
前言
本次分享将带领大家从0到1完成一个语义分割任务,覆盖数据准备、模型训练评估和推理部署的全流程,项目将采用以PaddleSeg为核心的飞浆深度学习框架进行开发,并总结开发过程中踩过的一些坑,希望能为有类似项目需求的同学提供一点帮助。
项目背景和目标
背景:
- 语义分割是计算机视觉的一个基础任务。本次选用的案例来自现实生活场景,通过人像分割,实现背景替换。项目最后,将实现一个AI证件照的应用,并将应用部署到 AI Studio 平台,由于场景对实时性有更高要求,本次采用百度自研的 PP-LiteSeg 进行模型训练和部署。
目标:
- 基于paddlepaddle深度学习框架完成一个语义分割任务;
- 完成模型的训练、评估、预测和部署等深度学习任务全过程。
百度AI Studio平台
本次实验将采用AI Studio实训平台中的免费GPU资源,在平台注册账号后,点击创建项目-选择NoteBook任务,然后添加数据集,如下图所示,完成项目创建。启动环境可以自行选择CPU资源 or GPU资源,创建任务每天有8点免费算力,推荐大家使用GPU资源进行模型训练,这样会大幅减少模型训练时长。

飞浆深度学习开发框架介绍
PaddlePaddle百度提供的开源深度学习框架,其中文名是“飞桨”,致力于为开发者和企业提供最好的深度学习研发体验,国产框架中绝对的榜一大哥!其核心优势是生态完善,目前集成了各种开发套件,覆盖了数据处理、模型训练、模型验证、模型部署等各个阶段的工具。下面简要介绍一下本项目用到的几个核心组件:
- PaddleSeg:一个语义分割任务的工具集,集成了丰富的主流分割算法和百度自研的最新模型,提供覆盖分割任务全流程的API。
- PaddleServing:将模型部署成一个在线预测服务的库,支持服务端和客户端之间的高并发和高效通信。
- PaddleLite:将模型转换成可以端侧推理的库,比如将模型部署到手机端进行推理。
- Fastdeploy:一款全场景、易用灵活、极致高效的AI推理部署工具,支持云边端等各种部署方式。
从零开始实战
1 PaddleSeg完成模型训练
1.1 安装PaddleSeg
在项目中打开终端,然后运行如下命令:
# (可选)conda安装虚拟环境,环境会持久保存在项目中
conda create -p envs/py38 python=3.8
source activate envs/py38
# 安装paddlepaddle,根据云端环境选择cpu版本和gpu版本
pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install --upgrade paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 下载PaddleSeg代码 注意要安装2.9版本,gitee上是2.8
# 如果国内下载太慢,加上镜像https://mirror.ghproxy.com/
git clone https://github.com/PaddlePaddle/PaddleSeg.git
# 安装
cd PaddleSeg
pip install -r requirements.txt
pip install -v -e .
# 测试是否安装成功
sh tests/install/check_predict.sh
1.2 数据准备
数据集介绍
本次实验使用的数据集来自开源的人像语义分割数据集,数据集总共有 7082 张图片,手动划分为训练集、验证集和测试集,其中训练集 5666 张,验证集 1416 张。只包含两种标签类型:背景和人物。大家也可以选择其他开源的人像语义分割数据集。
我们需要制作符合PaddleSeg框架要求的数据集格式:参考准备自定义数据集。
step1: 解压数据集
# 打开终端
cd ~/data/
# -d 指定解压缩的路径,会在data0文件夹下生成koto数据集,持久保存在云端环境种
unzip data59640/koto.zip -d ../data0
step2: 制作标签文件
python generate_dataset.py
# 其中generate_dataset.py中的代码如下:
'''
import os
import cv2
import numpy as np
from tqdm import tqdm
# modify the data txt file
dataset_dir = '/home/aistudio/data0/koto'
for txt in ['train_list.txt', 'valid_list.txt']:
output = []
with open(dataset_dir + '/' + txt, 'r') as f:
lines = f.readlines()
for line in lines:
image, label = line.strip().split(' ')
image = image.replace('/mnt/d/data/koto/', '')
