
1 人工智能、机器学习、深度学习的关系
如图1所示
图 1 :人工智能、机器学习、深度学习之间的关系
可以看到,三者之间相互包含:人工智能涵盖范围最广,它包含了机器学习;而机器学习是人工智能的重要研究内容,它又包含了深度学习。
人工智能(Artificial Intelligence:AI)、机器学习(Machine Learning:ML)和深度学习(Deep Learning:DL)在计算机科学领域中形成了一种层次关系。在最广泛的层面上,人工智能构成了开发计算机系统的首要目标,它可以执行需要类人智能的任务。在人工智能领域中,机器学习作为一个专门的子集出现,专注于使机器在没有显式编程的情况下从数据中学习。ML包括各种学习范式,包括有监督、无监督和强化学习。另一方面,深度学习是ML中的进一步专业化,利用具有多层的深度神经网络来自动学习数据的层次表示。虽然人工智能封装了智能系统的宏伟愿景,但ML为机器提供了从数据中学习模式的基础工具,而DL通过使用复杂的神经结构来改进这一过程。深度学习,特别是其深度神经网络,擅长从大型数据集中捕捉复杂的特征,从而在图像和语音识别等任务上取得突破。从本质上讲,人工智能是一个总体概念,ML作为一个子集提供了学习能力,而DL,ML的一种特殊形式,利用深度神经网络来实现先进的学习和表示,共同推动了智能系统和技术的进化。这种层次关系突出了从人工智能的广泛愿望到ML和DL中分别复杂复杂的学习机制和神经结构的进展。
2 人工智能、大数据、数据分析、数据挖掘的关系
大数据是指大量的结构化和非结构化数据,它构成了人工智能应用的基础资源。人工智能算法,包括机器学习和深度学习,可以在大型数据集上进行训练模型和提高预测精度。
数据分析包括对数据的检查和解释,以得出结论,确定趋势和支持决策。在人工智能的背景下,数据分析在将数据集输入学习算法之前的预处理和细化中发挥着至关重要的作用。它有助于特征选择,识别异常值,并确保数据质量,有助于人工智能模型的有效性。
数据挖掘是数据分析的一个子集,它专注于从大型数据集中发现隐藏的模式和知识。它使用了各种技术,包括统计分析和机器学习算法,以发现有价值的见解。数据挖掘在提取相关信息方面尤其有用,这些信息可用于增强人工智能模型和提高其决策能力。
随着人工智能系统利用大数据的能力,利用大数据的丰富度来有效地训练模型,这些领域之间的关系变得很明显。反过来,人工智能通过自动提取复杂模式和基于学习到的行为进行预测来增强数据分析和数据挖掘过程。人工智能可以在大型数据集中发现复杂的关系,这可能是传统数据分析方法要识别的挑战。如图2 所示: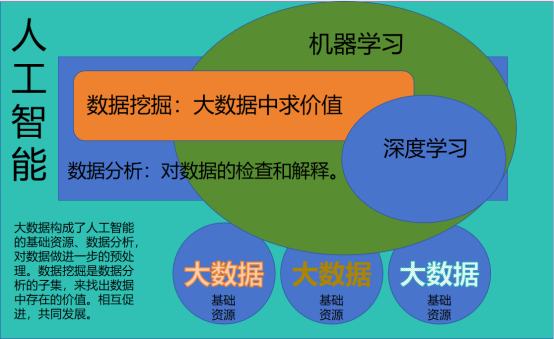
图2 人工智能、大数据、数据分析、数据挖掘的关系
3 深度学习
深度学习(DL)是机器学习(ML)的一个复杂的子集,它利用具有多层的神经网络来自动学习数据的层次表示。DL的本质在于它能够从大型而复杂的数据集中自动提取复杂的特征和模式,使机器能够以一种类似于人类认知的方式来理解和解释信息。深度学习的核心是深度神经网络,其特征是具有输入层、多个隐藏层和输出层的复杂架构。这些层通过加权连接相互连接,使模型能够逐步捕获层次结构的特征,从而允许在数据中表示抽象的概念和细微差别。