
前言
本次分享将带领大家从0到1完成一个图像分类任务的模型训练评估和推理部署全流程,项目将采用以PaddleClas为核心的飞浆深度学习套装进行开发,并总结开发过程中踩过的一些坑,希望对有类似项目需求的同学提供一点帮助。
项目背景和目标
背景:
- 图像分类是计算机视觉的基础,也是其他计算机复杂任务的基础。本次选用的案例来自智慧农业,实现对不同质量桃子的自动分类,从而减轻人工挑拣的负担。
目标:
- 掌握如何基于paddlepaddle深度学习框架完成一个图像分类任务;
- 掌握如何完成模型的训练、评估、预测和部署等深度学习工作过程;
百度AI Studio平台
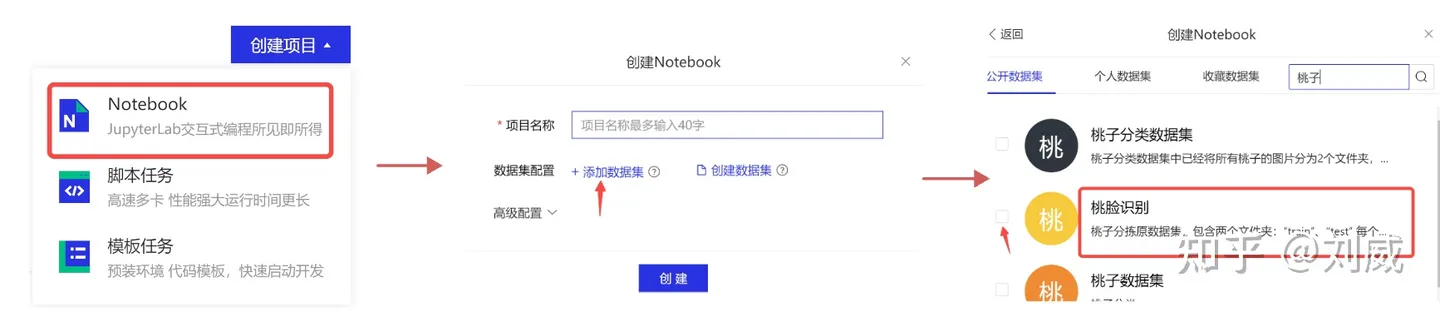
本次实验将采用AI Studio实训平台中的免费GPU资源,在平台注册账号后,点击创建项目-选择NoteBook任务,然后添加数据集,如下图所示,完成项目创建。启动环境可以自行选择CPU资源 or GPU资源,创建任务每天有8点免费算力,推荐大家使用GPU资源进行模型训练,这样会大幅减少模型训练时长。
数据集介绍
本次实验使用的数据集是四个种类桃子,这些桃子被分在四个文件夹中,每一个文件夹的名字就对应着一类桃子。
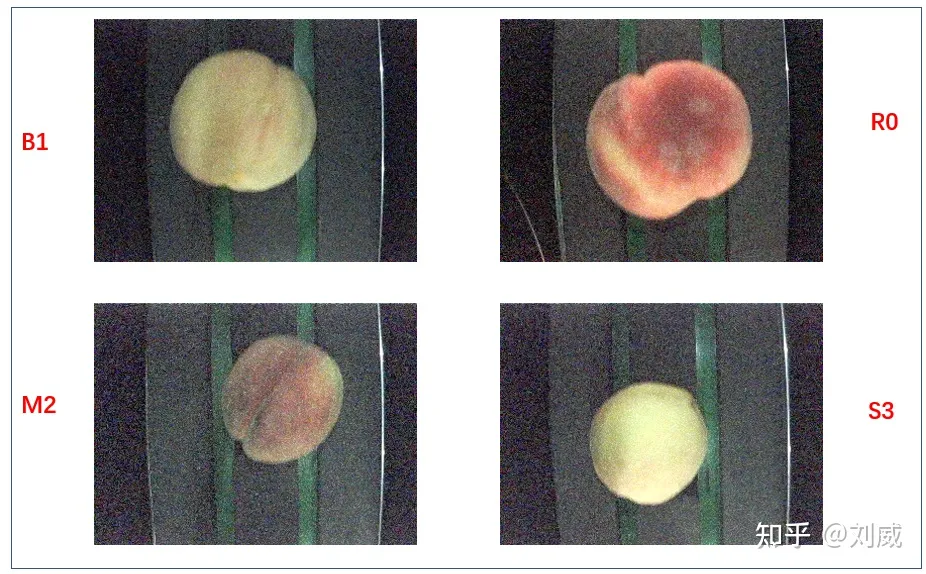
观察发现,这些桃子基本是按照大小、颜色来划分的,本次实验任务就是通过飞浆提供的套件完成一个图像分类任务。
飞浆深度学习开发框架介绍
PaddlePaddle百度提供的开源深度学习框架,其中文名是“飞桨”,致力于为开发者和企业提供最好的深度学习研发体验,国产框架中绝对的榜一大哥!其核心优势是生态完善,目前集成了各种开发套件,覆盖了数据处理、模型训练、模型验证、模型部署等各个阶段的工具。下面简要介绍一下本项目用到的几个核心组件:
- PaddleClas:一个图像识别和图像分类任务的工具集,集成了主流和百度自研的视觉模型和模型训练测试API。
- PaddleServing:将模型部署成一个在线预测服务的库,支持服务端和客户端之间的高并发和高效通信。
- PaddleLite:将模型转换成可以端侧推理的库,比如将模型部署到手机端进行推理。
从零开始开发
PaddleClas完成模型训练
安装PaddleClas
在项目中打开终端,然后运行如下命令:
# (可选)最好在虚拟环境中安装,环境会持久保存在项目中
pip install virtualenv # 安装虚拟环境管理包
virtualenv --python=python3.7 --system venv # 新建虚拟环境
source venv/bin/activate # 切换到新建的虚拟环境
# 安装paddlepaddle,根据云端环境选择cpu版本和gpu版本
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
# 克隆PaddleClas仓库
git clone https://gitee.com/paddlepaddle/PaddleClas.git
# 安装其他依赖
cd PaddleClas/
pip install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
# 编译安装paddleclas
python setup.py install
数据准备
我们需要制作符合PaddleClas框架要求的数据集格式:参考github.com,格式要求如下:
PaddleClas使用 txt 格式文件指定训练集和测试集,以 ImageNet1k 数据集为例,其中 train_list.txt 和 val_list.txt 的格式形如:
# 每一行采用"空格"分隔图像路径与标注
# 下面是 train_list.txt 中的格式样例
train/n01440764/n01440764_10026.JPEG 0
...
# 下面是 val_list.txt 中的格式样例
val/ILSVRC2012_val_00000001.JPEG 65
...
为此我们需要将桃子分类数据集制作上如上的格式:
# 首先将data目录下的数据解压到PaddleClas/dataset目录下
unzip /home/aistudio/data/data103593/data.zip -d /home/aistudio/PaddleClas/dataset/peach_data
cd dataset/peach_data
# 编写generate_dataset.py
python generate_dataset.py # 生成指定格式的train_list.txt val_list.txt test_list.txt