label = label.replace('/mnt/d/data/koto/', '')
output.append(image + ' ' + label)
with open(dataset_dir + '/new_' + txt, 'w') as f:
f.writelines(f'{line}'+'\n' for line in output)
# 将Label图像转换为标签,0:背景,1:人像
anno_dir = '/home/aistudio/data0/koto/annos'
annos = os.listdir(anno_dir)
for anno in tqdm(annos):
anno_file = os.path.join(anno_dir, anno)
label = cv2.imread(anno_file, 0)
new_label = np.zeros(label.shape, dtype=np.uint8)
if label[0, 0] < 10: # 背景黑色,人像白色
new_label[label > 128] = 1
else:
new_label[label <= 128] = 1
cv2.imwrite(anno_file, new_label)
'''
# 如果希望将灰度标注图转换为伪彩色标注图,可以执行以下命令。
cd PaddleSeg
python tools/data/gray2pseudo_color.py /home/aistudio/data0/koto/annos /home/aistudio/data0/koto/annos_color
如上,我们便完成了数据的准备工作,接下来将完成模型在该数据集上的训练。
1.3 模型训练:
这里我们以选用PaddleSeg自带的pp_liteseg为例,有关该模型的介绍可参考官方文档。
- 准备训练配置文件-以pp_liteseg为例:
cp configs/quick_start/pp_liteseg_optic_disc_512x512_1k.yml configs/quick_start/pp_liteseg_person_seg.yml
# 修改其中对应的数据集信息
'''
train_dataset:
type: Dataset
dataset_root: /home/aistudio/data0/koto/
train_path: /home/aistudio/data0/koto/new_train_list.txt
val_dataset:
type: Dataset
dataset_root: /home/aistudio/data0/koto/
val_path: /home/aistudio/data0/koto/new_valid_list.txt
'''
- 开启训练
python tools/train.py --config configs/quick_start/pp_liteseg_person_seg.yml --do_eval --use_vdl --save_interval 500 --save_dir output/liteseg
- 如果选用 UNet 模型
# 重新准备训练配置文件
cp configs/unet/unet_chasedb1_128x128_40k.yml configs/unet/unet_person_seg.yml
# 修改其中对应的数据集信息,如下
'''
batch_size: 16
iters: 10000
train_dataset:
type: Dataset
dataset_root: /home/aistudio/data0/koto/
train_path: /home/aistudio/data0/koto/new_train_list.txt
num_classes: 2
mode: train
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop
crop_size: [512, 512]
- type: RandomHorizontalFlip
- type: RandomDistort
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize
val_dataset:
type: Dataset
dataset_root: /home/aistudio/data0/koto/
val_path: /home/aistudio/data0/koto/new_valid_list.txt
num_classes: 2
mode: val
transforms:
- type: Normalize
optimizer:
type: SGD
momentum: 0.9
weight_decay: 4.0e-5
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0
power: 0.9
loss:
types:
- type: CrossEntropyLoss
coef: [1]
model:
type: UNet
num_classes: 2
use_deconv: False
pretrained: Null
'''
训练成功后,可以在终端查看训练过程,loss下降说明没问题:
大概20分钟左右就完成了1000次迭代,结果如下:
1.4 模型评估和测试
默认训练生成的模型保存在
output/liteseg
文件夹下:
# 在验证集上进行评估
python tools/val.py --config configs/quick_start/pp_liteseg_person_seg.yml --model_path output/liteseg/best_model/model.pdparams
找一张图像预测看看:
python tools/predict.py --config configs/quick_start/pp_liteseg_person_seg.yml --model_path output/liteseg/best_model/model.pdparams --image_path /home/aistudio/data0/koto/imgs/00002-323.jpg --save_dir output/
会在
output
文件夹下看到生成结果:

找张自己的头像照片试下呢?
1.5 模型导出
目的:将训练得到的最好模型转成部署需要的模型。
- 方式一:导出为
Paddle Inference模型
# (可选)可以指定固定输入图像大小 加上参数--input_shape 1 3 512 512
python tools/export.py --config configs/quick_start/pp_liteseg_person_seg.yml --model_path output/liteseg/best_model/model.pdparams --save_dir output/liteseg/inference_model
导出成功后,会在output/liteseg/inference_model文件夹下生成如下文件:
output/liteseg/inference_model
├── deploy.yaml # 部署相关的配置文件,主要说明数据预处理方式等信息
├── model.pdmodel # 预测模型的拓扑结构文件
├── model.pdiparams # 预测模型的权重文件
└── model.pdiparams.info # 参数额外信息,一般无需关注
# 其中model.pdmodel可以通过Netron打开进行模型可视化。
- 方式二:导出为
ONNX模型
# 安装 onnx
pip install paddle2onnx
# 然后执行如下命令
paddle2onnx --model_dir output/liteseg/inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 11 \
--save_file output/liteseg/inference_model/model.onnx
# 会出现报错:[ERROR][Paddle2ONNX] [pool2d: pool2d_4.tmp_0] Adaptive only support static input shape. 这是因为调用export.py时没有固定shape,所以重新执行export.py
python tools/export.py --config configs/quick_start/pp_liteseg_person_seg.yml \
--model_path output/liteseg/best_model/model.pdparams \
--save_dir output/liteseg/inference_model \
--input_shape 1 3 512 512
# 这时会在 deploy.yml 中看到固定的 input_shape ,再重新执行 paddle2onnx 就成功了
2 模型推理部署
模型训练完成并导出后,就可以将模型部署上线,为推理做好准备。通常情况下,导出模型有如下的部署场景,在 Paddle 框架下,对应需要使用的库如下:
部署场景使用的预测库服务器端(Nvidia GPU和X86 CPU) Python部署Paddle Inference服务器端(Nvidia GPU和X86 CPU) C++部署Paddle Inference移动端部署Paddle Lite服务化部署Paddle Servingweb端/前端部署Paddle JS
Paddle 框架下,对应的库及其使用场景如下图所示:
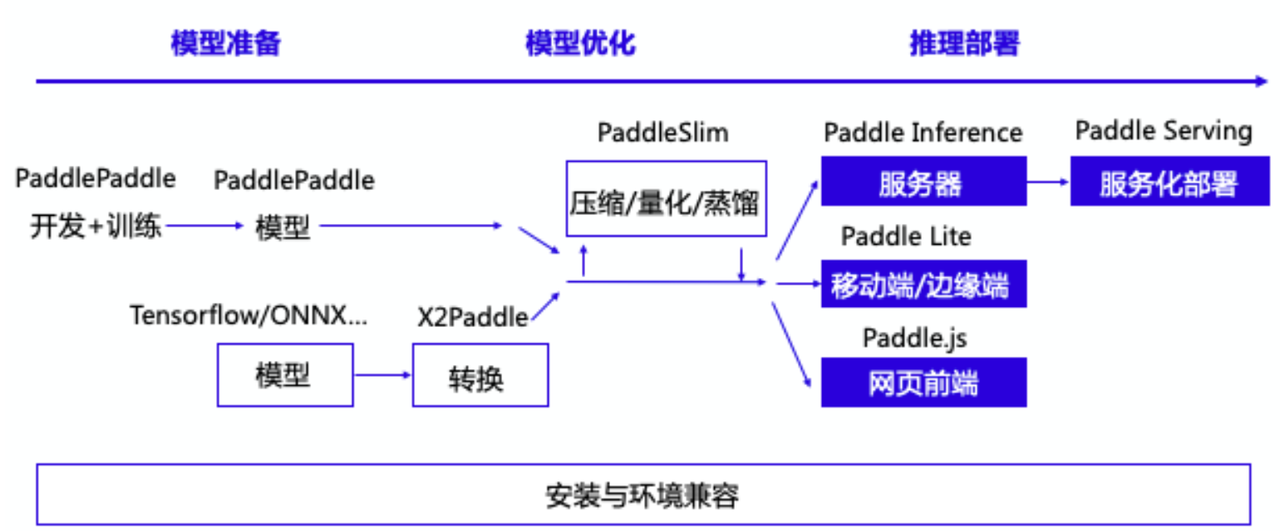
下面将对我们训练得到的模型,通过不同方式进行部署。
2.1 Paddle Inference部署(Python)
直接调用PaddleSeg中的推理接口:
python deploy/python/infer.py \
--config output/liteseg/inference_model/deploy.yaml \
