.csdn.net/weixin_59938092/article/details/129746003
版权归原作者 姓李与理性不可兼得 所有, 如有侵权,请联系我们删除。
版权归原作者 姓李与理性不可兼得 所有, 如有侵权,请联系我们删除。