cd ../.. # 返回PaddleClas主目录
其中generate_dataset.py中的代码如下:
import os
train_dir = 'train'
test_dir = 'test'
class_names = os.listdir(train_dir)
id2names = {}
for i, cls in enumerate(class_names):
id2names[cls] = i
# 制作标签对应关系
with open('label_list.txt', 'w') as f:
f.writelines(f'{id} {name}\n' for name, id in id2names.items())
# 制作训练集和验证集
traindata_list = []
valdata_list = []
for name in class_names:
class_images = os.listdir(os.path.join(train_dir, name))
for i, img in enumerate(class_images):
label = id2names[name]
if i%8 == 0:
valdata_list.append(f'{train_dir}/{name}/{img} {label}')
else:
traindata_list.append(f'{train_dir}/{name}/{img} {label}')
with open('train_list.txt', 'w') as f:
f.writelines(f'{data}\n' for data in traindata_list)
with open('val_list.txt', 'w') as f:
f.writelines(f'{data}\n' for data in valdata_list)
# 制作测试集
testdata_list = []
for name in class_names:
class_images = os.listdir(os.path.join(train_dir, name))
for i, img in enumerate(class_images):
label = id2names[name]
testdata_list.append(f'{test_dir}/{name}/{img} {label}')
with open('test_list.txt', 'w') as f:
f.writelines(f'{data}\n' for data in testdata_list)
如上,我们便完成了数据的准备工作,接下来将选用一个model完成模型在该数据集上的训练。
模型训练和评估:
这里我们以选用百度自研的PP-LCNetV2为例,有关该模型的介绍可参考官方文档。
- 下载预训练权重:让模型参数有个好的初始化
wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/legendary_models/PPLCNetV2_base_ssld_pretrained.pdparams
mv PPLCNetV2_base_ssld_pretrained.pdparams output/ # 移到output文件夹
- 修改配置文件:参考ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml
mkdir ppcls/configs/peach
# 复制一份配置文件并根据数据集对应修改
cp ppcls/configs/ImageNet/PPLCNetV2/PPLCNetV2_base.yaml ppcls/configs/peach/
# 需要修改的地方如下
pretrained_model: ./output/PPLCNetV2_base_ssld_pretrained
class_num: 4
Train:
dataset:
name: MultiScaleDataset
image_root: ./dataset/peach_data/
cls_label_path: ./dataset/peach_data/train_list.txt
Eval:
dataset:
name: ImageNetDataset
image_root: ./dataset/peach_data/
cls_label_path: ./dataset/peach_data/val_list.txt