训练过程包括向网络提供大量的标记数据,通过反向传播迭代地调整权值,并改进模型泛化模式的能力。DL擅长于图像和语音识别、自然语言处理和复杂决策等任务,在传统机器学习方法可能不足的领域表现出显著的表现。深度学习的变革性影响遍及各个行业,推动了医疗保健诊断领域的进步,自动驾驶汽车、推荐系统等等。虽然深度学习的计算需求可能是巨大的,但最近的技术进步和强大的硬件的可用性促进了它的广泛采用。深度学习的成功明显体现在其在特定领域超越人类水平的能力上,这标志着人工智能能力的范式转变。作为一个不断发展的领域,深度学习继续推动机器所能实现的边界,正在进行的研究集中于提高模型的可解释性,解决伦理考虑,并将其适用性扩展到新的领域。总之,深度学习代表了机器学习的一种革命性方法,使系统能够自主地从数据中学习复杂的表示,其影响在不同领域产生共鸣,塑造了人工智能的未来格局。
3.1 神经网络
人工智能的目的是让机器具备人的思维和意识。在实现的过程中,目前有主流三大学派、分别为行为主义、符号主义和连接主义。其中行为主义是基于控制论,目的是构建一个感知-动作控制系统。(控制论,如平衡、行走、避障等自适应控制系统)。符号主义是基于算数逻辑表达式,求解问题时先把问题描述为表达式,再求解表达式(可用公式描述、实现理性思维,如专家系统)。连接主义:基于仿生学,模仿神经元连接关系。(仿脑神经元连接,实现感性思维,如神经网络)。如图3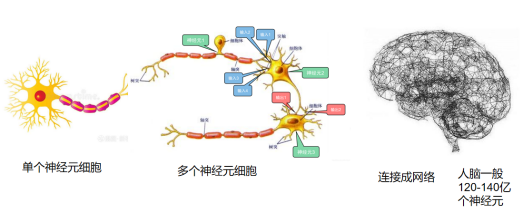
图 3 :仿人脑神经元构建的神经网络
3.2 神经网络设计过程
随着我们的成长,大量的数据通过视觉、听觉涌入大脑,使我们的神经网络连接,也就是神经元连接线上的权重发生变化,有些线权重增强了,有些线上的权重减弱了。如图4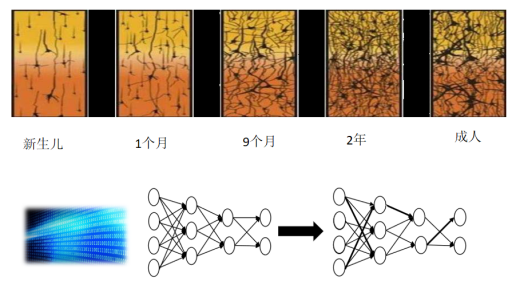
图 4 :神经网络设计过程
3.3 将人脑学习过程转换神经网络学习过程
3.31 数据准备
以手写数字识别mnist数据集为例:
MNIST数据集共有7000张图像,其中其中训练集60000张,测试集10000张,所有图像都是28*28的灰度图像,每张图像包含一个手写数字。
标注类别:共10个类别,每个类别代表0-9之间的数字。
图 5 :mnist数据集
数据集由图像和标签构成,mnist数据集的图像为28*28的灰色图像。标签则对应着每个图像所属的数字类别。
3.3.2 跨越语义的鸿沟
MNIST数据是由70000个2828的灰度图组成。我们人眼看到的是一张张图片。而计算机看到的是一组组矩阵。如图6
图6 :mnist数据集、计算机看到的矩阵形式2828的矩阵
同样的如果是3通道的彩色图像,则计算机看到的是3个矩阵。多通道则是n个矩阵。
3.3.3 彩色图像需要考虑的维度
如下图,随着学习的深入和进阶。我们需要考虑图像可能遇到的多个维度。计算机在处理时会遇到哪些困难。如图7所示: 可能包括但不限于视角、光照、遮挡、尺度、形变、背景杂波、运动模糊等。了解这些,在模型训练时,适当做些数据增强,效果会很好。同时针对不同图像的特点,有针对的性的做图像处理,也可以改善模型性能。
图 7 :图像需要考虑的多个维度
版权归原作者 广东工商职业技术大学人工智能实验室 所有, 如有侵权,请联系我们删除。