
本文基于Alpaca提供了一套LLaMA-7B模型在阿里云ECS上进行指令微调的训练方案,最终可以获得性能更贴近具体使用场景的语言模型。
背景信息
LLaMA(Large Language Model Meta AI )是Meta AI在2023年2月发布的开放使用预训练语言模型(Large Language Model, LLM),其参数量包含7B到65B的集合,并仅使用完全公开的数据集进行训练。LLaMA的训练原理是将一系列单词作为“输入”并预测下一个单词以递归生成文本。
LLM具有建模大量词语之间联系的能力,但是为了让其强大的建模能力向下游具体任务输出,需要进行指令微调,根据大量不同指令对模型部分权重进行更新,使模型更善于遵循指令。指令微调中的指令简单直观地描述了任务,具体的指令格式如下:
{
"instruction": "Given the following input, find the missing number",
"input": "10, 12, 14, __, 18",
"output": "16"
}
Alpaca是一个由LLaMA-7B模型进行指令微调得到的模型,其训练过程中采用的通过指令对LLaMA-7B模型进行小规模权重更新的方式,实现了模型性能和训练时间的平衡。
本文基于Alpaca提供了一套LLaMA-7B模型,基于DeepSpeed进行指令微调训练,并使用AIACC加速训练。AIACC包括ACSpeed和AGSpeed两个加速器。
加速器
说明
相关文档
ACSpeed
AIACC-ACSpeed(简称ACSpeed)是阿里云自研的AI训练加速器,在AI框架层、集合算法层和网络层上分别实现了与开源主流分布式框架的充分兼容,并实现了软硬件结合的全面优化。ACSpeed具有其显著的性能优势,在提高训练效率的同时能够降低使用成本,可以实现无感的分布式通信性能优化。
什么是AI分布式训练通信优化库AIACC-ACSpeed
AGSpeed
AIACC-AGSpeed(简称AGSpeed)是阿里云推出的一个基于PyTorch深度学习框架研发的计算优化编译器,用于优化PyTorch深度学习模型在阿里云GPU异构计算实例上的计算性能,可以实现计算优化。
什么是计算优化编译器AIACC-AGSpeed
重要
