

- Title:Masked Autoencoders Are Scalable Vision Learners
- Paper:https://arxiv.org/abs/2111.06377
- Github:https://github.com/facebookresearch/mae
摘要
本文证明了 masked autoencoder (MAE) 是一种可扩展的 (scalable) CV 自监督学习器。MAE 的思想很简单:mask 输入图像的随机 patches,并重建缺失的 pixels。MAE 基于两个核心设计。首先,我们开发了一个非对称 (asymmetric) 的编码器-解码器架构,编码器只操作于 patches 的可见子集 (无 mask tokens),轻量级解码器 从潜在表示和 mask tokens 中重构原始图像。其次,我们发现高比例地 mask 输入图像 (如 75%) 产生了一个重要 (non-trival) 和有意义的自监督任务。耦合 (coupling) 这两种设计使我们能够有效地训练大型模型:我们加速训练 (3×或更多) 并提高准确率。我们的可扩展方法 允许学习 具有良好泛化能力的高容量 (high-capacity) 模型:例如,在只用 ImageNet-1K 的方法中,一个普通的 ViT-Huge 达到最佳准确率 (87.8%)。在下游任务中的迁移性能优于有监督预训练,并表现出有前景的扩展行为 (scaling behavior)。
一、引言
深度学习见证了具有不断增长的能力和容量 (capability and capacity) 的架构的爆炸式增长。在硬件的快速增长的帮助下,今天的模型可以很容易地过拟合 100 万张图像,并开始要求数亿张 —— 通常是公开不可访问的 —— 带标签的图像。
这种对数据的饥渴已经在 NLP 中通过 自监督预训练 被成功地解决了。GPT 中基于 autoregressive 的语言建模,和 BERT 中的 masked autoencoding 的解决方案 在概念上很简单:**它们删除部分数据,并学习预测被删除的内容**。这些方法现在可以训练包含超过 1000 亿个参数的generalizable NLP 模型。
**Masked autoencoding 的思想,是一种更一般的 denoising autoencoders 的形式,是自然的且适用于 CV 的**。事实上,与视觉密切相关的研究早于 BERT。然而,尽管随着 BERT 的成功,人们对这一想法产生了极大的兴趣,但在视觉领域的 autoencoding 方法的进展落后于 NLP。我们会问:**是什么使 masked autoencoding 在视觉和语言之间有所不同**?我们试图从以下角度来回答这个问题:
(i) 直到最近的架构都是不同的。在视觉中,卷积网络在过去十年的中占主导地位。卷积通常在常规 grids 上运行,要将 mask token 或位置嵌入等 “indicators” 集成到卷积网络中并不简单。然而,随着 ViT 的引入,架构的鸿沟已经得到了解决且,不应再构成障碍。
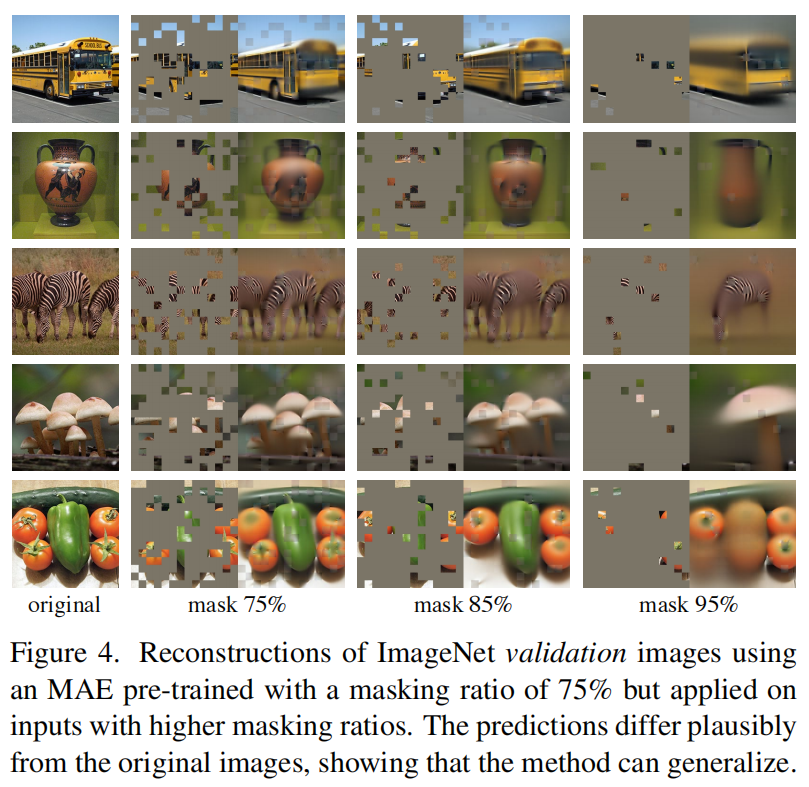
(ii) 语言和视觉之间的信息密度不同。**语言是由人类产生的信号,具有高度的语义性和信息密集性 (highly semantic and information-generated)**。当训练一个模型只预测每个句子中缺失的一些单词时,这项任务似乎能诱导 (induce) 复杂的语言理解。相反,图像是具有大量空间冗余的自然信号,例如,丢失的 patches 可以从相邻的 patches 中恢复,而几乎不需要对 parts、objects 和 scenes 的高级理解。为克服这种差异并鼓励学习有用的特征,我们展示了一个在 CV 中表现很好的简单策略:masking 非常高比例的随机 patches。这种策略在很大程度上减少了冗余,并创造了一个具有挑战性的自监督任务,需要对低级图像统计之外的整体 (holistic) 理解。要对我们的重建任务进行定性的了解,请参见图 2-4。
(iii) autoencoder 的解码器,它将潜在的表示映射回输入,在重建文本和图像之间起着不同的作用。**在视觉中,解码器重建像素,因此其输出的语义级别低于常见的识别任务。相反,在语言中,解码器预测包含丰富语义信息的缺失单词**。虽然在 BERT 中,解码器可以是简单的 (一个MLP),但我们发现,**对于图像,解码器的设计 在决定学习到的潜在表示的语义水平中 起着关键作用**。
在此分析的驱动下 (Driven by this analysis),我们提出了一种简单的、有效的、可扩展的 masked autoencoder (MAE) 形式,用于视觉表示学习。MAE 从输入图像中 mask 随机 patches,并重建像素空间中缺失的 patches。它具有非对称的编码器-解码器设计。我们的编码器只对可见的 patches 子集进行操作 (没有 mask tokens),并且我们的解码器是轻量级的,可以基于潜在表示和 mask tokens 重建输入 (图 1)。在我们的非对称编码器-解码器中,将 mask tokens 转移到小解码器可以大大减少计算量。在这种设计下,一个非常高的掩蔽率 (如 75%) 可以实现双赢的场景 (win-win scenario):它优化准确率,同时允许编码器只处理一小部分 (如 25%) patches。这可以将整体预训练时间减少 3× 或更多,同样减少内存消耗,使我们能够轻松地将 MAE 扩展为大型模型。
