
概述
- ECAPA-TDNN是说话人识别中基于TDNN的神经网络,是目前最好的单体模型之一
- 关于TDNN,可以参考深入理解TDNN(Time Delay Neural Network)——兼谈x-vector网络结构
ECAPA-TDNN
- TDNN本质上是1维卷积,而且常常是1维膨胀卷积,这样的一种结构非常注重context,也就是上下文信息,具体而言,是在frame-level的变换中,更多地利用相邻frame的信息,甚至跳过 t − 1 , t + 1 t-1,t+1 t−1,t+1的frame,而去对 t − 2 , t + 2 t-2,t+2 t−2,t+2的frame进行连接
- 在ECAPA-TDNN中,更是进一步利用了膨胀卷积,出现了 d i l a t i o n = 2 , 3 , 4 dilation=2,3,4 dilation=2,3,4的情况。此外,还引入了Res2Net,从而获得了多尺度的context,所谓多尺度,指的是各种大小的感受野
- 1维膨胀卷积已经在深入理解TDNN(Time Delay Neural Network)——兼谈x-vector网络结构中讲解清楚,下面先介绍Res2Net
Res2Net
- 经典的ResNet结构如下左图所示,先用 k e r n e l - s i z e = 1 × 1 kernel \text{-} size=1 \times 1 kernel-size=1×1的卷积运算,相当于只针对每个像素点的特征通道进行变换,而不关注该像素点的任何邻近像素,并且是降低特征通道的,所以也被叫做Bottleneck,就好像将可乐从瓶口倒出来,如果是增加特征通道,那么就叫Inverted Bottleneck
1 × 1 1\times1 1×1卷积后,会经过 3 × 3 3\times3 3×3卷积,通常不改变特征通道,如果不需要在最后加上残差连接,那么 s t r i d e = 2 stride=2 stride=2,特征图的分辨率会被下采样,如果需要在最后加上残差连接,那么 s t r i d e = 1 stride=1 stride=1,保持特征图分辨率不变- 最后还会有一个 1 × 1 1\times1 1×1卷积,目的是复原每个像素点的特征通道,使其等于输入时的特征通道,从而能够进行残差连接。整个Bottleneck block形似一个沙漏,中间是窄的(特征通道少),两边是宽的(特征通道多)
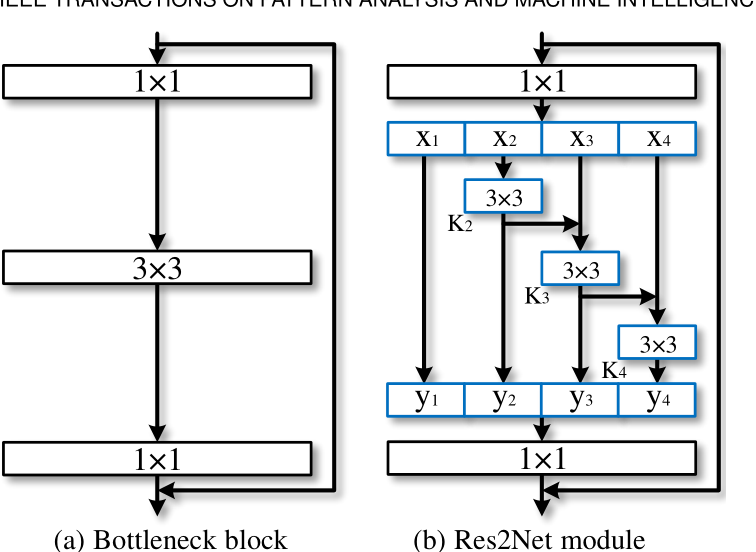
- 而Res2Net则是在中间的 3 × 3 3\times3 3×3卷积进行的微创新,首先将 1 × 1 1\times1 1×1卷积后的特征图,按照特征通道数进行平分,得到 s c a l e scale scale个相同的特征图(这里的 s c a l e scale scale是“尺度”的意思,Res2Net的作用就是多尺度特征,一语双关)
