
本文总计 500 字,预计阅读需要 2-3 分钟
Pandas 进行独热编码是非常简单的,那么如果使用 Spark该怎么做
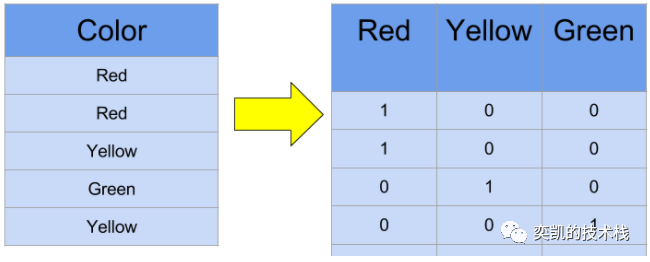
独热编码(One-hot-encoding) 是为机器学习建模准备数据时最常见的步骤之一。独热编码将分类数据转换为二进制向量表示。此方法为原始类别列中的每个唯一值创建一个新列。
Spark 非常擅长处理 PB 级的数据。但在复杂的建模技术方面,Spark 的 对于ML 支持还不够强大。所以是很多时候数据预处理是在 Spark 中完成,而下游建模是用纯 Python 或其他高级语言(如 Julia)实现的。
首先,我们需要设置 PySpark 会话并读取原始数据集。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("One_Hot_Encoding_Blog") \
.getOrCreate()
df = spark.read \
.option("header", True) \
.csv("ohe_explanation.csv")
df.show()
上面的代码产生以下结果:
+------+
| Color|
+------+
| Red|
| Red|
|Yellow|
| Green|
|Yellow|
+------+
现在,我们已经成功地将数据读入 PySpark dataframe,让我们看看在 PySpark 中实现 one-hot-encoding 的最简单(有问题的)方法。
将字符串值转换为数字标签/索引,One-Hot-Encode 数字标签到 VectorUDT (pyspark.ml.linalg.VectorUDT)
from pyspark.ml.feature import StringIndexer
from pyspark.ml.feature import OneHotEncoder
indexer = StringIndexer(inputCol="Color", outputCol="ColorNumericIndex")
df = indexer.fit(df).transform(df)
ohe = OneHotEncoder(inputCol="ColorNumericIndex", outputCol="ColorOHEVector")
df = ohe.fit(df).transform(df)
df.show()
返回的结果如下:
+------+-----------------+--------------+
| Color|ColorNumericIndex|ColorOHEVector|
+------+-----------------+--------------+
| Red| 0.0| (2,[0],[1.0])|
| Red| 0.0| (2,[0],[1.0])|
|Yellow| 1.0| (2,[1],[1.0])|
| Green| 2.0| (2,[],[])|
|Yellow| 1.0| (2,[1],[1.0])|
+------+-----------------+--------------+
这对于在 Spark 中完成下游建模的情况非常有用。PySpark 在将 one-hot-encoded 向量包装成密集向量 (VectorUDT) 方面做得非常出色,这在 Spark 世界中表现出色,但是它不能以 csv 格式写出向量。并且也不是人类可以理解的(尤其是对于数量很大的列)。
df.write.option("header", True).csv("ohe_result.csv")
如果我们要将上面的结果写入到CSV中就会得到提示:
pyspark.sql.utils.AnalysisException: CSV data source does not support struct<type:tinyint,size:int,indices:array<int>,values:array<double>> data type.
下面是我们需要的解决方案。要创建可解释的 One Hot Encoder,需要为每个不同的值创建一个单独的列。这很容易使用 pyspark的 inbuiltwithColumn 函数通过传递一个 UDF(用户定义函数)作为参数来完成。
from pyspark.sql.functions import udf, col
from pyspark.sql.types import IntegerType
我们只需要做2步:
- 收集列中需要进行编码的所有不同值
- 为每个收集的值创建一个新列,其列名格式为 <<original column name>>_ <<distinct value>>,表示记录中存在 (1) 或不存在 (0)
distinct_values = list(df.select("Color")
.distinct()
.toPandas()["Color"])
上面这段代码需要在运行代码的环境中安装pandas 0.23.2或以上版本。否则,代码将抛出以下错误:
ImportError: Pandas >= 0.23.2 must be installed; however, it was not found.
Pandas能够帮助我们处理很多事情,但实际上可能存在各种限制,例如无法在执行环境中安装新库。在这样的情况下,我们可以使用一个更 Spark 原生的方式,它不需要安装任何额外的库。
distinct_values = df.select("Color")\
.distinct()\
.rdd\
.flatMap(lambda x: x).collect()
要创建 One Hot Encoded 列,我们执行以下操作:
for distinct_value in distinct_values:
function = udf(lambda item:
1 if item == distinct_value else 0,
IntegerType())
new_column_name = "Color"+'_'+distinct_value
df = df.withColumn(new_column_name, function(col("Color")))
df.show()
结果显示如下:
+------+-----------+------------+---------+
| Color|Color_Green|Color_Yellow|Color_Red|
+------+-----------+------------+---------+
| Red| 0| 0| 1|
| Red| 0| 0| 1|
|Yellow| 0| 1| 0|
| Green| 1| 0| 0|
|Yellow| 0| 1| 0|
+------+-----------+------------+---------+
这个dataframe可以轻松的保存成csv文件供下游的任务使用, 并且这个输出与 pandas 使用 get_dummies 函数输出其 One Hot Encoded 值的方式非常相似。