
RAG 是一个先选内容再做生成的系统;retriever 不搜索文档,它搜索 chunks。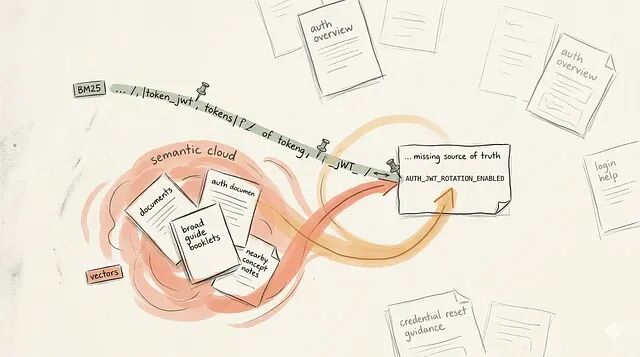
chunks 有问题了那么检索还没开始就已经完蛋了,所以我们可以用结构感知切分修这一点,把标题、代码块、警告框保持在一起。
但 chunks 完全连贯并不意味着就没事了,retriever 还需要正确的搜索信号才能命中它们。一个干净 chunk 如果搜索算法没法把用户意图对到文本上,它就毫无用处。这就是 lexical 和 semantic search 分不同的地方。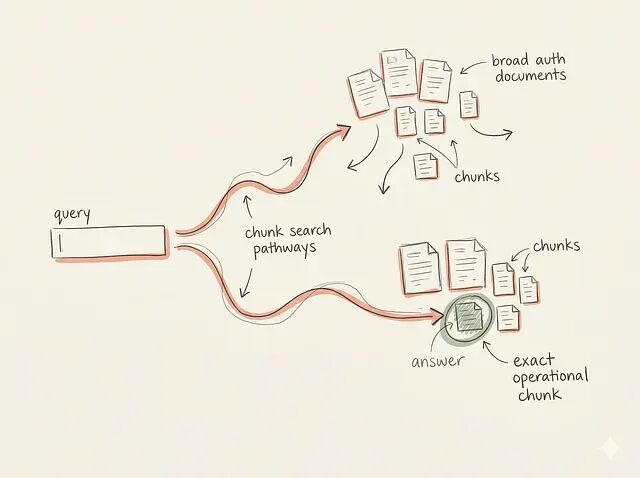
技术性查询的核心问题
并非所有查询行为都一样。在技术文档、内部知识库或支持工单上做搜索系统,你会看到一种非常具体的用户意图组合。
有些用户问的是概念性问题:某个系统怎么工作、某个架构决策为什么要这么做。他们用自然语言描述 bug 的症状,不知道确切的错误名。
另一些用户问的是高度具体的查找:从终端粘贴一段错误代码、搜索一条 API endpoint 路径、查类名或配置 flag。
这两类查询在根本上是两方向。精确标识符查找要的是精度;概念性故障排查要的是语义理解。一个 retriever 很少能把两边都处理得一样好。所以检索质量被查询类型塑造的程度,跟被文档质量塑造的程度差不多。
"哪种 retriever 最好?"通常太模糊以致没有用,其实正确的问题应该是:你的系统实际收到的是什么样的查询。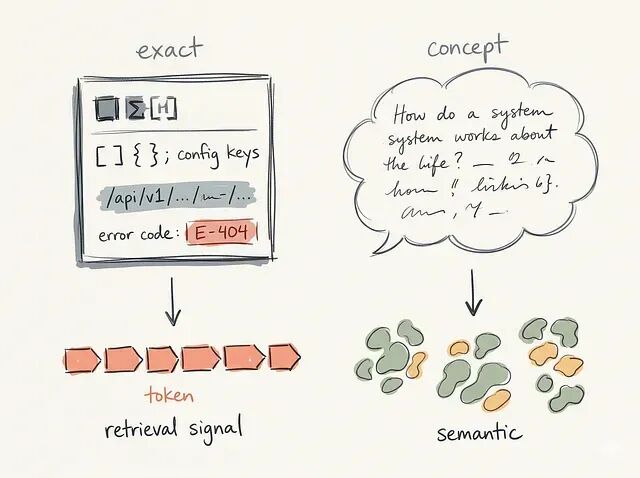
BM25 擅长什么
BM25 是搜索引擎用来估计文档与查询相关性的一个排名函数。它针对精确词项重叠和稀有词项重要性做优化,本质上是一个 lexical 匹配引擎。
要理解为什么它对某些任务表现这么好,从数学角度讲就可以,BM25 是 TF-IDF 的演化:根据查询词项在文档中出现的频率打分,同时惩罚那些在整个 corpus 中过于常见的词。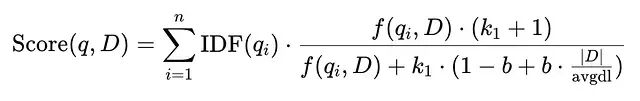
公式看着复杂其实很简单。
k_1
控制词频饱和:文档提一次错误代码是相关的,提二十次更相关,但绝不是相关二十倍。
k_1
让这个增长曲线趋于饱和。
b
控制长度归一化 —— 长文档天然包含更多词,算法会相对惩罚它,与一篇包含相同关键词的短文档比。
BM25 的强项在于找 config keys、environment variables、API routes、product SKUs、error strings、exact command names、version identifiers。这类查询是稀疏且精确的,lexical 精度比语义相似性更要紧。用户搜
PAYMENTS_API_TIMEOUT
时,他要的是包含那个字符串的文档,不是一篇关于 billing latency 延迟的文档。
下面是用
bm25s
库在 Python 中实现一个快速、现代的 BM25 retriever。
import bm25s
import Stemmer
def build_bm25_retriever(corpus: list[str]) -> bm25s.BM25:
# We use a stemmer to match variations like "running" and "run"
stemmer = Stemmer.Stemmer("english")
# Tokenize the corpus and remove common stop words
tokens = bm25s.tokenize(corpus, stopwords="en", stemmer=stemmer)
# Initialize and index the BM25 model
retriever = bm25s.BM25(corpus=corpus)
retriever.index(tokens)
return retriever
def bm25_search(retriever: bm25s.BM25, query: str, k: int = 5) -> list[dict]:
stemmer = Stemmer.Stemmer("english")
q_tokens = bm25s.tokenize(query, stemmer=stemmer)
