

我最近阅读了一篇名为《使用自动编码器进行异常检测》的文章,在该文中对所生成的数据进行了实验,并且我认为将使用自动编码器进行异常检测这一想法应用于真实世界当中的欺诈检测中,似乎是一个不错的主意。

我决定从Kaggle中使用信用卡欺诈数据:该数据集包含有在2013年9月欧洲持卡人的信用卡交易信息。
这个数据集显示了两天内发生的交易,其中在284,807次交易中有492次为欺诈数据。这样的数据集是相当不平衡的,其中正类(欺诈)数据占所有交易数据的0.172%。
数据挖掘
这虽然是一个非常不平衡的数据集,但是它也是一个很好的例子:对异常或欺诈进行识别验证。
首先,我们需要通过主成分分析法将数据集维度由30维下降到3维,并画出其对应的点状图。其中,该数据集共有32列,第一列为时间,29列为未知的数据,1列为交易金额和剩下1列为类别。需要说明的是,我们将忽略时间这一指标,因为它不是一个较为固定的指标。
def show_pca_df(df):
x = df[df.columns[1:30]].to_numpy()
y = df[df.columns[30]].to_numpy()
x = preprocessing.MinMaxScaler().fit_transform(x)
pca = decomposition.PCA(n_components=3)
pca_result = pca.fit_transform(x)
print(pca.explained_variance_ratio_)
pca_df = pd.DataFrame(data=pca_result, columns=['pc_1', 'pc_2', 'pc_3'])
pca_df = pd.concat([pca_df, pd.DataFrame({'label': y})], axis=1)
ax = Axes3D(plt.figure(figsize=(8, 8)))
ax.scatter(xs=pca_df['pc_1'], ys=pca_df['pc_2'], zs=pca_df['pc_3'], c=pca_df['label'], s=25)
ax.set_xlabel("pc_1")
ax.set_ylabel("pc_2")
ax.set_zlabel("pc_3")
plt.show()
df = pd.read_csv('creditcard.csv')
show_pca_df(df)
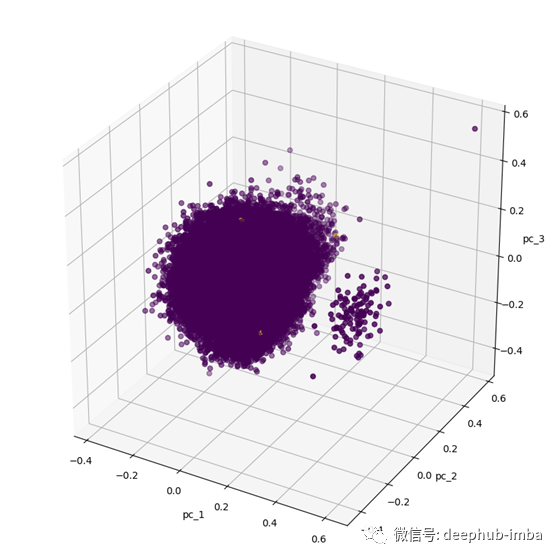
观察上图,能直观地看见有两个单独的集群,这看似是一个非常简单的任务,但是其实欺诈数据仅为黄色的点。仔细看的话,在较大的那个集群中,我们能够看见有三个黄色的点。因此,在我们保留欺诈数据的同时对正常数据进行了再次抽样。
df_anomaly = df[df[df.columns[30]] > 0]
df_normal = df[df[df.columns[30]] == 0].sample(n=df_anomaly.size, random_state=1, axis='index')
df = pd.concat([ df_anomaly, df_normal])
show_pca_df(df)
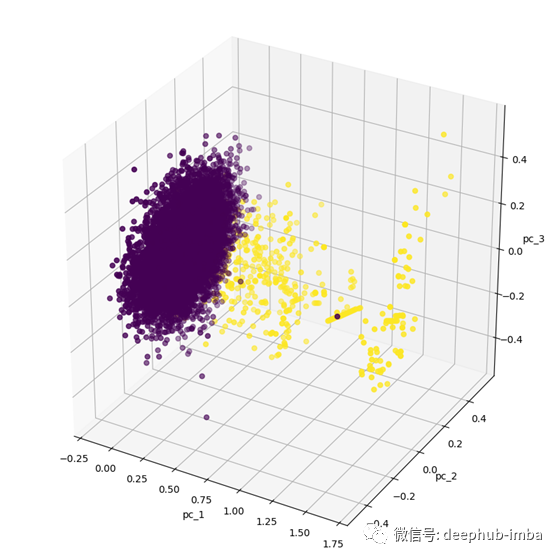
有上图可见,正常数据较为集中,类似于一个圆盘状,而欺诈数据则较为分散。此时,我们将构建一个自动编码器,它具有3层编码器和2层解码器,具体如下:
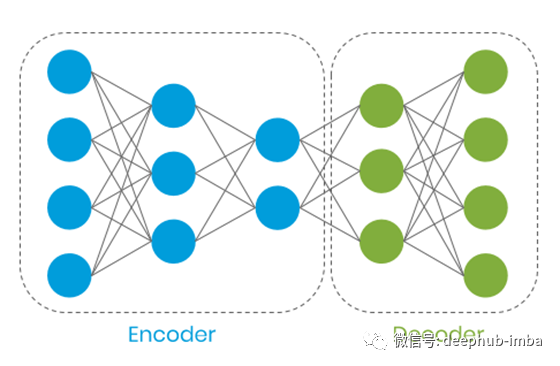
自动编码器将我们的数据编码到一个子空间,并且在对数据进行归一化时将其解码为相应的特征。我们希望自动编码器能够学习到在归一化转换时的特征,并且在应用时这个输入和输出是类似的。而对于异常情况,由于它是欺诈数据,所以输入和输出将会明显不同。
这种方法的好处是它允许使用无监督的学习方式,毕竟在我们通常所使用的数据中,大部分的数据均为正常交易数据。并且数据的标签通常是难以获得的,而且在某些情况下完全没法使用,例如手动对数据进行标记往往存在人为认识偏差等问题。从而,在对模型进行训练的过程中,我们只使用没有标签的正常交易数据。
接下来,让我们下载数据并训练自动编码器:
df = pd.read_csv('creditcard.csv')
x = df[df.columns[1:30]].to_numpy()
y = df[df.columns[30]].to_numpy()
# prepare data
df = pd.concat([pd.DataFrame(x), pd.DataFrame({'anomaly': y})], axis=1)
normal_events = df[df['anomaly'] == 0]
abnormal_events = df[df['anomaly'] == 1]
normal_events = normal_events.loc[:, normal_events.columns != 'anomaly']
abnormal_events = abnormal_events.loc[:, abnormal_events.columns != 'anomaly']
# scaling
scaler = preprocessing.MinMaxScaler()
scaler.fit(df.drop('anomaly', 1))
scaled_data = scaler.transform(normal_events)
# 80% percent of dataset is designated to training
train_data, test_data = model_selection.train_test_split(scaled_data, test_size=0.2)
