
Yolov5更换上采样方式
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
文章目录
常用上采样方式介绍
1. 最近邻插值(Nearest neighbor interpolation)
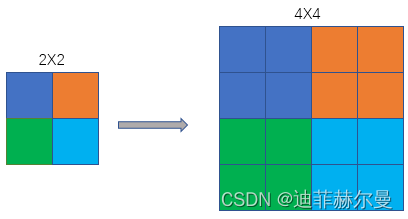
>>>input= torch.arange(1,5, dtype=torch.float32).view(1,1,2,2)>>>input
tensor([[[[1.,2.],[3.,4.]]]])>>> m = nn.Upsample(scale_factor=2, mode='nearest')>>> m(input)
tensor([[[[1.,1.,2.,2.],[1.,1.,2.,2.],[3.,3.,4.,4.],[3.,3.,4.,4.]]]])
2. 双线性插值(Bi-Linear interpolation)
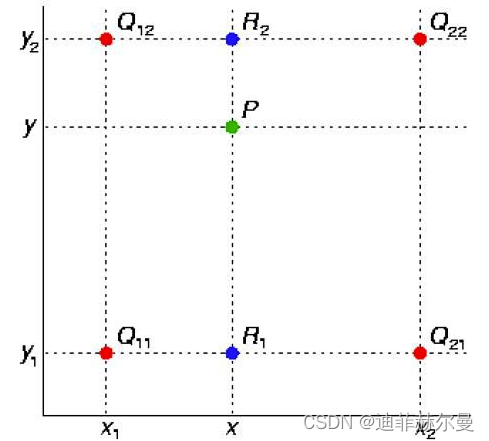
>>>input= torch.arange(1,5, dtype=torch.float32).view(1,1,2,2)>>>input
tensor([[[[1.,2.],[3.,4.]]]])>>> m = nn.Upsample(scale_factor=2, mode='bilinear')# align_corners=False>>> m(input)