# Retrieve the top-k documents and their scores
docs, scores = retriever.retrieve(q_tokens, k=k)
results = []
for i in range(docs.shape[1]):
results.append({
"content": docs[0, i],
"score": float(scores[0, i])
})
return results
BM25 在用户改述时会失败,对概念性问题失败,对模糊自然语言也很挣扎。用户搜 "how to fix database crash"、文档写的是 "resolving postgres memory exhaustion",BM25 会因为词面对不上而打很低的分。
Vector 检索擅长什么
Vector 检索是另一个方向,他针对语义相似性和概念接近性优化。
embedding 模型不看一个词的精确字符,而是把文本 chunks 映射到一个高维向量空间。模型被训练成把含义相近的概念在该空间中放得很近。"dog" 和 "puppy" 共享零个字符,向量却几乎指向同一方向。
查询时系统把它嵌入到同一空间,再用 Approximate Nearest Neighbor 算法高效找出离查询向量最近的文档向量。
Vector 检索在 "How do I…?" 类问题上表现很好。它能处理那些与官方文档措辞不同的故障排查查询,擅长概念检索,比如说当用户描述意图但说不出作者用的精确措辞时。
下面是用 Qdrant 设置一个稠密 vector 搜索。
from qdrant_client import QdrantClient, models
from openai import OpenAI
def build_vector_index(chunks: list[dict], collection_name: str = "docs") -> QdrantClient:
# Using in-memory mode for demonstration
client = QdrantClient(":memory:")
client.create_collection(
collection_name=collection_name,
vectors_config=models.VectorParams(
size=1536,
distance=models.Distance.COSINE
),
)
oai = OpenAI()
texts = [c["content"] for c in chunks]
# Generate embeddings for all chunks
resp = oai.embeddings.create(input=texts, model="text-embedding-3-small")
vectors = [e.embedding for e in resp.data]
# Insert into the database with payload metadata
points = []
for i, chunk in enumerate(chunks):
points.append(
models.PointStruct(
id=i,
vector=vectors[i],
payload={"content": chunk["content"], **chunk.get("meta", {})}
)
)
client.upsert(collection_name=collection_name, points=points)
return client
def vector_search(client: QdrantClient, query: str, collection_name: str = "docs", k: int = 5) -> list[dict]:
oai = OpenAI()
q_vec = oai.embeddings.create(input=[query], model="text-embedding-3-small").data[0].embedding
hits = client.query_points(
collection_name=collection_name,
query=q_vec,
limit=k,
).points
results = []
for hit in hits:
results.append({