- 第一个特征图保留,不进行变换,这是对前一层特征的复用,同时也降低了参数量和计算量。从第二个特征图开始,都进行 3 × 3 3\times3 3×3卷积,并且当前特征图的卷积结果,会与后一个特征图进行残差连接(逐元素相加),然后,后一个特征图再进行 3 × 3 3\times3 3×3卷积
- 卷积中有一个概念叫感受野,是指当前特征图上的像素点,由之前某一个特征图在多大的分辨率下进行卷积得到的。如下图所示, d i l a t i o n = 1 dilation=1 dilation=1的 3 × 3 3\times3 3×3卷积,其输出特征图的每一个像素点的感受野都是 3 × 3 3\times3 3×3,再进行 d i l a t i o n = 1 dilation=1 dilation=1的 3 × 3 3\times3 3×3卷积,其输出特征图的每一个像素点的感受野都是 5 × 5 5\times5 5×5
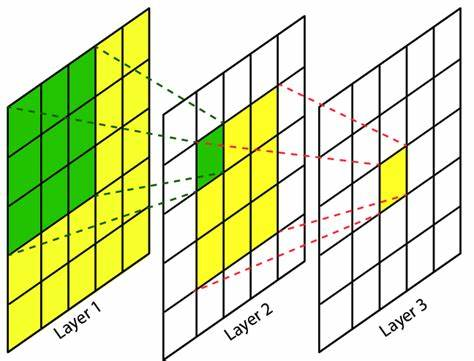
- 因此Res2Net中,第二个特征图的感受野为 3 × 3 3\times3 3×3,第三个特征图的感受野为 5 × 5 + 3 × 3 5\times5+3\times3 5×5+3×3,第四个特征图的感受野为 7 × 7 + 5 × 5 + 3 × 3 7\times7+5\times5+3\times3 7×7+5×5+3×3,以此类推,从而得到多尺度特征
- 所有的卷积结果都会按照特征通道进行串联(concatenate),由于第一个特征图保留,不进行变换,所以后续的特征图维度必须与第一个特征图相同,因此 3 × 3 3\times3 3×3卷积不改变特征通道和分辨率
- 最后的 1 × 1 1\times1 1×1卷积,目的是复原每个像素点的特征通道,使其等于输入时的特征通道,从而能够进行残差连接
- Res2Net可以作为一个即插即用的结构,插入到现有的其他神经网络中,还可以与其他即插即用的结构一起工作,比如SENet和ResNeXt
SENet
- SENet(Squeeze-and-Excitation Networks)是现代卷积神经网络所必备的结构,性能提升明显,计算量不大。基本思路是将一个特征图的每个特征通道,都映射成一个值(常用全局平均池化,即取该特征通道的均值,代表该通道),从而特征图会映射为一个向量,长度与特征通道数一致
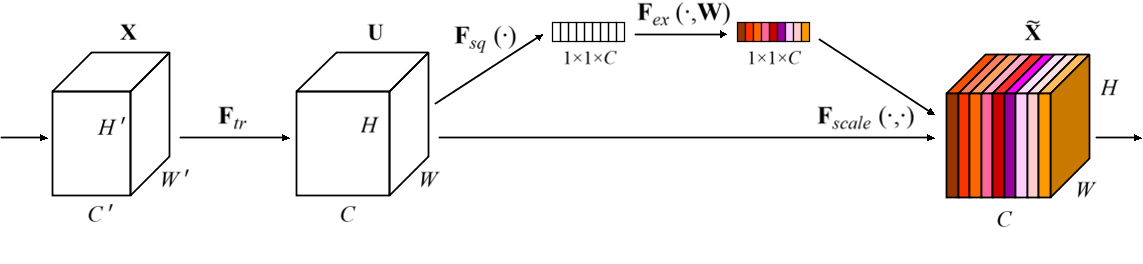
- 之后,对向量进行FC(用1维卷积也行,等价的),输出长度为特征通道数的 1 r \frac{1}{r} r1,然后经过激活函数ReLU,这个过程称为Squeeze(挤压);再进行FC,输出长度与特征通道数一致,然后经过激活函数Sigmoid,这个过程称为Excitation(激励);此时输出向量的每一个值,范围都是 ( 0 , 1 ) (0,1) (0,1),最后用输出向量的每一个值,对输入特征图的对应通道进行加权,这个过程称为Scale(伸缩)