PostProcess:
name: Topk
topk: 1
class_id_map_file: ./dataset/peach_data/label_list.txt
- 开启训练
# 这里需要使用云端GPU环境,cpu环境因为只有2core,训练跑不起来
python tools/train.py -c ppcls/configs/peach/PPLCNetV2_base.yaml
一般2-3个epoch就会有不错的效果。
- 模型评估
-o Global.pretrained_model 指定推理的权重位置
python tools/eval.py -c ppcls/configs/peach/PPLCNetV2_base.yaml -o Global.pretrained_model=output/PPLCNetV2_base/best_model
- 模型预测
-o Infer.infer_imgs指定预测的图片位置
python tools/infer.py -c ppcls/configs/peach/PPLCNetV2_base.yaml -o Global.pretrained_model=output/PPLCNetV2_base/best_model -o Infer.infer_imgs=./dataset/peach_data/test/M2/1800.png
模型推理部署
0 推理模型准备
其目的是为了得到用于inference的模型文件,最终存放位置由配置文件的Global.save_inference_dir指定
python tools/export_model.py -c ppcls/configs/peach/PPLCNetV2_base.yaml -o Global.pretrained_model=output/PPLCNetV2_base/best_model
# 在./deploy/models/PPLCNetV2_base_infer文件下得到三个文件
- inference.pdiparams
- inference.pdiparams.info
- inference.pdmodel
1 基于python预测引擎推理
测试一下上述得到的用于inference的模型有没有问题
cd deploy
# 复制一份inference_cls.yaml到inference_cls_peach.yaml并做相应修改,针对我们的任务需要修改的地方如下:
infer_imgs: "../dataset/peach_data/test/R0/0.png"
inference_model_dir: "./models/PPLCNetV2_base_infer"
class_id_map_file: "../dataset/peach_data/label_list.txt"
# 单张图像推理,默认使用gpu
python python/predict_cls.py -c configs/inference_cls.yaml
# 文件夹中所有图像推理,指定文件夹路径
python python/predict_cls.py -c configs/inference_cls_peach.yaml -o Global.infer_imgs=../dataset/peach_data/test/R0
2 服务化部署
这个部分的目的是将我们的模型部署成一个服务,客户端就可以通过http或rpc进行,飞浆已对上述需求所需要的功能实现进行了封装,细节可参考官方文档。具体执行命令如下:
# 第一步:安装必要的包
pip install paddle-serving-client==0.7.0
pip install paddle-serving-app==0.7.0
# 若为CPU部署环境:
pip install paddle-serving-server==0.7.0
# 若为GPU部署环境:
pip install paddle-serving-server-gpu==0.7.0.post102
# 第二步:模型转换成server需要的文件
python -m paddle_serving_client.convert --dirname ../models/PPLCNetV2_base_infer/ --model_filename inference.pdmodel --params_filename inference.pdiparams
## 运行完会在当前目录下生成两个文件夹,serving_server和serving_client
# 第三步:准备配置文件
cd paddleserving/
