

Pandas是一个受众广泛的python数据分析库。它提供了许多函数和方法来加快数据分析过程。pandas之所以如此普遍,是因为它的功能强大、灵活简单。本文将介绍20个常用的 Pandas 函数以及具体的示例代码,助力你的数据分析变得更加高效。

首先,我们导入
numpy
和
pandas
包。
importnumpyasnp
importpandasaspd
1. Query
我们有时需要根据条件筛选数据,一个简单方法是
query
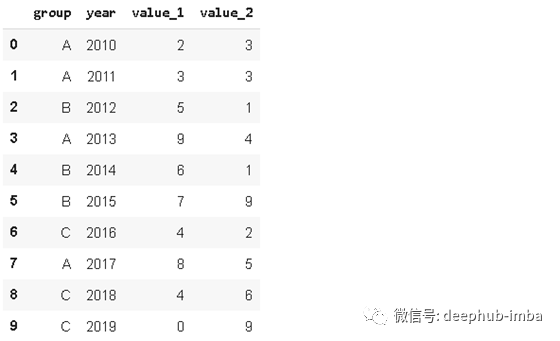
函数。为了更直观理解这个函数,我们首先创建一个示例 dataframe。
values_1 = np.random.randint(10, size=10)
values_2 = np.random.randint(10, size=10)
years = np.arange(2010,2020)
groups = ['A','A','B','A','B','B','C','A','C','C']
df = pd.DataFrame({'group':groups, 'year':years, 'value_1':values_1, 'value_2':values_2})
df
使用
query
函数的语法十分简单:
df.query('value_1 < value_2')

2. Insert
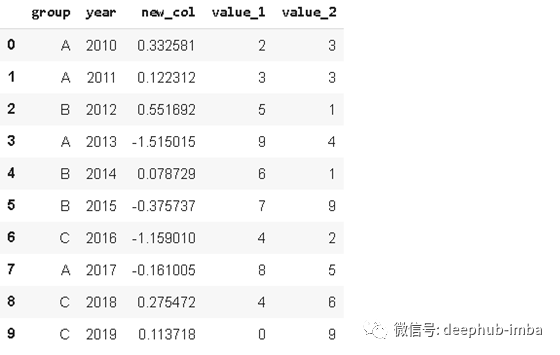
当我们想要在 dataframe 里增加一列数据时,默认添加在最后。当我们需要添加在任意位置,则可以使用
insert
函数。使用该函数只需要指定插入的位置、列名称、插入的对象数据。
# new column
new_col = np.random.randn(10)
# insert the new column at position 2
df.insert(2, 'new_col', new_col)
df
3. Cumsum
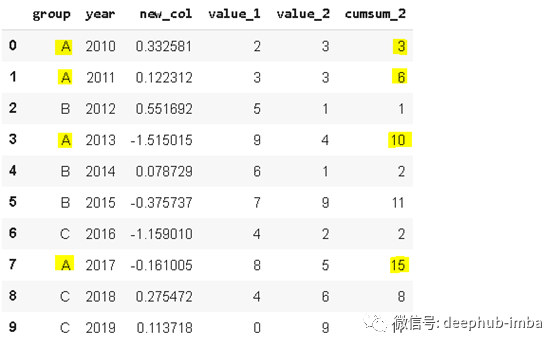
示例dataframe 包含3个小组的年度数据。我们可能只对年度数据感兴趣,但在某些情况下,我们同样还需要一个累计数据。Pandas提供了一个易于使用的函数来计算加和,即
cumsum
。
如果我们只是简单使用
cumsum
函数,(A,B,C)组别将被忽略。这样得到的累积值在某些情况下意义不大,因为我们更需要不同小组的累计数据。对于这个问题有一个非常简单方便的解决方案,我们可以同时应用
groupby
和
cumsum
函数。
df['cumsum_2'] = df[['value_2','group'].groupby('group').cumsum()]
df
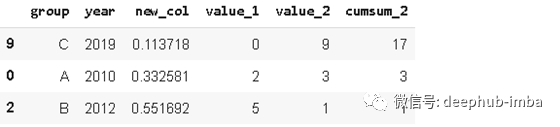
4. Sample
Sample
方法允许我们从DataFrame中随机选择数据。当我们想从一个分布中选择一个随机样本时,这个函数很有用。
sample1 = df.sample(n=3)
sample1
上述代码中,我们通过指定采样数量
n
来进行随机选取。此外,也可以通过指定采样比例
frac
来随机选取数据。当
frac=0.5
时,将随机返回一般的数据。
sample2 = df.sample(frac=0.5)
sample2
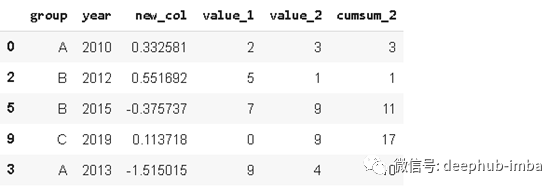
为了获得可重复的样品,我们可以指定
random_state
参数。如果将整数值传递给random_state,则每次运行代码时都将生成相同的采样数据。
5. Where
where
函数用于指定条件的数据替换。如果不指定条件,则默认替换值为 NaN。
df['new_col'].where(df['new_col'] >0, 0)

