
机器学习就是从数据中学习,从而使完成任务的表现越来越好。小样本学习是具有有限监督数据的机器学习。类似的,其他的机器学习定义也都是在机器学习定义的基础上加上不同的限制条件衍生出来。例如,弱监督学习是强调在不完整、不准确、有噪声、数据少的数据上学习,半监督学习是强调在少量标注数据和大量非标注数据上学习,迁移学习是把充足数据上学习的知识迁移到数据匮乏的任务上。
所谓小样本是训练数据较少,小样本学习的先验知识来自三方面:数据、模型、算法,小样本学习的研究也都是从这三方面着手。因此,小样本学习方法大致可分为基于数据增强的方法、基于模型改进的方法、基于算法优化的方法。当把few-shot learning运用到分类问题上时,就可以称之为few-shot classification,当运用于回归问题上时,就可以称之为few-shot regression。
1、基于数据增强的方法
主要思路就是数据增强,通俗地讲就是扩充样本。小样本学习所使用的数据增强方法主要有三个思路:
1)只有小样本数据集:可以训练一个transformer学习样本之间的变化,然后使用该transformer对小样本数据集进行扩充;
2)有小样本数据集+弱标注数据集:可以训练transformer从弱标注数据集中“挑选”样本来扩充小样本数据集;
3)有小样本数据集+相似的数据集:可以训练一个GAN网络,通过学习给小样本数据集加上扰动来生成新样本。
2、分类任务的小样本学习
总结:https://blog.csdn.net/qq_24178985/article/details/119900076
举例:小敏生日,在动物园游玩。小敏走进极地馆,发现了一毛茸茸的可爱小动物,她非常喜欢,但是小敏之前只认识其它动物,没有见过这种动物。小敏拿出入园时领取的动物学识卡,逐一翻阅卡片,确定图一中的小动物是狐狸。
2.1、Support Set 和 Query
在小样本学习中,动物学识卡这种数据集被称为Support Set,种需要判断其类别的图片被成为Query。根据Support Set中类别数量和样本数量的不同,Support Set 可被称为 k-way、 n-shot Support Set。小样本分类问题一般被定义为 K-way N-shot 问题。
k-way:Support Set中存在 k 个类别
n-shot:每个类别中存在 n 个样本
在上述小敏学会辨认狐狸的例子中,小敏入园时领取的动物学识卡构成的Support Set中有狐狸、松鼠、兔子、仓鼠、水獭和海狸6种不同的小动物,因此 k 等于6。每种小动物卡片只有一张,所有 n 等于1。这个Support Set是6-way 1-shot Support Set。
小样本分类准确率会受到Support Set中类别数量和样本数量的影响,随着类别数量增加,分类准确率会降低。随着每个类别样本数增加,分类会更准确。
Support Set与训练集的区别:
训练集是一个非常大的数据集,每一类均包含非常多张图片。训练集足够大,可以用来训练一个深度神经网络。Support Set非常小,每一类只包含一张或几张图片,不足以训练一个深度神经网络。Support Set用于在预测时提供额外信息,使得模型能够断出所属类别不在训练集中的Query图片的类别。
即:先通过大的数据集训练一个能够区分与本类别相似的分类网络,之后在 Support Set 上微调。查询测试则在 Query 上进行。
2.2、基本思路
在小样本学习问题中,Support Set中每一类往往只有少数几个样本,单单依靠这些样本,不可能训练出一个深度神经网络,甚至无法采用迁移学习中的Pretraining+Fine Tuning方法。即对于小样本学习问题,不能采用传统的监督学习方法来进行分类。
小样本学习的最基本想法是学习一个 sim 函数来判断相似度。给定两张图片 a 和 b,如果两张图片越相似,则 sim (a, b) 的值越大。在理想情况下,若 a 和 b 属于同一类,则 sim (a, b) = 1 ,若a 和 b 属于不同类,则 sim (a, b) = 0。具体可以按照如下思路解决小样本学习问题:
step1、在一个大数据集中学习一个判断两张图片相似程度的相似度函数;
step2、给定一个Query图片,将其和Support Set中各图片逐一对比,计算相似度;
step3、在Support Set中找到与Queryt图片相似度最高的图片,将其类别作为预测结果。