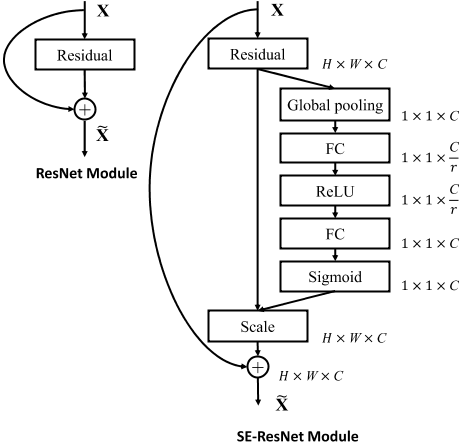
- SENet的结构相当于对特征图的特征通道进行加权,因为每个特征通道的重要性是不一样的,所以让神经网络自行学习每个特征通道的权重,因此是一种Attention机制。并且输入特征图和输出特征图的维度完全一致,从而可以作为一个即插即用的结构,下面是Res2Net与SENet结合得到的结构,被称为SE-Res2Net
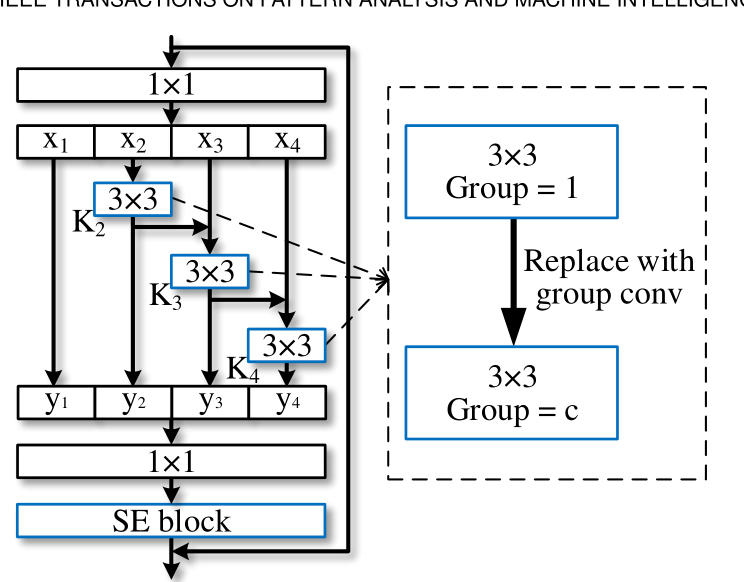
- Res2Net还可以与ResNeXt结合,其实就是将中间的 3 × 3 3\times3 3×3卷积换成 3 × 3 3\times3 3×3分组卷积,不过ECAPA-TDNN中没有用到,就不再赘述了,接下来介绍ECAPA-TDNN的具体设计
回到ECAPA-TDNN
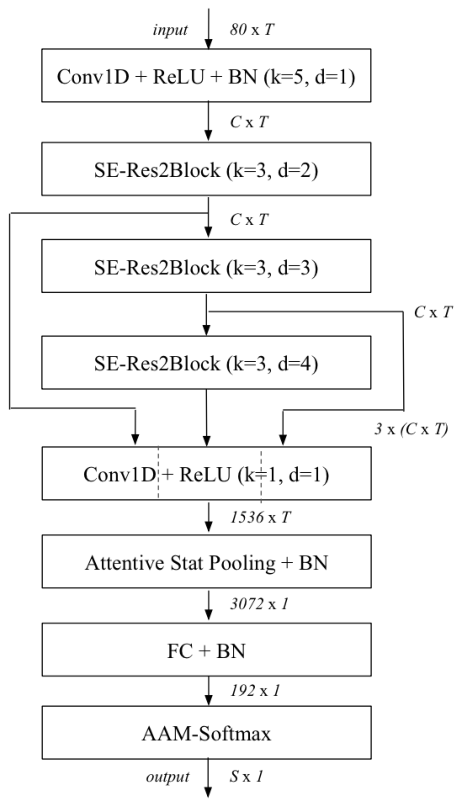
- 在ECAPA-TDNN中所用的Res2Net,是上述结构中的2维卷积全部换成1维卷积,采用的中间 k = 3 k=3 k=3卷积(1维卷积,不能用 3 × 3 3\times3 3×3表示,以下都用 k = 3 k=3 k=3代替)为膨胀卷积,并且随着网络深度增加, d i l a t i o n dilation dilation分别为 2 , 3 , 4 2,3,4 2,3,4。ECAPA-TDNN的结构图如下,SE-Res2Block后面括号内的参数,指的是Res2Block的中间 k = 3 k=3 k=3卷积的参数
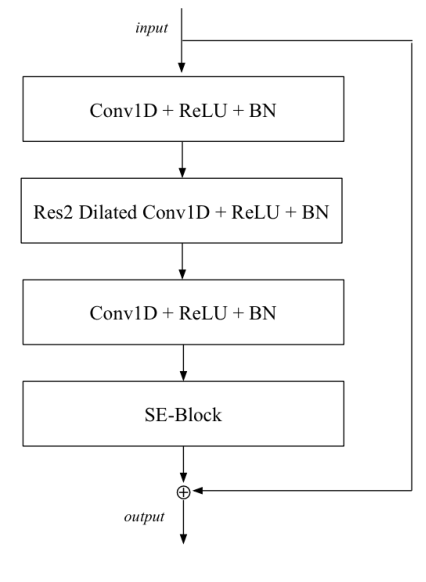
- SE-Res2Block的内部,如下图所示,夹着Res2的两个CRB(Conv1D+ReLU+BN)结构的参数为 ( k = 1 , d = 1 ) (k=1,d=1) (k=1,d=1),中间的Res2, s c a l e = 8 scale=8 scale=8,之后的运算与上述Res2Net一致,不过每个 k = 3 k=3 k=3卷积都是膨胀卷积,并且都会接ReLU和BN,从而形成Res2 Dilated Conv1D+ReLU+BN的结构
- 最后的SE-Block是在特征维度进行的,也就是将T个frame的特征,在每个特征维度求平均,得到的向量,长度与特征维度一致,之后的运算与上述SENet一致
- 之前提到ResNet结构是沙漏型的,但是ECAPA-TDNN的frame-level变换中的ResNet结构,除了Res2会把特征维度进行平分外,其余的运算都没有发生特征维度的变化,关于frame-level变换,详见深入理解TDNN(Time Delay Neural Network)——兼谈x-vector网络结构。ECAPA-TDNN有两个版本,主要区别就在于frame-level的变换中,特征维度是512还是1024
