
面向存算架构的神经网络数字系统(Compute-in-Memory, CIM 或 Processing-in-Memory, PIM)是一种旨在突破传统计算架构瓶颈的新型系统设计。传统的计算系统中,数据存储和数据计算通常分开进行,这导致了大量的数据搬移和相关的时间、能量消耗。而存算一体化架构通过将计算单元和存储单元集成在一起,可以显著提高计算效率和能量效率,特别是在处理大量数据的神经网络任务中表现尤为突出。
面向存算架构的优势
- 减少数据搬移:传统架构中,处理器和内存之间的数据搬移会产生显著的延迟和能量消耗。CIM通过在存储器内执行计算,大大减少了数据搬移的需求。
- 提高能量效率:在存储器中执行计算任务可以显著降低功耗,尤其是在深度学习等需要大量矩阵乘法和加法运算的应用中。
- 提升计算性能:由于减少了数据搬移时间,存算一体化架构能够加速计算过程,提高系统的整体性能。
存算架构的实现方式
- 基于SRAM的CIM:静态随机存取存储器(SRAM)由于其高速和低功耗特性,常用于构建高性能的存算一体化单元。通过在SRAM单元中集成简单的计算逻辑单元,可以实现高效的并行计算。
- 基于DRAM的CIM:动态随机存取存储器(DRAM)虽然速度较慢,但其高密度和大容量特性使其适合于大规模数据存储和计算。通过在DRAM中集成计算单元,可以处理更大规模的数据集。
- 基于ReRAM的CIM:电阻式随机存取存储器(ReRAM)是一种新型存储技术,具有高速度和非易失性特点。在ReRAM中集成计算单元,可以在提高计算速度的同时保持数据的持久性。
存算架构在神经网络中的应用
- 加速训练过程:存算一体化架构能够加速神经网络训练过程中的矩阵运算,显著减少训练时间。
- 提高推理效率:在推理阶段,CIM架构能够快速处理输入数据并生成输出结果,适用于实时应用。
- 降低能耗:通过在存储器内直接进行计算,CIM架构可以显著降低神经网络计算的能耗,延长电池供电设备的使用时间。
ResNet14 算法基本架构
ResNet14 是一种深度卷积神经网络,属于 ResNet(残差网络)系列。尽管 ResNet14 并不是最常见的 ResNet 版本(如 ResNet18、ResNet34、ResNet50 等),其基本架构仍然遵循 ResNet 的设计理念。以下是 ResNet14 的基本架构和其关键组件的简要说明:
ResNet 基本设计理念
- 残差块(Residual Block): 核心组件是残差块,通过引入快捷连接(skip connections)来缓解梯度消失问题。每个残差块可以表示为: [ y = F(x, {Wi}) + x ] 其中 (x) 是输入,(y) 是输出,(F(x, {Wi})) 是表示通过权重为 ({W_i}) 的卷积层等操作后的输出。
- 快捷连接(Skip Connection): 将输入直接添加到输出,允许梯度直接传回较早的层,从而增强网络的训练能力。
ResNet14 架构
ResNet14 可以看作是一个简化版的 ResNet18,通常由以下几个部分组成:
- 输入层(Input Layer):
- 输入图像大小:(224 \times 224)
- 一个 (7 \times 7) 的卷积层,64 个滤波器,步幅为 2。
- 一个 (3 \times 3) 的最大池化层,步幅为 2。
- 残差块组(Residual Blocks):
- 第一个残差块组: - 两个基本块(Basic Block),每个块包含两个 (3 \times 3) 的卷积层。
- 第二个残差块组: - 两个基本块,每个块包含两个 (3 \times 3) 的卷积层。
- 第三个残差块组: - 两个基本块,每个块包含两个 (3 \times 3) 的卷积层。