- 阿里云不对第三方模型“llama-7b-hf”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
- 您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
准备工作
操作前,请先在合适的地域和可用区下创建VPC和交换机。
- 本文使用ecs.gn7i-c32g1.32xlarge规格的ECS实例进行训练,仅部分地域可用区支持该实例规格,具体请参见ECS实例规格可购买地域。
- 关于如何创建VPC和交换机,请参见创建专有网络和创建交换机。
创建ECS实例
控制台方式
FastGPU方式
- 前往实例创建页。
- 按照向导完成参数配置,创建一台ECS实例。需要注意的参数如下。更多信息,请参见自定义购买实例。- 实例:规格选择ecs.gn7i-c32g1.32xlarge(包含4卡NVIDIA A10 GPU)。
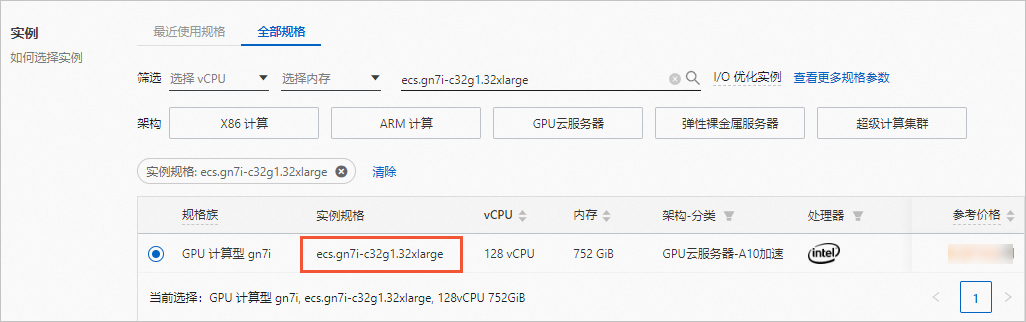 - 镜像:使用云市场镜像,名称为aiacc-train-solution,该镜像已部署好训练所需环境。您可以直接通过名称搜索该镜像,版本可选择最新版本。
- 镜像:使用云市场镜像,名称为aiacc-train-solution,该镜像已部署好训练所需环境。您可以直接通过名称搜索该镜像,版本可选择最新版本。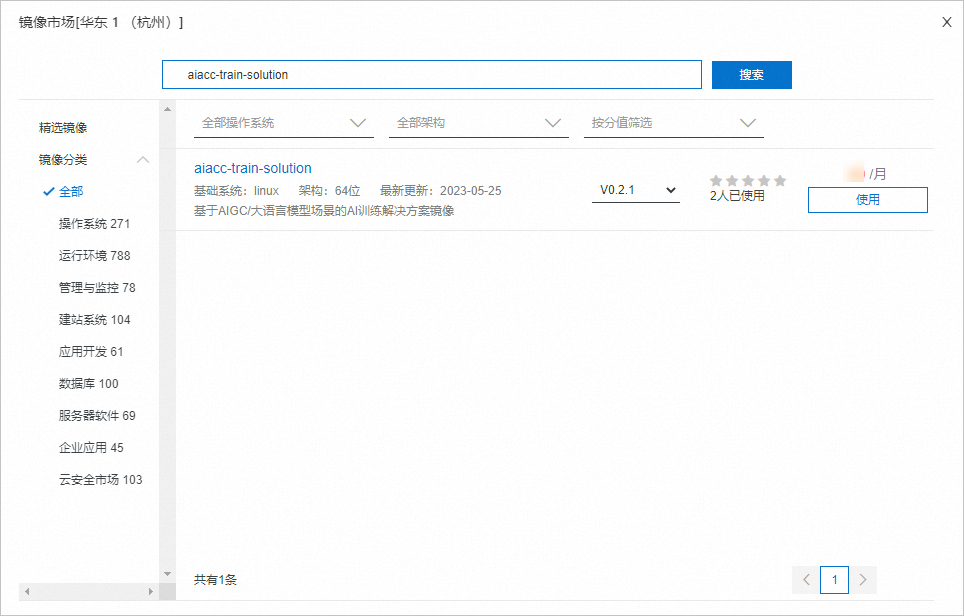 说明您也可以选择公共镜像(如CentOS 7.9 64位),后续手动部署环境。- 公网IP:选中分配公网IPv4地址,按需选择计费模式和带宽。本文使用按流量计费,带宽峰值为5 Mbps。
说明您也可以选择公共镜像(如CentOS 7.9 64位),后续手动部署环境。- 公网IP:选中分配公网IPv4地址,按需选择计费模式和带宽。本文使用按流量计费,带宽峰值为5 Mbps。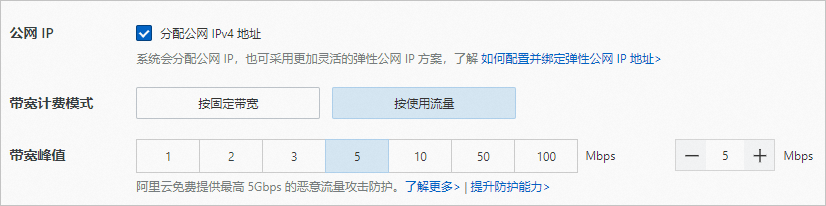
- 添加安全组规则。在ECS实例所需安全组的入方向添加一条规则,开放7860端口,用于访问WebUI。具体操作,请参见添加安全组规则。以下示例表示向所有网段开放7860端口,开放后所有公网IP均可访问您的WebUI。您可以根据需要将授权对象设置为特定网段,仅允许部分IP地址访问WebUI。

