
由深度神经网络(dnn)驱动的人工智能(AI)领域最近经历了翻天覆地的变化,这导致了对专业AI加速器的迫切需求。人工智能卓越的能力和复杂的工作性质进一步放大了这一需求。然而,为各种人工智能任务设计专门的加速器仍然是一项艰巨而耗时的冒险。此外,使用现有的设计探索和自动化工具[11],[13],[14],[17],[36],[43],[45]所需的硬件专业水平对非专家来说是一个巨大的挑战,抑制了AI加速器的创新发展。这个复杂的技术领域目前的特点是陡峭的学习曲线,这限制了AI加速器设计对一般AI开发者的访问和扩展,在AI算法开发和相应的加速器之间造成了越来越大的差距。

一个由llm驱动的通用AI加速器设计自动化管道
面对这些挑战,我们在大型语言模型(LLMs)[16]、[25]、[35]、[44]的新兴功能中找到了灵感,它们具有基于人类语言指令生成高质量内容的惊人能力。这些能力带来了一个诱人的前景,激发了本研究的核心问题:“我们能否利用llm的能力来自动化人工智能加速器的设计?”具体来说,如图所示,llm驱动的AI加速器设计自动化旨在探索加速器设计空间从而生成高质量的加速器实现,既能满足用户需求,又能最大限度地减少人工参与。为了回答上述问题,我们首先对llm在生成AI加速器设计方面的局限性和能力进行了全面的调查。这是为了了解当前的形势,同时也在探索我们如何更好地利用llm的力量来自动化人工智能加速器设计。根据本次调查得出的见解,我们开发了一个名为GPT4AIGChip的框架,表示“GPT for AI Generated Chip”。GPT4AIGChip旨在通过利用人类自然语言作为设计指令,而不是依赖于特定领域的语言,使人工智能加速器设计更加大众化,特别是对那些不精通硬件的人。
我们的贡献总结如下:
•我们深入研究了利用现有llm生成AI加速器设计的局限性和能力,以了解我们目前的位置,并就如何在设计自动化流水线中有效利用现有llm得出有用的见解。作为这些见解的具体应用,我们开发了GPT4AIGChip,这是第一个演示llm驱动的AI加速器设计自动化的框架。
•通过上述综合调查,我们发现了利用现有llm优势的三个关键观点:(1)当前的llm正在努力理解那些显示出长依赖关系的冗长代码,特别是那些不常见的语言,如高级合成语言(HLS),因此需要在设计空间中解耦不同的硬件功能;(2)考虑到用于开源LLM高效微调的注释数据的稀缺,采用上下文学习和典型的闭源但强大的LLM的逻辑推理能力的混合是一个更有效的选择;洞察-(3)用高质量的演示增强llm的提示是至关重要的,这些演示与输入设计指令的上下文相关。
•我们的GPT4AIGChip通过构建一个用HLS编写的解耦加速器设计模板实例化了上述的Insight-(1)。通过这种方式,它将加速器设计的不同硬件模块和功能解耦,从而首次实现了由llm驱动的AI加速器设计自动化。
•通过为GPT4AIGChip配备一个演示增强的提示生成器,我们实例化了上述的Insight-(2)/-(3)
利用llm进行自动化AI加速器设计。值得注意的是,我们的GPT4AIGChip通过在封闭源代码但功能强大的GPT-4[24]之上实现上下文学习,并结合两个基本组件,实例化三个观点:(1) llm友好的硬件模板,它将复杂的AI加速器代码简化为模块化结构,以及(2)演示增强提示生成器,它增强了llm生成优化AI加速器的能力。
通过精心选择的演示来补充提示进行设计。通过将llm友好型硬件模板与演示增强提示生成器集成,我们的GPT4AIGChip采用迭代方法来增强生成的AI加速器设计,逐步接近最优解决方案。每一次迭代遵循一个四个阶段的工作流程,如下图所示:
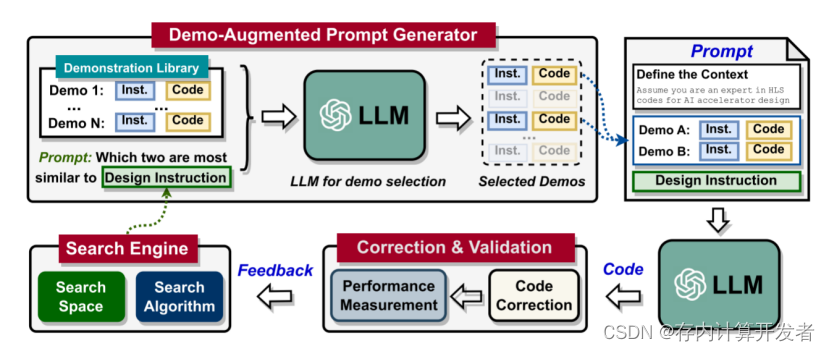
** Figure1:可视化我们提出的GPT4AIGChip框架的工作流程**
•搜索引擎识别下一个设计和llm友好型硬件模板中每个模块的相应指令,利用之前搜索设计的反馈来指导实施和评估。
•演示增强提示生成器为每个模块创建提示,结合相关演示(指令-代码对),以增强llm的上下文学习。
•具有上述提示的llm依次生成硬件设计实现。