--image_path /home/aistudio/data0/koto/imgs/00002-323.jpg
执行成功后会在 output 文件夹下生成同名的预测图片
2.2 PaddleServing服务端部署
这个部分的目的是将我们的模型部署成一个服务,客户端就可以通过http或rpc进行,飞浆已对上述需求所需要的功能实现进行了封装,需要调用PaddleServing库。
step 1: 安装PaddleServing包
注意:这里会出现版本依赖的问题,比如报错
No module named 'paddle.fluid'
,通常意味着需要较低的 paddlepaddle 版本,需要降低版本到 2.4 。所以需要重新建立一个 python 环境来安装PaddleServing包。
cd ~ # 回到根目录
conda create -p envs/py37 python=3.7
source activate envs/py37
pip install paddlepaddle==2.4
pip install paddle-serving-client
pip install paddle-serving-app
## 若为CPU部署环境:
pip install paddle-serving-server
## 若为GPU部署环境:
pip install paddle-serving-server-gpu
step 2: 导出PaddleServing格式的模型
cd output/liteseg/
python -m paddle_serving_client.convert \
--dirname inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams
成功后会在当前文件夹生成
serving_client
和
serving_server
两个文件夹,分别保存模型的服务端和客户端配置。
step 3: 启动服务
# 用cpu
python -m paddle_serving_server.serve --model serving_server --port 9393 --thread 10 --ir_optim
# 用gpu
python -m paddle_serving_server.serve --model serving_server --port 9393 --thread 10 --ir_optim --gpu_ids 0
注意,如果使用gpu,这里可能出现报错:
ImportError: libnvinfer.so.7: cannot open shared object file: No such file or directory。
- 原因分析:这是因为没有安装tensorrt。
- 怎么解决:可参考这篇博文:报错解决ImportError: libnvinfer.so.7
服务端启动成功后,会出现如下信息:
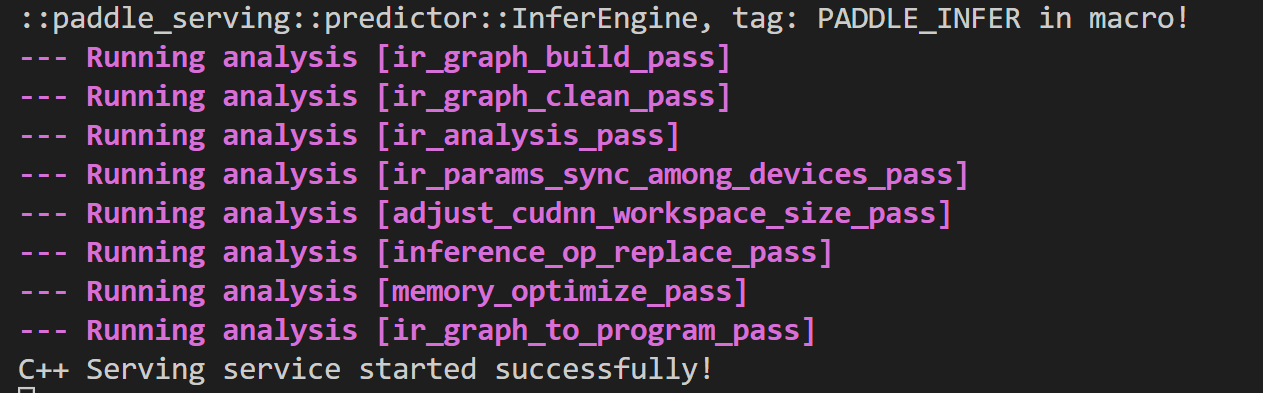
step4: 测试服务-客户端调用
# 重起一个终端
cd PaddleSeg
python deploy/serving/test_serving.py \
--serving_client_path output/liteseg/serving_client \
--serving_ip_port 127.0.0.1:9393 \
--image_path /home/aistudio/data0/koto/imgs/00002-323.jpg
注意,这里可能出现报错:
ImportError: libcrypto.so.10: cannot open shared object file: No such file or directory ImportError: libssl.so.10: cannot open shared object file: No such file or directory,
- 原因分析:这是因为ssl版本的问题
- 怎么解决:可参考这篇博文:报错解决ImportError: libcrypto.so.10
还可能出现报错:
KeyError: 'save_infer_model/scale_0.tmp_1'
- 原因分析:
serving_client/serving_client_conf.prototxt中的 fetch_var 对应的 name: “save_infer_model/scale_0.tmp_0”- 怎么解决:
deploy/serving/test_serving.py第42和44行的"save_infer_model/scale_0.tmp_1"都要改为"save_infer_model/scale_0.tmp_0"
再重新测试,客户端调用成功后:会在当前目录下生成
result.png
, 也即预测结果。
2.3 PaddleLite移动端部署
