
引言
ChatGPT4相比于ChatGPT3.5,有着诸多不可比拟的优势,比如图片生成、图片内容解析、GPTS开发、更智能的语言理解能力等,但是在国内使用GPT4存在网络及充值障碍等问题,**如果您对ChatGPT4.0感兴趣,可以私信博主为您解决账号和环境问题。同时,如果您有一些AI技术应用的需要,也欢迎私信博主,我们聊一聊思路和解决方案**
什么是RAG
RAG(Retrieval Augmented Generation)检索增强生成,顾名思义,通过**检索**的方法来增强**生成模型**的能力。RAG可以理解为是Function Calling 的一种水平补充。如果大模型需要调外部API才能完成任务,那就使用Function Calling。如果大模型需要检索知识库才能完成回答,那就使用 RAG。
Embedding
Embedding 向量文本,是一种将高维复杂数据转换为低维向量表示的技术,解决了数据处理和语义捕捉的问题。比如,我们根据一句话找出与这句话语义相近的一段话,就用用到将这两段文字转为 Embedding ,存储在向量数据库中。
检索方式
文本检索
文本检索即我们传统的文档数据库检索,比如 es 。这种检索的特点是只能完全字面匹配,同一个语义换个说法可以就无法检索到。
向量检索
根据语句的相似度检索。语义相似的文本,他们的向量相关度会比高。这个特性依赖于向量模型的向量算法。
向量间的相似度计算

向量模型的训练:
- 构建相关(正立)与不相关(负例)的句子对儿样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大

举例:使用OpenAI的 Embedding 模型接口:text-embedding-ada-002 来计算两个文档的相关度。
OpenAI的 text-embedding-ada-002 是24年初为止,最好的文本向量模型,它甚至可以计算一个英文文本和中文文本的相关性。后来 OpenAI 已经发布新的更优秀的模型了。
from openai import OpenAI
import numpy as np
from numpy import dot
from numpy.linalg import norm
client = OpenAI()
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
def get_embeddings(texts, model="text-embedding-ada-002", dimensions=None):
'''封装 OpenAI 的 Embedding 模型接口'''
if model == "text-embedding-ada-002":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
test_query = ["测试文本"]
vec = get_embeddings(test_query)[0]
print(f"Total dimension: {len(vec)}")
print(f"First 10 elements: {vec[:10]}")
# query = "国际争端"
# 且能支持跨语言
query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
print("Query与自己的余弦距离: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print()
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))
Query与自己的余弦距离: 1.00
Query与Documents的余弦距离:
0.7622376995981269
0.7564484035029618
0.7426558372998221
0.7077987135264395
0.7254230492369407
Query与自己的欧氏距离: 0.00
Query与Documents的欧氏距离:
0.6895829747071625
0.697927847429074
0.7174178392255148
0.7644623330084925
0.7410492267209755
向量数据库
向量数据库,是专门为向量检索设计的中间件。向量数据库解决的是数据存储和快速检索的功能,向量模型是解决数据相似度计算的问题。
澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
主流向量数据库功能对比
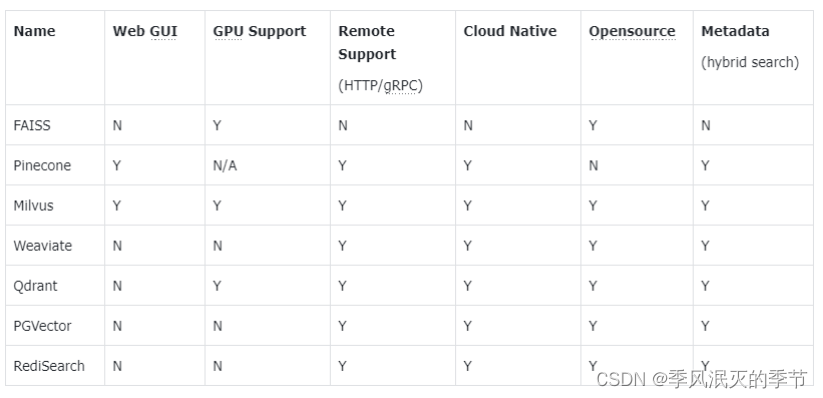
FAISS: Meta 开源的向量检索引擎 https://github.com/facebookresearch/faiss
Pinecone: 商用向量数据库,服务器在国外,使用非常简单。只有云服务 https://www.pinecone.io/
Milvus: 开源向量数据库,同时有云服务 https://milvus.io/
Weaviate: 开源向量数据库,同时有云服务 https://weaviate.io/