•设计验证流程审查llm生成的代码,执行必要的修改以确保可部署性。
利于LLM的硬件模板设计
为LLM提供硬件设计模板对于弥补其有限的AI加速器设计知识至关重要。然而,现有的HLS加速器模板由于其复杂的设计参数耦合和相互依赖,给基于llm的AI加速器生成带来了重大挑战。为了解决这个问题,我们首先建立一个llm友好的加速器微架构和源代码模板的设计原则。在这些原则的指导下,我们提出了一个独特的模块化AI加速器模板,量身定制来优化LLM生成AI加速器设计的能力。然后,我们将讨论我们的模板的含义和优点。
在更广泛的场景中增强llm辅助设计生成。所期望的模板设计原则。为了确保有效的llm辅助生成加速器设计,我们确定了设计模板的三个关键原则:(1)高模块化,(2)解耦模块设计,(3)深度设计层次,以方便逐步生成设计,以解决llm固有的局限性。
•高模块化:由于LLM的令牌容量限制,在上下文学习时使用的输入样本代码的大小以及每一轮(即单个LLM模型推理)最终生成的设计的代码大小都受到了显著限制。由于具有高模块化,模板被分割成更小的、更易于管理的模块。这种模块化设计生成方法可以大大减少llm的输入和输出所需的代码大小。
•解耦模块设计:将代码模板分割成更小的模块可能会无意中引入配置设置之间的耦合和依赖关系。这与我们通过高模块化来减少输入令牌大小的目标相矛盾,因为LLM必须回忆以前模块的设置。为了解决这个问题,我们提出了独立的模块生成,每个模块维护自己的本地设置。然而,这可能导致整体设计不理想,连接模块之间可能存在数据速率不匹配。造成隔间或死锁。为了协调模块的运行,我们提出了一个附加的搜索引擎和适应性强的模块间通信方案。这些可以优化地协调所有本地设置,调解通信速率和带宽差异。因此,LLM可以生成每个模块根据其本地设置,维护解耦原则。
•为循序渐进的设计类别提供深层的设计层次:加速器的复杂性甚至会导致单个模块内的大量代码,这可能超过一个LLM的处理能力。为了解决这个问题,我们的模板采用了基于层次的、逐个模块生成的方法,简化了过程,并降低了每个阶段的复杂性。每个模块由多个遵循解耦原则的子模块组成,这些子模块可以进一步包含它们自己的子模块。这种递归嵌套一直持续到进一步的划分不可行的时候(见图2(b)中的Level-L)。这使得LLM可以系统地为每个模块生成设计层次结构,限制每个步骤的代码大小和复杂性。
加速器模板的概述。结合上述三个关键原则,我们引入了一种新的、模块化的、解耦的加速器微架构和相应的代码模板,如图2 (b)所示。考虑到GEMM算子在各种AI算法中的广泛应用,这里我们将重点关注广泛使用的GEMM算子,但我们的模板保留了通用结构。由一组通用模块组成,每个模块可以根据提示和本地配置设置灵活地重新设计,提供不同的硬件效率甚至独特的功能。为了指导LLMs精确解耦的代码生成,我们模板中的每个模块都严格对应于源代码中的函数实例化,如图2 (b)所示。每个模块都由嵌套的子模块分层组成,以方便LLMs的逐步生成。模块通过基于流的通信链路和异步数据fifo相互连接,以减少处理不同模块的数据生产和消耗率之间潜在的不匹配的控制开销。每个模块中的处理开始和终止主要取决于数据可用性,这促进了细粒度操作重叠,并简化了控制开销[15]。对于具有多个输入端口的模块,如图2 (b)中的互连模块,我们包括额外的同步逻辑,以确保数据对齐和准确性。
加速器模板的关键组件。我们对不同的模块进行如下图2 (b)所示。
•缓冲模块:这些模块旨在促进后续计算单元的并行数据访问,并利用各种数据重用模式。它们定义了(1)片上内存分区和相应的并行访问数据分配,以及(2)在缓冲区中刷新、重置或保留数据的过程,这些过程由与不同数据重用模式相关的控制信号决定。假设所有可能的设计风格都有双缓冲区,以确保最佳吞吐量。
•计算单元模块:这些模块主要处理计算,例如,乘法和加法,在他们的并行计算单元。作为一个乘法和累加(MAC)单元的集合实现,它们的互连可以根据不同的设计提示进行定制,在空间数据重用、MAC的数据传播延迟和片上缓冲区带宽争用之间取得平衡。我们构建嵌套的设计层次结构,以更容易的llm辅助生成,并适应各种MAC互连风格。因为所提出的模块化和解耦的加速器模板,以层次的方式方便一步一步地生成设计。