MAE 学习了非常高容量的模型,且具有很好的泛化能力。通过 MAE 预训练,我们可以在 ImageNet-1K (IN1K) 上训练诸如 ViT-Large/-Huge 这样的对数据饥渴的模型,从而提高泛化性能。使用一个普通的 ViT-Huge 模型,当我们在 ImageNet-1K 上微调时,达到了 87.8% 的准确率,这优于之前所有只使用 ImageNet-1K 数据的结果。我们还评估了迁移学习的目标检测、实例分割和语义分割。在这些任务中,我们的预训练比有监督预训练取得了更好的结果,更重要的是,我们通过扩大 (scaling up) 模型观察到显著的收益。这些观察结果与 NLP 中自监督预训练的观察结果一致,我们希望 NLP 能够使 CV 领域探索类似的轨迹。
二、相关工作
**Masked language modeling (MLM) **及其对手 autoregressive,如 BERT 和 GPT,是 NLP 中非常成功的预训练方法。这些方法包含了部分输入序列,并训练模型来预测缺失的内容。这些方法已被证明能够良好扩展/放缩 (scale excellently),并且大量的证据表明,这些预训练好的表示可以很好地推广到各种下游任务。
**Autoencoding**是学习表示的一种经典方法。它有一个将输入映射到潜在表示 (latent representations) 的编码器,和一个重建输入的解码器。例如,PCA 和 k-means 是 autoencoders。Denoising autoencoders (DAE) 是一类 autoencoders,它会损坏 (corrupt) 一个输入信号,并学习重建原始的、未损坏的信号。一系列的方法可以被认为是在不同的损坏下的广义 DAE,例如,masking pixels 或移除颜色通道。我们的 MAE是 denoising autoencoding 的一种形式,但在许多方面与经典的 DAE 不同。
** **Masked image encoding方法从被 masking 损坏的图像中学习表示。Stacked denoising autoencoders 作为开创性工作将 masking 作为DAE 中的一种噪声类型。Context Encoder 使用卷积网络来补全大的缺失区域。由于 NLP 的成功,近期相关方法是基于 Transformer 的。iGPT 处理像素序列并预测未知像素。ViT 研究了自监督学习预测 masked patch。最近,BEiT 提出预测离散 tokens。
**Self-supervised learning** 方法对 CV 具有显著兴趣,通常聚焦于预训练的不同前置 (pretext) 任务。最近,对比学习非常流行,它建模两个或多个视图 (views) 之间的图像相似性和不相似性 (或仅为相似性)。对比的 (Contrastive) 和相关方法强烈依赖于数据增广。Autoencoding 追求一个概念上不同的方向,相比于我们将呈现出的内容,它将表现出不同的行为。
三、方法
我们的 masked autoencoder (MAE) 是一种简单的 autoencoding 方法,它可以重建原始信号。像所有的 autoencoders 一样,本方法有一个 将观察到的信号映射到一个潜在表示 的编码器 ,和一个从潜在表示重建原始信号 的解码器。与经典的 autoencoders 不同,我们采用了一种**非对称的设计**,**允许编码器只操作部分的、观察到的信号 (没有 mask tokens)**,以及一个轻量级的解码器,从潜在表示和 mask tokens 重j建完整的信号。图 1 说明了接下来将介绍的这个想法。
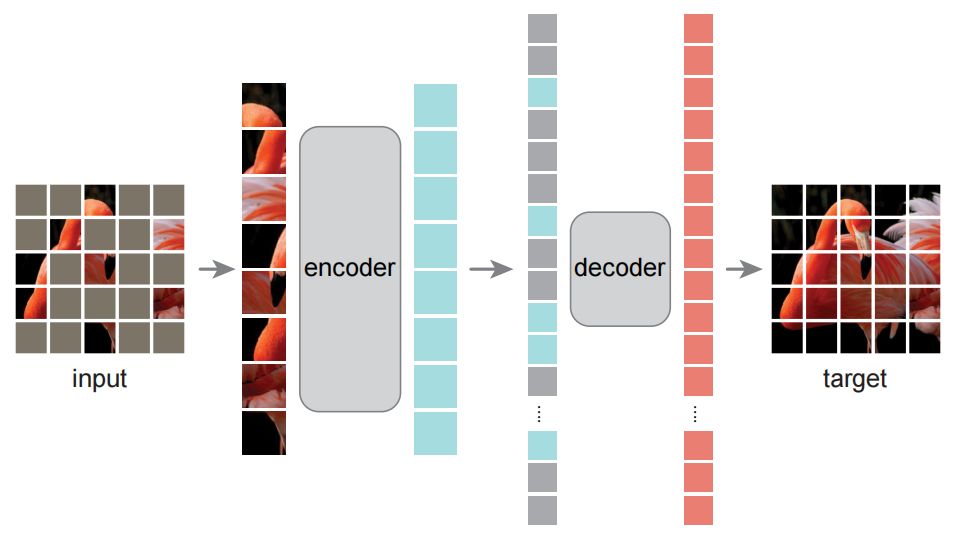
图 1:MAE 架构。
在预训练过程中,大量的图像 patches 的随机子集 (如 75%) 被 mask。
该编码器应用于可见 patches 的小子集。
在编码器之后引入 mask tokens,全部经编码的可见 patches 和不可见 mask tokens 由一个小解码器处理,从而按像素重建原始图像。
预训练后,解码器被舍弃,编码器被应用于未损坏的图像 (完整的 patches 集合) 进行识别任务。
**Masking**。我们 **按照 ViT 将一幅图像划分成规则无重叠的 (non-overlapping) patches**。然后,**从所有 patches 中采样一个子集,并 mask (即移除) 其余未被采样的 patches**。采样策略很简单:**按照均匀分布随机采样 patches 而不替换**。我们仅将其称为 “随机采样”。
具有 **高 masking 比例的随机采样** (即被移除的 patches 的比例) **很大程度上消除了冗余**,从而创建了一个不易通过从可见的相邻 patches 进行外推/外插 (extrapolation) 来解决的任务 (见图 2-4)。**均匀分布防止了潜在的中心偏差 **(即在图像中心附近有更多的 masked patches)。最后,高度稀疏的输入为设计一个有效的编码器创造了机会,接下来将介绍。