- 使用Workbench连接实例。如果使用示例的云市场镜像进行测试,由于环境安装在
/root目录下,连接实例时需使用root用户。关于如何连接ECS实例,请参见通过密码或密钥认证登录Linux实例。
(可选)手动部署环境
启动训练
- 下载tmux并创建一个tmux session。
yum install tmuxtmux说明训练耗时较长,建议在tmux session中启动训练,以免ECS断开连接导致训练中断。 - 进入Conda环境。
conda activate llama_train - 获取llama-7b-hf预训练权重。1. 下载llama-7b权重。
cd /root/LLaMAgit lfs installgit clone https://huggingface.co/decapoda-research/llama-7b-hf2. 修复官方代码Bug。sed -i "s/LLaMATokenizer/LlamaTokenizer/1" ./llama-7b-hf/tokenizer_config.json - 创建并设置DeepSpeed配置文件。
cd LLaMA/stanford_alpaca``````cat << EOF | sudo tee ds_config.json{ "zero_optimization": { "stage": 3, "contiguous_gradients": true, "stage3_max_live_parameters": 0, "stage3_max_reuse_distance": 0, "stage3_prefetch_bucket_size": 0, "stage3_param_persistence_threshold": 1e2, "reduce_bucket_size": 1e2, "sub_group_size": 1e8, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "stage3_gather_16bit_weights_on_model_save": true }, "communication":{ "prescale_gradients": true }, "fp16": { "enabled": true, "auto_cast": false, "loss_scale": 0, "initial_scale_power": 32, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1 }, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false, "zero_force_ds_cpu_optimizer": false}EOF - (可选)如果使用多台ECS实例进行训练,需配置hostfile。本文使用一台ECS实例进行训练,可跳过此步骤。如下示例表示配置两台ECS实例(GPU总数为8)时,需要填入每台ECS实例的内网IP和slots,其中slots表示进程数(即GPU数量)。
cat > hostfile <<EOF{private_ip1} slots=4{private_ip2} slots=4EOF - 启动训练。启动训练的命令脚本如下,alpaca_data.json为指令数据集文件,
$MASTER_PORT请替换为2000-65535之间的随机端口号。deepspeed --master_port=$MASTER_PORT --hostfile hostfile \train.py \--model_name_or_path ../llama-7b-hf \--data_path ./alpaca_data.json \--output_dir ./output \--report_to none \--num_train_epochs 1 \--per_device_train_batch_size 2 \--per_device_eval_batch_size 2 \--gradient_accumulation_steps 8 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 400 \--save_total_limit 2 \--learning_rate 2e-5 \--weight_decay 0. \--warmup_ratio 0.03 \--lr_scheduler_type "cosine" \--logging_steps 1 \--deepspeed ./ds_config.json \--tf32 False \--bf16 False \--fp16启动训练后预期返回如下: 说明训练完成大概需要7小时左右,在tmux session中进行训练的过程中,如果断开了ECS连接,重新登录ECS实例后执行
说明训练完成大概需要7小时左右,在tmux session中进行训练的过程中,如果断开了ECS连接,重新登录ECS实例后执行tmux attach命令即可恢复tmux session,查看训练进度。
效果展示
查看WebUI推理效果
- 查看原生预训练模型的推理效果。1. 进入Conda环境。
conda activate llama_train2. 使用原生checkpoint文件进行推理。cd /root/LLaMA/text-generation-webuiln -s /root/LLaMA/llama-7b-hf ./models/llama-7b-hf3. 启动WebUI服务。python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf --listen预期返回: 4. 打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如
4. 打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如101.200.XX.XX:7860。5. 在Input框中输入问题(建议输入英语),单击Generate,在Output框获取结果。原生的预训练模型不能很好理解指令。示例如下: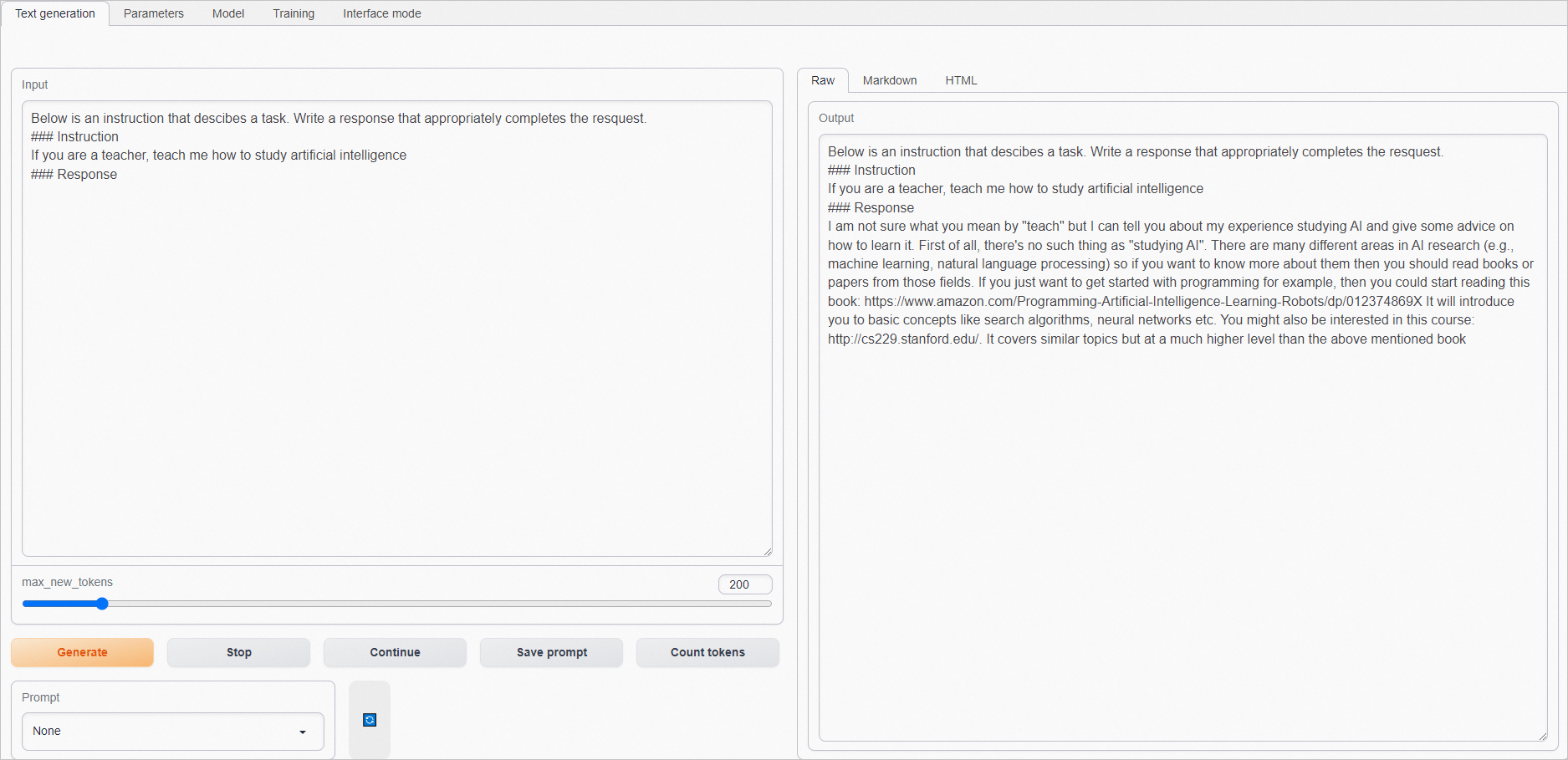
- 等待训练完成后,查看指令微调后模型的推理效果。1. 重新连接ECS实例。2. 进入Conda环境。
conda activate llama_train3. 使用训练完成的checkpoint文件进行推理。cd /root/LLaMA/text-generation-webuiln -s /root/LLaMA/stanford_alpaca/output/checkpoint-800 ./models/llama-7b-hf-8004. 