where
函数首先根据指定条件定位目标数据,然后替换为指定的新数据。上述代码中,
where(df['new_col']>0,0)
指定'new_col'列中数值大于0的所有数据为被替换对象,并且被替换为0。
重要的一点是,pandas 和 numpy的
where
函数并不完全相同。我们可以得到相同的结果,但语法存在差异。
Np.where
还需要指定列对象。以下两行返回相同的结果:
df['new_col'].where(df['new_col'] >0, 0)
np.where(df['new_col'] >0, df['new_col'], 0)
6. Isin
在处理数据帧时,我们经常使用过滤或选择方法。
Isin
是一种先进的筛选方法。例如,我们可以根据选择列表筛选数据。
years = ['2010','2014','2017']
df[df.year.isin(years)]
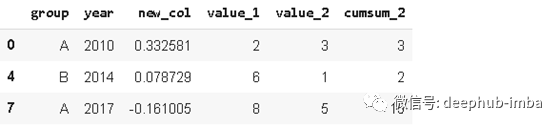
7. Loc 和 iloc
Loc 和 iloc 函数用于选择行或者列。
- loc:通过标签选择
- iloc:通过位置选择
loc
用于按标签选择数据。列的标签是列名。对于行标签,如果我们不分配任何特定的索引,pandas默认创建整数索引。因此,行标签是从0开始向上的整数。与
iloc
一起使用的行位置也是从0开始的整数。
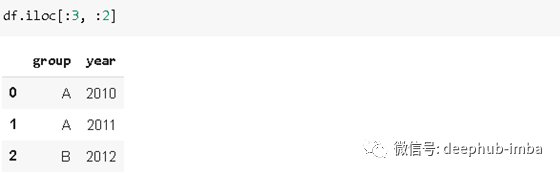
下述代码实现选择前三行前两列的数据(
iloc
方式):
df.iloc[:3,:2]
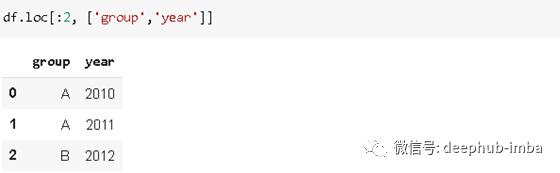
下述代码实现选择前三行前两列的数据(
loc
方式):
df.loc[:2,['group','year']]
注:当使用
loc
时,包括索引的上界,而使用iloc则不包括索引的上界。
下述代码实现选择"1","3","5"行、"year","value_1"列的数据(
loc
方式):
df.loc[[1,3,5],['year','value_1']]

8. Pct_change
此函数用于计算一系列值的变化百分比。假设我们有一个包含[2,3,6]的序列。如果我们对这个序列应用
pct_change
,则返回的序列将是[NaN,0.5,1.0]。从第一个元素到第二个元素增加了50%,从第二个元素到第三个元素增加了100%。
Pct_change
函数用于比较元素时间序列中的变化百分比。
df.value_1.pct_change()

