

ChatGPT 在全世界范围内风靡一时,我现在每天都会使用 ChatGPT 帮我回答几个问题,甚至有的时候在一天内我和它对话的时间比和正常人类对话还要多,因为它确实“法力无边,功能强大”。

ChatGPT 可以帮助我解读程序,做翻译,提供思路等等。
所以我就很好奇 ChatGPT 是怎么训练得到的,怀揣着好奇心,我带着大家一探究竟。
当然,ChatGPT 的论文还没有正式发布,想要完美解读它现在是不可能的,不过我们知道 ChatGPT 和 Open AI 的另一项工作 InstructGPT 息息相关。
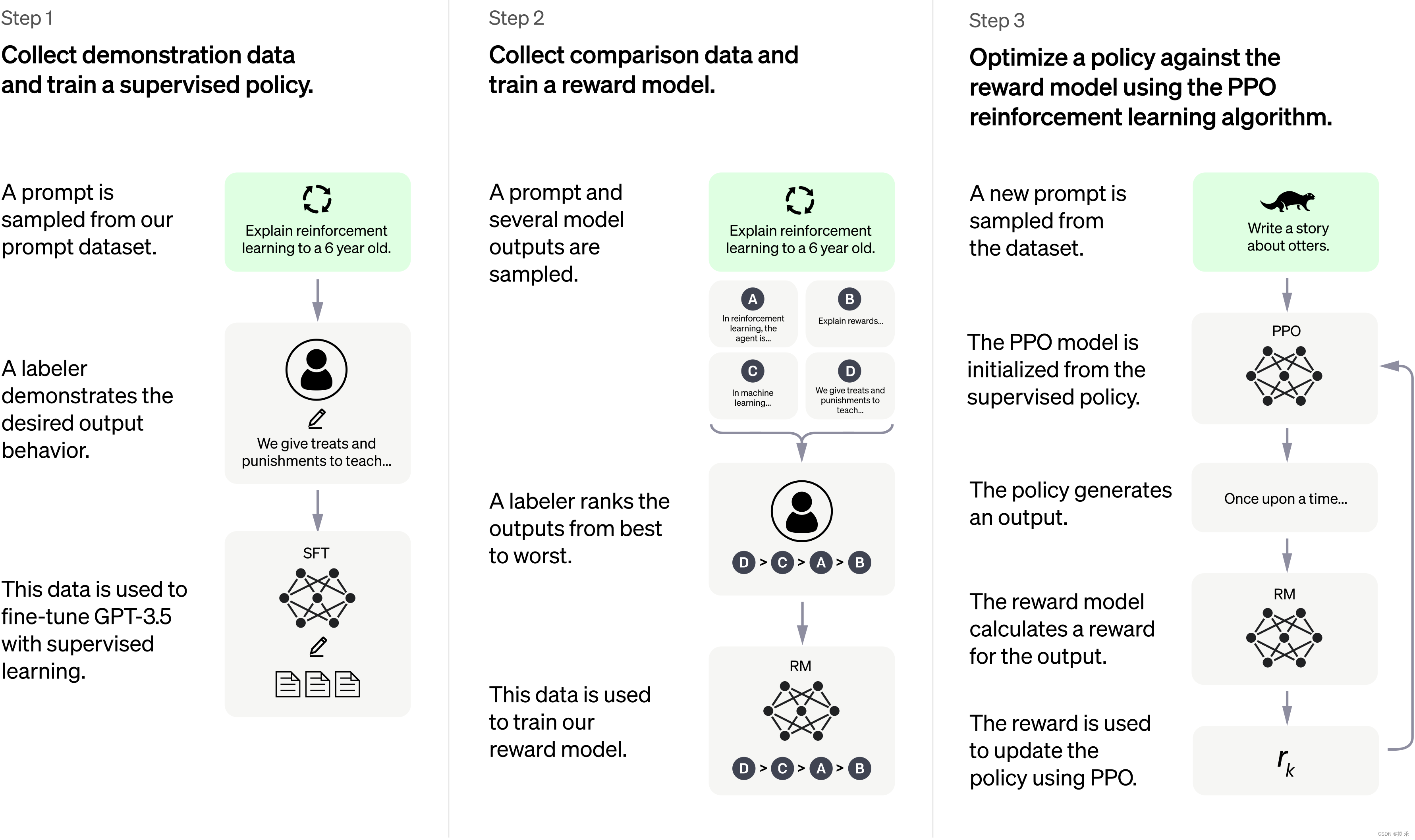
这是 ChatGPT 官网上面的模型训练过程。
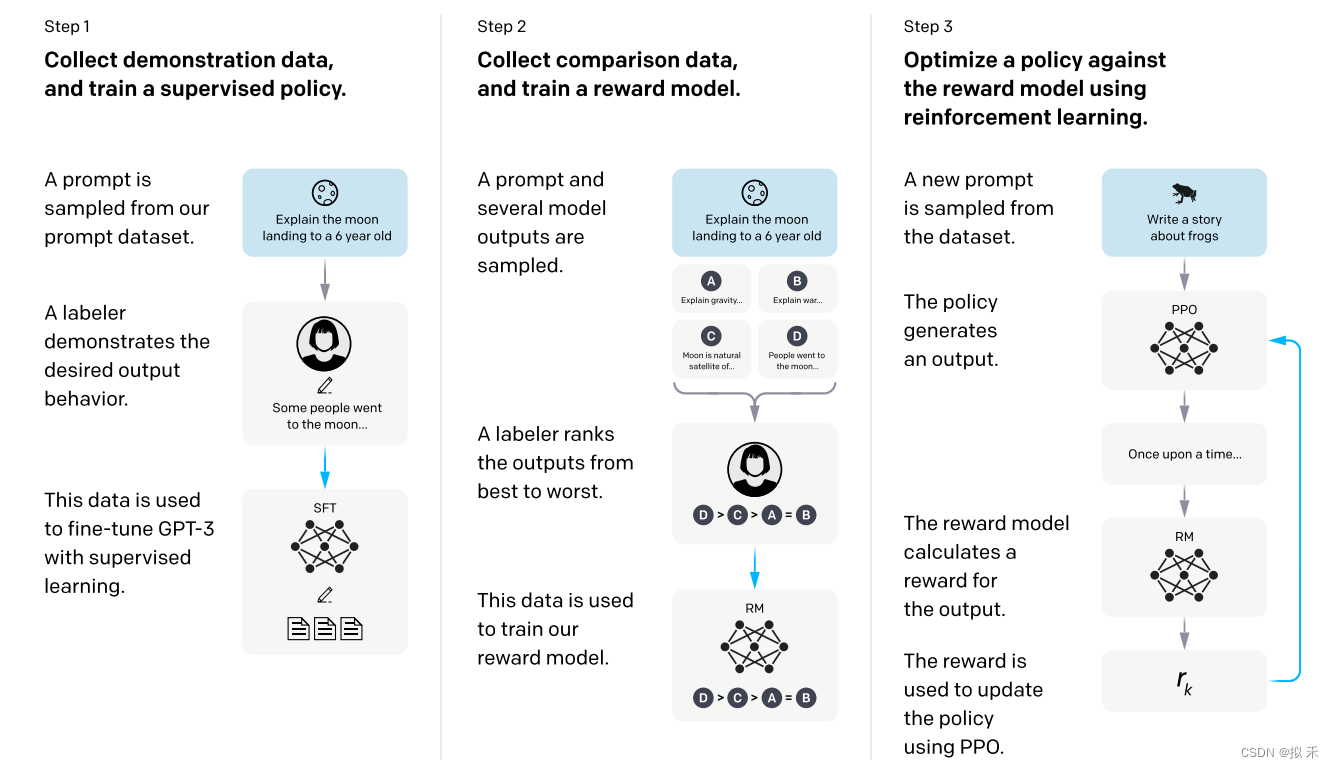
这是 InstructGPT 论文中的模型训练过程。
对比这两张图片,不能说一模一样,只能说完全一致。
所以我们就按照 InstructGPT 的论文讲一讲 ChatGPT 吧。
1. 学习文字接龙🐉
GPT (Generative Pre-trained Transformer) 模型就是在海量的文本数据上学习文字接龙,通过训练掌握基于前文内容生成后续文本的能力。这样的训练不需要人类标注数据(自监督学习),只需要给一段话的上文同时把下文遮住,将 GPT 模型的回答与语料中下文的内容做对比,进行优化。
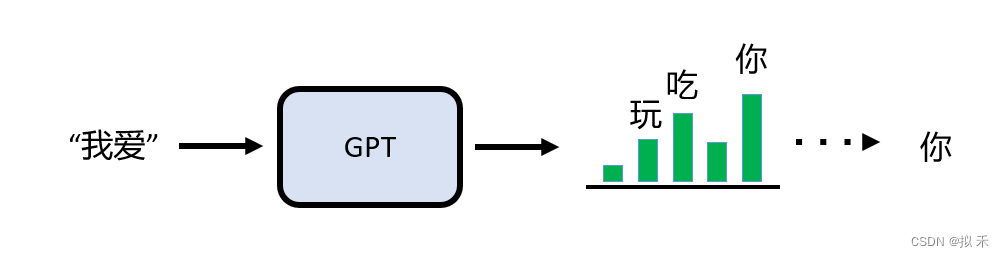
