
【自然语言处理(NLP)】文本数据处理实践

活动地址:CSDN21天学习挑战赛
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
前言
什么是NLP?
自然语言处理(Natural Language Processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,是一门融语言学、计算机科学、数学于一体的科学,主要用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题问答、文本语义对比、语音识别、中文OCR等方面。
一、文本序列化
(一)、创建数据字典
import jieba
import numpy as np
dict_path ='work/dict.txt'
data_sat ='work/data1.txt'# 'work/data2.txt'中文#创建数据字典,存放位置:dicts.txt。在生成之前先清空dict.txt#在生成all_data.txt之前,首先将其清空withopen(dict_path,'w')as f:
f.seek(0)
f.truncate()
dict_set =set()
train_data =open(data_sat)for data in train_data:
seg = jieba.lcut(data)for datas in seg:ifnot datas is" ":ifnot datas is'\n':
dict_set.add(datas)
dicts =open(dict_path,'w')for data in dict_set:
dicts.write(data +'\n')
dicts.close()
(二)、定义数据函数
defload_vocab(vocab_file):"""Loads a vocabulary file into a dictionary."""
vocab ={}withopen(vocab_file,"r", encoding="utf-8")as reader:
tokens = reader.readlines()for index, token inenumerate(tokens):
token = token.rstrip("\n").split("\t")[0]
vocab[token]= index
return vocab
vocab = load_vocab(dict_path)for k, v in vocab.items():print(k, v)
部分输出结果如图1所示:

(三)、训练数据
train_data =open(data_sat)for data in train_data:
input_ids =[]
input_names =''for token in jieba.cut(data):# print(token)# breakifnot token is" ":ifnot token is'\n':
token_id = vocab.get(token,1)
input_ids.append(token_id)
input_names += token
input_names +=' 'print(input_names)print(input_ids)
部分输出结果如下图2所示:

二、one-hot文本向量化
import numpy as np
#初始数据:每个样本是列表的一个元素(本例中的样本是一个句子,但也可以是一整篇文档)
train_data =open('work/data2.txt')
samples =[]for data in train_data:
samples.append(data)# print(samples)# samples = ['The cat sat on the mat.', 'The dog ate my homework.']#构建数据中所有标记的索引
token_index ={}for sample in samples:#利用 split 方法对样本进行分词。在实际应用中,还需要从样本中去掉标点和特殊字符for word in jieba.lcut(sample):# print(word)if word notin token_index:#为每个唯一单词指定一个唯一索引。注意,没有为索引编号 0 指定单词
token_index[word]=len(token_index)+1print(token_index)#对样本进行分词。只考虑每个样本前 max_length 个单词
max_length =10
results = np.zeros((len(samples), max_length,max(token_index.values())+1))for i, sample inenumerate(samples):# print(sample)# datas = jieba.lcut(sample)#每句话只取10个单词for j, word inlist(enumerate(jieba.lcut(sample)))[:max_length]:
index = token_index.get(word)#将结果保存在 results 中
results[i, j, index]=1.for i inrange(len(samples)):print(f'data:{samples[i][:-1]}')print(f'ont-hot:{results[i]}')
部分输出结果如下图3所示:

三、TF-IDF文本向量化
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
defsklearn_tfidf():
train_data =open('work/data1.txt')
samples =[]for data in train_data:
samples.append(data)
vectorizer = CountVectorizer()#将文本中的词语转换为词频矩阵
X = vectorizer.fit_transform(samples)#计算个词语出现的次数
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)#将词频矩阵X统计成TF-IDF值 for i inrange(len(samples)):print(samples[i])print(tfidf.toarray()[i])
sklearn_tfidf()
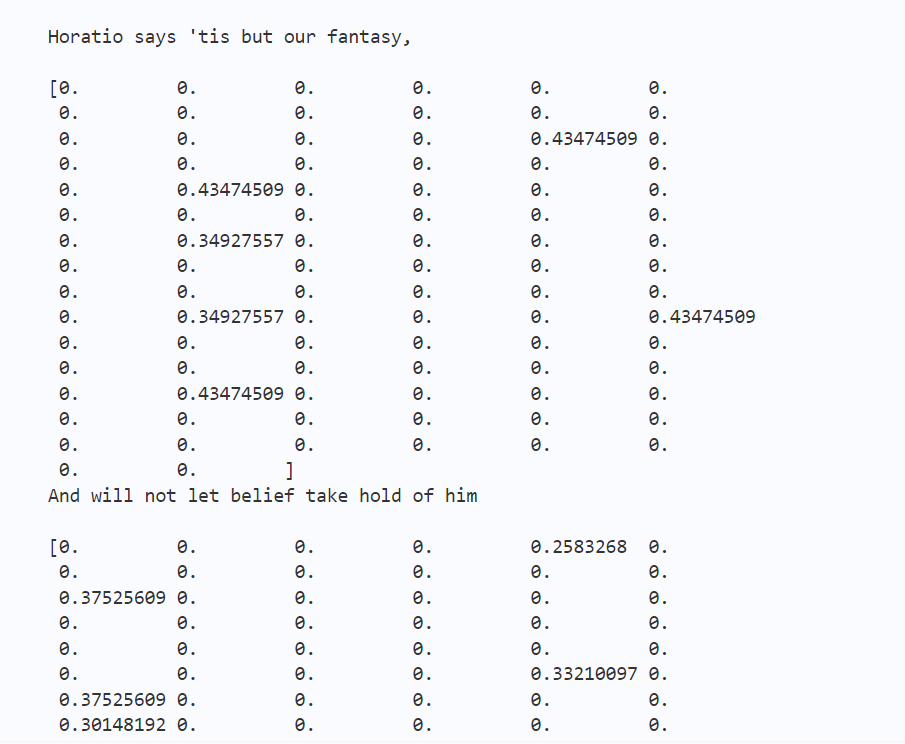
部分输出结果如图4所示:
总结
本系列文章内容为根据清华社出版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~

本文转载自: https://blog.csdn.net/m0_54754302/article/details/126311054
版权归原作者 云曦智划 所有, 如有侵权,请联系我们删除。
版权归原作者 云曦智划 所有, 如有侵权,请联系我们删除。