**MAE encoder**。编码器是一个只应用于 visible & unmasked patches 的 ViT。正如一个标准 ViT,编码器 通过一个添加了位置嵌入的线性投影 来嵌入 patches,然后通过一系列 Transformer blocks 处理结果集。然而,**编码器只操作于整个集合的一小个子集 (如 25%)**。删除 masked patches;不使用 mask tokens。这允许** 只用一小部分的计算和内存 来训练非常大的编码器**。完整的集合由一个轻量级解码器处理。
**MAE decoder**。MAE 解码器的输入是完整的 tokens 集合,包括 (i) 经编码的可见 patches,和 (ii) mask tokens。见图 1。每个 mask token 是一个共享的、经学习的向量,它指示要预测的缺失 patches 的存在。我们 **向这个完整集中的所有 tokens 添加位置嵌入,否则 mask token 就没有关于它们在图像中所处的位置的信息**。该解码器有另一系列的 Transformer blocks。
MAE 解码器 **仅用于在预训练时执行图像重建任务****(只有编码器产生用于识别的图像表示)**。因此,解码器架构可以以独立于编码器设计的方式灵活设计。实验使用非常小的解码器,比编码器更窄更浅 (narrow and shallow)。例如,相比于编码器,默认的解码器的每个 token 计算 < 10%。通过这种不对称的设计,完整的 tokens 集只由轻量级的解码器来处理,这大大减少了预训练时间。
**Reconstruction target**。MAE 通过预测每个 masked patch 的像素值来重建输入。**解码器输出的每个元素 都是一个 代表一个 patch 的像素值的向量。解码器的最后一层是一个线性投影,其输出通道数 等于 一个 patch 中的像素值数** (如果 L = 单个 patch 的像素数,那么 D = patch 数 ???)。解码器的输出被 reshaped 以形成一幅经重建的图像。损失函数为像素空间中经重建图像和原始图像间的** MSE**,且 **只计算在 masked patches 上的损失**,类似于 BERT (不同于 **计算所有像素损失的传统 denoising autoencoders (DAE)**,仅在 masked patch 上计算损失 纯粹是由 **结果驱动的**:计算所有像素上的损失会导致准确率的轻微下降,例如 ∼0.5%)。
我们还研究了一个变体,其 **重建目标 **是 **每个 masked patch 的归一化像素值**。具体来说,计算一个 patch 中所有像素的平均值和标准差来归一化 patch。在实验中,使用归一化像素作为重建目标,**改善了表示的质量**。
**Simple implementation**。MAE 预训练可以高效地实现 而无需任何专门的稀疏操作。首先,**为每个输入 patch 生成一个 token** (通过添加位置嵌入的线性投影)。接着,**随机 shuffle tokens 列表,并根据 masking 比例删除 tokens 列表的最后一部分**。该过程为编码器产生一个小的 tokens 子集,相当于 无替换的 patches 采样 (无放回抽样?)。编码后,**为经编码的 patches 列表****额外加入 一个 mask tokens 列表**,并 **unshuffle (随机 shuffle 的反操作)** 该完整列表,**以将所有 tokens 与它们的 tagrtes 对齐**。解码器被用于这个完整的列表 (添加了位置嵌入)。如上所述 (as noted),无需稀疏操作。这个简单的实现引入了可以忽略不计的开销,因为 shuffle 和 unshuffle 操作很快。
四、ImageNet 实验
我们用 ImageNet-1K (IN1K) 训练集 自监督预训练。然后,进行有监督训练,通过 **(i) end-to-end fine-tuning** 或 **(ii) linear-probing** 来评估表示。我们报告了单个 **224×224 裁剪的 top-1 验证准确率**。详见附录A.1。
**Baseline: ViT-Large**。消融研究 使用 **ViT-Large (ViT-L/16) 作为主干**。ViT-L 非常大 (比 ResNet-50 大一个数量级),且倾向于过拟合。以下是** 从头开始训练的 ViT-L** 与** 微调的基线 MAE** 的比较。可见,**不论是原版 ViT-Large,还是添加了强正则化的 ViT-Large,性能都大幅落后于基线 MAE**。
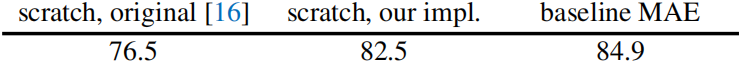
注意,从头开始训练原版有监督 ViT-L 并不重要 (76.5%),一个具有强正则化的好方法才是需要的 (a good recipe) (82.5%, 见附录 A.2)。即便如此,我们的 MAE 预训练也有了很大的改善 (84.9%)。此处,微调 50 个 epochs,而从头开始训练 200 个 epochs,这意味着 (implying that) **微调的准确率很大程度上依赖于预训练**。