Qdrant: 开源向量数据库,同时有云服务 https://qdrant.tech/
PGVector: Postgres 的开源向量检索引擎 https://github.com/pgvector/pgvector
RediSearch: Redis 的开源向量检索引擎 https://github.com/RediSearch/RediSearch
ElasticSearch 也支持向量检索 https://www.elastic.co/enterprise-search/vector-search
上述前四个相对来说是市面上主流的向量数据库。其中,FAISS 是 脸书 早期出的一个引擎,它的上层应用封装不是很完善,所以不推荐使用。Pinecone、Milvus、Weaviate是近两年火起来的创业公司发布的,后两个都是开源的。Pinecone使用非常方便,但是它不开源,且云服务器在国外。Milvus性能上有很大的优势,推荐使用。
基于向量检索的 RAG
class RAG_Bot:
def __init__(self, vector_db, llm_api, n_results=2):
self.vector_db = vector_db
self.llm_api = llm_api
self.n_results = n_results
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query, self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(
prompt_template, context=search_results['documents'][0], query=user_query)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
# 创建一个RAG机器人
bot = RAG_Bot(
vector_db,
llm_api=get_completion
)
user_query = "llama 2有多少参数?"
response = bot.chat(user_query)
print(response)
llama 2有7B, 13B, 和70B参数。
更换国产模型¶
import json
import requests
import os
# 通过鉴权接口获取 access token
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": os.getenv('ERNIE_CLIENT_ID'),
"client_secret": os.getenv('ERNIE_CLIENT_SECRET')
}
return str(requests.post(url, params=params).json().get("access_token"))
# 调用文心千帆 调用 BGE Embedding 接口
def get_embeddings_bge(prompts):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/embeddings/bge_large_en?access_token=" + get_access_token()
payload = json.dumps({
"input": prompts
})
headers = {'Content-Type': 'application/json'}
response = requests.request(
"POST", url, headers=headers, data=payload).json()
data = response["data"]
return [x["embedding"] for x in data]
# 调用文心4.0对话接口
def get_completion_ernie(prompt):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions_pro?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": prompt
}
]
})
headers = {'Content-Type': 'application/json'}
response = requests.request(
"POST", url, headers=headers, data=payload).json()
return response["result"]
# 创建一个向量数据库对象
new_vector_db = MyVectorDBConnector(
"demo_ernie",
embedding_fn=get_embeddings_bge
)
# 向向量数据库中添加文档
new_vector_db.add_documents(paragraphs)
# 创建一个RAG机器人
new_bot = RAG_Bot(
new_vector_db,
llm_api=get_completion_ernie
)
user_query = "how many parameters does llama 2 have?"