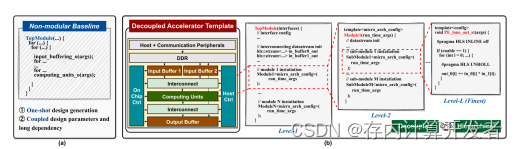
****Figure2:****具有非模块化模板的llm受到一次性设计生成、耦合设计参数和长期依赖的限制;(b)相反
例如,可以将单个mac连接起来形成1D PE- lane子模块,将多个PE lane连接起来形成更大的2D PE-array模块,增强了可扩展性。
•模块互联:实现缓冲模块和计算单元模块之间的数据灵活分布和同步。当计算单元由多个2D PE阵列组成,以及当算法到PE阵列的映射在运行时可以改变时,它们的灵活性就变得至关重要。
•控制(Ctrl)模块:它们处理从主机获取初始控制数据,控制数据解码,以及潜在的运行时控制数据生成,以改变各种模块的模式。
•灵活的通信仲裁器:这些仲裁器旨在管理互联模块之间的数据生产/消费速率和带宽的潜在不匹配,从而促进速率和带宽转换。
提出的模板的含义和优点。该模板具有三个主要优点:(1)通过解耦模块设计减少代码大小,并利用深度设计层次,该模板允许llm使用有限的输入和输出令牌容量,逐步生成复杂的加速器设计,增强llm的上下文学习能力;(2)当使用额外的样本代码和提示对数据集进行微调时,LLMs生成AI加速器设计的潜力可以进一步扩大。我们提出的模板简化了这个微调过程。它允许开发人员在一个模块中按模块、按层次生成数据集,大大降低了设计的复杂性;(3)为建议模板确定的原则超出了HLS的领域。在使用llm为其他编程语言生成设计时,与llm辅助设计生成有关的同样问题仍然存在。因此,上述关键原则通常是适用的,尽管不同领域的技术实现可能有所不同。
演示增强提示生成器的设计精心强化的提示,并辅以演示,可以有效地促进llm的语境学习。这赋予llm重要的特定于任务的知识,解锁他们的全部能力。然而,提示长度限制使得将所有可能的演示合并到一个提示中不切实际。为了解决这个问题,我们的演示增强提示生成器的目标是高效地生成提示,自动从我们精心设计的库中选择最相关的演示,并将它们合并到提示中,平衡提示长度和上下文学习性能。
工作流。受到先前强调llm在不同指令之间识别相似性的能力的研究的启发,我们在我们的演示增强提示生成器中使用llm来促进演示选择,这进一步减少了在人工智能加速器设计中对人类专业知识的需求。具体来说,如图4所示,在每次迭代中,给定一个由搜索引擎生成的设计指令,我们部署一个LLM来识别生成的设计指令与演示库中的设计指令之间的相似性。然后,我们选择两个最相似的指令,将它们与相应的实现配对,作为代码生成迭代的演示。然后,我们使用下面的模板生成演示增强提示符:
•假设你是AI加速器设计的HLS代码的专家,我现在将为你提供关于生成AI加速器设计的[模块名称]的说明。下面是两个演示指令和相应生成的代码。演示A:说明:[演示A说明]。代码:[Demo A代码];演示B:说明:[演示B说明]。代码:[Demo B Code]。现在请按照以下说明。
代码:【设计说明】。
演示库。高质量的演示库是我们的演示增强提示生成器的关键组件。这个库中的演示本质上是llm获取特定领域见解的主要知识来源。我们的目标是为目标领域组装一个包含多种设计选择的演示库,即本文中的GEMM。这确保了库提供具有丰富领域知识的演示,满足从搜索引擎生成的各种设计说明。为此,我们在示范库建设中坚持以下指导原则:
•高度相关的指令和代码对:每个演示包括一个详细的实现指令和相应的代码,并伴随着注释。每一行指令都明确地链接到特定的代码段,从而明确了它们的相关性和原理。
•多样化的设计选择:为了确保llm为给定的设计指令找到具有足够领域知识的演示,我们在我们的搜索空间(第IV-D部分)为每个设计参数生成单独的演示修改。
由于GPT4AIGChip考虑的搜索空间较大,基于上述原则生成大量不同的AI加速器设计需要大量的人力。幸运的是,我们提出的对llm友好的硬件模板使其可行。该模板展示了高模块化,并允许在AI加速器中对每个模块进行解耦生成。这种方法通过两种方式显著地减少了所需的人力:(1)每个模块都是简洁和结构化的实现。