4.1 主要属性
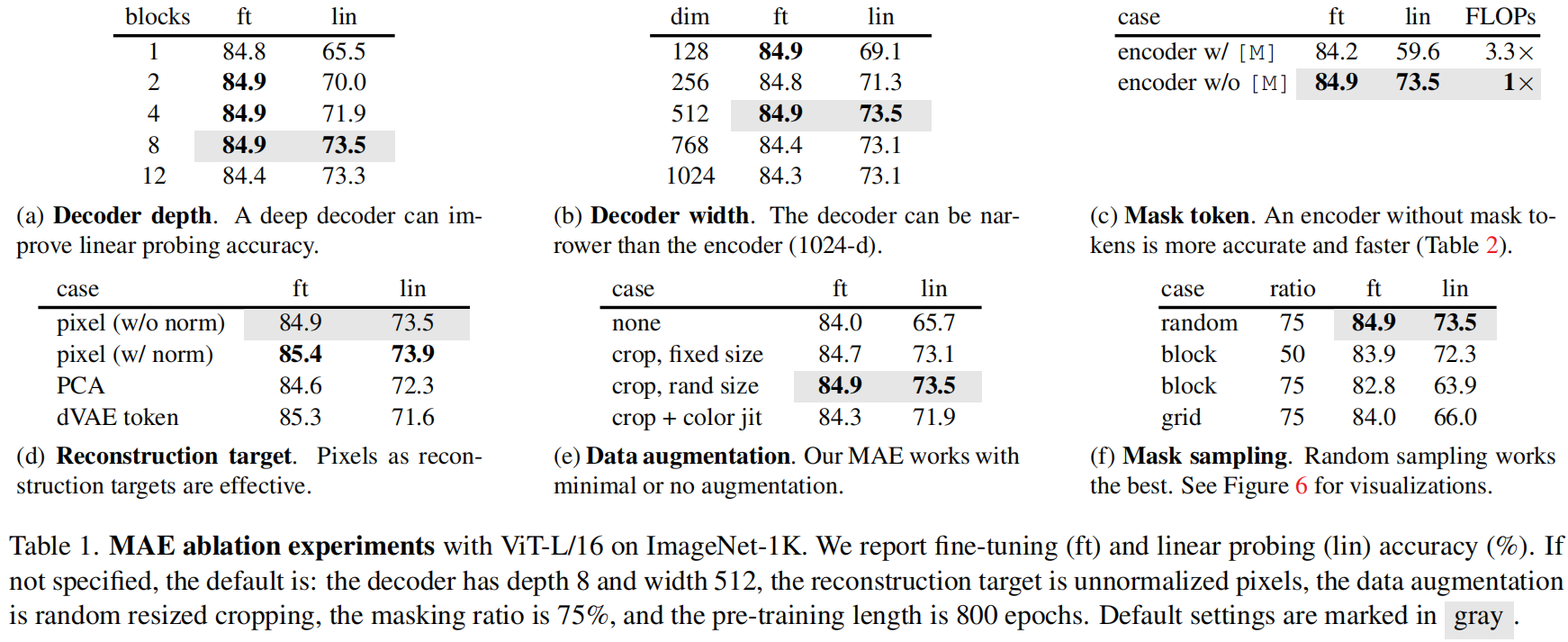
我们在表 1 中使用默认设置消融 (ablate) MAE (见说明文字),并观察到了几个有趣的特性。
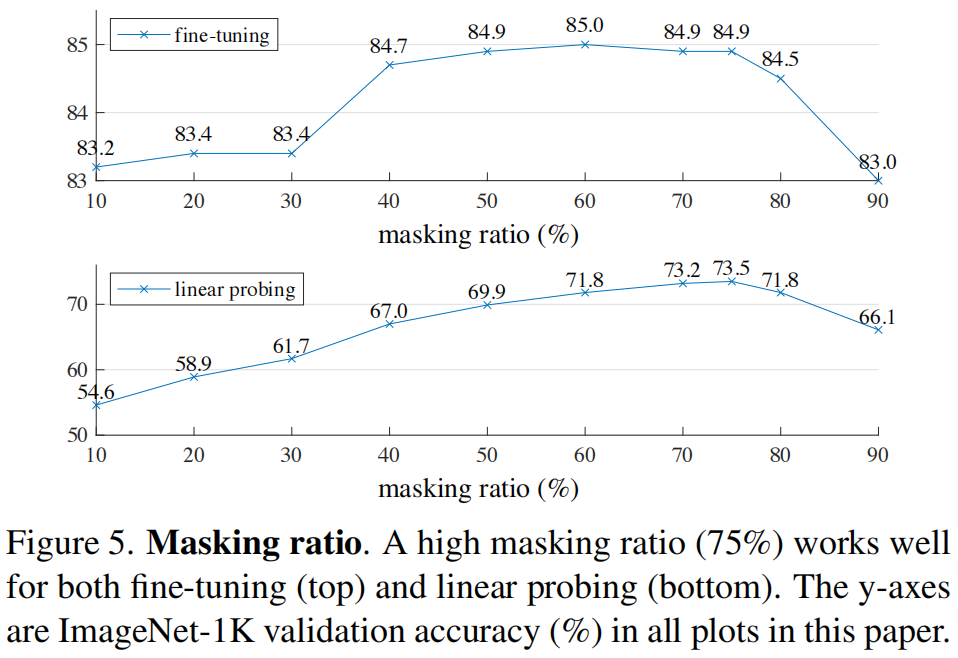
**Masking ratio**。图 5 显示了掩码率的影响。**75% 这么高的最佳掩码率同时有利于 linear probing 和 fine-tuning**。这种行为与典型掩码率为 15% 的 BERT。我们的 75% 掩码率也远高于 CV 中的相关工作 (20%-50%)。
模型推断出缺失的 patches 以产生不同的、但看似可信的输出 (图 4)。它使物体和场景的 gestalt 变得有意义,这不能简单地通过延伸线条或纹理来完成。我们假设这种类似推理 (reasoning-like) 的行为与学习有用的表示有关。
图 5 还显示出 linear probing 和微调结果遵循不同的趋势。对于 linear probing,准确率随着掩码率稳步增加,直到最佳点 (sweet point):准确率差距高达 ~20% (最低的 54.6% vs 最高的 73.5%)。对于微调,结果对掩码率的敏感度较低,而且掩码率在很大范围内 (40-80%) 模型都能工作得很好。图 5 中的所有微调结果都优于从头开始训练 (82.5%)。
**Decoder design**。可以灵活设计 MAE 解码器,如表 1a 和 1b 所示。表 1a 改变了 **解码器的深度 (Transformer blocks 数)**。**一个足够深的解码器对 linear probing 而言是很重要的**。这可以用像素重建任务和识别任务之间的差距来解释:**autoencoder 的最后几层更加专门 (specialized) 用于重建,但与识别的相关性较小**。一个合理的/适度的 (reasonably) 深度解码器 能解释 重建的专门化/特殊化 (specialization),将潜在的表示留在一个更抽象的层次上 (A reasonably deep decoder can account for the reconstruction specialization, leaving the latent representations at a more abstract level)。这种设计在 linear probing 方面可以实现高达 8% 的提高 (表 1a, “lin”)。然而,若用微调,则编码器的最后一层可以被调整以适应识别任务。**解码器深度对改进微调的影响较小** (表 1a, “ft”)。
有趣的是,具有单个 block 的解码器 的 MAE 可通过微调实现强大的性能 (84.8%)。注意,**单个 Transformer block 是将信息从可见 token 传播到 mask tokens 的最小要求**。这样一个小的解码器可以进一步加快训练速度。
在表 1b 中,我们研究了 **解码器的宽度 (通道数)**。默认使用的 **512-d **在微调和 linear probing 下均表现良好。一个较窄的解码器也可以很好地进行微调。
总之,默认的 MAE 解码器是轻量级的,有 **8 个 blocks,512-d 的宽度** (表 1 中的灰色),每个 token 只有 9% 的 FLOPs;而 ViT-L 则有24 个 blocks 和 1024-d 的宽度)。因此,虽然解码器处理所有的 tokens,但这仍是整个计算的一小部分。
**Mask token**。MAE 的一个重要设计是跳过编码器中的 mask token ![[M]](https://latex.codecogs.com/gif.latex?%5Cinline%20%5BM%5D),然后将其应用到轻量级解码器中。表 1c 研究了该设计。
**编码器如果使用 mask token 会表现更差**:在 linear probing 中,其精度下降了14%。在这种情况下,预训练和部署之间存在一个鸿沟:**这个编码器在预训练的输入中有大量的 mask token,然而 mask token 在未损坏的图像中是不存在的**。这种鸿沟可能会降低部署的准确率。通过从编码器中删除 mask token,**能够约束编码器始终看到真实存在的 patches,从而提高准确率**。
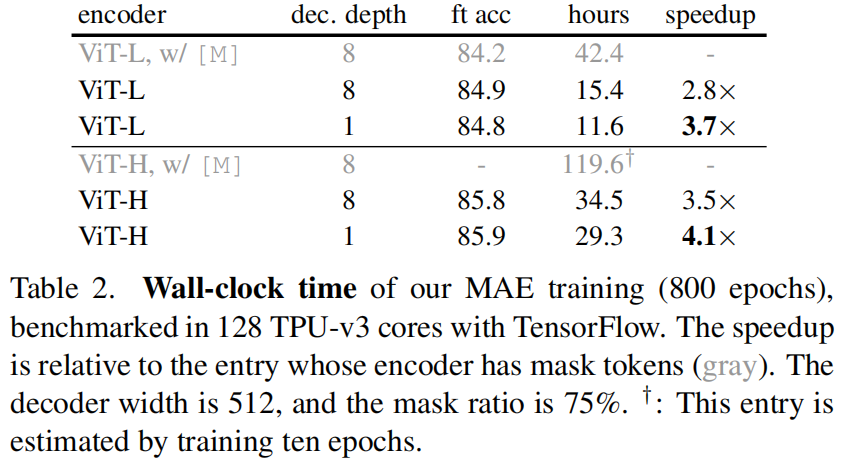
此外,通过跳过编码器中的 mask token,**可以大大减少训练计算量**。在表 1c 中,我们将总训练 FLOPs 减少了 3.3×。这导致了在我们的实现中一个 2.8× 的 wall-clock 加速 (见表 2)。对于 一个更小的解码器 (1-block),一个更大的编码器 (ViT-H),或二者都有时,wall-clock 加速甚至更大 (3.5-4.1×)。注意,对于 75% 的掩码率,加速可以 > 4×,部分原因是自注意力的复杂度是平方的。此外,内存的大大减少,使得我们可以训练更大的模型 或 通过大 batch 极大地加速训练。时间和内存的高效性使我们的 MAE 有利于训练非常大的模型。