## 修改classification_web_service.py中依赖的配置文件config.yml和imagenet.label
## 其中config.yml中需要指定model_config: serving_server,也即我们在第二步生成的serving_server文件夹
## 其中imagenet.label是ImageNet的标签文件,需要修改成我们数据集的标签,可以copy一份并命名为peach.label,并将4个标签填入
## 修改classification_web_service.py中preprocess函数中{"inputs": input_imgs}=>{"x": input_imgs}
## 注意这里的"x"是因为需要和我们模型输入的名称对应,可查看serving_server/serving_server_conf.prototxt
## 修改serving_client/serving_client_conf.prototxt和serving_server/serving_server_conf.prototxt中fetch_var的alias_name,具体而言:
feed_var {
name: "x"
alias_name: "x"
is_lod_tensor: false
feed_type: 1
shape: 3
shape: 224
shape: 224
}
fetch_var {
name: "softmax_1.tmp_0"
alias_name: "prediction"
is_lod_tensor: false
fetch_type: 1
shape: 4
}
# 第四步:启动服务
# 启动服务并放到后台运行,运行日志保存在 log.txt
python classification_web_service.py &>log.txt &
# 第五步:客户端调用(发送请求)
python pipeline_http_client.py # http请求
python pipeline_rpc_client.py # rpc请求
3 端侧部署
这个部分的目的是将我们的模型部署到移动端(比如手机),这样就不用依赖云端服务器来进行推理了,飞浆已对上述需求所需要的功能实现进行了封装,主要体现在PaddleLite这个组件上,细节可参考官方文档。端侧部署相对稍微复杂一些,主要可以分为以下几个步骤进行:
3.1 模型优化
考虑到端侧对推理耗时要求比较高,故需要采用paddlelite对inference模型做进一步优化
# 安装最新版的paddlelite==2.12, 2.10转换pplcnet时会报错-Check failed: it != attrs().end(): No attributes called fix_seed found for dropout Aborted (core dumped)
pip install paddlelite==2.12
# 模型转换
cd PaddleClas/deploy
paddle_lite_opt --model_file=models/PPLCNetV2_base_infer/inference.pdmodel --param_file=models/PPLCNetV2_base_infer/inference.pdiparams --optimize_out=models/pplcnet
#上述代码会在models/下生成pplcnet.nb文件

3.2 执行编译
这一步会得到手机端的可执行文件clas_system,下面以华为Mate30为例,其cpu是armv8架构,如果选用其他手机,需要查看其处理器架构是armv8还是armv7。
cd PaddleClas/deploy/lite/
# 克隆 Autolog 代码库,以便获取自动化日志
git clone https://github.com/LDOUBLEV/AutoLog.git
# 如果国内下载不了,加上镜像https://mirror.ghproxy.com/
git clone https://mirror.ghproxy.com/https://github.com/LDOUBLEV/AutoLog.git
# 下载 linux-x86_64 版本的 Android NDK, 并添加系统环境变量
wget https://dl.google.com/android/repository/android-ndk-r17c-linux-x86_64.zip
unzip android-ndk-r17c-linux-x86_64.zip