tensor([[[[1.0000,1.2500,1.7500,2.0000],[1.5000,1.7500,2.2500,2.5000],[2.5000,2.7500,3.2500,3.5000],[3.0000,3.2500,3.7500,4.0000]]]])>>> m = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)>>> m(input)
tensor([[[[1.0000,1.3333,1.6667,2.0000],[1.6667,2.0000,2.3333,2.6667],[2.3333,2.6667,3.0000,3.3333],[3.0000,3.3333,3.6667,4.0000]]]])
3. 双立方插值(Bi-Cubic interpolation)
>>>input= torch.arange(1,5, dtype=torch.float32).view(1,1,2,2)>>>input
tensor([[[[1.,2.],[3.,4.]]]])>>> m = nn.Upsample(scale_factor=2, mode='bicubic')# align_corners=False>>> m(input)
tensor([[[[0.6836,1.0156,1.5625,1.8945],[1.3477,1.6797,2.2266,2.5586],[2.4414,2.7734,3.3203,3.6523],[3.1055,3.4375,3.9844,4.3164]]]])>>> m = nn.Upsample(scale_factor=2, mode='bicubic', align_corners=True)>>> m(input)
tensor([[[[1.0000,1.3148,1.6852,2.0000],[1.6296,1.9444,2.3148,2.6296],[2.3704,2.6852,3.0556,3.3704],[3.0000,3.3148,3.6852,4.0000]]]])
计算效果:最近邻插值算法 < 双线性插值 < 双三次插值
计算速度:最近邻插值算法 > 双线性插值 > 双三次插值
4. 三线性插值(Trilinear Interpolation)
当
align_corners = True
时,线性插值模式(线性、双线性、双三线性和三线性)不按比例对齐输出和输入像素,因此输出值可以依赖于输入的大小
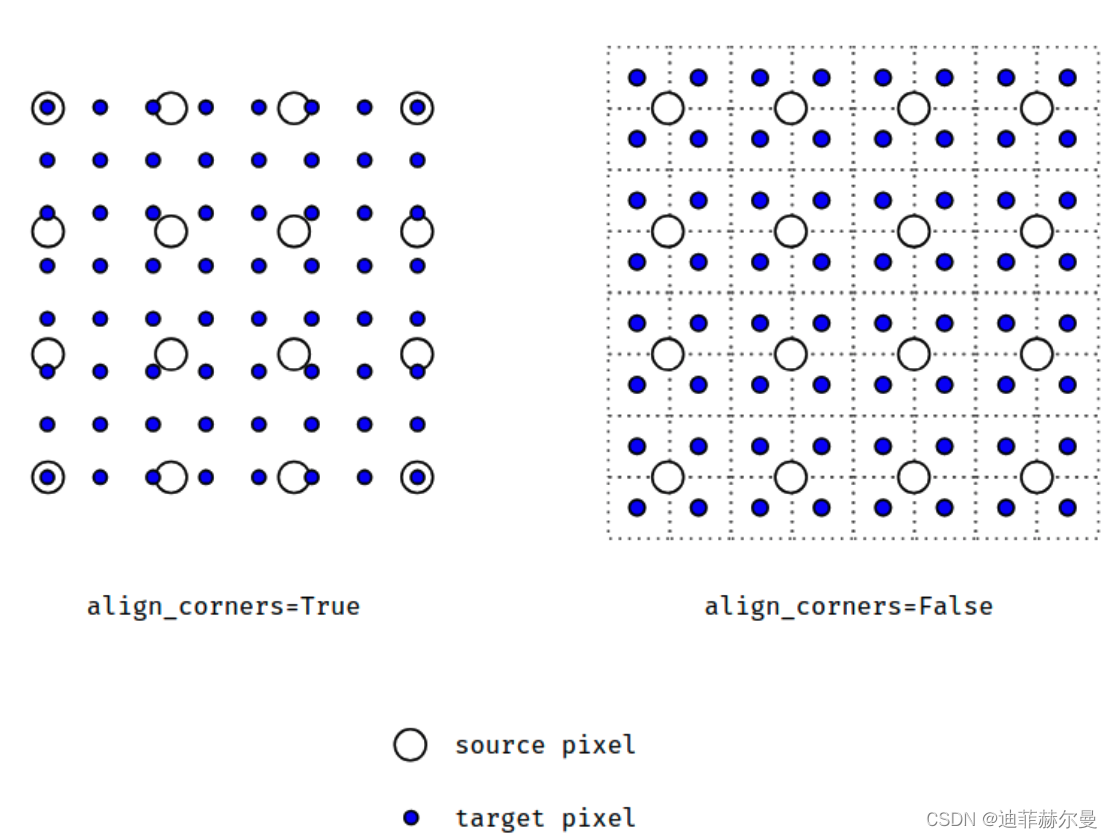
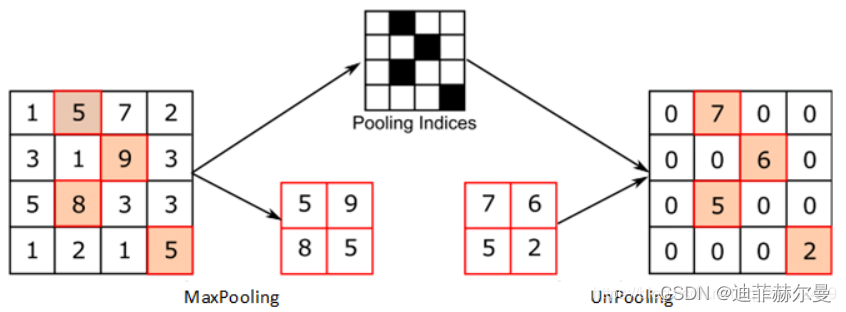
5. 反池化
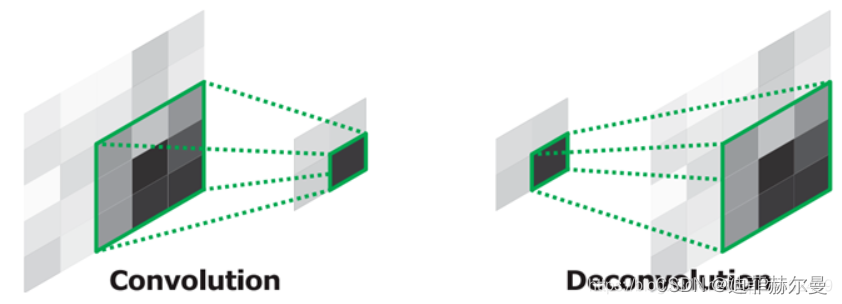
6. 转置卷积
yolov5
默认采用的就是
最近邻插值
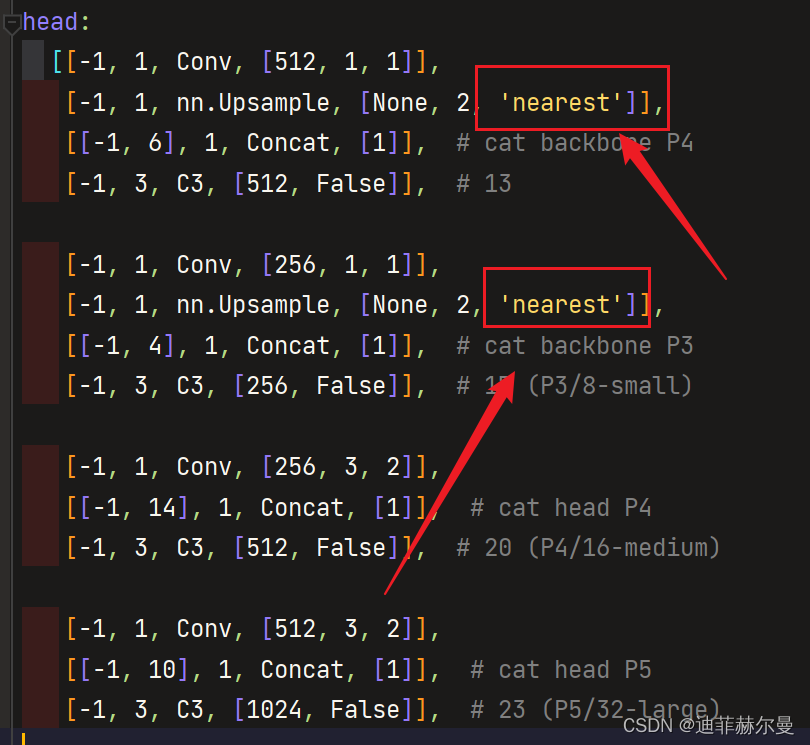
实验结果
这里我将原本的
最近邻插值
的上采样方式替换为
转置卷积
;有人通过实验证明了确实涨点,但是我在VOC数据集上测试并没有涨点,
mAP0.5
大概掉了不到1点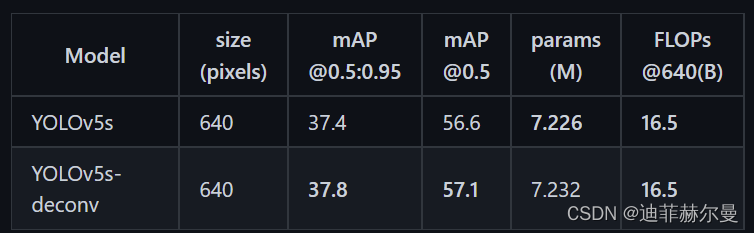
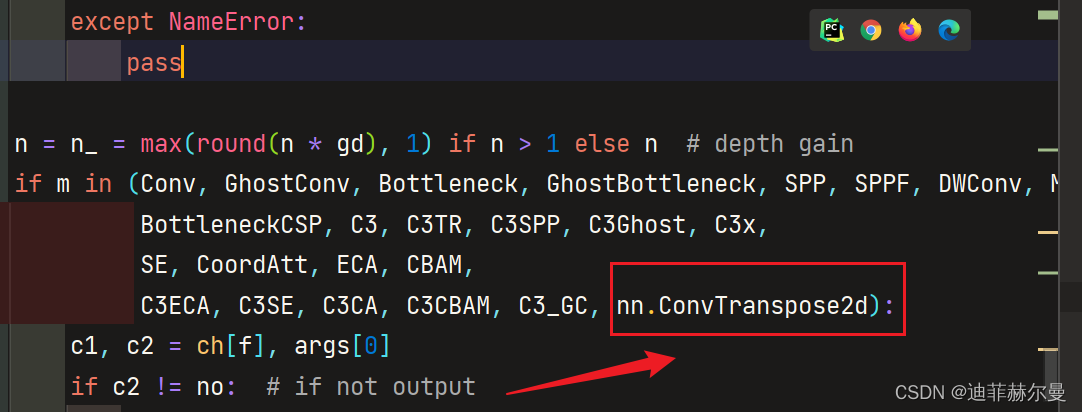
修改方式:
第一步;在
models/yolo.py
添加
nn.ConvTranspose2d
第二步;
models/yolo.py
添加如下代码
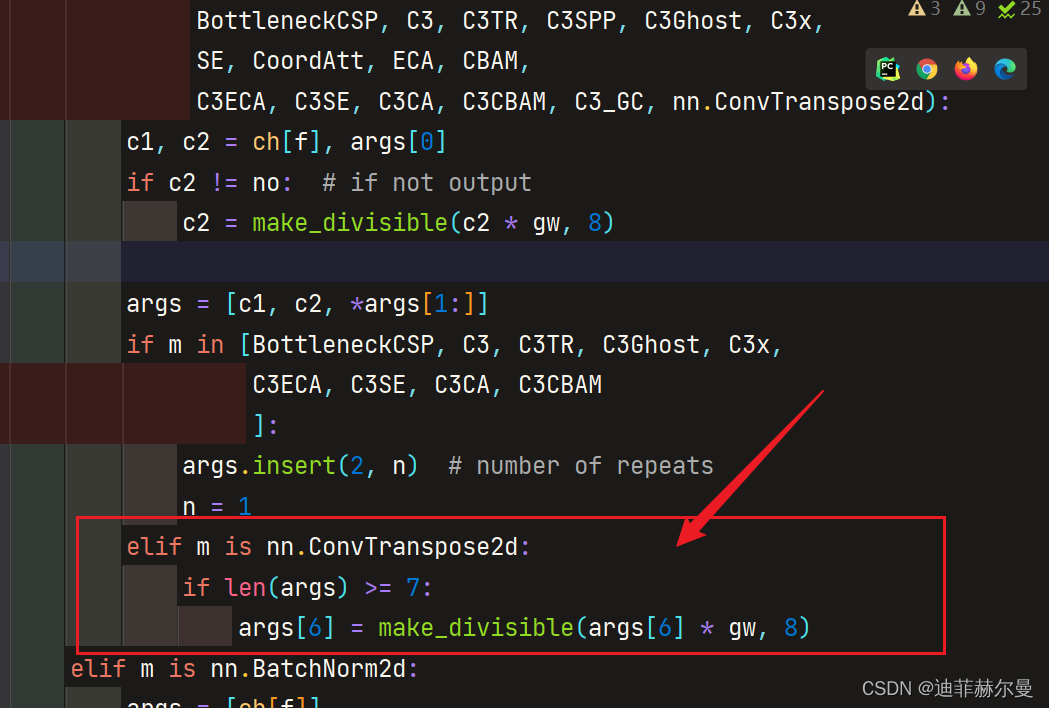