- 全局平均池化层(Global Average Pooling Layer):
- 对整个特征图进行平均池化,将特征图转化为一个单一的特征向量。
- 全连接层(Fully Connected Layer):
- 最后连接一个全连接层,用于分类。
详细结构
为了更清晰地理解,以下是 ResNet14 的具体层级结构:
- 卷积层和最大池化层:
- Conv1: (7 \times 7) 卷积,64 个滤波器,步幅 2
- Max Pool: (3 \times 3) 最大池化,步幅 2
- 残差块组:
- 第一个残差块组: - Basic Block 1:- Conv2_1: (3 \times 3) 卷积,64 个滤波器- Conv2_2: (3 \times 3) 卷积,64 个滤波器- Basic Block 2:- Conv2_3: (3 \times 3) 卷积,64 个滤波器- Conv2_4: (3 \times 3) 卷积,64 个滤波器
- 第二个残差块组: - Basic Block 1:- Conv3_1: (3 \times 3) 卷积,128 个滤波器- Conv3_2: (3 \times 3) 卷积,128 个滤波器- Basic Block 2:- Conv3_3: (3 \times 3) 卷积,128 个滤波器- Conv3_4: (3 \times 3) 卷积,128 个滤波器
- 第三个残差块组: - Basic Block 1:- Conv4_1: (3 \times 3) 卷积,256 个滤波器- Conv4_2: (3 \times 3) 卷积,256 个滤波器- Basic Block 2:- Conv4_3: (3 \times 3) 卷积,256 个滤波器- Conv4_4: (3 \times 3) 卷积,256 个滤波器
- 全局平均池化和全连接层:
- Global Average Pooling
- Fully Connected Layer (Output Layer)

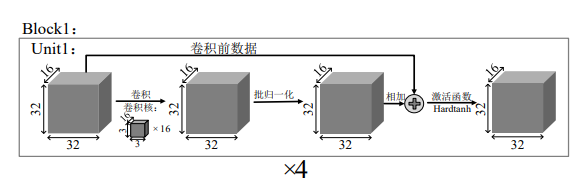
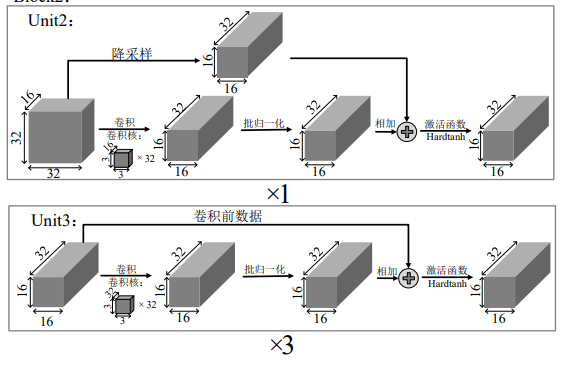
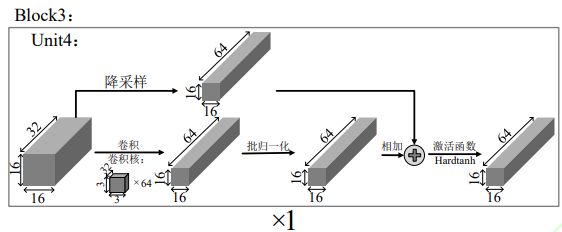
激活函数
ResNet14 架构中的激活函数通常使用的是 ReLU(Rectified Linear Unit)。ReLU 是一种常用的激活函数,因为它计算简单,同时能够有效地解决梯度消失问题。以下是 ReLU 激活函数的定义及其在 ResNet 中的应用。
ReLU 激活函数
ReLU 的数学定义如下:
f(x)=max(0,x)
即,对于输入 (x),输出是 (x) 和 0 中的较大值。ReLU 有以下几个优点:
- 计算简单:ReLU 的计算仅涉及简单的比较和取值操作,非常高效。
- 减轻梯度消失问题:相比于 Sigmoid 和 Tanh 等激活函数,ReLU 能有效地缓解梯度消失问题,使得深层神经网络能够更容易地训练。
ReLU 在 ResNet 中的应用
在 ResNet 架构中,ReLU 激活函数通常应用在每个卷积层之后。以下是 ResNet14 中激活函数的具体使用位置:
- 卷积层后的激活:每个卷积层后,应用 ReLU 激活函数。例如,在每个残差块中,两个 (3 \times 3) 卷积层之后都会应用 ReLU 激活。
- 残差块的激活:在残差块的输出处,输入 (x) 和通过卷积层处理后的输出 (F(x, {W_i})) 相加后,也会应用 ReLU 激活。
对于激活函数的选取,参考了 Relu、Sigmoid、 Tanh 和 Hardtanh 等主流激活函数。