**Reconstruction target**。表 1d 中比较了不同的重建目标。到目前为止,我们的结果是 **基于未经 (per-patch) 归一化的像素**。使用经归一化的像素可以提高准确率。这种**per-patch 归一化 增强了局部的对比度**。在另一种变体中,我们在 patch 空间中执行 PCA,并用最大的 PCA 系数 (此处为 96) 作为 target,但这样做会降低准确率。这两个实验都表明,**高频分量在我们的方法中是有用的**。
我们还比较了一种预测 tokens 的 MAE 变体,其 **target 使用于 BEiT**。特别是对于这种变体,我们遵循 BEiT 使用 DALLE 预训练的 dVAE 作为 tokenizer。此处,MAE 解码器使用交叉熵损失来 **预测 token indices**。这种 tokenization 与未经归一化的像素相比提高了 0.4% 的微调准确率,但与经归一化像素相比则没有优势。这种 tokenization 还降低了 linear probing 的准确率。在 §5 中,我们进一步证明了**tokenization 在迁移学习中不是必要的**。
我们的基于像素的 MAE 比 tokenization 要简单得多。**dVAE tokenizer **需要一个额外的预训练阶段,这可能依赖于额外的数据 (250M 图像)。dVAE 编码器是一个大型的卷积网络 (ViT-L 40% 的 FLOPs),并增加了大量的开销 (adds nontrivial overhead)。**使用像素则并未遇到这些问题**。
**Data augmentation**。表 1e 研究了数据扩增对 MAE 预训练的影响。
MAE 使用只裁剪 (cropping-only) 的扩增,无论是固定尺寸还是随机尺寸 (但都有随机水平翻转),效果都很好。添加 color-jittor 会降低结果,所以我们不在其他实验中使用它。
令人惊讶的是,**即使没用数据扩增 (只有中心裁剪 没有翻转),MAE 也表现得很好**。**这一特性与严重依赖于数据扩增的对比学习及相关方法显著不同**。据观察,对于 BYOL 和 SimCLR,使用只裁剪的扩增会分别降低 13% 和 28% 的准确率。此外,没有证据表明对比学习可以在无需扩增的情况下工作:一幅图像的两个视图 (view) 相同,且可以很容易地满足一个平凡的解 (trivial solution)。
在 MAE 中,数据扩增的作用主要通过随机 masking (ablated next) 来实现。每次迭代的 masks 都不同,所以无论如何数据扩增,它们都会生成新的训练样本。前置任务 (pretext) 因 masking 变得困难,且需要较少的扩增来正则化训练。

**Mask sampling strategy**。表 1f 比较了不同的 mask 采样策略,如图 6 所示。
BEiT 中提出的 **block-wise masking 策略倾向于删除大的 blocks** (图 6 中间)。我们的 block-wise masking MAE 在 50% 的比例下工作得相当有效,但在 75% 的比例下性能下降。这个任务比随机抽样更难,因为观察到了更高的训练损失。重建结果也更加模糊。
我们还研究了 grid-wise 采样,它规律地保留每 4 个 patches 中的 1 个 (图 6 右侧)。这是一项更容易完成的任务,且训练损失也更低。重建结果更加锐利。但是,表示的质量更低。
简单随机抽样最适合 MAE。它允许一个更高的掩码率,这提供了一个更大的加速收益,同时也享受良好的准确率。
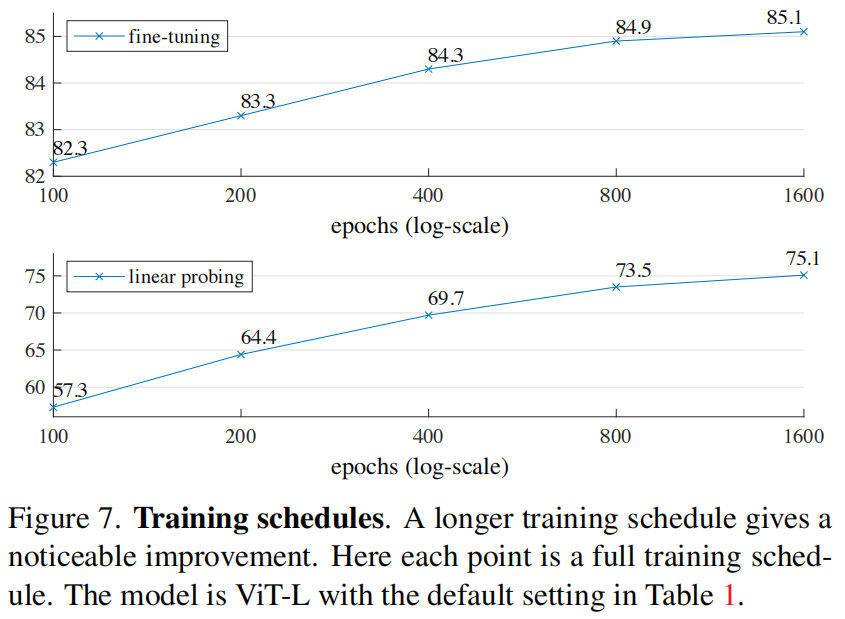
**Training schedule**。到目前为止,我们的消融是基于** 800**-epoch 的预训练。图 7 显示了训练计划长度的影响。随着更长时间的训练,准确率会稳步提高。事实上,即使在** 1600** 个 epoches 时也未能观察到 linear probing 准确率的饱和。这种行为有别于对比学习方法,例如,MoCo v3 在 ViT-L 的 **300** 个 epoches 时便达到饱和。注意,MAE 编码器在每个 epoch 只看到 **25% **的 patches;而在对比学习中,编码器每个 epoch 可以看到 **200% **(两次复制) 甚至更多 (多次裁剪) 的 patches。
4.2 与先前结果的对比
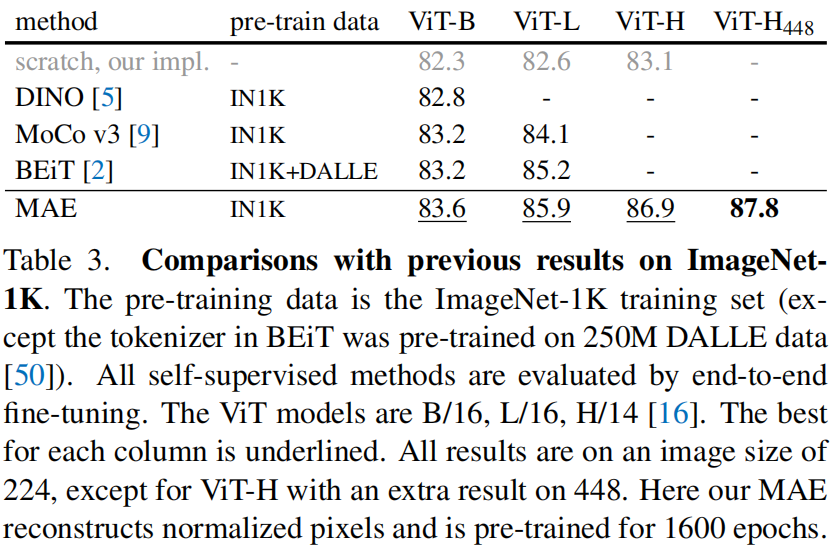
**Comparisons with self-supervised methods**。表 3 比较了自监督 ViT 模型的微调结果。对于 ViT-B,所有方法的性能都很接近。对于ViT-L,方法之间的差距则更大,这表明 **更大的模型面临的挑战是降低过拟合**。
MAE 可以很容易地扩大 (scale up),并从更大的模型中显示出稳步改善。我们用 ViT-H (尺寸** 224**) 获得了** 86.9%** 的准确率。仅用 IN1K 数据,通过用尺寸 **448** 微调实现了** 87.8%** 的准确率。在所有仅用 IN1K 数据的方法中,之前基于先进的网络的最佳准确率是 87.1% (尺寸** 512**)。在高度竞争激烈的 IN1K 基准测试 (没有外部数据) 中,我们以显著的优势 (by a nontrivial margin) 提高了 SOTA 水平。我们的研究结果 **基于普通的 (vanilla) ViT**,我们期望先进的网络会表现得更好。
