
TASKONOMY Dataset
taskonomy 官网Taskonomy
该数据集包括来自500多座建筑的450多万张来自室内场景的图像。涵盖了26个视觉领域的常见任务,包括但不限于:2D边缘检测、平面法线、拼图、自动上色、房间布局构建、物体分类、场景预测 。每一张图片有这26个任务的所有标签,数据集的总大小为11.16 TB。
对于非语义类标签,作者采用程序自动计算标签;对于语义类标签,作者采用知识提炼,用已有的模型产生相关语义标签。例如:使用resnet-151(Image-Net 中100 类) 产生 sementic objects任务的标签。最后经过人工检测,发现得到的语义标签错误率不超过7%。

Taskonomy tree:
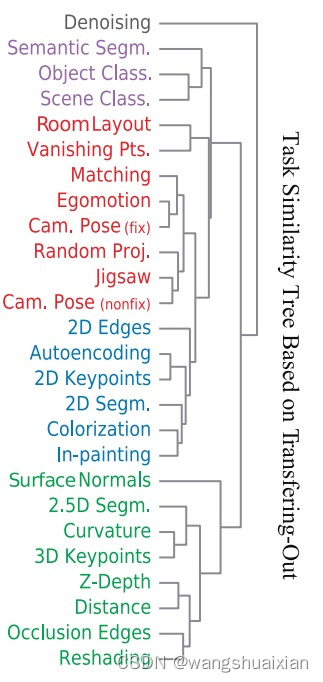
单张图像任务包括:
Autoencoder Curvatures Colorization Denoising-Autoencoder
Depth Edge-2D Edge-3D Euclidean-Distance
Inpainting Jigsaw-Puzzle Keypoint-2D Keypoint-3D
Object-Classification Reshading Room-Layout Scene-Classification
Segmentation-2D Segmentation-3D Segmentation-Semantic Surface-Normal
Vanishing-Point
多张图像任务包括:
Pairwise-Nonfixated-Camera-Pose Pairwise-Fixated-Camera-Pose
Triplet-Fixated-Camera-Pose Point-Matching
Data structure:
class_object/
Object classification (Imagenet 1000) annotation distilled from ResNet-152
class_scene/
Scene classification annotations distilled from PlaceNet
depth_euclidean/
Euclidian distance images.
Units of 1/512m with a max range of 128m.
depth_zbuffer/
Z-buffer depth images.
Units of 1/512m with a max range of 128m.
edge_occlusion/
Occlusion (3D) edge images.
edge_texture/
2D texture edge images.
keypoints2d/
2D keypoint heatmaps.
keypoints3d/
3D keypoint heatmaps.
nonfixated_matches/
All (point', view') which have line-of-sight and a view of "point" within the camera frustum
normal/
Surface normal images.
127-centered
points/
Metadata about each (point, view).
For each image, we keep track of the optical center of the image.
This is uniquely identified by the pair (point, view).
Contains annotations for:
Room layout
Vanishing point
Point matching
Relative camera pose esimation (fixated)
Egomotion
And other low-dimensional geometry tasks.
principal_curvature/
Curvature images.
Principal curvatures are encoded in the first two channels.
Zero curvature is encoded as the pixel value 127
reshading/
Images of the mesh rendered with new lighting.
rgb/
RGB images in 512x512 resolution.
rgb_large/
RGB images in 1024x1024 resolution.
segment_semantic/
The semantic segmentation classes are a subset of MS COCO dataset classes. The annotations are in the form of pixel-wise object labels and are distilled from [FCIS](https://arxiv.org/pdf/1611.07709.pdf), so they should be viewed as pseudo labels, as opposed to labels done individually by human annotators (a more accurate annotation set will be released in the near future).
The annotations have 18 unique labels, which include 16 object classes, a "background" class, and an "uncertain" class. "Background" means the FCIS classifiers were certain that those pixels belong to none of the 16 objects in the dictionary. "Uncertain" means the classifiers had too low confidence for those pixels to mark them as either an object or the background -- so they could belong to any class and they should be masked during learning to not contribute to the loss in a positive or negative way.
The classes "0" and "1" mark "uncertain" and "background" pixels, respectively. The rest of the classes are specified in [this file](https://github.com/StanfordVL/taskonomy/blob/master/taskbank/assets/web_assets/pseudosemantics/coco_selected_classes.txt).
segment_unsup2d/
Pixel-level unsupervised superpixel annotations based on RGB.
segment_unsup25d/
Pixel-level unsupervised superpixel annotations based on RGB + Normals + Depth + Curvature.
