
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
遗传算法是一种基于自然选择的优化问题的技术。在这篇文章中,我将展示如何使用遗传算法进行特征选择。
虽然 scikit-learn 中有许多众所周知的特征选择方法,但特征选择方法还有很多,并且远远超出了scikit-learn 提供的方法。特征选择是机器学习的关键方面之一。但是因为技术的快速发展,现在是信息大爆炸的时代,有多余的可用数据,因此通常会出现多余的特征。许多特征都是多余的。它们会为模型增加噪音,并使模型解释出现问题。
我们面临的问题是确定哪些特征与问题相关。我们找寻目标是具有高质量的特征。
遗传算法
本篇文章使用了“sklearn-genetic”包:
该软件包与现有的sklearn模型兼容,并为遗传算法的特征选择提供了大量的功能。
在这篇文章中,我使用遗传算法进行特征选择。但是遗传算法也可以用于超参数优化。因为这些步骤非常简单和一般化,所以可以适用于许多不同的领域。
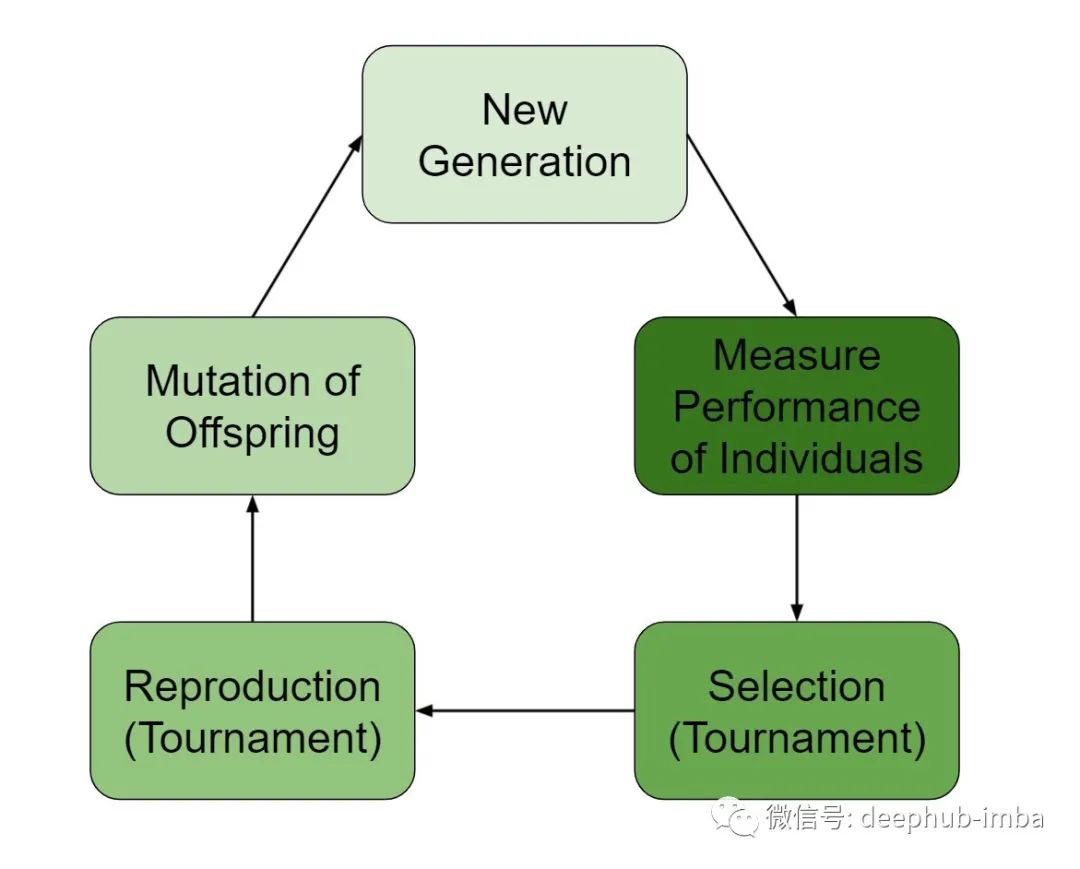
特征选择
选择特性是一个NP-Hard问题(所有NP问题都能在多项式时间复杂度内归遇到的问题)。给定一组特征,最优配置是这些特征的集合或子集。这种方法是离散选择。在可能性排列的情况下,确定最优特征集的成本是非常高的。
遗传算法使用一种基于进化的方法来确定最优集。对于特征选择,第一步是基于可能特征的子集生成一个总体(种群)。
从这个种群中,使用目标任务的预测模型对子集进行评估。一旦确定了种群的每个成员,就会进行竞赛以确定哪些子集将延续到下一代。下一代由竞赛获胜者组成并进行交叉(用其他获胜者的特征更新获胜特征集)和变异(随机引入或删除一些特征)。
大致的步骤如下:
- 产生初始种群
- 对种群中的每个成员进行评分
- 通过竞赛选择子集进行繁殖
- 选择要传递的遗传物质(特征)
- 应用突变
- 以上步骤重复多次,每一次成为一代(generation)
该算法运行一定数量的代之后,群体的最优成员就是选定的特征。
实际操作
实验基于 UCI 乳腺癌数据集,其中包含 569 个实例和 30 个特征。使用这个数据集,我测试了几个分类器的所有特征、遗传算法的特征子集以及使用卡方检验的五个特征进行比较。
下面是用于使用遗传算法选择最多五个特征的代码。