这个部分的目的是将我们的模型部署到移动端(比如手机),这样就不用依赖云端服务器来进行推理了,飞浆已对上述需求所需要的功能实现进行了封装,主要体现在PaddleLite这个组件上。
端侧部署相对稍微复杂一些,主要可以分为以下几个步骤进行:
2.3.1 模型优化
考虑到端侧对推理耗时要求比较高,故需要采用paddlelite对inference模型做进一步优化,并转换成Paddle-Lite支持的文件格式,也即以.nb名称结尾的单个文件。
pip install paddlelite
# 生成lite模型-FP16,执行如下命令,最终在output/liteseg/lite/下生成 model.nb
mkdir output/liteseg/lite
paddle_lite_opt --valid_targets=arm --model_file=output/liteseg/inference_model/model.pdmodel --param_file=output/liteseg/inference_model/model.pdiparams --optimize_out=output/liteseg/lite/model --enable_fp16=true
2.3.2 本地电脑和手机准备
第一步:windows 安装 Android Studio
- 谷歌的安卓平台下载 Android Studio 进行安装:官网
第二步:手机连接电脑(华为Mate30手机为例)
- 开启开发者模式:设置-关于手机-点击“版本号”多次直到提示“您已进入开发者模式”
- 打开USB调试:设置-系统与更新-开发人员选项-USB调试-选择USB配置(多媒体传输)
2.3.3 APP 快速体验
# 本地 windows 电脑下载 PaddleSeg 仓库代码
git clone https://github.com/PaddlePaddle/PaddleSeg.git
打开Android Studio,点击File -> New -> New Project,在弹出的路径选择窗口中进入"PaddleSeg/deploy/lite/humanseg_android_demo/"目录,然后点击右下角的"Open"按钮即可导入工程。

注意,这里可能出现报错:
Unable to make field private final java.lang.String java.io.File.path accessible: module,
- 原因分析:项目各种依赖的问题
- 怎么解决:可参考这篇博文逐一尝试:Gradle问题解决
手机连接成功后,点击 app 右侧的 Run ,开始构建工程。build 过程中会自动下载demo需要的模型和Lite预测库。如果出现编译错误,需要更新 gradle 到最新版本,再重新 Run 就可以成功了。在手机端,可以看到新安装了一个 APP。手机上随便找一张图像测试一下,界面如下:

2.3.4 二次开发
为了让手机端能够加载我们训练得到的模型,首先将 2.3.1 节得到的
model.nb
下载到电脑端,放在
PaddleSeg\deploy\lite\human_segmentation_demo\app\src\main\assets\image_segmentation\models\for_cpu
目录下,然后在重新 build ,目前尝试最终失败,欢迎尝试成功的读者评论区留言。
注:
手机端部署最终在采用 Fastdeploy 部署工具后成功,感兴趣的读者可以接着往下看。
2.4 Web 端/前端部署
这里主要介绍使用前端推理引擎 Paddle.js 对分割模型进行部署,使用一个新模型完成部署流程,需要如下步骤: 环境准备、模型转换、模型预测。
step1: 环境准备
什么是node.js : Node.js是一个 JavaScript 运行时环境,而npm是Node.js的包管理工具,帮助开发者更方便地管理Node.js项目中的依赖项。
# node.js 安装
wget https://npmmirror.com/mirrors/node/v18.20.0/node-v18.20.0-linux-x64.tar.xz
tar -xf node-v18.20.0-linux-x64.tar.xz
cd node-v10.9.0-linux-x64/
./bin/node -v # 输出node 版本
# 解压文件的 bin 目录底下包含了 node、npm 等命令,我们可以使用 ln 命令来设置软连接:
# 回到根目录
mkdir bin
ln -s node-v18.20.0-linux-x64/bin/npm /home/aistudio/bin/
ln -s node-v18.20.0-linux-x64/bin/node /home/aistudio/bin/
export PATH=$PATH:/home/aistudio/bin/ # 添加到环境变量中
node -v # 再次执行 就成功了
step2: 模型转换
# 新建一个python=3.7的环境,安装paddlejsconverter
conda create -p envs/py37 python=3.7
