
Zero-Shot Information Extraction via Chatting with ChatGPT
利用ChatGPT实现零样本信息抽取(Information Extraction,IE),看到零样本就能大概明白这篇文章将以ChatGPT作为一个基座然后补全前后端,来实现抽取任务。主要针对抽取中的三个重要任务:
对于句子:《我的爱情日记》是1990年在北京上映的中国…
- 实体关系三元组抽取任务,如(我的爱情日记,上映日期,1990年)
- 命名实体识别任务,如人物的实体有(吴天戈,…)
- 事件抽取任务,如事件是(产品行为-上映)
ChatIE如下图所示,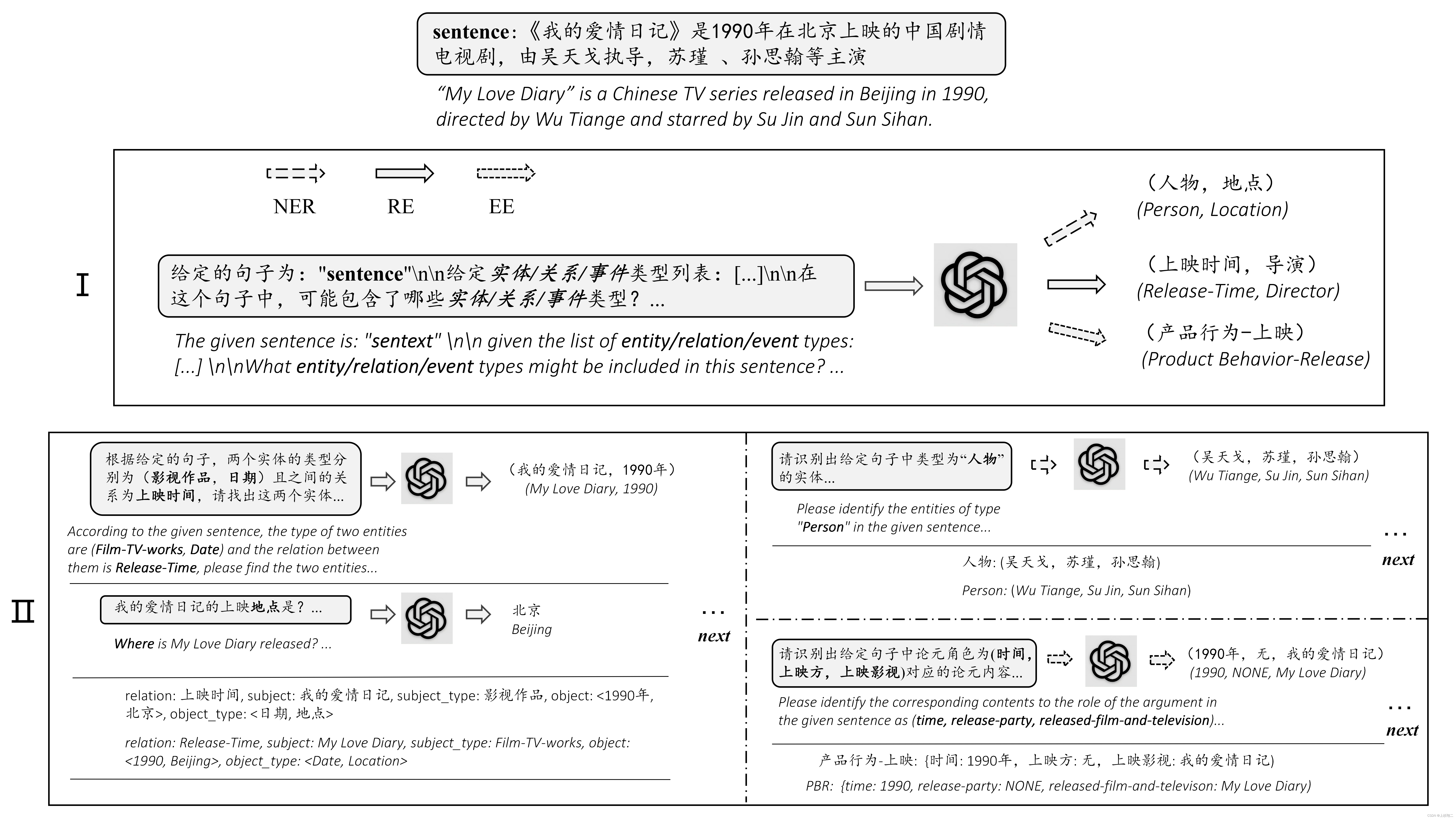
具体来说,ChatIE实现零样本的策略是将其任务转化为具有多轮提问-回答问题,主要分为两个阶段:
- 第一阶段,找出句子中可能存在的相应元素类型(对应三个任务分别为实体、关系或事件),通过这种方式可以提前过滤到不需要的信息,以减少搜索和计算复杂度。
- 如上图中的上半部分,输入给chatGPT的信息为:“给定的句子为:sentence。给定实体/关系/事件类型列表:[…]。在这个句子中,可能包含了哪些实体/关系/事件类型”,然后得到一些关于人物/地点的实体,上映时间/导演等关系,上映等具体事件。
- 第二阶段,对第一阶段识别出的每个元素按照任务执行相应的信息抽取。由于有些问题比较复杂,所以作者们设计了问题模板链,即某个元素的抽取可能取决于前一些元素的抽取。
- 如上图中的下半部分,分不同的子任务处理方法不同。
# 命名关系
# 先定义实体的类别
df_nert = {
'chinese': ['组织机构', '地点', '人物']
}
# 再输入到prompt中
ner_s1_p = {
'chinese': '''给定的句子为:"{}"\n\n给定实体类型列表:{}\n\n在这个句子中,可能包含了哪些实体类型?\n如果不存在则回答:无\n按照元组形式回复,如 (实体类型1, 实体类型2, ……):'''
}
# 关系抽取
# 先定义抽取的schema
df_ret = {
'chinese': {'所属专辑': ['歌曲', '音乐专辑'], '成立日期': ['机构', 'Date'], ....}
}
# 再输入到prompt中
re_s1_p = {
'chinese': '''给定的句子为:"{}"\n\n给定关系列表:{}\n\n在这个句子中,可能包含了哪些关系?\n请给出关系列表中的关系。\n如果不存在则回答:无\n按照元组形式回复,如 (关系1, 关系2, ……):'''
}
# 事件抽取
# 先事件的schema
df_eet = {
'chinese': {'灾害/意外-坠机': ['时间', '地点', '死亡人数', '受伤人数'],...}
}
# 再输入到prompt中
ee_s1_p = {
'chinese': '''给定的句子为:"{}"\n\n给定事件类型列表:{}\n\n在这个句子中,可能包含了哪些事件类型?\n请给出事件类型列表中的事件类型。\n如果不存在则回答:无\n按照元组形式回复,如 (事件类型1, 事件类型2, ……):'''
}
代码已经开源,包含了详细的前后端处理。
本文转载自: https://blog.csdn.net/qq_39388410/article/details/129978286
版权归原作者 上杉翔二 所有, 如有侵权,请联系我们删除。
版权归原作者 上杉翔二 所有, 如有侵权,请联系我们删除。