如上图所示,我们输入“我爱”让 GPT 做文字接龙,绿色柱子的高低理解为输出概率的大小,GPT 的输出最有可能是“你”,当然也可能是“吃”或“玩”。
GPT 的输出通常是通过概率采样得到的。在生成文本时,模型根据前面的文本内容和当前的上下文,计算每个可能的输出单词的概率分布。然后,模型会根据这个概率分布对下一个单词进行采样,得到最终的输出单词。在采样的过程中,模型通常使用一种称为 “softmax” 的函数来转换概率分布,从而确保所有可能的输出单词的概率总和为1。
由于采样的过程是基于随机性的,因此即使提供相同的输入和上下文,模型生成的文本输出也可能会有所不同。使用概率采样可以产生更有趣、更有意思的文本输出。这就可以解释为什么 ChatGPT 对于相同的问题往往会有不一样的答案,当然,概率采样也可能会导致一些质量较低的输出,例如语法错误、重复和不相关的单词。
2. 人类老师的引导👮
只是让 GPT 自己做自监督的文字接龙是有局限性的,因为机器是没有感情的,因为 GPT 不知道什么样的答案是有效的,所以需要人类力量的介入,引导 GPT 生成有用的答案。
- 首先,我们从问题数据集(prompt dataset)中挑出一些问题。
- 让真正的人类(labeler)给出这些问题的正确答案。
- 这样就形成了有标签的数据集,这些数据用于微调 GPT-3.5,这个过程也称作 supervised fine-tuning (SFT)
3. 模仿人类老师的喜好📊
可是人类的力量也是有限的,我们不可能让人类老师给出所有问题的答案,但是我们可以给 GPT 生成的答案进行评分,这就相对轻松很多了。