source activate envs/py37
pip install paddlejsconverter
cd PaddleSeg/output/liteseg/
paddlejsconverter --modelPath=inference_model//model.pdmodel --paramPath=inference_model/model.pdiparams --outputDir=./js
上述代码会生成
model.json
描述文件和12个分片参数文件,至此你已经有了Paddle.js推理所需的模型。

step3: demo 体验
cd PaddleSeg/deploy/web/example/
npm install
# 出现报错 TS1005: ':' expected. 这是因为typescript版本过低, 卸载后重新安装
.\node_modules\.bin\tsc -v # 查看typescript版本 5.4.3
npm uninstall typescript
npm install typescript
npm run dev
注:这里官方 example 能跑通,但自己的模型依然无法成功部署,欢迎尝试成功的读者评论区留言。
2.5 FastDeploy 部署套件
一款全场景、易用灵活、极致高效的AI推理部署工具,支持云边端部署,详情可参考官方文档。
下面介绍几种常见的部署方式。
2.5.1 服务器端 Python 部署
cd deploy/fastdeploy/semantic_segmentation/cpu-gpu/python
python infer.py --model ~/PaddleSeg/output/liteseg/inference_model/ --image /home/aistudio/data0/koto/imgs/00002-323.jpg --device cpu
# 成功后会在当前文件夹下生成vis_img.png的结果图片
2.5.2 手机端部署
在2.3 PaddleLite移动端部署我们已经跑通了手机端部署的流程,按照同样的方式,我们将官方示例的工程构建成功后,接下来只需要替换我们自己训练的模型
model.nb
即可,替换PaddleSeg模型的步骤如下:
- 将模型放在 app/src/main/assets/models 目录下,比如我的文件夹是 inference_model;
- 修改 app/src/main/res/values/strings.xml 中模型路径的默认值,如:models/inference_model
重新 Run 后,手机端部署成功,这个应用还可以调用手机后置摄像头,在右上角的设置中可以发现:替换的模型已经加载进来了,手机端测试如下图所示:
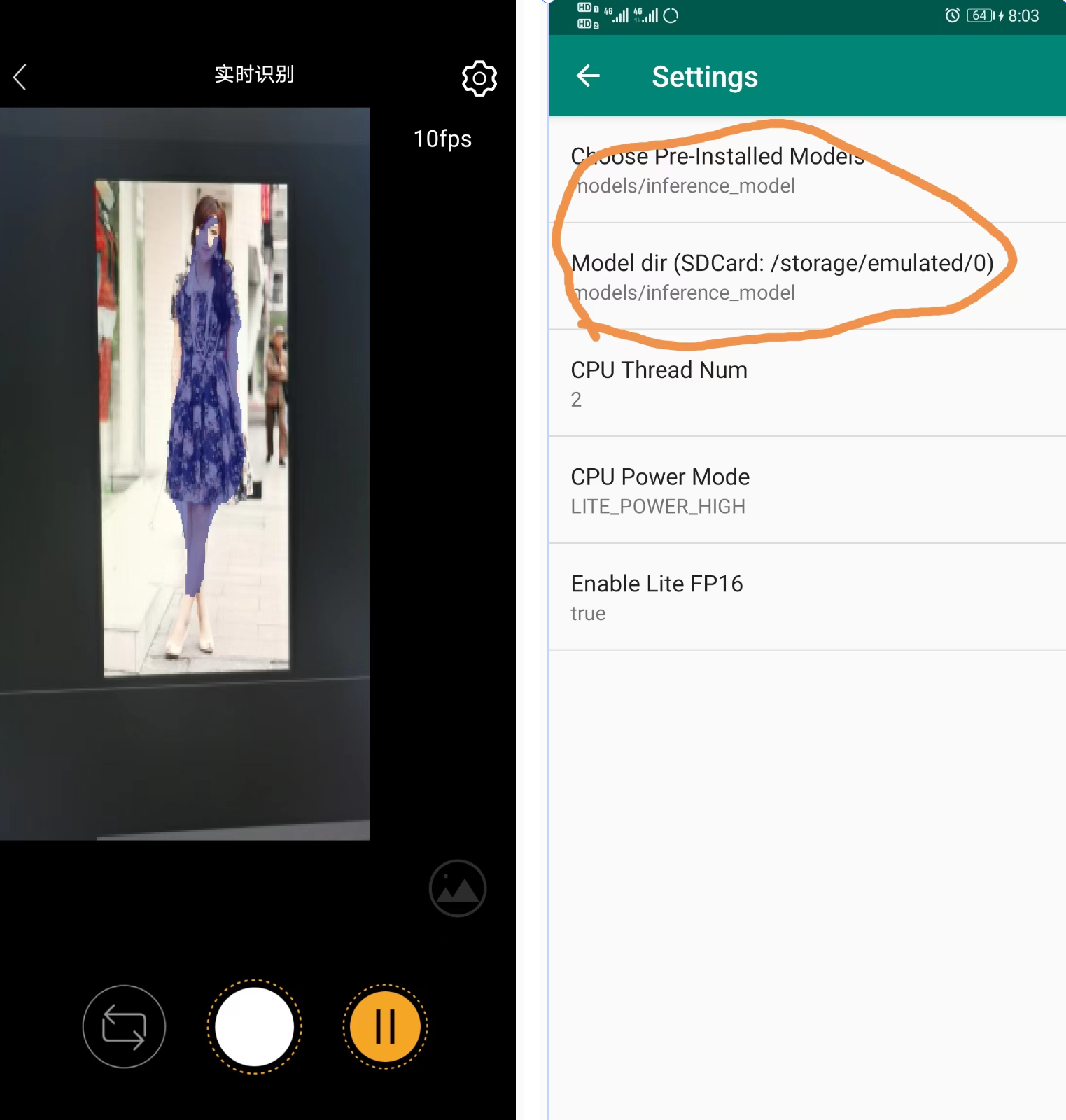
2.5.3 服务端部署
FastDeploy 的服务端部署分两种方式:
- simple_serving:适用于只需要通过http等调用AI推理任务,没有高并发需求的场景。基于Flask框架具有简单高效的特点,可以快速验证线上部署模型的可行性
# FastDeploy安装
## 官方提供了两种方式,这里选择cpu环境下的python预编译库
#https://github.com/PaddlePaddle/FastDeploy/tree/develop/docs/cn/build_and_install
pip install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
# 进入文件夹
cd PaddleSeg/deploy/fastdeploy/semantic_segmentation/serving/simple_serving
# 修改模型文件位置
model_dir = '/home/aistudio/PaddleSeg/output/liteseg/inference_model/'
# 启动服务-启动成功后 默认接口在 http://127.0.0.1:8000, 也可以指定端口--port 8080
fastdeploy simple_serving --app server:app
# 客户端调用-发送http请求
python client.py
# 成功后会在当前文件夹下生成visualized_result.png的结果图片
- fastdeploy_serving:适用于高并发、高吞吐量请求的场景。基于Triton Inference Server框架,是一套可用于实际生产的完备且性能卓越的服务化部署框架
由于官方文档基于拉取的镜像进行构建,自行编译在ai studio云环境中无法进行,暂且搁置
2.5.4 web 端/前端部署
这一部分主要介绍了
pp-humanseg
这个contrib,更多信息在介绍文档,可以训练后再通过 paddle.js 部署。
3 AI证件照应用搭建
在第 2 部分我们介绍了各种模型部署方式,那么如何基于本篇训练得到的模型,快速搭建一个应用并上线展示呢?