- frame-level变换之后,则是统计池化(Statistics Pooling),ECAPA-TDNN采用了ASP作为统计池化层,并且还进行了一些改进
ASP
- ASP(Attentive Statistics Pooling)是2018年提出的,至今仍然广为使用的带有Attention的统计池化层,直到2022年才出现竞争对手(一种带有Multi-head Attention的统计池化)
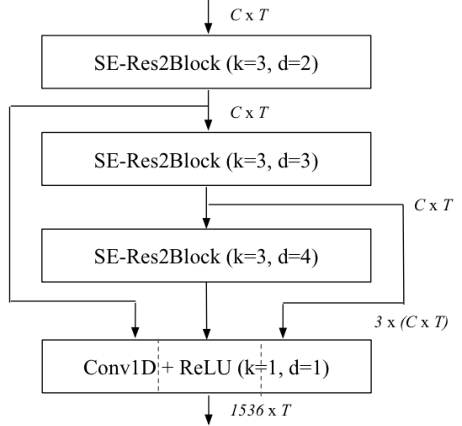
- ECAPA-TDNN中对ASP进行了改进,首先将之前3个SE-Res2Block的输出,按照特征维度进行串联,假设frame-level变换中的特征维度是512,由于3个SE-Res2Block的输出维度都是 ( b s , 512 , T ) (bs,512,T) (bs,512,T),所以串联之后是 ( b s , 512 ∗ 3 , T ) (bs,512*3,T) (bs,512∗3,T),之后经过一个CRB结构,输出维度固定为 ( b s , 1536 , T ) (bs,1536,T) (bs,1536,T),即便frame-level的特征维度是1024,该CRB的输出维度也不变。如下图所示
- 对特征图 ( b s , 1536 , T ) (bs,1536,T) (bs,1536,T),记为h,按照T维度计算每个特征维度的均值和标准差,如上图的TSTP公式所示(符号 ⊙ \odot ⊙表示哈达玛积,即对应项相乘,两个因子的维度必须相同,从而结果的维度与因子的维度也相同),从而T维度消失,得到的均值和标准差维度均为 ( b s , 1536 ) (bs,1536) (bs,1536)
- 之后的操作很神奇,将均值在T维度重复堆叠T次,维度恢复为 ( b s , 1536 , T ) (bs,1536,T) (bs,1536,T),对标准差也是堆叠,维度恢复为 ( b s , 1536 , T ) (bs,1536,T) (bs,1536,T),接着将特征图、均值和标准差在特征维度进行串联,得到的特征图维度为 ( b s , 1536 ∗ 3 , T ) (bs,1536*3,T) (bs,1536∗3,T),记为H
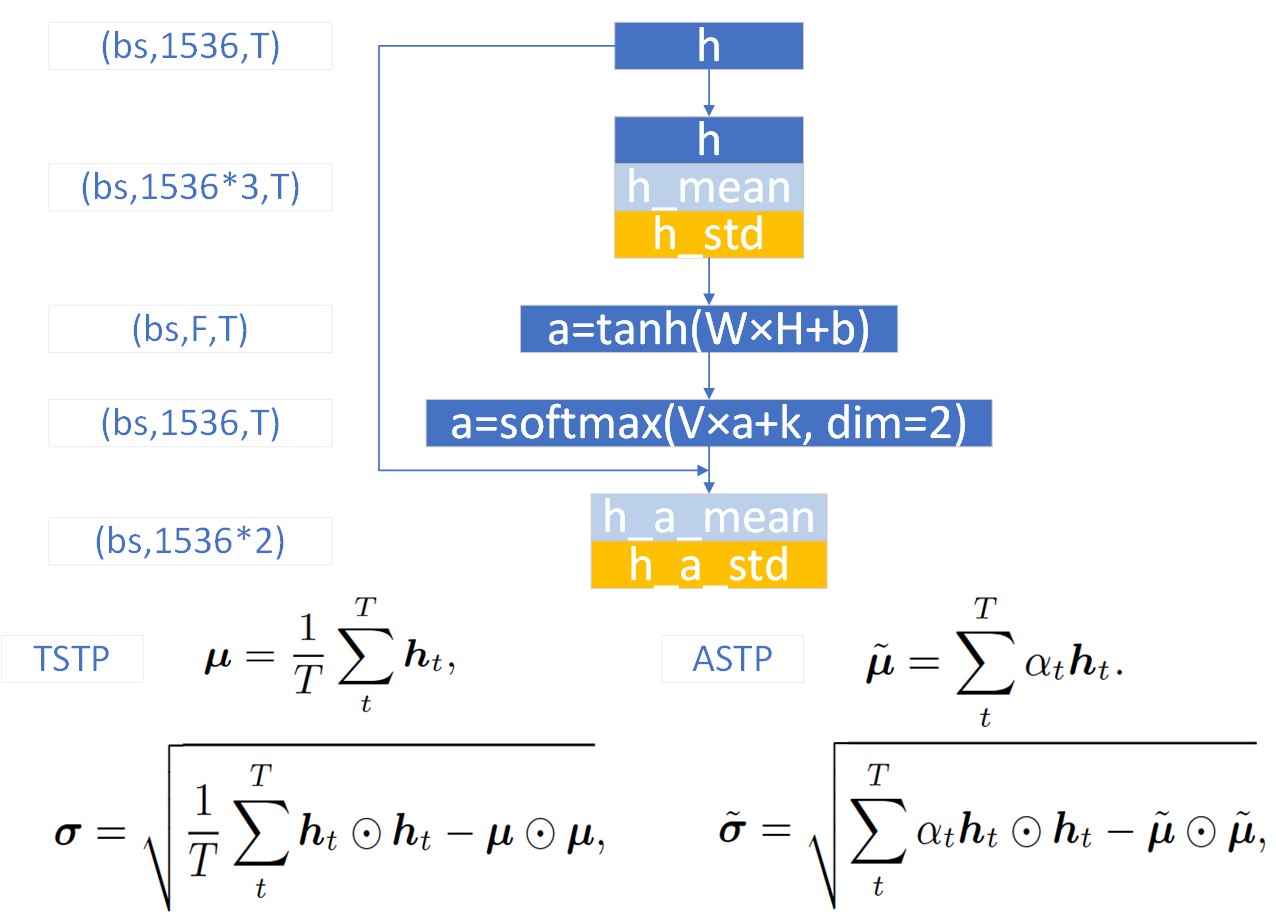
- 对H进行1维卷积,等价于上图的 W × H + b W\times H+b W×H+b,目的是将每个frame的特征从1536*3维降维映射到F维,F可取128,然后经过tanh激活函数,得到特征图a,维度为 ( b s , F , T ) (bs,F,T) (bs,F,T)
- 对a进行1维卷积,等价于上图的 V × a + k V\times a+k V×a+k,目的是将每个frame的特征从F维恢复映射到与h相同的维度,即1536,然后在T维度,进行softmax激活,得到特征图a,维度为 ( b s , 1536 , T ) (bs,1536,T) (bs,1536,T)