n_features = x.shape[1]
# model
encoder = models.Sequential(name='encoder')
encoder.add(layer=layers.Dense(units=20, activation=activations.relu, input_shape=[n_features]))
encoder.add(layers.Dropout(0.1))
encoder.add(layer=layers.Dense(units=10, activation=activations.relu))
encoder.add(layer=layers.Dense(units=5, activation=activations.relu))
decoder = models.Sequential(name='decoder')
decoder.add(layer=layers.Dense(units=10, activation=activations.relu, input_shape=[5]))
decoder.add(layer=layers.Dense(units=20, activation=activations.relu))
decoder.add(layers.Dropout(0.1))
decoder.add(layer=layers.Dense(units=n_features, activation=activations.sigmoid))
autoencoder = models.Sequential([encoder, decoder])
autoencoder.compile(
loss=losses.MSE,
optimizer=optimizers.Adam(),
metrics=[metrics.mean_squared_error])
# train model
es = EarlyStopping(monitor='val_loss', min_delta=0.00001, patience=20, restore_best_weights=True)
history = autoencoder.fit(x=train_data, y=train_data, epochs=100, verbose=1, validation_data=[test_data, test_data], callbacks=[es])
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
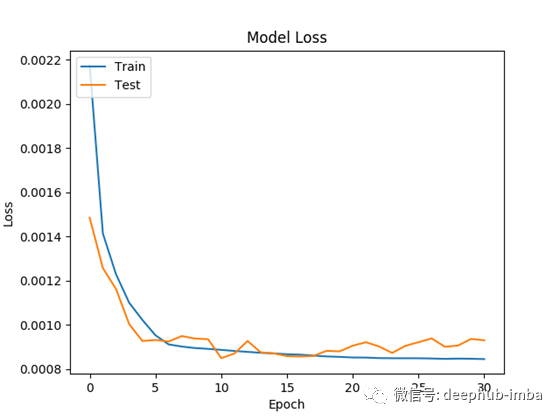
观察下图可知,该模型的误差大约为8.5641e-04,而误差最小时约为5.4856e-04。
使用该模型,我们能够计算出正常交易时的均方根误差,并且还能知道当需要均方根误差值为95%时,阈值应该设置为多少。
train_predicted_x = autoencoder.predict(x=train_data)
train_events_mse = losses.mean_squared_error(train_data, train_predicted_x)
cut_off = np.percentile(train_events_mse, 95)
我们设置的阈值为0.002,如果均方根误差大于0.002时,我们就把这次的交易视为异常交易,即有欺诈行为出现。让我们选取100个欺诈数据和100个正常数据作为样本,结合阈值能够绘制如下图:
plot_samples = 100
# normal event
real_x = test_data[:plot_samples].reshape(plot_samples, n_features)
predicted_x = autoencoder.predict(x=real_x)
normal_events_mse = losses.mean_squared_error(real_x, predicted_x)
normal_events_df = pd.DataFrame({
'mse': normal_events_mse,
'n': np.arange(0, plot_samples),
'anomaly': np.zeros(plot_samples)})
# abnormal event
abnormal_x = scaler.transform(abnormal_events)[:plot_samples].reshape(plot_samples, n_features)
predicted_x = autoencoder.predict(x=abnormal_x)
abnormal_events_mse = losses.mean_squared_error(abnormal_x, predicted_x)
abnormal_events_df = pd.DataFrame({
'mse': abnormal_events_mse,
'n': np.arange(0, plot_samples),
'anomaly': np.ones(plot_samples)})
mse_df = pd.concat([normal_events_df, abnormal_events_df])
plot = sns.lineplot(x=mse_df.n, y=mse_df.mse, hue=mse_df.anomaly)
line = lines.Line2D(
xdata=np.arange(0, plot_samples),