from sklearn.datasets import load_breast_cancer
from genetic_selection import GeneticSelectionCV
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
import numpy as npdata = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
X = df.drop(['target'], axis=1)
y = df['target'].astype(float)estimator = DecisionTreeClassifier()
model = GeneticSelectionCV(
estimator, cv=5, verbose=0,
scoring="accuracy", max_features=5,
n_population=100, crossover_proba=0.5,
mutation_proba=0.2, n_generations=50,
crossover_independent_proba=0.5,
mutation_independent_proba=0.04,
tournament_size=3, n_gen_no_change=10,
caching=True, n_jobs=-1)
model = model.fit(X, y)
print('Features:', X.columns[model.support_])
GeneticSelectionCV
初始种群(大小为“n_population”)是从特征集的样本空间中随机生成的。这些集合的范围受参数“max_features”的限制,该参数设置每个特征子集的最大大小。
对于初始种群的每个成员,使用目标度量来衡量一个分数。此度量是指定的估算器的性能。
进行竞赛选择以确定哪些成员将继续到下一代。竞赛中的成员数量由“tournament_size”设置。竞赛规模是根据评分指标从总体中选出的几个成员相互竞争。获胜者被选为下一代的父母。
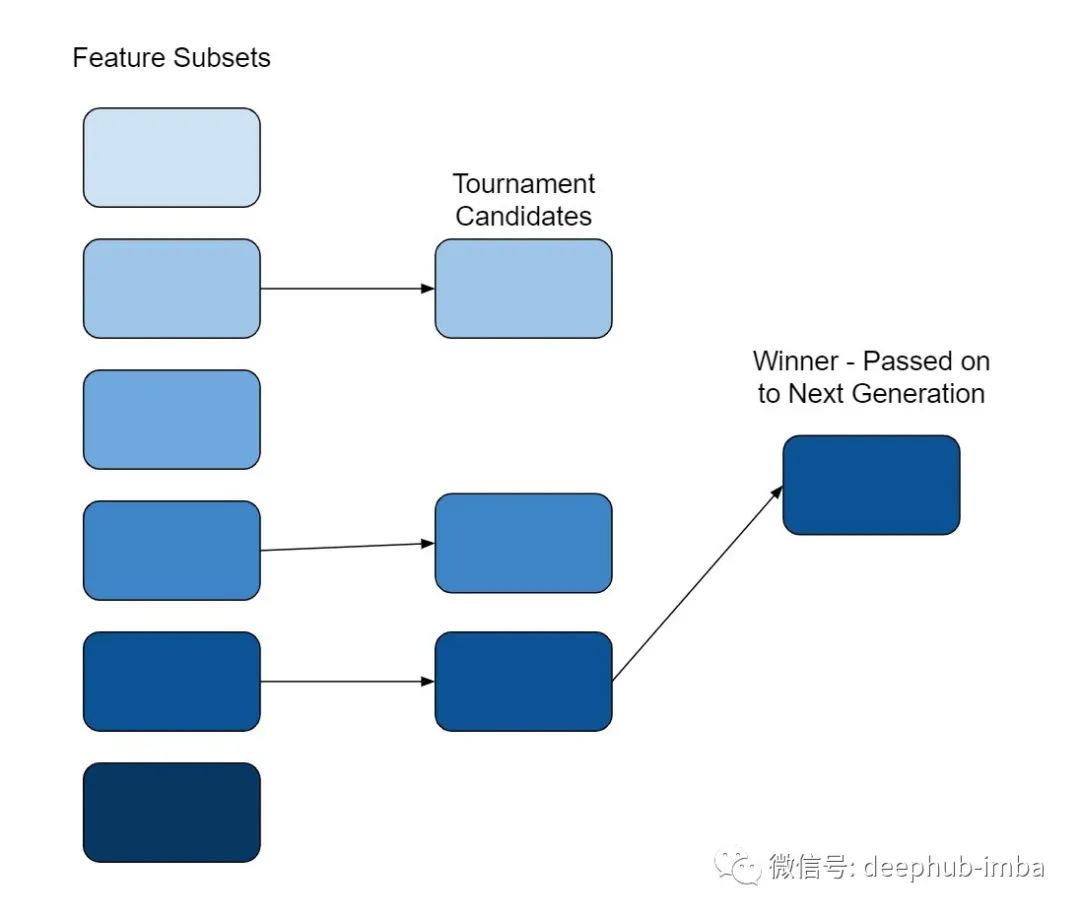
参加竞赛的成员人数应该很少。当值比较大时,通常选择当前最好的成员。此行为不会导致选择任何较弱的成员。对于较弱的成员,虽然提供了暂时的性能提升,但最终这会导致整体性能的降低,因为较弱的选项没有得到改进的机会。