- 此时的特征图a的每一行特征,在T维度上求和,都等于1,这是softmax激活的效果,又因为与h的维度相同,所以可以将a视为一种Attention分数,利用上图的ASTP公式,对h求基于Attention的均值和标准差,关于Attention分数,可以参考深入理解Self-attention(自注意力机制)
- 基于Attention的均值和标准差,维度都为 ( b s , 1536 ) (bs,1536) (bs,1536),再将它们按照特征维度进行串联,得到ASP最终的输出,维度为 ( b s , 1536 ∗ 2 ) (bs,1536*2) (bs,1536∗2),在ECAPA-TDNN中,ASP之后还会接一个BN
BN
- 这一节是讲BN(Batch Normalization)的,可能观众会感觉我太啰嗦了,怎么连BN都要讲,主要是ECAPA-TDNN是一个完全的TDNN结构,连BN都是1维的,所以怕大家一下子转不过来弯,下面主要讲解1维BN,自认对BN滚瓜烂熟的观众,可跳过本节 t o r c h . n n . B a t c h N o r m 1 d ( n u m - f e a t u r e s , e p s = 1 e − 05 , m o m e n t u m = 0.1 , a f f i n e = T r u e , t r a c k - r u n n i n g - s t a t s = T r u e , d e v i c e = N o n e , d t y p e = N o n e ) torch.nn.BatchNorm1d(num \text{-} features, eps=1e-05, momentum=0.1, affine=True, track \text{-} running \text{-} stats=True, device=None, dtype=None) torch.nn.BatchNorm1d(num-features,eps=1e−05,momentum=0.1,affine=True,track-running-stats=True,device=None,dtype=None)
- BN中的 n u m - f e a t u r e s num \text{-} features num-features是理解BN的关键,对于图像任务, n u m - f e a t u r e s num \text{-} features num-features要等于输入特征图的通道数,而对于音频任务, n u m - f e a t u r e s num \text{-} features num-features要等于 ( b s , F , T ) (bs,F,T) (bs,F,T)中的F
- 也就是说,BN必然是作用于图像的特征图通道,或者音频中frame的每个特征的, n u m - f e a t u r e s num \text{-} features num-features是告诉BN,均值和标准差,这两个向量的长度