这里推荐采用 AI Studio 的高代码应用开发,支持 Streamlit 和 Gradio 两种前端展现方式, 目前还可以免费利用百度免费的 CPU 资源。
3.1 快速搭建 跑通流程
我们可以先基于AI Studio 的高代码应用开发的官方文档,采用前后端分离的开发思路,先将应用快速搭建起来,跑通整个流程。
基本思路:
- 后端:Fastdeploy 的 simple_serving 方式,开启一个后端服务,供前端调用。
- 前端:采用 Gradio 搭建前端界面,并调用后端服务进行图片推理。
基本步骤:
- step1: 模型和数据准备
cd ~ # 回到根目录
mkdir demo & cd demo
cp -r ../PaddleSeg/output/liteseg/inference_model/ ./
cp ../PaddleSeg/deploy/fastdeploy/semantic_segmentation/serving/simple_serving/server.py ./
- step2: 开启后端服务
# 修改模型位置,并启动服务
fastdeploy simple_serving --app server:app
- step3: 实现前端界面
touch demo.gradio.py # 新建文件
# 在主进程中写一个调用函数
'''
def process_image(image):
url = "http://127.0.0.1:8000/fd/ppliteseg"
headers = {"Content-Type": "application/json"}
np_image = np.array(image)
data = {"data": {"image": cv2_to_base64(np_image)}, "parameters": {}}
resp = requests.post(url=url, headers=headers, data=json.dumps(data))
if resp.status_code == 200:
r_json = json.loads(resp.json()["result"])
result = fd.vision.utils.json_to_segmentation(r_json)
vis_im = fd.vision.vis_segmentation(np_image, result, weight=0.5)
return vis_im, 'Success'
else:
print("Error code:", resp.status_code)
return np_image, resp.text
'''
# 前端界面实现
'''
demo = gr.Interface(fn=process_image,
inputs=[gr.Image(label="Upload image", type="pil")],
outputs=[gr.Image(label="Masked image", width=400, height=400), gr.Textbox(label='Status')],
title="Human Image Segmentation",
description="Seg any image using pp_liteseg trained by PaddleSeg",
allow_flagging="never",
examples=["./demo/1.jpg", ])
'''
- step4: 界面测试
回到 CodeLab 界面,打开 demo.gradio.py ,右侧会自动渲染 Gradio 界面。

- step5: 应用上线
# 准备项目依赖文件 requirements.txt,其中写入
'''
numpy
pillow
gradio
fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
'''
# 编写入口文件 main.gradio.py,其中写入
'''
import os
import time
import subprocess
# 启动后端服务,并在后台运行
backend_process = subprocess.Popen('fastdeploy simple_serving --app server:app', shell=True)
# 前端调用
time.sleep(5) # 等待后端服务启动
os.system('python demo.gradio.py')
'''
在项目 CodeLab 界面右上角点击“部署”,选择“Gradio应用”,注意我们的部署目录是 /demo,如下图,确认好之后,点击部署。如果部署失败,可以在 CodeLab 界面右下角查看日志。
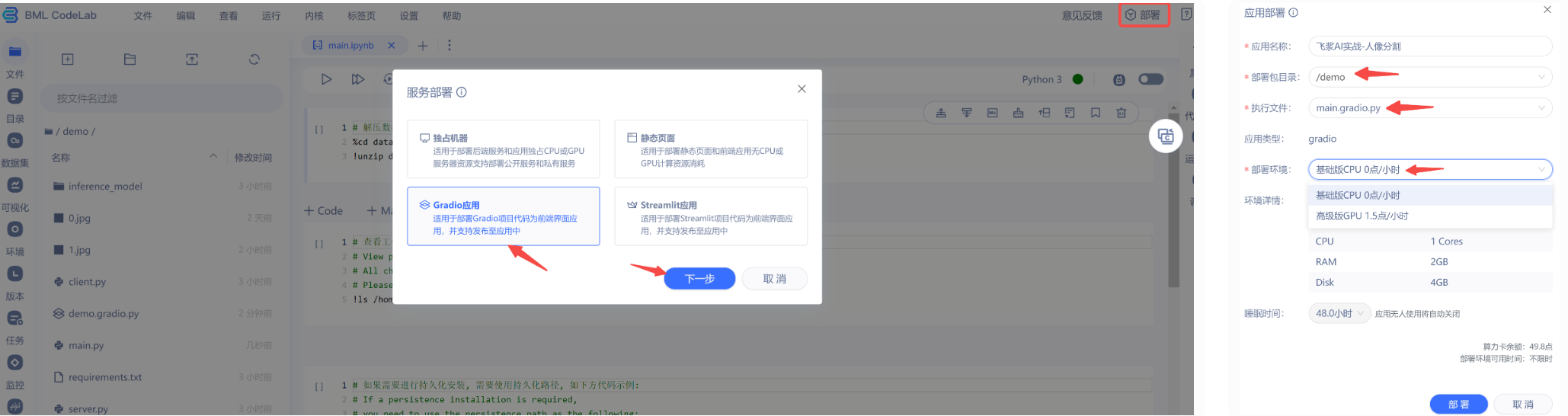
部署成功后,可以在 CodeLab 界面右下角点击查看,或者也可以在自己的控制台-我的-应用中找到,如下图所示,进去后,用自带的图测试一下,搞定!