启动WebUI服务。python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf-800 --listen预期返回: 5. 打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如
5. 打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如101.200.XX.XX:7860。6. 单击Model页签,在Model模型列表中,选择指令微调后模型(如本文的llama-7b-hf-800)。当页面右下角显示Successfully loaded llama-7b-hf-800时,说明该模型已加载完成。说明****llama-7b-hf-*后面的数字代表微调的step数,一般情况下,选择微调step数越大的模型,效果越好。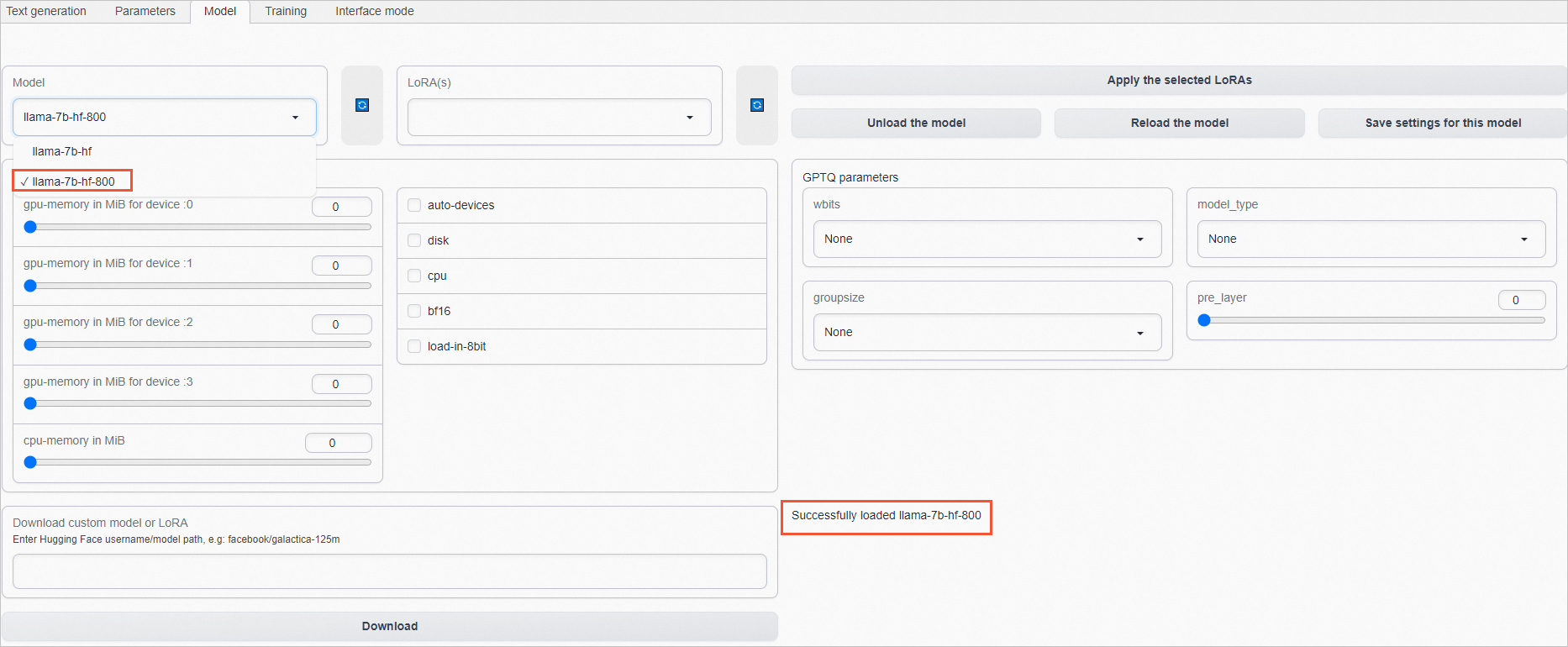 7. 在Input*框中输入问题(建议输入英语),单击*Generate,在Output框获取结果。指令微调后的模型能更好地理解指令,并生成更合理的答案。示例如下:
7. 在Input*框中输入问题(建议输入英语),单击*Generate,在Output框获取结果。指令微调后的模型能更好地理解指令,并生成更合理的答案。示例如下: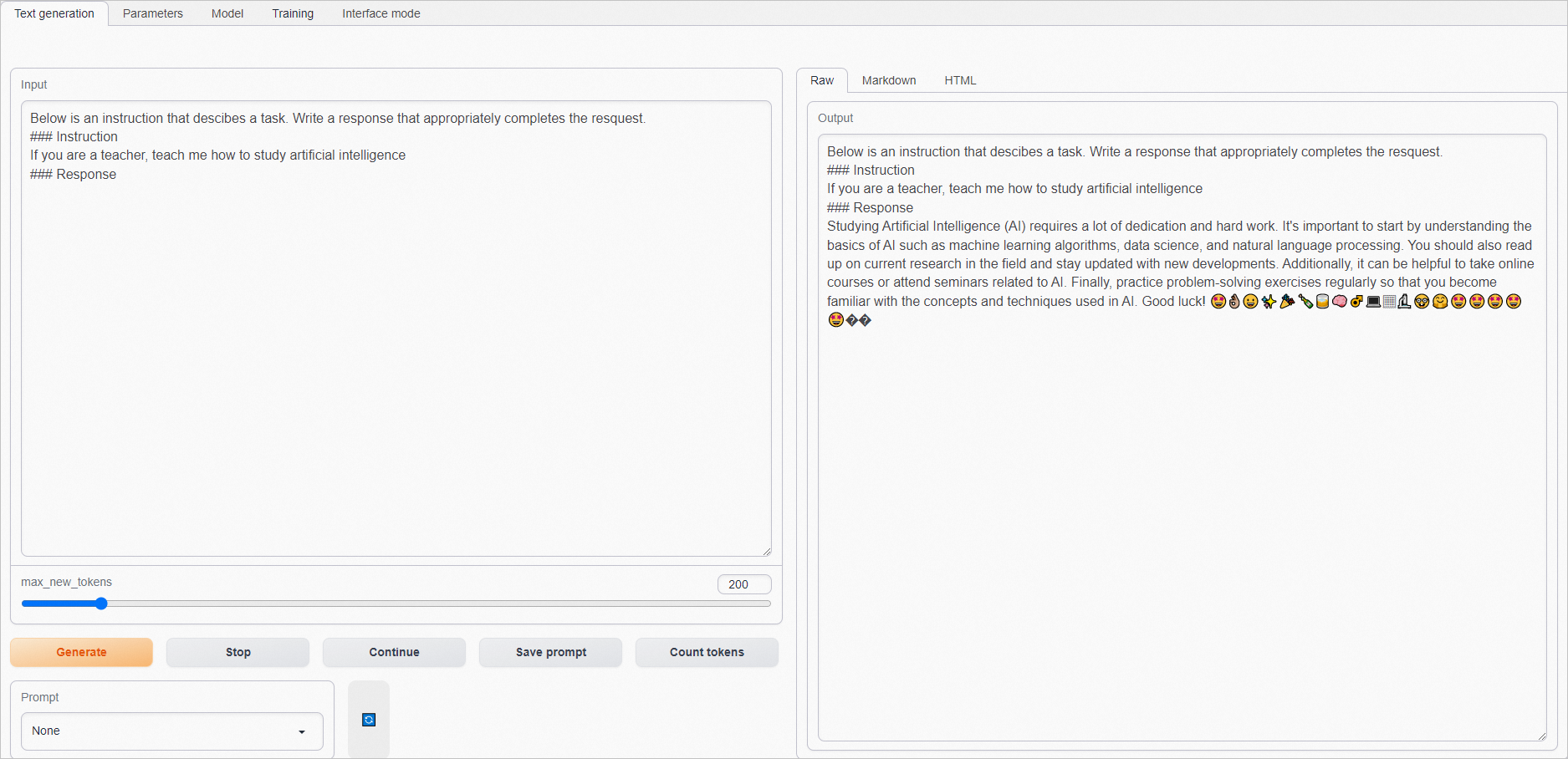
查看AIACC加速效果
以下是使用2台ecs.gn7i-c32g1.32xlarge规格的ECS实例(2*4 NVIDIA A10 GPU),基于DeepSpeed进行训练时,是否启动AIACC的性能对比。s/it代表训练每个iteration的时间,时间越短代表训练速度越快。由下图可以看出启动AIACC后相比原生DeepSpeed提速35%左右。
说明
训练完成后,您可以在
/root/LLaMA/stanford_alpaca/wandb/latest-run/files/output.log
文件中了解性能。
- 使用DeepSpeed进行训练

- 使用DeepSpeed+AIACC进行训练

版权归原作者 segwyang 所有, 如有侵权,请联系我们删除。