专注于特定的功能。因此,一个模块的实现不需要考虑对其他模块的影响,从而简化了实现过程,减少了劳动密集型;(2)并不是模板中的所有模块都受到搜索空间中所有参数的影响。因此,与整个AI加速器设计相比,每个模块的潜在设计变化大大减少。
其他器件在GPT4AIGChip
硬件设计空间。为了确保生成的加速器在不同设计中的性能,通用加速器设计空间至关重要。它支持灵活的设计过程,为代码生成器提供多个选项来定制每个目标操作符的设计。利用第IV-B部分的模板,我们确定了五个关键的硬件设计参数:
•MAC数组大小:它们表示实例化的加速器的MAC数组中的MAC总数。
•片上网络(NoC)风格:它们决定了数据在计算单元之间的分布,以及数据在计算单元之间的传播。它们可以分为三种主要类型:单播、多播和广播。为了提高设计的多样性,这些风格被独立应用于计算单元的不同层次,包括单个MAC、1D MAC lanes和2D MAC array。此外,NoC样式为不同的数据类型分别配置,例如,GEMM中的两个输入操作数和一个输出,扩大了设计变化。
•片上缓冲区大小:它们表示加速器设计中三个主要缓冲区的容量,包括两个输入缓冲区和一个(部分)输出缓冲区。所有附加的辅助缓冲区和寄存器的大小取决于这三个主要缓冲区的能力。
•片上缓冲区分区风格:它们决定了每个缓冲区内的片上内存块之间的数据分配。通过将数据划分到多个块,可以通过缓冲区分区实现并行访问。这种划分可以采用数据宽度和高度两个维度。
•数据重用模式:它们定义了数据缓存后如何在计算过程中重用。改变缓冲区和DRAM交换数据的方式会导致不同的重用策略,例如,第一次输入操作数重用,第二次输入操作数重用,或输出重用。
采用的搜索算法。GPT4AIGChip的加速器搜索采用一种进化算法,称为锦标赛选择[19],该算法迭代地进化加速器的设计。这个迭代进化过程从初始化种群P开始,由|p |从可用的设计空间中随机选择的加速器设计{hw}组成。具体地说,在每次迭代中,从p中随机选择一个固定大小的子集S。根据llm生成的实现的顶级硬件性能判断,优秀的设计成为父设计{hw}parent。新型加速器设计{hw}child 然后通过突变(父元素设计参数的随机调整)和交叉(两个父元素之间的随机元素交换)出现。合成物{hw}child 为保持恒定的种群大小|P|,最古老的设计从P逐步淘汰,紧随[32]。最后,一旦达到最大循环数,则选择整个搜索过程中性能最高的加速器设计作为最优解。
设计验证和代码修正流程。GPT4AIGChip还集成了一个验证和确保llm生成设计的功能的过程,包括三个主要阶段:(1)综合能力评估(2)正确性验证(3)性能分析。在综合评价中,我们最初使用标准化的Vivado HLS工具[42]来合成LLM生成的代码。随后,输出日志消息通过一个定制的错误解析器处理,该解析器配备了经过经验测试的错误检测和纠正协议。如果解析器遇到超出其能力的错误,则可能需要(1)llm驱动的设计再生或(2)人为干预来纠正错误。当前的设置包含了检测和寻址未定义变量、不恰当的HLS pragma使用和出界数组(内存)访问的过程。通过结果的正确性检验,保证了设计产生了预期的结果。具体地说,构建一个具有预期输入和输出的测试工作台模板。随后将生成的输出与预期输出进行对比,以确认准确性。考虑到可能出现的各种错误,这一步骤不包括自动更正。如果结果不正确,需要重新设计。最后,我们评估性能指标(例如,延迟)和资源使用,以便向搜索引擎提供反馈,如图1所示。Vivado HLS内置工具在设计综合后生成这些性能和资源估计。
深入研究了llm在人工智能加速器设计自动化方面的能力。作为关键的第一步,我们对llm在自动AI加速器生成方面的优势和局限性进行了深入调查,对llm驱动的设计自动化的前景提出了重要的见解。基于这些见解,我们开发了GPT4AIGChip,该芯片集成了一个自动即时生成的流水线,使用上下文学习来引导llm创建高质量的AI加速器设计。各种实验和烧蚀研究验证了GPT4AIGChip在响应人类自然语言生成高性能人工智能加速器方面的有效性。据我们所知,这项工作标志着llm驱动的自动化人工智能加速器一代管道的首次成功演示,突出了llm在设计自动化领域尚未开发的潜力,并为下一代人工智能加速器的发展提出了有前景的道路。