elif m is nn.ConvTranspose2d:iflen(args)>=7:
args[6]= make_divisible(args[6]* gw,8)
第三步;修改配置文件,以yolov5s.yaml为例
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc:80# number of classes
depth_multiple:0.33# model depth multiple
width_multiple:0.50# layer channel multiple
anchors:-[10,13,16,30,33,23]# P3/8-[30,61,62,45,59,119]# P4/16-[116,90,156,198,373,326]# P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1,1, Conv,[64,6,2,2]],# 0-P1/2[-1,1, Conv,[128,3,2]],# 1-P2/4[-1,3, C3,[128]],[-1,1, Conv,[256,3,2]],# 3-P3/8[-1,6, C3,[256]],[-1,1, Conv,[512,3,2]],# 5-P4/16[-1,9, C3,[512]],[-1,1, Conv,[1024,3,2]],# 7-P5/32[-1,3, C3,[1024]],[-1,1, SPPF,[1024,5]],# 9]# YOLOv5 v6.0 head
head:[[-1,1, Conv,[512,1,1]],[-1,1, nn.ConvTranspose2d,[512,4,2,1,0,512]],[[-1,6],1, Concat,[1]],# cat backbone P4[-1,3, C3,[512,False]],# 13[-1,1, Conv,[256,1,1]],[-1,1, nn.ConvTranspose2d,[256,4,2,1,0,256]],[[-1,4],1, Concat,[1]],# cat backbone P3[-1,3, C3,[256,False]],# 17 (P3/8-small)[-1,1, Conv,[256,3,2]],[[-1,14],1, Concat,[1]],# cat head P4[-1,3, C3,[512,False]],# 20 (P4/16-medium)[-1,1, Conv,[512,3,2]],[[-1,10],1, Concat,[1]],# cat head P5[-1,3, C3,[1024,False]],# 23 (P5/32-large)[[17,20,23],1, Detect,[nc, anchors]],# Detect(P3, P4, P5)]
出现下面这样子就是运行成功啦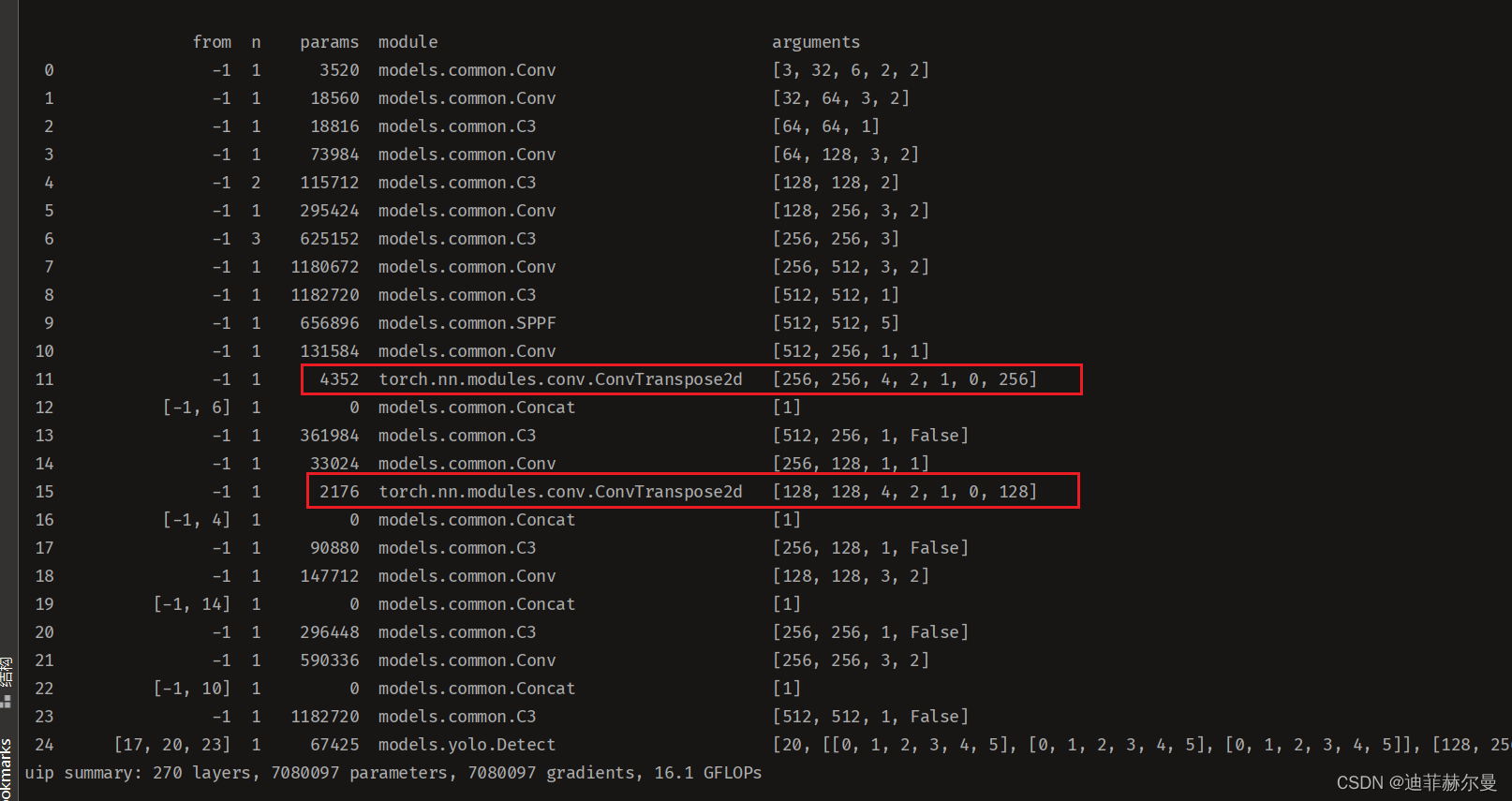
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
本人更多YOLOv5实战内容导航🍀🌟🚀
- 手把手带你调参Yolo v5 (v6.2)(推理)🌟强烈推荐
- 手把手带你调参Yolo v5 (v6.2)(训练)🚀
- 手把手带你调参Yolo v5 (v6.2)(验证)
- 如何快速使用自己的数据集训练Yolov5模型
- 手把手带你Yolov5 (v6.2)添加注意力机制(一)(并附上30多种顶会Attention原理图)🌟强烈推荐🍀新增8种