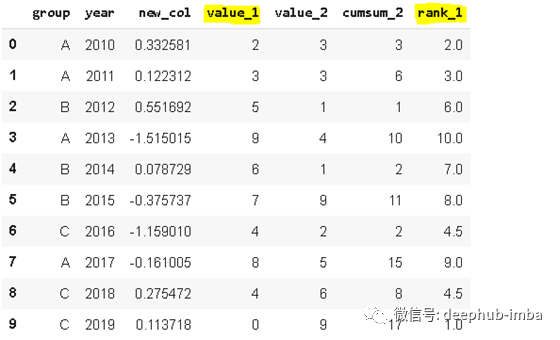
9. Rank
Rank
函数实现对数据进行排序。假设我们有一个包含[1,7,5,3]的序列。分配给这些值的等级为[1,4,3,2]。
df['rank_1'] = df['value_1'].rank()
df
10. Melt
Melt
用于将维数较大的 dataframe转换为维数较少的 dataframe。一些dataframe列中包含连续的度量或变量。在某些情况下,将这些列表示为行可能更适合我们的任务。考虑以下情况:
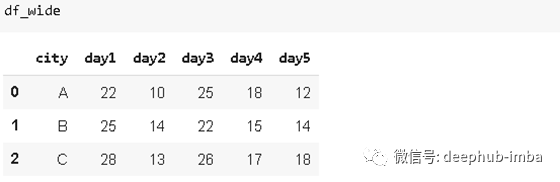
我们有三个不同的城市,在不同的日子进行测量。我们决定将这些日子表示为列中的行。还将有一列显示测量值。我们可以通过使用'melt'函数轻松实现:
df_wide.melt(id_vars=['city'])
df
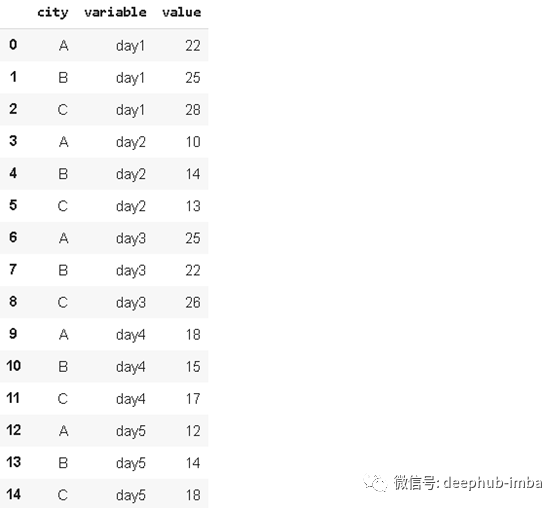
变量名和列名通常默认给出。我们也可以使用
melt
函数的var_name和value_name参数来指定新的列名。
11. Explode
假设数据集在一个观测(行)中包含一个要素的多个条目,但您希望在单独的行中分析它们。

我们想在不同的行上看到“c”的测量值,这很容易用
explode
来完成。
df1.explode('measurement').reset_index(drop=True)
df

12. Nunique
Nunique
统计列或行上的唯一条目数。它在分类特征中非常有用,特别是在我们事先不知道类别数量的情况下。让我们看看我们的初始数据:
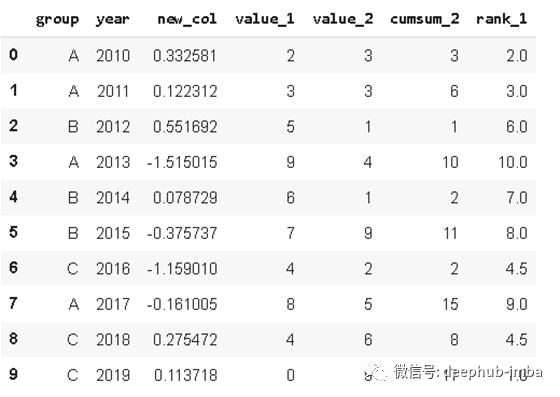
df.year.nunique()
10
df.group.nunique()
3
我们可以直接将
nunique
函数应用于dataframe,并查看每列中唯一值的数量:

如果axis参数设置为1,
nunique
将返回每行中唯一值的数目。
13. Lookup
'lookup'可以用于根据行、列的标签在dataframe中查找指定值。假设我们有以下数据:
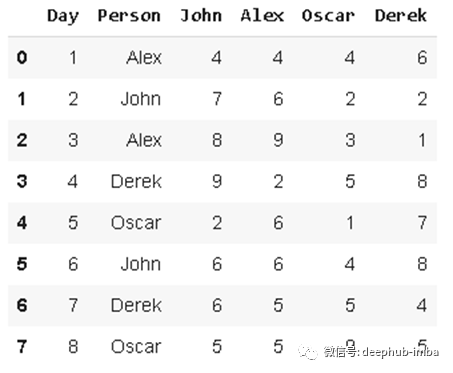
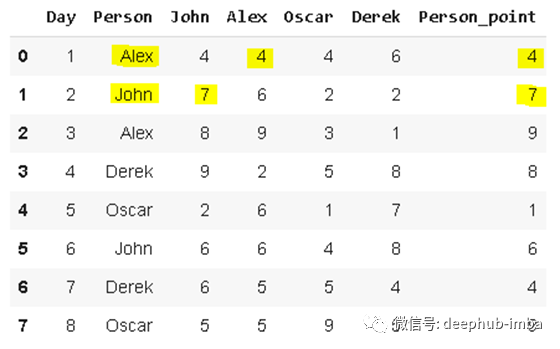
我们要创建一个新列,该列显示“person”列中每个人的得分:
df['Person_point'] = df.lookup(df.index, df['Person'])
df
14. Infer_objects
Pandas支持广泛的数据类型,其中之一就是object。object包含文本或混合(数字和非数字)值。但是,如果有其他选项可用,则不建议使用对象数据类型。使用更具体的数据类型,某些操作执行得更快。例如,对于数值,我们更喜欢使用整数或浮点数据类型。
infer_objects
尝试为对象列推断更好的数据类型。考虑以下数据:
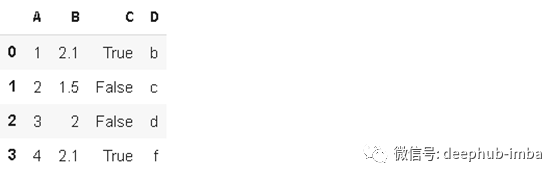
df2.dtypes
A object
B object
C object
D object
dtype: object
通过上述代码可知,现有所有的数据类型默认都是object。让我们看看推断的数据类型是什么:
df2.infer_objects().dtypes
A int64
B float64
C bool
D object
dtype: object
'infer_obejects'可能看起来微不足道,但在有很多列时作用巨大。
15. Memory_usage
Memory_usage()
返回每列使用的内存量(以字节为单位)。考虑下面的数据,其中每一列有一百万行。
df_large = pd.DataFrame({'A': np.random.randn(1000000),
'B': np.random.randint(100, size=1000000)})
df_large.shape
(1000000, 2)
每列占用的内存:
df_large.memory_usage()
Index 128
A 8000000
B 8000000
dtype: int64
整个 dataframe 占用的内存(转换为以MB为单位):
df_large.memory_usage().sum() / (1024**2) #converting to megabytes
15.2589111328125
16. Describe
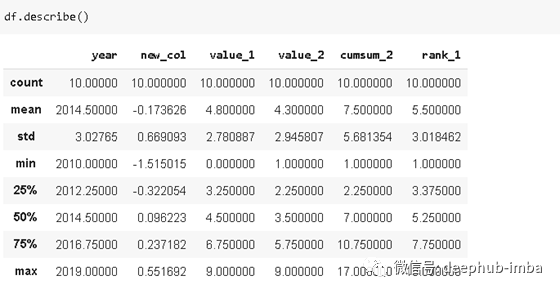
describe
函数计算数字列的基本统计信息,这些列包括计数、平均值、标准偏差、最小值和最大值、中值、第一个和第三个四分位数。因此,它提供了dataframe的统计摘要。
17. Merge