- 比如,我们让刚刚训练好的 SFT 模型回答相同的问题四次,这样就产生了四个不同的答案 A、B、C、D 。
- 然后人工对这些答案进行评分或者说是评级(rank),比如 D > C > A = B 。
- 这样就又形成了一部分数据来训练 reward model(RM),从而训练出一个符合人类评价标准的 Reward 模型。
- 这样下次 GPT 生成答案就不需要人工评分了,直接把答案放到 Reward 模型中去就可以自动判断答案的好坏了。
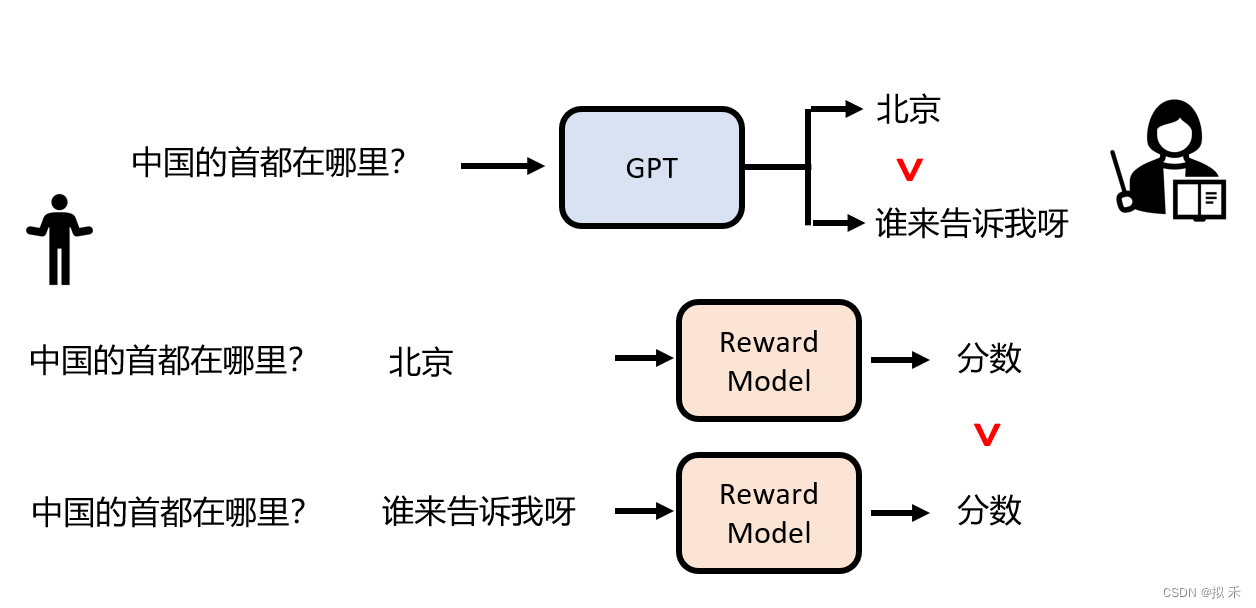
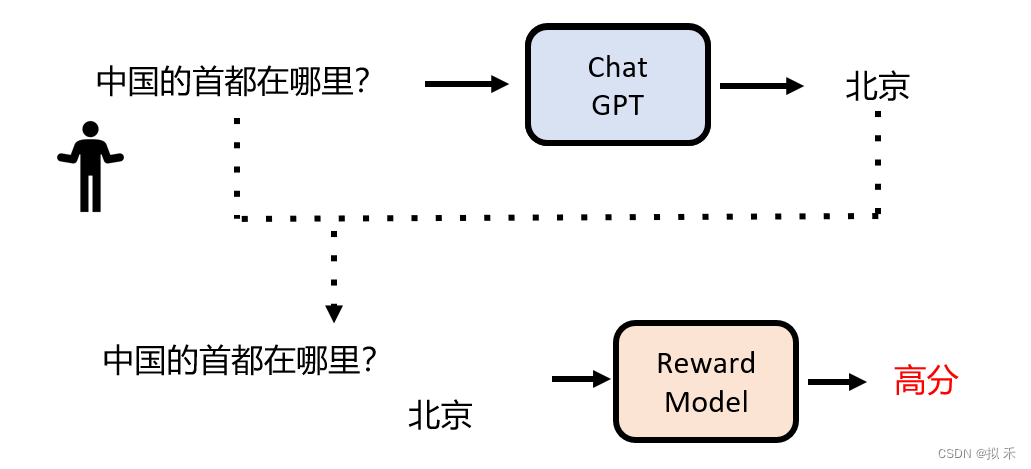
- 如下图所示,对于相同问题的不同答案,Reward Model 学习到了在合理的答案上面打“高分”,在不合理的答案上打“低分”。
4. 强化学习💪
根据 Reward Model 的打分结果,继续优化 SFT 模型。
使用强化学习的技术调整 GPT 模型参数,使 GPT 生成的答案通过 Reward Model 可以得到最高的 Reward,重复这个过程,ChatGPT 就训练出来了。
5. RLHF👏
所以 ChatGPT 是一种通过 RLHF 训练得到的语言模型,Reinforcement Learning from Human Feedback (RLHF) 是一种基于人类反馈的强化学习方法,它通过与人类交互来获得任务的奖励信号,从而实现任务的学习。
