
一、前言
尽管现在的大语言模型已经非常强大,可以解决许多问题,但在处理复杂情况时,仍然需要进行多个步骤或整合不同的流程才能达到最终的目标。然而,现在可以利用langchain来使得模型的应用变得更加直接和简单。
通过使用langchain,用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。langchain会自动将任务分解为多个子任务,并将它们传递给适合的语言模型进行处理。
其他安全合规的文章:
开源模型应用落地-安全合规篇-用户输入合规性检测(一)
开源模型应用落地-安全合规篇-用户输入合规性检测(二)
开源模型应用落地-安全合规篇-模型输出合规性检测(三)
二、术语
2.1.LangChain
是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangChain的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain 提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
LangChain的主要特性:
1.可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
2.允许语言模型与其环境交互
3.封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
4.可以使用链的方式组装这些组件,以便最好地完成特定用例。
5.围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。
2.2. 事件回调
即(CallBack)允许开发者在 LLM 应用程序的各个阶段设置 hook(钩子)。这意味着,无论是日志记录、监控、数据流处理还是其他任何任务,开发者都可以精确地控制和管理。开发者可以通过使用 API 中的回调参数来订阅不同的事件。
2.3、DFA算法
是一种用于字符串匹配的算法,常用于敏感词过滤、关键词搜索等应用中。它可以高效地检测一个给定的文本中是否存在某个预定义的模式(通常是一个字符串)。
DFA 算法的基本思想是将模式(敏感词或关键词)表示为一个有限状态机,其中每个状态代表匹配模式的不同阶段。算法通过读取输入文本的字符并根据当前状态进行状态转换,直到达到终止状态或将整个文本读取完毕。
三、前提条件
3.1.安装虚拟环境
pip install langchain openai
四、技术实现
4.1.敏感词过滤工具类
# -*- coding = utf-8 -*-
import os
class DFAFilter():
def __init__(self):
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
if not isinstance(keyword, str):
keyword = keyword.decode('utf-8')
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
if os.path.exists(path):
with open(path, encoding='UTF-8') as f:
for keyword in f:
self.add(keyword.strip())
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = message.decode('utf-8')
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
return ''.join(ret)
def is_contain_sensitive_word(self, message):
repl = '_-__-'
dest_string = self.filter(message=message, repl=repl)
if repl in dest_string:
return True
return False
if __name__ == "__main__":
dfa = DFAFilter()
dfa.parse("keywords")
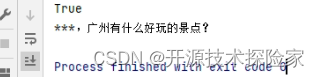
print(dfa.is_contain_sensitive_word("踏马的,广州有什么好玩的景点?"))
print(dfa.filter("踏马的,广州有什么好玩的景点?", "*"))
调用结果:
- 在代码同级目录下,新建一个keywords文件,并写入以下内容:
踏马的
越秀公园
- 执行main方法
4.2.合规性检测
# -*- coding = utf-8 -*-
import os
import sys
import warnings
from typing import Any, Dict
from langchain.chains import LLMChain
from langchain import OpenAI
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.outputs import LLMResult
from langchain_core.prompts import PromptTemplate
from sensitive_word import DFAFilter
warnings.filterwarnings("ignore")
class LegitimacyCallbackHandler(BaseCallbackHandler):
def __init__(self, dfa: DFAFilter,userId:str) -> None:
self.dfa = dfa
self.userId = userId
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
# print('on_chain_start: ', inputs)
result = dfa.is_contain_sensitive_word(message=inputs['question'])
if result:
print(f'用户: {userId}输入的内容命中违禁词')
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
# print('on_chain_end: ', outputs)
result = dfa.is_contain_sensitive_word(message=outputs['text'])
if result:
print(f'模型输出给用户{userId}的内容命中违禁词')
if __name__ == '__main__':
dfa = DFAFilter()
dfa.parse("keywords")
userId = "10001"
handler = LegitimacyCallbackHandler(dfa,userId)
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
os.environ["OPENAI_API_KEY"] = API_KEY
llm = OpenAI(model_name='gpt-3.5-turbo-1106',temperature=0.1, max_tokens=512)
prompt = PromptTemplate.from_template("问题:{question}")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