自然选择
在自然选择中,遗传信息存储在染色体中。在繁殖过程中一些遗传物质从父母传给孩子。然后孩子包含来自父母双方的遗传物质。此属性用参数“crossover_proba”表示。指定的概率表示从一个生成交叉到下一个生成的机会。还有一个参数“crossover_independent_proba”,它是一个特征将交叉到子节点的概率。
进化的一个关键方面是突变。变异降低了搜索陷入局部最优被卡住的风险。在每一代中除了交叉之外,还添加了一个随机突变。突变发生的概率由参数“mutation_prob”设置。此参数与“mutation_independent_proba”结合,这是向特征集添加特征的机会。
值得注意的是,将此概率设置得太高会将算法转换为随机选择过程。因此将此值设置在相对较低的水平。在每一代中随机引入特征可以有效地作为遗传过程的正则化。
此处使用的遗传搜索算法还有一个“n_gen_no_change”参数,用于监控种群中最好的成员是否在几代中没有发生变化。在这种情况下,搜索是否找到了一个最佳选择。是否考虑增加突变或交叉概率以进一步改变选择。
结果
遗传与卡方特征选择的结果如下所示。还列出了使用所有特性的基准性能。结果来自交叉验证,使用准确性作为度量标准,使用的特征数量在括号中显示。
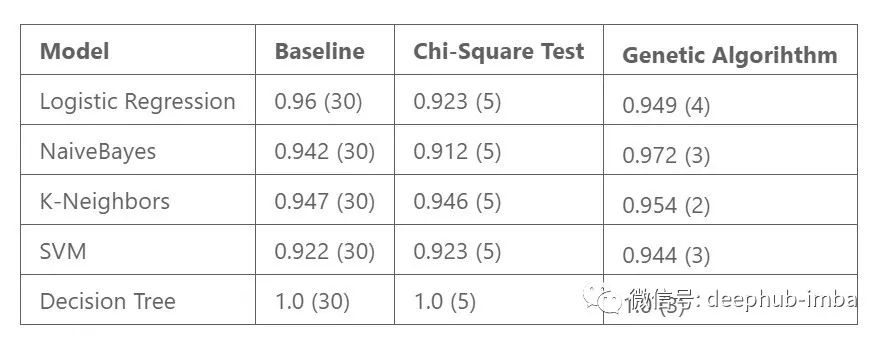
虽然这些结果不是决定性的,但它们显示了遗传算法的好处。模型性能基于遗传算法的特征子集,该子集始终优于基线模型和卡方特征子集。逻辑回归模型是一个例外,其结果仍然具有可比性。
此外,产生的最佳特征子集小于五个特征的最大值。具有较少特征的模型最终比较大的模型更受青睐,因为它们更简单且更易于解释。
总结
遗传算法非常通用,适用于广泛的场景。
这篇文章探讨了如何使用 sklearn-genetic 包将遗传算法用于特征选择。这些算法也已被证明在超参数搜索和生成式设计中是有效的。
虽然不像 sklearn 中现成的方法那么传统,但遗传算法提供了一种独特而实用的特征选择方法。这些算法优化的方式与大多数其他特征选择方法有很大不同。该过程基于纯自然选择方法。
我鼓励数据科学家花时间在他们的工作中理解和实施遗传算法。
作者:Zachary Warnes
喜欢就关注一下吧:
点个 在看 你最好看!********** **********