RLHF 通过与人类交互来获得任务的奖励信号(Reward),并通过基于梯度的强化学习算法来优化策略,实现任务的学习。与传统的强化学习方法相比,RLHF不需要为任务定义奖励函数,因此更具有实际应用的价值。
6. 使用ChatGPT做个总结🐹
- ChatGPT是一种基于神经网络的自然语言处理模型,它可以生成类似于人类语言的对话,并被广泛用于聊天机器人、智能客服等应用领域。该模型使用了预训练的方式进行训练,可以自动学习语言的规则和模式,从而能够生成自然流畅的对话。
- ChatGPT在社会中产生了广泛的影响。首先,它为人工智能在自然语言处理领域的应用开辟了新的道路。它可以帮助人们更加便捷地获取信息、解决问题、进行娱乐等,进一步提高了人们的生活质量。其次,它也推动了人工智能技术的发展和普及,为人工智能技术在更多领域的应用提供了借鉴和参考。
- 未来,ChatGPT在技术上还有很大的发展空间。一方面,可以通过增加模型的深度和复杂度,来提高模型的精度和泛化能力。另一方面,可以通过结合其他技术,如图像识别、情感分析等,进一步提升模型的功能和性能。此外,ChatGPT也可以与其他技术结合,如语音识别、自然语言生成等,来实现更加人性化的交互方式,为人们提供更加便捷的服务和体验。
- 总之,ChatGPT是一种重要的自然语言处理技术,对社会产生了广泛的影响,未来也有着广阔的发展前景。它为人们提供了更加便捷、高效、智能化的服务和体验,有望在不久的将来成为人们日常生活中必不可少的一部分。同时,ChatGPT的发展也将推动人工智能技术的发展,为人们带来更多的福利和发展机会。
版权归原作者 拟 禾 所有, 如有侵权,请联系我们删除。