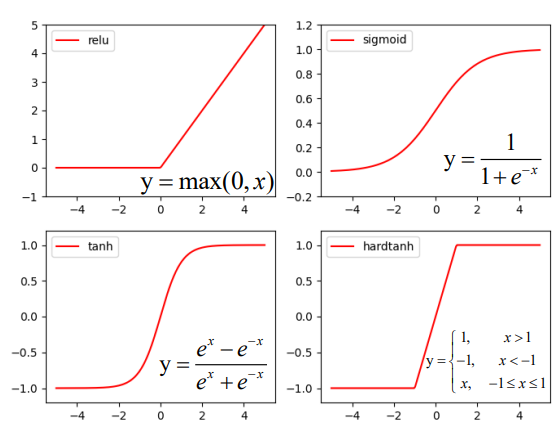
具体实现
对于 ResNet14 的每个残差块,ReLU 的应用可以如下表示:
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = self.relu(out)
return out
class ResNet14(nn.Module):
def __init__(self, num_classes=10):
super(ResNet14, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 2, stride=1)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(256, num_classes)
def _make_layer(self, in_channels, out_channels, blocks, stride):
layers = []
layers.append(BasicBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
layers.append(BasicBlock(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
数字系统的多神经网络兼容性设计
数字系统中的多神经网络兼容性设计涉及确保不同类型的神经网络模型能够在同一个系统中高效运行、协同工作。这种设计对于构建复杂的智能系统(如多模态处理系统、自适应学习系统等)非常重要。以下是实现多神经网络兼容性设计的一些关键原则和方法:
1. 模型互操作性
确保不同神经网络模型可以在同一个框架下运行和交互。常用的方法包括:
- 标准化模型格式:使用标准的模型格式,如 ONNX(Open Neural Network Exchange),使得不同深度学习框架(如 TensorFlow、PyTorch、Caffe)之间的模型可以互相转换和兼容。
- 统一编程接口:通过定义统一的编程接口和API,使得不同模型可以通过统一的方式进行调用和操作。
2. 模型部署与推理
确保不同模型可以高效地部署和推理。关键技术包括:
- 模型优化:使用模型量化、剪枝和蒸馏等技术优化模型,减少计算资源的消耗。
- 推理引擎:使用高效的推理引擎(如 TensorRT、ONNX Runtime)来执行不同类型的模型。
3. 资源管理
有效管理计算资源,以确保多个模型在同一系统上高效运行。方法包括:
- 资源调度:设计智能资源调度算法,根据模型的计算需求动态分配CPU、GPU等计算资源。
- 任务并行化:通过并行化执行不同模型的推理任务,提高系统的整体吞吐量。
4. 数据兼容性
确保不同模型能够共享和处理同样的数据格式和数据流。技术措施包括:
- 数据预处理与标准化:定义统一的数据预处理和标准化流程,确保输入数据的一致性。
- 数据管道:使用统一的数据管道来传输和处理数据,保证数据在不同模型之间的兼容性。
5. 系统架构设计
设计灵活的系统架构,以支持多神经网络的兼容性。常见的方法包括:
- 模块化设计:将系统分为多个模块,每个模块处理特定的任务和模型,并通过标准接口进行通信。
- 服务化架构:使用微服务架构,将每个神经网络模型部署为独立的服务,通过API进行调用和管理。
6. 案例分析
下面以一个具体案例说明如何实现多神经网络兼容性设计:
假设我们要构建一个智能语音助手系统,该系统需要同时使用语音识别模型(ASR)、自然语言处理模型(NLP)和语音合成模型(TTS)。
1. 模型互操作性:
- 使用 ONNX 格式将 ASR、NLP 和 TTS 模型导出,确保模型在不同框架之间的互操作性。