ydata=np.full(plot_samples, cut_off),
color='#CC2B5E',
linewidth=1.5,
linestyle='dashed')
plot.add_artist(line)
plt.title('Threshlold: {threshold}'.format(threshold=cut_off))
plt.show()
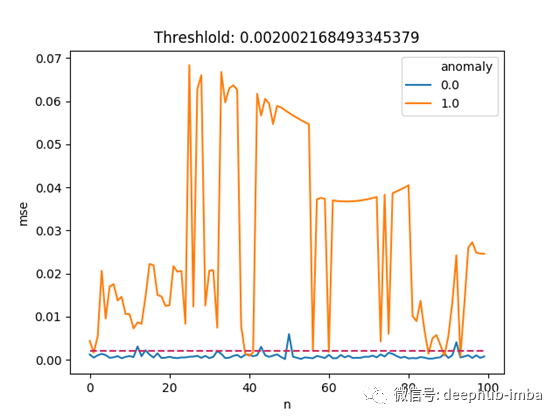
由上图可知,与正常交易数据相比,绝大部分欺诈数据均有较高的均方根误差,从而这个方法对欺诈数据的识别似乎非常奏效。
虽然我们放弃了5%的正常交易,但仍然存在低于阈值的欺诈交易。这或许可以通过使用更好的特征提取方法来进行改进,因为一些欺诈数据与正常交易数据具有非常相似的特征。例如,对于信用卡欺诈而言,如果交易是在不同国家发生的,那么比较有价值的特征是:前一小时、前一天、前一周的交易数量。
下一步的工作
对超参数进行优化。
使用一些数据分析方法来更好的理解数据的特征。
3.将上述方法与其他机器学习的方法相比较,例如:支持向量机或k-means聚类等等。
本文的完整代码均能在Github上进行获取。
https://github.com/bgokden/anomaly-detection-with-autoencoders
引用文献
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and GianlucaBontempi. Calibrating Probability with Undersampling for UnbalancedClassification. In Symposium on Computational Intelligence and DataMining (CIDM), IEEE, 2015
Dal Pozzolo, Andrea; Caelen, Olivier; Le Borgne, Yann-Ael;Waterschoot, Serge; Bontempi, Gianluca. Learned lessons in credit cardfraud detection from a practitioner perspective, Expert systems withapplications,41,10,4915--4928,2014, Pergamon
Dal Pozzolo, Andrea; Boracchi, Giacomo; Caelen, Olivier; Alippi,Cesare; Bontempi, Gianluca. Credit card fraud detection: a realisticmodeling and a novel learning strategy, IEEE transactions on neuralnetworks and learning systems,29,8,3784--3797,2018,IEEE
Dal Pozzolo, Andrea Adaptive Machine learning for credit card frauddetection ULB MLG PhD thesis (supervised by G. Bontempi)
Carcillo, Fabrizio; Dal Pozzolo, Andrea; Le Borgne, Yann-Aël;Caelen, Olivier; Mazzer, Yannis; Bontempi, Gianluca. Scarff: a scalableframework for streaming credit card fraud detection with Spark,Information fusion,41, 182--194,2018,Elsevier
Carcillo, Fabrizio; Le Borgne, Yann-Aël; Caelen, Olivier; Bontempi,Gianluca. Streaming active learning strategies for real-life credit cardfraud detection: assessment and visualization, International Journal ofData Science and Analytics, 5,4,285--300,2018,Springer InternationalPublishing
7.Bertrand Lebichot, Yann-Aël Le Borgne, Liyun He, Frederic Oblé,Gianluca Bontempi Deep-Learning Domain Adaptation Techniques for CreditCards Fraud Detection, INNSBDDL 2019: Recent Advances in Big Data andDeep Learning, pp 78--88, 2019
- Fabrizio Carcillo, Yann-Aël Le Borgne, Olivier Caelen, FredericOblé, Gianluca Bontempi Combining Unsupervised and Supervised Learningin Credit Card Fraud Detection Information Sciences, 2019
作者:Berk Gökden
deephub翻译组:李爱(Li Ai)
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********