3、孪生网络
训练孪生网络需要用到一个大的分类数据集,数据集中每张图片均有标注,每一类均包含许多张图片。训练的第一种方法是每次从数据集中随机抽取两个样本,比较他们的相似度,并根据相似度函数损失更新网络参数。
首先须使用数据集来构造正样本和负样本,其中正样本用于告诉神经网络什么东西是同一类,负样本用于告诉神经网络事物之间的区别。构造正样本首先须从数据集中随机抽取一张图片 a,然后从同一类中随机抽取另一张图片 b,形成三元组( a, b, 1)。构造负样本每次先随机抽取一张图片 c,然后排除 c 的类别,从随机集中随机抽取另一张图片d,形成三元组(c , d,0)。重复上述构造正样本和负样本的过程,即可生成用于训练孪生网络的训练集。

搭建卷积神经网络用于提取图片中的特征,网络输入是一张图片 x ,输出是提取的特征向量 f(x)。将生成的训练集中一个样本的两张图片 x1和 x2 分别输入搭建的卷积神经网络,得到特征向量 h1 和 h2。将向量 h1 和 h2 结合形成特征向量 z (如令 z = concat(h1, h2)或 z=|h1-h2| 等等),然后用一些全连接层处理 z 向量,输出一个标量,并将该标量经过 Sigmoid 激活函数,得到一个介于0 ∼ 1之间的实数。
该实数可以衡量输入的两张图片 x1和 x2 之间的相似度,如果 x1和 x2 属于同一个类别,则输出实数应该接近于1,否则应该接近于0。使用网络输出与真实标签之间的交叉熵(CrossEntropy)作为损失函数,通过反向传播计算模型参数的梯度,并使用梯度下降法来更新模型参数。
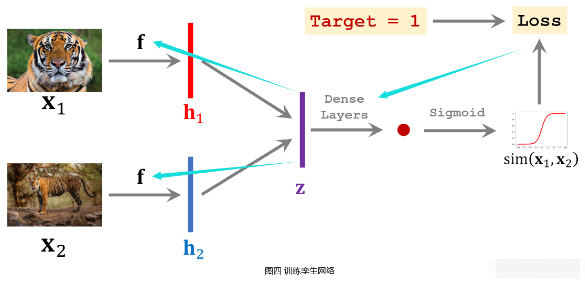
训练孪生网络需要准备数量大致相当的正样本和负样本,负样本是不同类别的两张图片,其标签为0,通过训练使孪生网络输出接近于0。训练好孪生网络之后,可以用来做小样本分类。逐一对比Query图片与Support Set中的图片,返回Support Set中相似度最高的图片类别作为预测结果。
4、Triplet Loss
上述训练孪生网络方法从理论上看起来很完美,但是在深度学习实践中,上述方法效果并不是特别好。在深度学习领域,理论上看起来很完美,但是实际效果却一塌糊涂的例子数见不鲜,比上述方法更好的训练孪生网络的方法是使用Triplet Loss。
使用Triplet Loss,在构建训练集时,需每次从数据集中选取3张图片。首先从数据集中随机选取一张图片作为锚点(Anchor),再从锚点图片所在类别中随机抽取另一张图片作为正样本(Positive),然后排除锚点图片所在类别,从数据集中随机选取一张图片作为负样本(Negative)。
将锚点图片、正样本图片和负样本图片分别输入搭建好的用于提取图片特征的卷积神经网络,得到三个特征向量,计算类内、类间距离。训练时希望类内距离越小、类间距离越大。
训练孪生网络的损失函数首先应该鼓励正样本在特征空间上接近锚点,即使d+尽量小。其次应该鼓励负样本在特征空间上远离锚点,即使d-尽量大。因此,可分为如下两种情况:

确定损失函数之后,可以求损失函数关于模型参数的梯度,并使用随机梯度下降法更新模型参数。训练好孪生网络之后,可以通过如下方法来做小样本分类。
将Query图片和Support Set中所有图片全部转化为特征向量,然后依次计算Query图片对应的特征向量和Support Set中各图片对应特征向量之间的距离,返回Support Set中距离最小的图片类别作为预测结果。
参考文献:
1、Generalizing from a Few Examples: A Survey on Few-Shot Learning
https://arxiv.org/pdf/1904.05046.pdf
2、距离你解决小样本/少数据难题,只差这篇文章
https://mp.weixin.qq.com/s/WsQWRbtkylDC81EXOI6NxA
3、小样本学习(Few-Shot Learning)
https://blog.csdn.net/qq_24178985/article/details/119900076
4、【机器学习】Few-shot learning(少样本学习)
https://blog.csdn.net/weixin_44211968/article/details/121314757
版权归原作者 alex1801 所有, 如有侵权,请联系我们删除。