Merge()
根据共同列中的值组合dataframe。考虑以下两个数据:
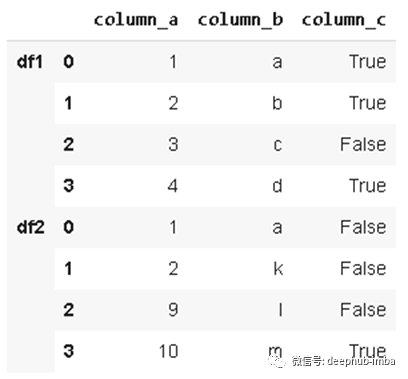
我们可以基于列中的共同值合并它们。设置合并条件的参数是“on”参数。
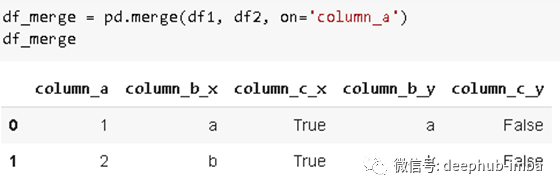
df1和df2是基于column_a列中的共同值进行合并的,
merge
函数的
how
参数允许以不同的方式组合dataframe,如:“inner”、“outer”、“left”、“right”等。
- inner:仅在on参数指定的列中具有相同值的行(如果未指定其它方式,则默认为 inner 方式)
- outer:全部列数据
- left:左一dataframe的所有列数据
- right:右一dataframe的所有列数据
18. Select_dtypes
Select_dtypes
函数根据对数据类型设置的条件返回dataframe的子集。它允许使用include和exlude参数包含或排除某些数据类型。
df.select_dtypes(include='int64')
df.select_dtypes(exclude='int64')
19. Replace
顾名思义,它允许替换dataframe中的值。第一个参数是要替换的值,第二个参数是新值。
df.replace('A', 'A_1')
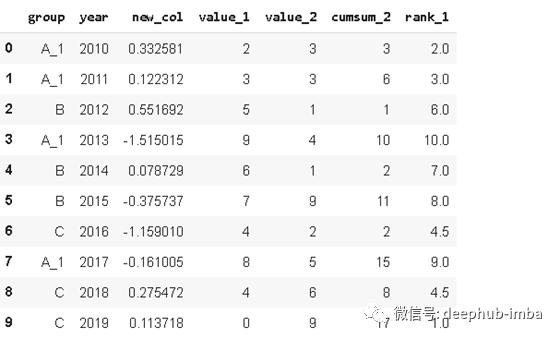
我们也可以在同一个字典中多次替换。
df.replace({'A':'A_1', 'B':'B_1'})
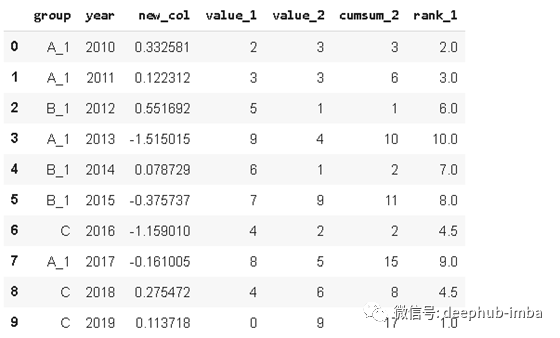
20. Applymap
Applymap
用于将一个函数应用于dataframe中的所有元素。请注意,如果操作的矢量化版本可用,那么它应该优先于applymap。例如,如果我们想将每个元素乘以一个数字,我们不需要也不应该使用applymap函数。在这种情况下,简单的矢量化操作(例如
df*4
)要快得多。
然而,在某些情况下,我们可能无法选择矢量化操作。例如,我们可以使用pandas dataframes的style属性更改dataframe的样式。以下代码将负值的颜色设置为红色:
defcolor_negative_values(val):
color = 'red'ifval<0else'black'
return'color: %s'%color
通过
Applymap
将上述代码应用到dataframe:
df3.style.applymap(color_negative_values)

作者:Soner Yıldırım
deephub翻译组:Oliver Lee
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********