2. 模型部署与推理:
- 使用 TensorRT 优化所有模型,并将它们部署在一个统一的推理引擎上,以提高推理速度和效率。
3. 资源管理:
- 设计资源调度算法,动态分配 GPU 资源给 ASR、NLP 和 TTS 模型,以确保每个模型都有足够的计算资源进行实时处理。
4. 数据兼容性:
- 定义统一的音频数据预处理流程(如降噪、归一化),并使用标准的文本编码格式(如 UTF-8),确保数据在 ASR、NLP 和 TTS 模型之间的兼容性。
5. 系统架构设计:
- 采用微服务架构,将 ASR、NLP 和 TTS 部署为独立的服务。通过 RESTful API 或 gRPC 进行服务间通信,确保每个模型服务可以独立开发和部署,同时实现系统的灵活性和可扩展性。
以下是系统架构的简化示意图:
+-------------------+ +-------------------+ +-------------------+
| ASR Service | | NLP Service | | TTS Service |
| | | | | |
| Audio -> Text | | Text Processing | | Text -> Audio |
+-------------------+ +-------------------+ +-------------------+
| | |
| | |
+-----------+---------------+---------------+-----------+
| | |
+---------------+---------------+
|
+-----------------------+
| Orchestrator |
| (API Gateway) |
+-----------------------+
|
+-----------------------+
| User Interface |
+-----------------------+
测试及结果
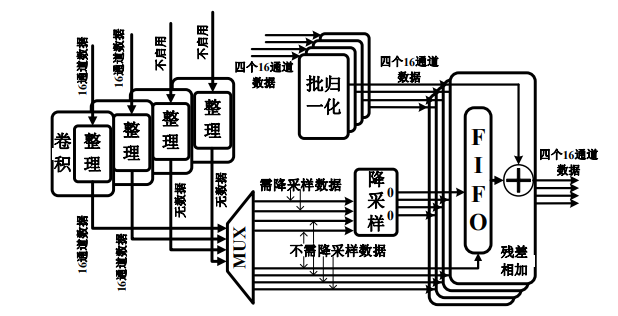
本文设计的数字系统与存算阵列全部采用 Verilog 实现,通过 AHB 总线与 Cortex-M4 连接。编写 C 程序驱动 MCU 向数字系统内写入所需的卷积核和其他参数,并控制数字系统的使能信号以确保其正常运行。生成的 bit 文件和 bin 文件被烧录到 Xilinx Virtex UltraScale+ FPGA XCVU13P 验证平台上进行系统级验证。
在数据集图片通过 MCU 完成神经网络的首个卷积层后,输出结果通过 AHB 发送到数字系统中进行中间卷积层的计算。随后,MCU 通过 AHB 接收数字系统的运算结果,完成最后的平均池化和全连接层,最终得到前向推理结果。在 10MHz 时钟频率下,系统实现了 60FPS 的图片处理速度,Cifar-10 和 MNIST 目标分类准确率分别达到了 84.17% 和 98.79%。结果显示,本文设计的数字系统在进一步压缩数据位宽的同时,仍然保持了较高的准确率。
参考文献
- 知存科技
- 中国移动研究院
- 电子与信息学报—存内计算芯片研究进展及应用
- 中科院—基于NorFlash的表积神经网络量化
- 卢北辰,杨兵.面向存算架构的神经网络数字系统设计[J/OL].微电子学与计算机:1-10
- 杨茜,王远博,王承智,等.基于MRAM的新型存内计算范式[J/OL].单片机与嵌入式系统应用,1-13
- 唐成峰,胡炜.应用于忆阻器阵列存内计算的低延时低能耗新型感知放大器[J].微电子学与计算机,2024,41(02):58-66.
版权归原作者 一键难忘 所有, 如有侵权,请联系我们删除。