- BN计算均值和标准差的操作,与上述ASP的第一步,计算h_mean和h_std是类似的,不过计算的范围是在一个batch中 μ B = 1 b s ∗ T ∑ t b s ∗ T h t σ B 2 = 1 b s ∗ T ∑ t b s ∗ T ( h t − μ ) 2 \begin{aligned} \mu_B &= \frac{1}{bsT} \sum_{t}^{bsT} h_t \ \sigma_B^2 &= \frac{1}{bsT} \sum_{t}^{bsT} (h_t - \mu)^2 \end{aligned} μBσB2=bs∗T1t∑bs∗Tht=bs∗T1t∑bs∗T(ht−μ)2
- 得到一个batch的统计量后,BN的输出也就确定了,不过需要先将 μ B \mu_B μB和 σ B 2 \sigma_B^2 σB2重复堆叠成 ( b s , F , T ) (bs,F,T) (bs,F,T)的大小,与输入BN的特征图H的维度相同,才能让其与H进行运算。在训练时,BN的输出 y t r a i n i n g = γ ∗ H − μ B σ B 2 + ϵ + β y_{training}=\gamma * \frac{H-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} +\beta ytraining=γ∗σB2+ϵH−μB+β
- 其中 - ϵ \epsilon ϵ是用于稳定计算的,可取 1 0 − 5 10^{-5} 10−5- γ \gamma γ和 β \beta β是两个可学习参数,用于将输出进行伸缩和平移,提高模型的表达能力
- 此外,BN内部还有两个用于估计全局统计量的均值和标准差向量,在训练时,这两个向量根据每个batch的统计量进行更新,在测试时,BN会采用全局统计量对特征图进行规范化 μ s a m p l e = μ B σ s a m p l e 2 = b s ∗ T b s ∗ T − 1 σ B 2 μ r u n n i n g = ( 1 − m o m e n t u m ) ∗ μ r u n n i n g + m o m e n t u m ∗ μ s a m p l e σ r u n n i n g 2 = ( 1 − m o m e n t u m ) ∗ σ r u n n i n g 2 + m o m e n t u m ∗ σ s a m p l e 2 y e v a l u a t i n g = γ ∗ H − μ r u n n i n g σ r u n n i n g 2 + ϵ + β \begin{aligned} \mu_{sample}&=\mu_B \ \sigma_{sample}^2&=\frac{bsT}{bsT-1} \sigma_B^2 \ \mu_{running}&=(1-momentum)\mu_{running}+momentum\mu_{sample} \ \sigma_{running}^2&=(1-momentum)\sigma_{running}^2+momentum\sigma_{sample}^2 \ y_{evaluating}&=\gamma * \frac{H-\mu_{running}}{\sqrt{\sigma_{running}^2+\epsilon}} +\beta \end{aligned} μsampleσsample2μrunningσrunning2yevaluating=μB=bs∗T−1bs∗TσB2=(1−momentum)∗μrunning+momentum∗μsample=(1−momentum)∗σrunning2+momentum∗σsample2=γ∗σrunning2+ϵH−μrunning+β
- 其中 - 下标 r u n n i n g running running表示采用移动平均(running average)的方法对全局统计量进行估计- 系数 m o m e n t u m momentum momentum是对当前batch的统计量的权重,可取 0.1 0.1 0.1
尾声
- 在ASP+BN之后,接FC+BN,得到嵌入码,长度是192,最后接损失函数即可
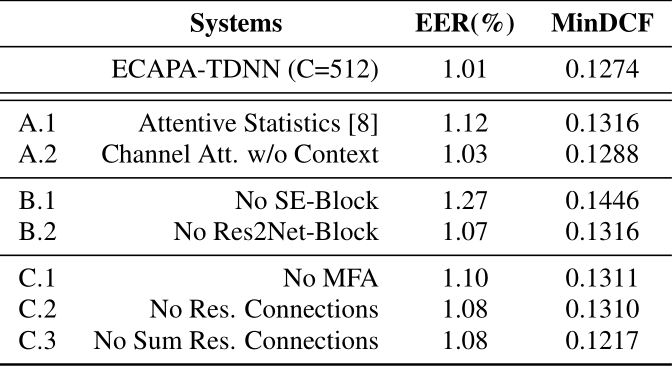
- 总结一下ECAPA-TDNN的改进 - 对ASP进行了改进- 引进了SE-Res2Block- 将多层特征聚合(原文中称为Multi-layer feature aggregation),再送入统计池化层- 最后一点,也是有争议的一点改进,原文中称为Multi-layer feature summation,也就是在frame-level的变换中 - frame-layer2(第二个SE-Res2Block)的输入是frame-layer1(第一个SE-Res2Block)和frame-layer0(第一个CRB)的逐元素相加- frame-layer3(第三个SE-Res2Block)的输入是frame-layer2、frame-layer1以及frame-layer0的逐元素相加- 实验结果是下图中的C.3,可以看到,如果没有Multi-layer feature summation,EER升高了,但是minDCF降低了,由于VoxSRC是以minDCF作为最终性能指标的,所以Multi-layer feature summation没有在一些开源代码中被实现
本文转载自: https://blog.csdn.net/m0_46324847/article/details/128613853
版权归原作者 DEDSEC_Roger 所有, 如有侵权,请联系我们删除。
版权归原作者 DEDSEC_Roger 所有, 如有侵权,请联系我们删除。