export NDK_ROOT=/home/aistudio/android-ndk-r17c # 注意路径
# 下载paddlelite的交叉编译库-注意这里的版本2.12要和上面的paddlelite==2.12对应上
wget https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.12/inference_lite_lib.android.armv8.clang.c++_static.with_extra.with_cv.tar.gz
tar -xf inference_lite_lib.android.armv8.clang.c++_static.with_extra.with_cv.tar.gz
# 修改makefile,指定LITE_ROOT=./inference_lite_lib.android.armv8.clang.c++_static.with_extra.with_cv
# 执行编译命令
make
## 编译成功后,会在当前目录生成 clas_system 可执行文件,该文件用于手机端推理
3.3 和手机联调
将可执行文件、模型文件和测试图片推送到手机上,进行联调。
# 第一步:windows安装adb
谷歌的安卓平台下载ADB软件包进行安装:链接
安装好后adb.exe 一般保存在C:\Users\用户名xx\AppData\Local\Android\Sdk\platform-tools
需要将其加到系统环境变量中:
-- 以win11为例,系统-系统信息-高级系统设置-环境变量
-- 新建AndroidHome=C:\Users\用户名xx\AppData\Local\Android\Sdk
-- Path-新建:%AndroidHome%\platform-tools
# 第二步:手机连接电脑
华为Mate30手机为例:
- 开启开发者模式:设置-关于手机-点击“版本号”多次直到提示“您已进入开发者模式”
- 打开USB调试:设置-系统与更新-开发人员选项-USB调试-选择USB配置(多媒体传输)
# 第三步:文件传输到手机
- 将所需文件下载到D:\Downloads\litedemo
- 10.png # 测试图像
- clas_system # 可执行文件
- config_pplcnet.txt # config文件
- label_list.txt # 标签映射文件
- libpaddle_light_api_shared.so
- pplcnet.nb # 模型权重文件
- 在D:\Downloads\litedemo下打开终端:
adb devices # 显示设备
adb shell ls # 查看手机系统目录
# 使用adb push命令将文件夹中所有文件传输到手机上:
adb shell mkdir -p /data/local/tmp/arm_cpu/
adb push clas_system /data/local/tmp/arm_cpu/
adb push config_pplcnet.txt /data/local/tmp/arm_cpu/
adb push label_list.txt /data/local/tmp/arm_cpu/
adb push libpaddle_light_api_shared.so /data/local/tmp/arm_cpu/
adb push pplcnet.nb /data/local/tmp/arm_cpu/
adb shell chmod +x /data/local/tmp/arm_cpu//clas_system # 需要加可执行权限
adb shell 'export LD_LIBRARY_PATH=/data/local/tmp/arm_cpu/; /data/local/tmp/arm_cpu/clas_system /data/local/tmp/arm_cpu/config_pplcnet.txt /data/local/tmp/arm_cpu/10.png'
预测成功,看到如下结果: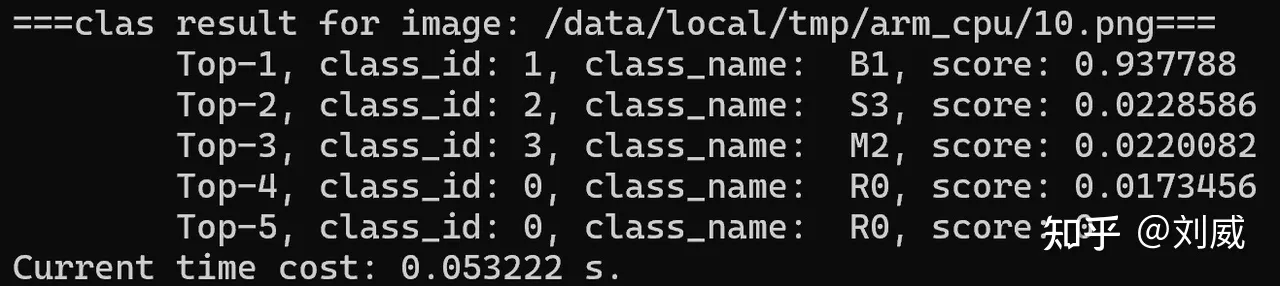
测试成功后,可将文件夹删除adb shell rm -r /data/local/tmp/arm_cpu/
总结
本文通过一个计算机视觉领域中最基础的任务之图像分类,带领大家熟悉百度Paddle深度学习框架中的各种组件。案例选自智慧农业场景,有现实场景应用需求,本系列的后续文章将沿袭这一思路,继续分享更多采用Paddle深度学习框架服务更多产业应用的案例。
版权归原作者 AI码上来 所有, 如有侵权,请联系我们删除。