与 BEiT 相比,MAE 更准确、更简单、更迅速。MAE 重建像素,与预测 tokens 的 BEiT 相比:BEiT 报告了在使用 ViT-B 重建像素时,退化了 1.8% (我们在使用 ViT-L 的 BEiT 中也观察到了退化:它产生了 85.2% (tokens) 和 83.5% (pixels),拷贝自官方代码)。我们无需 dVAE 预训练。此外,MAE 比 BEiT 要快得多 (3.5× 每 epoch),原因如表 1c 所示。
表 3 中的 MAE 模型预训练了 1600 个 epochs 以获取更好的准确率 (图 7)。即便如此,在相同的硬件上训练时,我们的预训练总时间比其他方法少。例如,在 128 个TPU-v3 内核上训练 ViT-L,MAE 训练 1600 epochs 用时 31 小时,而 MoCov3 训练 300 epochs 用时 36 小时。
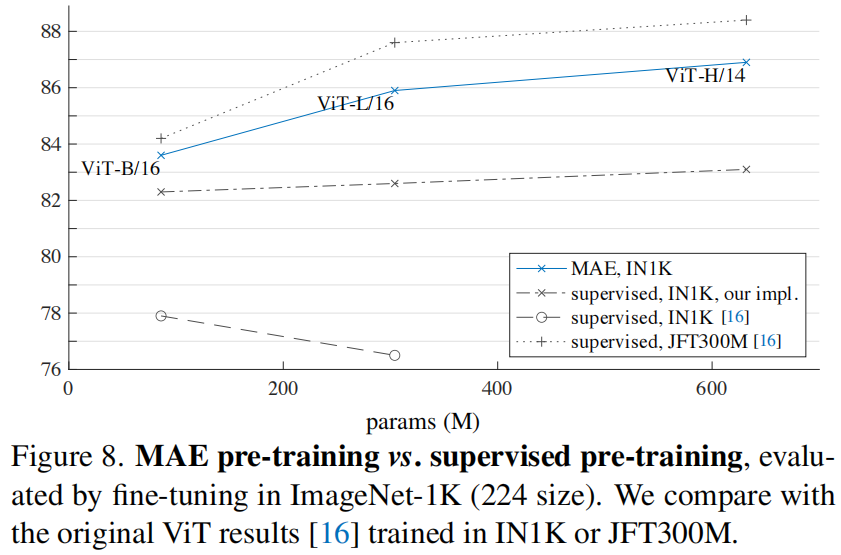
** Comparisons with supervised pre-training**。在最初的 ViT 论文中,ViT-L 在 IN1K 中训练时退化。我们实施的有监督训练 (见 A.2) 效果更好,但准确率达到饱和。见图 8。
** MAE 的预训练只用 IN1K,可以更好地泛化:对于更高容量的模型,从头开始训练的增益更大**。它遵循了类似于 ViT 原文中的 JFT-300M 监督预训练的趋势。这种比较表明,MAE 有助于扩大模型尺寸。
4.3 部分微调
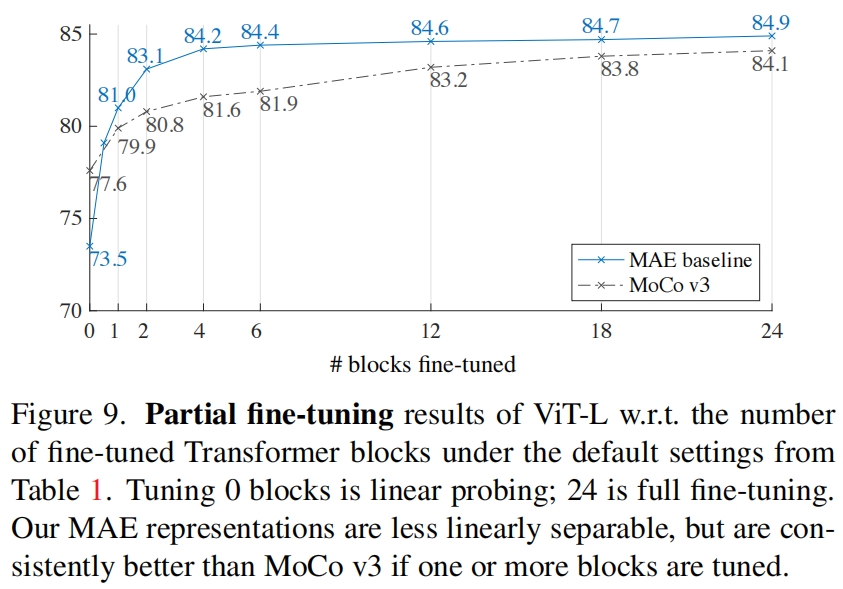
微调 0 个 blocks 即为 linear probing (只有最后的 FC 分类器可学习),24 个即为完全微调 (所有层都可以学习)
表 1 显示,linear probing 和微调的结果在很大程度上是不相关的 (largely uncorrelated)。在过去的几年中,linear probing 一直是一种流行的 protocol;然而,它错过了追求强大但非线性特征的机会 —— 这确实是深度学习的一种优势。作为中间立场 (as a middle ground),我们研究了一个 **部分微调 protocol:微调最后几层,同时冻结其他层**。这个 protocol 也被用于早期的工作中。
图 9 显示了结果。值得注意的是 (notably),仅微调一个 Transformer block 就可以将准确率从 73.5% 显著提高到 81.0%。此外,如果只微调最后一个 block (即它的 MLP sub-block),可以得到 79.1%,比 linear probing 好得多。这个变体本质上是对 MLP 头进行微调。**微调几个 blocks (例如 4 或 6 个) 可以实现接近完全微调的准确率**。
图 9 中还与 MoCo v3 比较,这是一种与 ViT-L 结果相结合的对比方法。MoCo v3 的 linear probing 准确率较高,但它所有部分微调结果都不如 MAE。当调优 4 个块时,差距为 2.6%。虽然 MAE 表示的线性可分离性较少,但它们具有更强的非线性特征,且当非线性头部被调优时表现良好。
这些观察结果表明,**线性可分性 (linear separability) 并不是评价表示质量的唯一指标**。人们还观察到,linear probing 与迁移学习性能并没有很好的相关性,例如,对于目标检测。据我们所知,**线性评价在 NLP 中并不经常用于预训练的基准测试**。
五、迁移学习实验
我们使用表 3 中的预训练模型来评估下游任务中的迁移学习。
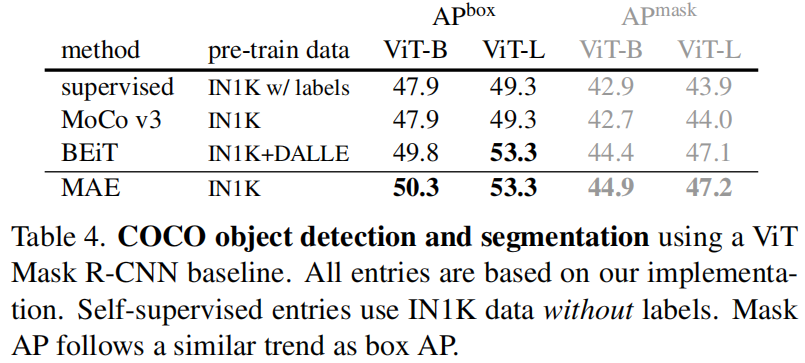
**Object detection and segmentation**。我们在 COCO 上对 Mask R-CNN 进行端到端微调。ViT 主干适和与 FPN 共用 (见 A.3)。我们对表4 中的所有条目都应用了这种方法。我们报告了用于目标检测的 box AP 和用于实例分割的 mask AP。
与有监督的预训练相比,MAE 在所有配置下都表现得更好 (表 4)。对于较小的 ViT-B,MAE 比有监督的预训练高 2.4 个点 (50.3 vs. 47.9, APbox)。更重要的是,对于较大的 ViT-L,MAE 预训练比有监督的预训练高 4.0 个点 (53.3 vs. 49.3)。基于 pixel 的 MAE 比基于 token 的 BEiT 更好或相当,而 MAE 更简单、更快。**MAE 和 BEiT 都优于 MoCov3,MoCov3 与有监督的预训练相当**。
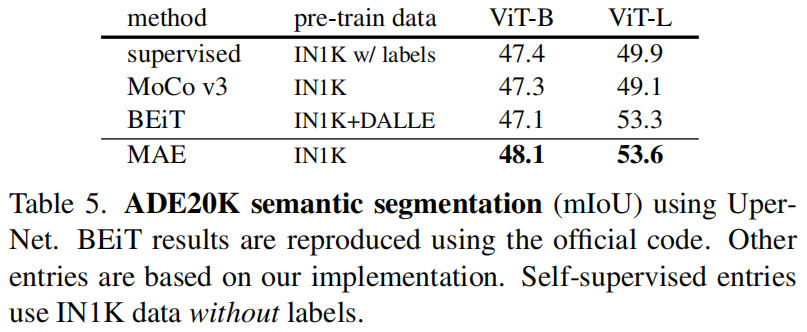
** Semantic segmentation**。我们用 UperNet 在 ADE20K 进行实验 (见 A.4)。表 5 显示,我们的预训练 比 有监督预训练 显著提高了结果,例如,ViT-L 提高了 3.7 个点。基于 pixel 的 MAE 也优于基于 token 的 BEiT。这些观察结果与在 COCO 上的一致。
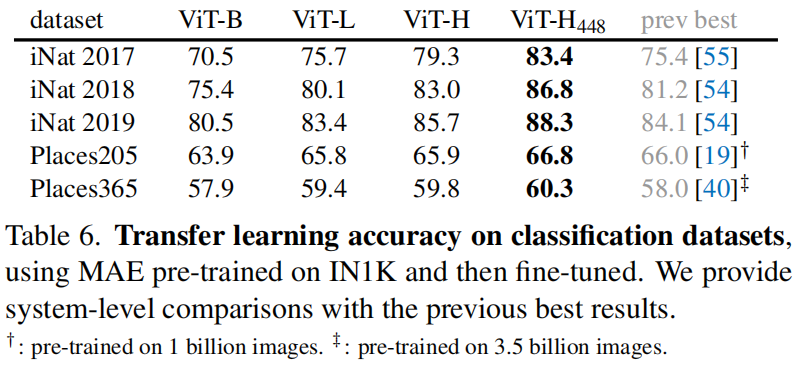