"content": hit.payload["content"],
"score": hit.score,
"id": hit.id
})
return results
Vectors 在精确标识符、短而隐晦的查询、稀有 token、版本敏感的查找上失败。因为它经常返回语义相关、操作上却没用的宽泛文档。
各自的失败方式不一样
BM25 和 vector search 的失败不是边缘情况,是因为算法处理文本的方式。
要理解为什么 embedding 模型在精确关键词匹配上会失败,看一下 tokenization。现代 embedding 模型用 subword tokenizer。把
AUTH_JWT_ROTATION_ENABLED
传进去,它会按统计频率切成 sub-tokens。
embedding 模型基于这些片段算一个复杂的表示并理解大致概念。它知道这个字符串和 authentication、rotation 相关,却丢失了精确字符串本身的严格身份。这个字符串的向量可能最终和
enable_jwt_auth_rotation
的向量挨得很近 —— 但找这个具体环境变量的开发者要的是精确匹配。
BM25 没这个毛病,它把精确字符串当作一个独立 token。查询里包含那个字符串,数学就重重奖励匹配它的文档。
所以Hybrid search 不是为了显得聪明而堆出来的复杂性,而是lexical 和 semantic 检索以完全不同方式失败之后才会去构建的东西。
具体例子
BM25 在精确标识符主导相关性时取胜。用户搜
POST /v2/invoices
,要的是该 endpoint 的精确 API reference;搜
billing-worker
,要的是该具体服务的日志或 runbook;搜
RetryPolicyExponentialBackoff
,要的是某个类定义。BM25 会瞬间命中。Vector search 给回来的会是关于"处理重试"或"创建 invoice"的通用文档。
而Vectors 在语义错配时胜出。用户问「How do we safely roll back the billing worker?」,vector search 能理解意图,找到那篇标题叫「Reverting Deployments for Payment Services」的事故响应指南。BM25 在这里会失败,"safely"、"roll back"、"billing worker" 这些词不太可能在目标文档里以那个组合出现。
Hybrid 在查询同时混合精确词与语义意图时取胜。「How do I debug PAYMENTS_API_TIMEOUT in staging?」要的是错误代码的精确性 + debug 这个词的语义理解。「What changed in the auth migration after version 3?」需要理解 migration 概念,同时严格匹配版本号。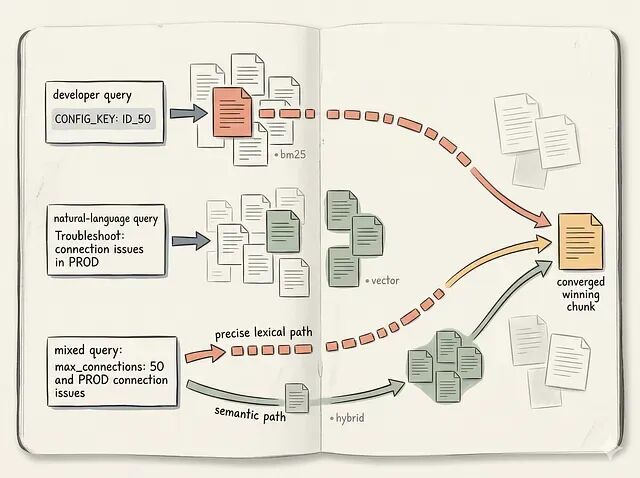
Hybrid Search 实际上怎么工作
hybrid search 的高层模式是:用 BM25 检索一个 top-K 候选列表;用 vector search 单独检索另一个 top-K 候选列表;把两个集合并起来,把它们的排名组合起来。
直接把 BM25 分数加到 cosine similarity 分数上是不行的,因为两者尺度完全不同。BM25 分数可能是 18.5,cosine similarity 分数始终在 -1 到 1 之间。直接相加,BM25 分数会完全压过 cosine similarity。
这就是 Reciprocal Rank Fusion 存在的原因。RRF 完全忽略原始分数,只看文档在每个列表里的 rank。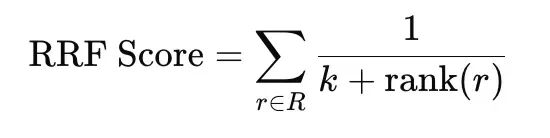
k
常量通常设为 60,作用是把曲线平滑化,让排第 1 的结果不会完全压过排第 2、第 3 的结果。如果一个文档在 vector search 里排第 1、在 BM25 里排第 4,会拿到一个高的组合分;如果它在 vector search 里排第 2、在 BM25 里完全没出现,仍能拿到一个不错的分数。同时出现在两个列表里的文档,通常会击败只出现在一个列表里的文档。
下面是融合步骤的一个Python 实现。
def reciprocal_rank_fusion(*result_lists: list[dict], k: int = 60, top_n: int = 5) -> list[dict]:
scores: dict[str, float] = {}
best_docs: dict[str, dict] = {}
for results in result_lists:
for rank, result in enumerate(results):
# We need a unique identifier to deduplicate chunks across lists
# In a real system, use the chunk ID. Here we use the first 100 chars.
doc_id = result.get("id", result["content"][:100])
if doc_id not in scores:
scores[doc_id] = 0.0
# Add the RRF penalty based on the rank
scores[doc_id] += 1.0 / (k + rank + 1)
# Keep the document payload for the final output
if doc_id not in best_docs:
best_docs[doc_id] = result
# Sort the documents by their new RRF score in descending order
ranked_ids = sorted(scores, key=scores.__getitem__, reverse=True)[:top_n]
final_results = []
for doc_id in ranked_ids:
doc = best_docs[doc_id].copy()
doc["rrf_score"] = scores[doc_id]
final_results.append(doc)
return final_results
Hybrid search 不是简单跑两个 retriever 完事。融合步骤是架构里关键的一环,把两个有噪声的 retriever 草率地拼起,结果仍然会有噪声。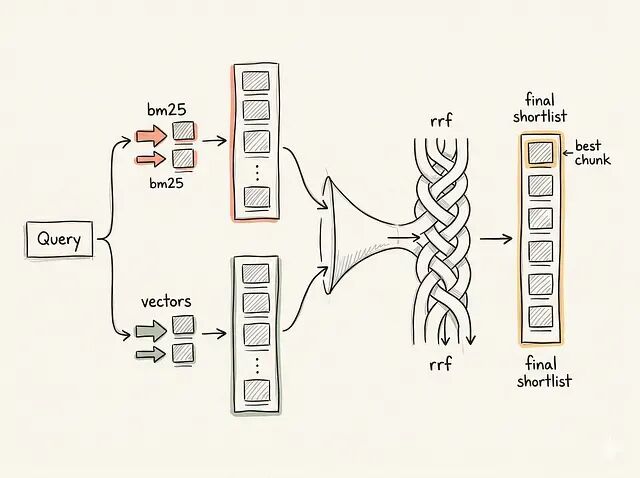
Metadata 过滤仍然重要
哪怕 lexical 和 semantic 信号都完美,也仍然可能出错 —— 版本错了、服务错了、环境错了。
用户要 staging 数据库迁移 runbook,BM25 和 vector search 如果纯靠文本,很可能把生产数据库迁移 runbook 排到 top。文本几乎一样、语义含义也是,唯一差别是目标环境。
所以Hybrid 检索不能替代好的 metadata,最佳工作方式是:metadata 先把候选集收窄,给 chunks 打上 service、environment、document type、version、owner 的 tag。
执行搜索时,把过滤器与查询一起传进去。在 Qdrant 里,构造一个 filter 对象传给 query 方法。数据库会在 vector 相似度计算之前或期间,把搜索空间限制在符合 filter 的 chunks 上。这样能保证用户明确问 staging 时,不会拿到 production 指令。
Chunking 在 Hybrid Search 里的角色
BM25 搜索 chunks,vector search 搜索 chunks,reranker 给 chunks 打分。chunks 有问题那么BM25 找到的是坏的精确文本、vectors 找到的是坏的语义片段、hybrid search 只是把两个方向上坏的证据拼起来。
把文档切成 50-token 的小 chunks,BM25 失去词频优势 —— 一个词在小 chunk 里可能只出现一次,数学没法把它的相关性推上去。切成 1000-token 的大 chunks,vector search 又会被稀释 —— embedding 模型把太多不同概念平均掉,cosine similarity 跌下来。
Hybrid 检索救不了一个已经摧毁原文档含义的 chunking 策略,结构感知切分仍然得做。
怎么正确评估 Hybrid Search
搜索工程里最大的反模式是只用自然语言问题评估系统,然后下结论说 vectors 更好。如果只测「How do I deploy?」这种查询,vector search 每次都赢。