3.2 功能优化 界面美化
流程跑通后,接下来让我们把功能做的更完善一些,界面设计的更美观一些吧!
需求分析:
- 用户需要指定照片生成尺寸;
- 用户需要指定照片背景颜色
功能实现:
新建
demo2.gradio.py来实现第二版的功能和前端界面。
# 主函数处理逻辑中增加背景替换功能
def process_image(image, backgroud_color, width, height, radio):
url = "http://127.0.0.1:8000/fd/ppliteseg"
headers = {"Content-Type": "application/json"}
np_image = np.array(image)
data = {"data": {"image": cv2_to_base64(np_image)}, "parameters": {}}
resp = requests.post(url=url, headers=headers, data=json.dumps(data))
if resp.status_code == 200:
r_json = json.loads(resp.json()["result"])
result = fd.vision.utils.json_to_segmentation(r_json) # label map
vis_im = fd.vision.vis_segmentation(np_image, result, weight=0.5) # mask image
out_im = add_background(np_image, result, backgroud_color, width, height, radio)
return vis_im, out_im, 'Success'
else:
print("Error code:", resp.status_code)
return np_image, np_image, resp.text
# 实现背景替换:尺寸 + 颜色
def add_background(input_image, label_mask, backgroud_color, out_width, out_height, radio):
height, width, _ = input_image.shape
mask = np.array(label_mask.label_map).reshape(label_mask.shape)
back_image = np.array(Image.new('RGB', (width, height), backgroud_color))
back_image = cv2.cvtColor(back_image, cv2.COLOR_RGB2BGR)
out_image = (mask[...,None]*input_image + (1-mask[...,None])*back_image).astype(np.uint8)
if radio == "保持原图大小":
out_size = (width, height)
else:
out_size = (int(out_width), int(out_height))
return cv2.resize(out_image, out_size)
界面优化:
参考其他项目的界面设计,发现 AI抠图|一键制作证件照 这个项目的界面设计和逻辑和我们的需求非常类似。
with gr.Blocks() as demo:
with gr.Tab(label="AI抠图-证件照"):
with gr.Row(): # 水平布局行
with gr.Column(): # 垂直布局列
radio_1 = gr.Radio(choices=["自选(使用下面的取色器)",
"白色(用于护照、签证、身份证等)",
"蓝色(用于毕业证、工作证等)",
"红色(用于一些特殊的证件照)" ], label="背景颜色", value="白色(用于护照、签证、身份证等)")
color_picker_1 = gr.ColorPicker(label="取色器", value="#FFFFFF")
radio_1.change(fn=update_color, inputs=[radio_1, color_picker_1], outputs=color_picker_1)
with gr.Column():
radio_2 = gr.Radio(choices=[
"保持原图大小",
"自选(在下面输入尺寸)",
"一寸(295像素 x 413像素)",
"大一寸(390像素 x 567像素)",
"小二寸(413像素 x 531像素)",
"二寸(413像素 x 626像素)" ], label="证件尺寸大小", value="一寸(295像素 x 413像素)")
with gr.Row():
width = gr.Number(label="宽度(像素)", value=295)
height = gr.Number(label="高度(像素)", value=413)
radio_2.change(fn=update_size, inputs=[radio_2, width, height], outputs=[width, height])
with gr.Row():
with gr.Column():
image_input = gr.Image(label="输入图片", type='pil')
button = gr.Button(value="提交", variant="primary")
with gr.Column():
with gr.Row():
image_output_1 = gr.Image(label="抠图输出图片", show_download_button=True)
image_output_2 = gr.Image(label="证件照输出图片", show_download_button=True)
status = gr.Textbox(label='处理状态')
button.click(fn=process_image, inputs=[image_input, color_picker_1, width, height, radio_2], outputs=[image_output_1, image_output_2, status])
修改 main.gradio.py 中的前端接口:
# 前端调用
# os.system('python demo.gradio.py')
os.system('python demo2.gradio.py')
最后再按照 3.1 节step5: 应用上线的流程部署上线就 OK 拉,测试结果如下图所示。
目前版本的模型分割效果还不是太好,感兴趣的小伙伴还可以尝试:
- 训练迭代更多的次数
- 更多针对证件照场景的数据集
- 其他性能更佳的模型
总结
本文通过一个计算机视觉领域中最基础的任务之语义分割,带领大家熟悉百度PaddleSeg深度学习框架中的各种组件,覆盖了数据准备、模型训练评估、推理部署的全流程,最后通过应用开发实现了一个简单的前后端分离项目,感兴趣的小伙伴还可以选择其他部署方式。案例选自现实生活场景-人像分割和证件照制作,有现实应用需求。
本系列的后续文章将沿袭这一思路,继续分享更多采用Paddle深度学习框架服务更多产业应用的案例。如果对你有帮助,欢迎 关注 收藏 支持一下啊~
本文由mdnice多平台发布
版权归原作者 AI码上来 所有, 如有侵权,请联系我们删除。