Decoder loss:

taskonomy 数据集下载:
(1)安装 omnidata
sudo apt-get install aria2
pip install omnidata-tools
Taskonomy数据集是Omnidata starter数据集(Omnidata:14M图像,包括室内、室外和聚焦对象的场景)的子集。用下面命令只下载taskonomy子数据集:
omnitools.download all --components taskonomy --subset fullplus \
--dest ./omnidata_starter_dataset/ \
--connections_total 40 --agree
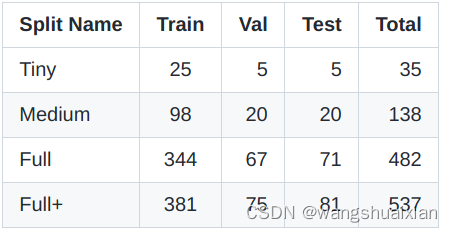
taskonomy 数据集提供标准的训练/验证/测试拆分,以标准化未来的基准测试。考虑到完整数据集的大容量,提供了4个等级(tiny、medium、full、fullplus)标准的数据集拆分,大小越来越大,用户可以根据其存储和计算资源使用这些子数据集。Full+包含Full,Full包含Medium,Medium包含Tiny。下表显示了每个分区中的建筑数量。
下载链接https://github.com/StanfordVL/taskonomy/raw/master/data/assets/splits_taskonomy.zip
下载taskonomy Tiny数据集
omnitools.download all --components taskonomy --subset tiny \
--dest ./omnidata_starter_dataset/ \
--connections_total 40 --agree
Taskonomy任务详解
taskonomy/task_definitions.pdf at master · StanfordVL/taskonomy · GitHub
- Autoencoding 自动编码
PCA是一种广泛使用的方法,通过查找一个低维度的潜在表示来理解数据。自动编码是PCA的一种非线性概括,它最初是在迁移学习中提出的:通过自动编码预先训练来提高下游性能。
- Colorization着色
着色需要拍摄灰度图像并预测原始颜色。 这是一项无人监督的任务,但也是一种语义感知的任务。 例如,一旦确定了水果,预测水果的颜色就很简单。
- Context Encoding 上下文编码
背景编码首先由Pathak等人介绍[26]并且是自动编码的一种形式,其中大部分输入被掩盖在模型中。 为了填充遮挡区域,模型必须推断场景几何和语义。 与着色类似,它是一种无监督但仍然是语义的任务。
- Content Prediction 内容预测
Context Encoding的一个有辨别力的版本,Jigsaw [25]要求网络解密输入图像的置换平铺(permuted tiling)。
- Curvature Estimation 曲率估计
基于曲率的特征非常适合识别,因为它们在刚性变换下是不变的。 曲率在视觉处理中非常重要 - 因此猕猴(Macaque)视觉皮层具有专用的曲率处理区域[41]。
- Denoising 降噪
对于类似的输入进行去燥来获得相似的representations,但是通过自动编码学习的representations对输入中的扰动过于敏感。降噪【36】(自动编码)通过将微扰动输入映射到未扰动输入,来鼓励有限的不变性。
- Depth Estimation, Euclidean 欧几里得深度估计
深度估计是一项重要任务,可用于检测与障碍物和感兴趣物品的接近程度。 It is also a useful intermediate step for agents to localize themselves in 3D space(在3D空间定位物体的有用一步)。 欧几里得深度是指从每个像素到相机光学中心的距离。
- Depth Estimation, Z-Buffer
与欧几里德深度估计相反,研究人员通常使用Z-Buffer深度,其被定义为到相机平面的距离。 这不是人类通常感知深度的方式,应用它是因为这是标准公式,我们所有深度派生的任务都是从Z-Buffer派生的。
- Edge Detection(2D)边缘检测
边缘检测在历史上是计算机视觉中的基本任务。 边缘通常用作中间representations或作为较大处理管道(a larger processing pipeline)中的特征。 我们包括没有非极大值抑制的Canny边缘检测器的输出(以使任务可以通过神经网络学习)。
- Edge Detection(3D)
与2D边缘相反,我们将3D边缘定义为“遮挡边缘”,或者前景中的对象遮挡其后面的东西的边缘。 2D边缘响应纹理的变化,但3D边缘是仅依赖于3D几何体和对颜色、光照不变的特征。
- Keypoint Detection (2D)关键点检测