- 手把手带你Yolov5 (v6.2)添加注意力机制(二)(在C3模块中加入注意力机制)
- Yolov5如何更换激活函数?
- Yolov5如何更换BiFPN?
- Yolov5 (v6.2)数据增强方式解析
- Yolov5更换上采样方式( 最近邻 / 双线性 / 双立方 / 三线性 / 转置卷积)
- Yolov5如何更换EIOU / alpha IOU / SIoU?
- Yolov5更换主干网络之《旷视轻量化卷积神经网络ShuffleNetv2》
- YOLOv5应用轻量级通用上采样算子CARAFE
- 空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC🚀
- 用于低分辨率图像和小物体的模块SPD-Conv
- GSConv+Slim-neck 减轻模型的复杂度同时提升精度🍀
- 头部解耦 | 将YOLOX解耦头添加到YOLOv5 | 涨点杀器🍀
- Stand-Alone Self-Attention | 搭建纯注意力FPN+PAN结构🍀
- YOLOv5模型剪枝实战🚀
- YOLOv5知识蒸馏实战🚀
- YOLOv7知识蒸馏实战🚀
- 改进YOLOv5 | 引入密集连接卷积网络DenseNet思想 | 搭建密集连接模块🍀
有问题欢迎大家指正,如果感觉有帮助的话请点赞支持下👍📖🌟
本文转载自: https://blog.csdn.net/weixin_43694096/article/details/125416120
版权归原作者 迪菲赫尔曼 所有, 如有侵权,请联系我们删除。
版权归原作者 迪菲赫尔曼 所有, 如有侵权,请联系我们删除。