response = new_bot.chat(user_query)
print(response)
Llama 2的变体有7B、13B和70B三种参数。同时,还训练了34B的变体,但在本文中报告并未发布。所以,Llama 2的参数有7B、13B和70B三种可选择的变体。
OpenAI 新发布的两个 Embedding 模型
2024 年 1 月 25 日,OpenAI 新发布了两个 Embedding 模型
text-embedding-3-large
text-embedding-3-small
其最大特点是,支持自定义的缩短向量维度,从而在几乎不影响最终效果的情况下降低向量检索与相似度计算的复杂度。text-embedding-ada-002 只支持1536维计算。
通俗的说:越大越准、越小越快。 官方公布的评测结果:

注:MTEB 是一个大规模多任务的 Embedding 模型公开评测集
model = "text-embedding-3-large"
dimensions = 128
# query = "国际争端"
# 且能支持跨语言
query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = get_embeddings([query], model=model, dimensions=dimensions)[0]
doc_vecs = get_embeddings(documents, model=model, dimensions=dimensions)
print("向量维度: {}".format(len(query_vec)))
print()
print("Query与Documents的余弦距离:")
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
print()
print("Query与Documents的欧氏距离:")
for vec in doc_vecs:
print(l2(query_vec, vec))
这种可变长度的 Embedding 技术背后的原理叫做 Matryoshka Representation Learning
实战 RAG 系统的进阶知识
文本分割的粒度
缺陷
- 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
- 问题的答案可能跨越两个片段
改进: 按一定粒度,部分重叠式的切割文本,使上下文更完整
检索后排序
问题: 有时,最合适的答案不一定排在检索的最前面
方案:
- 检索时多招回一部分文本
- 通过一个排序模型对 query 和 document 重新打分排序
混合检索(Hybrid Search)
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣。
举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆。
RAG-Fusion
将一个问题换几个角度提问,然后取各次返回结果都比较靠前的。
向量模型的本地加载与运行
rom sentence_transformers import SentenceTransformer
model_name = 'BAAI/bge-large-zh-v1.5' #中文
# model_name = 'moka-ai/m3e-base' # 中英双语,但效果一般
# model_name = 'BAAI/bge-m3' # 多语言,但效果一般
model = SentenceTransformer(model_name)
query = "国际争端"
# query = "global conflicts"
documents = [
"联合国就苏丹达尔富尔地区大规模暴力事件发出警告",
"土耳其、芬兰、瑞典与北约代表将继续就瑞典“入约”问题进行谈判",
"日本岐阜市陆上自卫队射击场内发生枪击事件 3人受伤",
"国家游泳中心(水立方):恢复游泳、嬉水乐园等水上项目运营",
"我国首次在空间站开展舱外辐射生物学暴露实验",
]
query_vec = model.encode(query)
doc_vecs = [
model.encode(doc) for doc in documents
]
print("Cosine distance:") # 越大越相似
# print(cos_sim(query_vec, query_vec))
for vec in doc_vecs:
print(cos_sim(query_vec, vec))
重点:
- 不是每个 Embedding 模型都对余弦距离和欧氏距离同时有效
- 哪种相似度计算有效要阅读模型的说明(通常都支持余弦距离计算)
RAG 实践步骤及技巧总结
1. 文档拆分
文档拆分是否完整直接决定了RAG的效果。在实战中,推荐以下几种文档拆分方式:
按段落拆分:在准备文本时尽量的要保证相关性较强的内容 放到 同一个段落。高度保证根据一个段落的内容能回答我们的一个问题,这样检索出来的内容准确性比较高。
按格式拆分: 比如将内容转换为 markdown格式,然后根据markdown的格式来拆分内容。
段落与语义相结合: 先将文本按段落拆分,再将段落用 向量模型计算相关性,相关性高的拼在一起。
用大模型进行拆分:利用大模型将文本拆分成若干个相关度不高的小文本。这种方案比较依赖大模型的理解能力,有一定的成本。
2. 向量模型选择
在中国大陆企业内部做RAG时,推荐使用谷歌的bert模型,尤其是Huggingface的Chinese-bert 模型。
3. 向量的检索
向量数据库推荐使用Milvus,性能上有很大的优势。在数据召回时,我们要结合实际测试的情况考虑是否要将排名靠前的多个结果一并发给大模型、是否要调整排序、是否要使用文本检索。
RAG 效果差排查步骤
- 检查预处理效果:文档加载是否正确,切割的是否合理
- 测试检索效果:问题检索回来的文本片段是否包含答案
- 测试大模型能力:给定问题和包含答案文本片段的前提下,大模型能不能正确回答问题
版权归原作者 季风泯灭的季节 所有, 如有侵权,请联系我们删除。