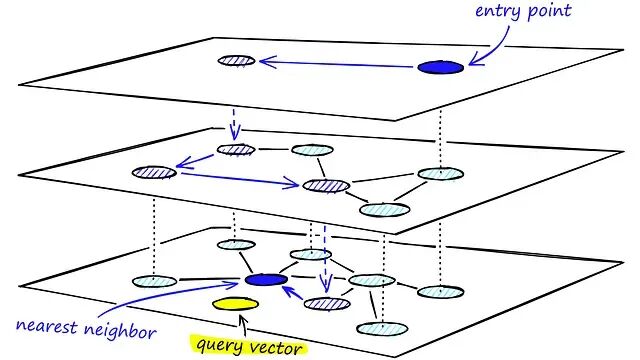
向量相似性搜索详解:Flat Index、IVF 与 HNSW
Flat Index、IVF 和 HNSW:你需要了解的向量搜索算法
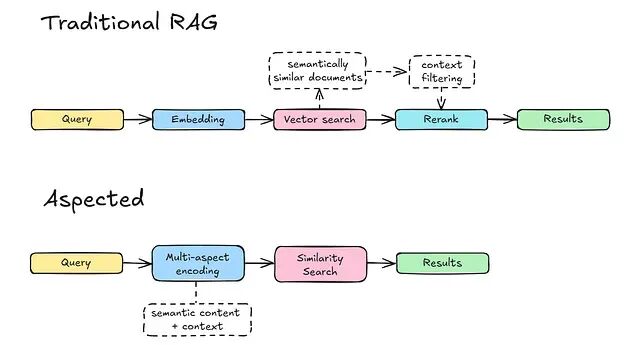
多 Aspect Embedding:将上下文信号编入向量相似性计算的检索架构
本文分析传统向量数据库架构的过滤与检索机制,并介绍 Aspected 的 Aspect Database:一个面向 AI 系统的上下文感知检索引擎
【拥抱AI】对比embedding模型gte-Qwen2-7B-instruct和bge-m3:latest(三)
优势:指令跟随能力、多任务处理、大规模参数。性能:在文本生成、问答系统、文本分类、情感分析、命名实体识别、语义匹配等任务中表现优秀,生成质量和准确性较高。适用场景:需要生成高质量的文本或构建复杂的对话系统。优势:多模态能力、预训练、资源需求较低。性能:在多模态任务(如图像标注、多模态情感分析)、文本
如何使用OpenAI文本Embedding模型构建AI系统
01.Embeddings 向量与 Embedding 模型简介Embedding 向量是人工智能(AI)中的一个核心概念,它将复杂的非结构化数据(如图像、文本、视频或音频文件等)以机器可以理解和处理的数值向量来表示。这些向量能够捕捉数据中的语义含义和关系,帮助 AI 模型更有效地分析、比较和生成内
LangChain——Embedding 智谱AI
Embedding嵌入创建一段文本的矢量表示。这很有用,因为这意味着我们可以考虑向量空间中的文本,并执行语义搜索之类的操作,在其中查找向量空间中最相似的文本片段。LangChain 中的基类Embeddings提供了两种方法:一种用于嵌入文档,另一种用于嵌入查询。前者采用多个文本作为输入,而后者采用
【AI知识点】词嵌入(Word Embedding)
词嵌入(Word Embedding)是自然语言处理(NLP)中的一种技术,用于将词语或短语映射为具有固定维度的实数向量。这些向量(嵌入向量)能够捕捉词语之间的语义相似性,即将语义相近的词映射到向量空间中距离较近的位置,而语义相异的词会被映射到较远的位置。词嵌入是文本表示学习的核心,广泛应用于文本分
前端大模型入门:编码(Tokenizer)和嵌入(Embedding)解析 - llm的输入
大模型并不能直接理解文字等数据,所以需要利用编码+嵌入.本文利用两个js库来介绍了对比了二者的作用,看完立刻试试吧
【AIGC】AI如何匹配RAG知识库: Embedding实践,语义搜索
Embedding是一种将高维数据映射到低维空间的技术。在NLP中,Embedding通常用于将单词、句子或文档转换为连续的向量表示。这些向量不仅保留了原始数据的关键信息,还能够在低维空间中捕捉到语义上的相似性。简单来说,就是机器无法直接识别人类的语言,所以需要通过Embedding去转化成机器能够
【AI大模型】使用Embedding API
我们可以调用response的object来获取embedding的类型。print(f’返回的embedding类型为:{response.object}')返回的embedding类型为:list。
人工智能安全(一)Leakage In Embedding: GEIA
GEIA”:,发表在ACL2022。GEIA通过模型生成的语句embedding存在泄漏敏感信息的可能性。GEIA可以通过embedding复原有序语句,且和真实的输入语句有高相似性。
大模型RAG基础知识 #Datawhale AI夏令营
在实际业务场景中,通用的基础大模型可能存在无法满足我们需求的情况,大模型幻觉、知识局限性,为了上述这些问题,研究人员提出了检索增强生成(Retrieval Augmented Generation, RAG)的方法。
人工智能 | Embedding
通过使用Embedding,我们可以将每个单词或句子表示为一个固定长度的向量,其中每个维度代表了某种语义特征。通过将文本转换为向量表示,我们可以在机器学习和深度学习模型中使用这些向量进行文本分类、情感分析、机器翻译等任务。近日,北京数元灵科技有限公司开源了语义向量(Embedding)模型:DMet
AI-知识库搭建(二)GPT-Embedding模型使用
Embedding模型是一种将高维度的离散数据(如文本、图像、音频等)映射到低维度的连续向量空间的技术。"Text-Embedding-Ada-002" 是OpenAIAP|中的一个预训练文本嵌入模型,它属于"Ada" 系列的-个变种。Ada系列的模型专注于文本分类和语言理解任务,它在理解语义和推断
【AI大模型】Embedding模型解析 文本向量知识库的构建和相似度检索
在大模型中,"embedding"指的是将某种类型的输入数据(如文本、图像、声音等)转换成一个稠密的数值向量的过程。这些向量通常包含较多维度,每一个维度代表输入数据的某种抽象特征或属性。Embedding 的目的是将实际的输入转化为一种格式,使得计算机能够更有效地处理和学习文本Embedding在自
详解AI大模型行业黑话,迅速搞懂提示工程(prompt)、向量工程(embedding)、微调工程(fine-tune)
当身边的人都在讨论大模型时,你有没有发现总会听到一些陌生的词汇?本文通过通俗易懂的例子带你轻松了解这些大模型的行业黑话,看完你也是专家!
AI 绘画Stable Diffusion 研究(十五)SD Embedding详解
那在上一篇中只是简单提到了Embedding, 对于我们实际使用stable diffusion过程中,可能很多朋友对Embedding的概念还不是很清楚。今天我们就来详细介绍一下Embedding, 它到底是干嘛的?在使用stable diffusion进行绘画时,Embedding可以用于将输入