所以得用不同查询类型构建评估集才能看清真实情况:identifier 桶、conceptual 桶、mixed 桶。
下面这个 benchmark 脚本可以证明哪种 retriever 最适合具体数据。
from dataclasses import dataclass
@dataclass
class EvalCase:
query: str
expected_substring: str
query_type: str # "identifier", "conceptual", or "mixed"
def evaluate_retrievers(cases: list[EvalCase], retrievers: dict[str, callable], k: int = 5) -> dict:
report = {name: {"total_hits": 0, "by_type": {}} for name in retrievers}
for case in cases:
for name, search_fn in retrievers.items():
# Execute the search function
results = search_fn(case.query, k=k)
# Check if the expected answer is in the top-k chunks
top_contents = [r["content"] for r in results]
found = any(case.expected_substring in content for content in top_contents)
# Record the metrics
report[name]["total_hits"] += int(found)
q_type = case.query_type
if q_type not in report[name]["by_type"]:
report[name]["by_type"][q_type] = {"hits": 0, "total": 0}
report[name]["by_type"][q_type]["total"] += 1
report[name]["by_type"][q_type]["hits"] += int(found)
# Calculate final hit rates
total_cases = len(cases)
for name in report:
report[name]["overall_hit_rate"] = report[name]["total_hits"] / total_cases if total_cases else 0
for q_type, stats in report[name]["by_type"].items():
stats["hit_rate"] = stats["hits"] / stats["total"] if stats["total"] else 0
return report
在真实技术 corpus 上跑这个 benchmark结果模式会非常清楚,BM25 一致地命中标识符,但概念查询失败;vector search 翻转过来,概念上表现出色,精确字符串漏掉;hybrid search 把两边都接住,覆盖绝大多数。
所以要不要上 hybrid search,应该由观察到的查询失败来论证。要测的是 top-K 检索命中率、来源有用性、按查询类型分的性能。
最后配上 Reranking
Hybrid search 解决了 lexical 与 semantic 错配,但它没解决的是有噪声的候选排序。hybrid pipeline 可能检索出 20 个 chunks,你真正需要的那个可能排在第 14 位;宽泛但相关的 chunks 可能排在精确操作步骤的前面;陈旧但语义相关的文档仍可能赢下 RRF 的计算。
把 lexical 和 semantic 候选合并之后,下一个问题是:哪些候选实际进得了最终 prompt。token 预算摆在那里,把 20 个 chunks 全喂给语言模型还期待完美答案是不现实的。
reranking 在这里成为下一个杠杆点。需要 Cross-Encoders、LLM rerankers,以及在生成之前把 hybrid 候选完美排序,这样才能得到最好的结果。
by Anubhav