print(chain.invoke({'question':'踏马的,广州有什么好玩的景点?'}))
调用结果:

在keywords文件中录入了“踏马的”和“越秀公园”两个词,其中“踏马的”命中了输入提示语,而“越秀公园”命中了模型输出结果。
五、附带说明
5.1.合规性检测进阶(骚操作)
4.2.合规性检测 只能记录用户和模型的违规日志,若我们简单的调整一下代码,即能实现用户输入和模型输出的敏感词过滤
# -*- coding = utf-8 -*-
import os
import sys
import warnings
from typing import Any, Dict
from langchain.chains import LLMChain
from langchain import OpenAI
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.prompts import PromptTemplate
from sensitive_word import DFAFilter
warnings.filterwarnings("ignore")
class LegitimacyCallbackHandler(BaseCallbackHandler):
def __init__(self, dfa: DFAFilter,userId:str) -> None:
self.dfa = dfa
self.userId = userId
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> None:
print('用户原始输入内容: ', inputs)
result = dfa.is_contain_sensitive_word(message=inputs['question'])
if result:
print(f'用户: {userId}输入的内容命中违禁词')
filter_question = dfa.filter(message=inputs['question'], repl='')
inputs['question'] = filter_question
print('用户过滤后输入内容: ', filter_question)
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> None:
result = dfa.is_contain_sensitive_word(message=outputs['text'])
if result:
print(f'模型输出给用户{userId}的内容命中违禁词')
outputs['text'] = '重新新开一个话题吧'
if __name__ == '__main__':
dfa = DFAFilter()
dfa.parse("keywords")
userId = "10001"
handler = LegitimacyCallbackHandler(dfa,userId)
API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
os.environ["OPENAI_API_KEY"] = API_KEY
llm = OpenAI(model_name='gpt-3.5-turbo-1106',temperature=0.1, max_tokens=512)
prompt = PromptTemplate.from_template("问题:{question}")
chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler])
print(chain.invoke({'question':'踏马的,广州有什么好玩的景点?'}))
修改langchain包的base.py (langchain > chains > base.py)
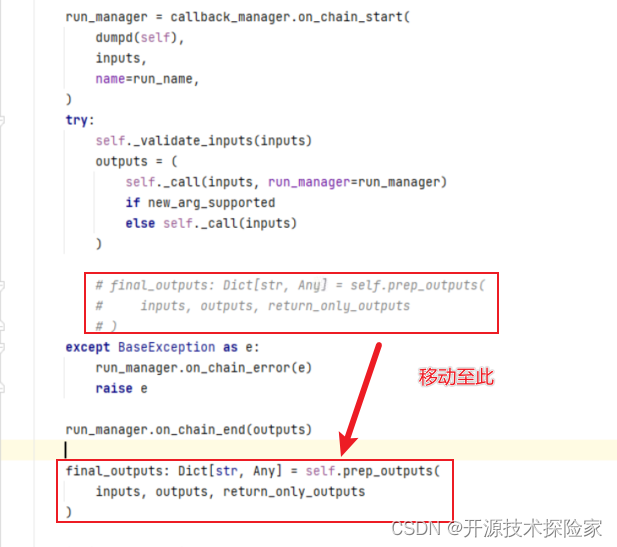
调用结果:

用户输入的内容命中“踏马的”,处理后被替换成“”
模型输出的内容命中“越秀公园”,处理后被替换成“重新新开一个话题吧”
5.2. 可实现的事件回调方法
当事件被触发时,CallbackManager将在每个处理程序上调用适当的方法
class BaseCallbackHandler:
"""Base callback handler that can be used to handle callbacks from langchain."""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Run when LLM starts running."""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Run when Chat Model starts running."""
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""Run on new LLM token. Only available when streaming is enabled."""
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running."""
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when LLM errors."""
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> Any:
"""Run when chain starts running."""
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any:
"""Run when chain ends running."""
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when chain errors."""
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> Any:
"""Run when tool starts running."""
def on_tool_end(self, output: Any, **kwargs: Any) -> Any:
"""Run when tool ends running."""
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when tool errors."""
def on_text(self, text: str, **kwargs: Any) -> Any:
"""Run on arbitrary text."""
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action."""
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""Run on agent end.""
本文转载自: https://blog.csdn.net/qq839019311/article/details/138164690
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。
版权归原作者 开源技术探险家 所有, 如有侵权,请联系我们删除。