**Classification tasks**。表 6 研究了在 iNaturalists 和 Places 任务上的迁移学习 (见 A.5)。在 iNat 上,我们的方法显示出很强的扩展行为:准确率随着模型增大显著提高。我们的结果远超 (by large margins) 之前的最佳结果。在 Places 上,MAE 优于之前的对数十亿张图像预训练获得的最佳结果。
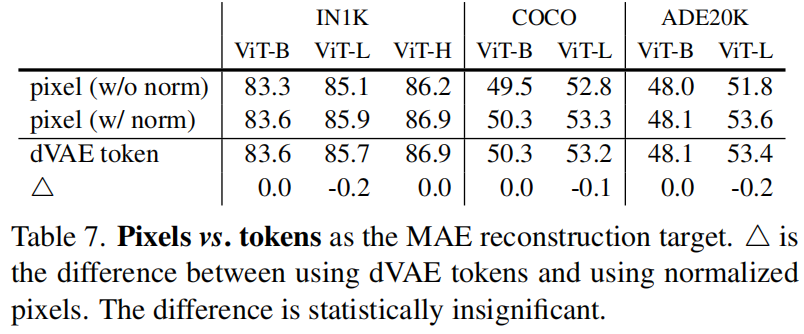
**Pixels vs. tokens**。表 7 比较了 pixel 与 token 作为 MAE 重建目标。虽然使用 dVAE token 比使用未经归一化的像素更好,但它在统计上与 在我们测试的所有案例中 使用的经归一化像素相似。这再次表明,**tokenization 对 MAE 并不是必要的**。
六、讨论与结论
**具有良好扩展性 (scale well) 的简单算法是深度学习的核心**。在 NLP 中,简单的自监督学习方法可以从指数级扩展 (exponentially scaling) 的模型中获益。在 CV 中,尽管在自监督学习方面取得了进展,但实际的预训练范式仍主要是有监督的。在这项研究中,我们在 ImageNet 和迁移学习中观察到,一个 autoencoder —— 一种类似于 NLP 技术的简单的自监督方法 —— 提供了可扩展/放缩 (scalable) 的好处。**视觉中的自监督学习现在可能开始了 (be embarking on) 与 NLP 类似的轨迹**。
另一方面,我们注意到图像和语言是不同性质的信号,必须仔细处理这种差异。图像只是记录到的光,它没有语义分解成单词的视觉模拟。我们没有试图删除目标物体,而是删除了那些很可能不会形成语义分片 (segment) 的随机 patches。同样地,我们的 MAE 重建了像素,它们不是语义实体 (semantic entities)。然而,我们观察到 (如图 4),我们的 MAE 推断出了复杂的、整体的重建,**表明它已经学习了许多视觉概念,即语义 (semantics)**。我们 **假设这种行为是基于 在 MAE 内部的丰富的隐藏表示 而发生的**。我们希望这一观点能启发未来的工作。
**Broader impacts**。所提出的方法 基于训练数据集的已学习到统计信息 (statistic) 来预测内容,因此将反映这些数据中的偏差/偏置 (bias),包括那些具有负面社会影响的数据。该模型可能会生成不存在的内容。当在这基础上生成图像时,这些问题值得进一步研究 (warrant further research) 和考虑。
七、核心代码
# https://github.com/facebookresearch/mae/blob/main/models_mae.py
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
# --------------------------------------------------------
# References:
# timm: https://github.com/rwightman/pytorch-image-models/tree/master/timm
# DeiT: https://github.com/facebookresearch/deit
# --------------------------------------------------------
from functools import partial
import torch
import torch.nn as nn
from timm.models.vision_transformer import PatchEmbed, Block
from util.pos_embed import get_2d_sincos_pos_embed
class MaskedAutoencoderViT(nn.Module):
""" Masked Autoencoder with VisionTransformer backbone
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, decoder_embed_dim), requires_grad=False) # fixed sin-cos embedding
self.decoder_blocks = nn.ModuleList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True) # decoder to patch
# --------------------------------------------------------------------------
self.norm_pix_loss = norm_pix_loss
self.initialize_weights()
def initialize_weights(self):