**REFERENCES **
[1] “Ds891-zynq-ultrascale-plus-overview,” https://docs.xilinx.com/v/u/
en-US/ds891-zynq-ultrascale-plus-overview, (Accessed on 02/21/2023).
[2] B. Ahmad et al., “Fixing hardware security bugs with large language
models,” arXiv preprint arXiv:2302.01215, 2023.
[3] T. Brown et al., “Language models are few-shot learners,” *Advances in *
neural information processing systems, vol. 33, pp. 1877–1901, 2020.
[4] S. Bubeck et al., “Sparks of artificial general intelligence: Early exper
iments with gpt-4,” arXiv preprint arXiv:2303.12712, 2023.
[5] S. C. Chan et al., “Data distributional properties drive emergent few-shot
learning in transformers,” arXiv preprint arXiv:2205.05055, 2022.
[6] A. Chen et al., “Improving code generation by training with natural
language feedback,” arXiv preprint arXiv:2303.16749, 2023.
[7] M. Chen et al., “Evaluating large language models trained on code,”
arXiv preprint arXiv:2107.03374, 2021.
[8] J. Devlin et al., “Bert: Pre-training of deep bidirectional transformers
for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[9] L. Floridi and M. Chiriatti, “Gpt-3: Its nature, scope, limits, and
consequences,” Minds and Machines, vol. 30, pp. 681–694, 2020.
[10] Y. Fu et al., “Auto-nba: Efficient and effective search over the joint space
of networks, bitwidths, and accelerators,” in *International Conference on *
Machine Learning. PMLR, 2021, pp. 3505–3517.
[11] R. Garg et al., “A taxonomy for classification and comparison of
dataflows for gnn accelerators,” arXiv preprint arXiv:2103.07977, 2021.
[12] S. Garg et al., “What can transformers learn in-context? a case study
of simple function classes,” *Advances in Neural Information Processing *
Systems, vol. 35, pp. 30 583–30 598, 2022.
版权归原作者 存内计算开发者 所有, 如有侵权,请联系我们删除。