关键点检测在计算机视觉中具有悠久的历史,并且对许多任务都很有用。 关键点算法通常由两部分组成,包括关键点检测器和一些局部补丁描述符,它们在多个图像中是不变的[20,3,28]。 2D关键点检测鼓励网络识别图像的本地重要区域,并且点匹配鼓励网络学习特征描述符。 在更大的视觉管道中识别关键点通常仍是第一步。 我们使用SURF [3]的输出(在非最大抑制之前)作为我们的ground-truth。
- Keypoint Detection (3D)
3D关键点类似于2D关键点,除了它们是从3D数据派生的,因此考虑了场景几何。它们通常对纹理等信息(but possibly distracting)没反应[44, 45, 21, 42, 14]。 我们使用NARF的输出[35]算法(在非最大抑制之前)作为我们的3D关键点ground-truth。
- Point Matching
为点匹配训练的深度网络学习特征描述符,证明对downstream tasks有用。 点匹配应用于细粒度分类和物体识别三维重建和运动结构,宽基线匹配,SLAM 和视觉测距。
- Relative Camera Pose Estimation, Non-Fixated 相对相机姿态估计,非固定
Held和Hein 著名的“小猫旋转木马(Kitten Carousel)”实验表明,采取行动对强烈的感知至关重要。 对于具有相同光学中心的两个不同视图,我们尝试预测它们之间的6-DOF相对相机姿态(偏航,俯仰,滚动,xyz平移)。
- Relative Camera Pose Estimation, Triplets (Egomotion)
视频是计算机视觉中常见的研究对象,它们提供具有高冗余度的密集数据。 因此,我们包括具有固定中心点的输入三元组的相机姿态匹配。 通过三个图像,模型具有更高的匹配点的能力,以实现精确定位。
Reshading
推断场景几何的一种方法是使用固有图像分解I = A·S的“阴影形状”,其中S是通过光照和深度参数化的阴影函数。 这种分解被认为在人类视觉感知中很有用。 按如下方式定义Reshading:给定RGB图像,标签是the shading function S,其由在相机原点处具有单个点光而得到,并且S乘以恒定的固定反照率。Room Layout Estimation 房间布局估算
估计和对齐3D边界框是一个中级任务,包括消失点估计这个子问题,并且具有机器人导航,场景重建[和增强现实的应用。 在LSUN房间布局挑战中使用了房间布局估计的变体,但是当存在相机滚动或者没有房间角落时,该formulation是不适合的。 相反,taskonomy提供了一个无论相机的姿势和视野如何都保持well-defined的formulation。 该任务包括一些语义信息,例如“什么构成房间”,同时还包括场景几何。
- Segmentation, Unsupervised (2D)) 分割,无监督
格式塔(Gestalt)心理学家提出了将分组作为一种机制的原则,通过这种机制,人类学会将世界视为一组连贯的对象[38]。 规范化切割[33]是将图像分割成感知相似组的一种方法,我们在字典中包含这个格式塔任务。
- Segmentation, Unsupervised (2.5D))
Segmentation2.5D使用与2D相同的算法,但是标签是从RGB图像,对齐的深度图像和对齐的表面法线图像联合计算的。 因此,2.5D分割不仅适用于the world as it seems(在RGB图像中),而且适用于the world as it is(ground-truth 3D)。 2.5D分割包含关于场景几何的信息,该场景几何不直接存在于RGB图像中,但是人类容易推断。
- Surface Normal Estimation 表面法线估计
表面法线估计被认为对空间认知至关重要。 例如,对象只能放置在具有向上法线的表面上。 即使对于运动,具有水平面法线的点表示它不容易穿过。 曲面法线直接从3D网格计算。
- Vanishing Point Estimation 消失点估计
透视(perspective)的结果是,消失点提供了关于场景几何的有用信息并且得到了很好的研究。 消失点证明在曼哈顿世界特别有用,其中有三个主要的消失点对应于X,Y和Z轴。 这种假设通常在城市环境中得到满足。 对于每个模型,我们分析地找到这三个消失点并将它们作为标签包含在内。
- Semantic Learning through Knowledge distillation 通过知识蒸馏进行语义学习
虽然taskonomy数据集不包含语义注释,但语义理解是现代计算机视觉的一个重要组成部分。 因此,taskonomy通过知识蒸馏添加伪语义注释。 从ImageNet 和MS-COCO 训练的最先进模型中提取知识,通过使用它们来注释taskonomy数据集,然后使用这些注释监督模型。
版权归原作者 wangshuaixian 所有, 如有侵权,请联系我们删除。