# initialization
# initialize (and freeze) pos_embed by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
decoder_pos_embed = get_2d_sincos_pos_embed(self.decoder_pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.decoder_pos_embed.data.copy_(torch.from_numpy(decoder_pos_embed).float().unsqueeze(0))
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
w = self.patch_embed.proj.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
torch.nn.init.normal_(self.cls_token, std=.02)
torch.nn.init.normal_(self.mask_token, std=.02)
# initialize nn.Linear and nn.LayerNorm
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
torch.nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def patchify(self, imgs):
"""
imgs: (N, 3, H, W)
x: (N, L, patch_size**2 *3)
"""
p = self.patch_embed.patch_size[0]
assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
h = w = imgs.shape[2] // p
x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
x = torch.einsum('nchpwq->nhwpqc', x)
x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
return x
def unpatchify(self, x):
"""
x: (N, L, patch_size**2 *3)
imgs: (N, 3, H, W)
"""
p = self.patch_embed.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, 3))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], 3, h * p, h * p))
return imgs
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio)
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)
return loss, pred, mask
def mae_vit_base_patch16_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=16, embed_dim=768, depth=12, num_heads=12,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
def mae_vit_large_patch16_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=16, embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
def mae_vit_huge_patch14_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=14, embed_dim=1280, depth=32, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
# set recommended archs
mae_vit_base_patch16 = mae_vit_base_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_large_patch16 = mae_vit_large_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_huge_patch14 = mae_vit_huge_patch14_dec512d8b # decoder: 512 dim, 8 blocks
本文转载自: https://blog.csdn.net/qq_39478403/article/details/128046715
版权归原作者 何处闻韶 所有, 如有侵权,请联系我们删除。
版权归原作者 何处闻韶 所有, 如有侵权,请联系我们删除。