
方法一:有序加权平均: OWA有序加权平均算法是一种用于处理不平衡数据的算法。在OWA中,不同的数据被赋予不同的权重,然后根据这些权重进行加权平均计算。这种方法可以有效地处理不平衡数据,并且可以为不同的数据类型提供不同的重要性。详情可参考IFROWANN文章。(调节效果主要取决于权向量的选择)


方法二:SMOTE:
SMOTE算法相对于传统的随机过采样算法有哪些进步?
答:与传统的随机过采样算法相比,SMOTE算法通过更好的合成少数类样本来解决类别不平衡问题,而不是简单地复制样本。因此,它可以提高分类器的性能,同时减少过拟合问题。这使得SMOTE算法在解决类别不平衡问题上更加有效和可靠。传统随机采样容易产生过拟合问题。
SMOTE算法是一种用于解决数据不平衡问题的机器学习算法。所谓数据不平衡,指的是数据集中不同类别的样本数量不平衡,导致训练出的模型在预测时偏向数量较多的类别。SMOTE算法的全称为Synthetic Minority Over-sampling Technique,即合成少数类过采样技术。它通过生成一些合成样本来增加少数类的样本数量,从而平衡数据集。
SMOTE算法在合成样本时,采用了对少数类样本进行随机插值的方法,即在少数类样本之间随机选取一些样本,对它们进行线性插值,得到新的合成样本。该算法的基本思想是在少数类样本中找出一个样本,然后在它的近邻中随机选取一个样本,计算两个样本之间的距离(一般采用欧氏距离),然后在两个样本之间进行插值,得到一个新的样本。这个新样本被添加到数据集中,从而使得数据集中少数类的样本数量增加(即过采样技术)。(注意:选出来的另一个样本也是少数类样本)
算法步骤如下

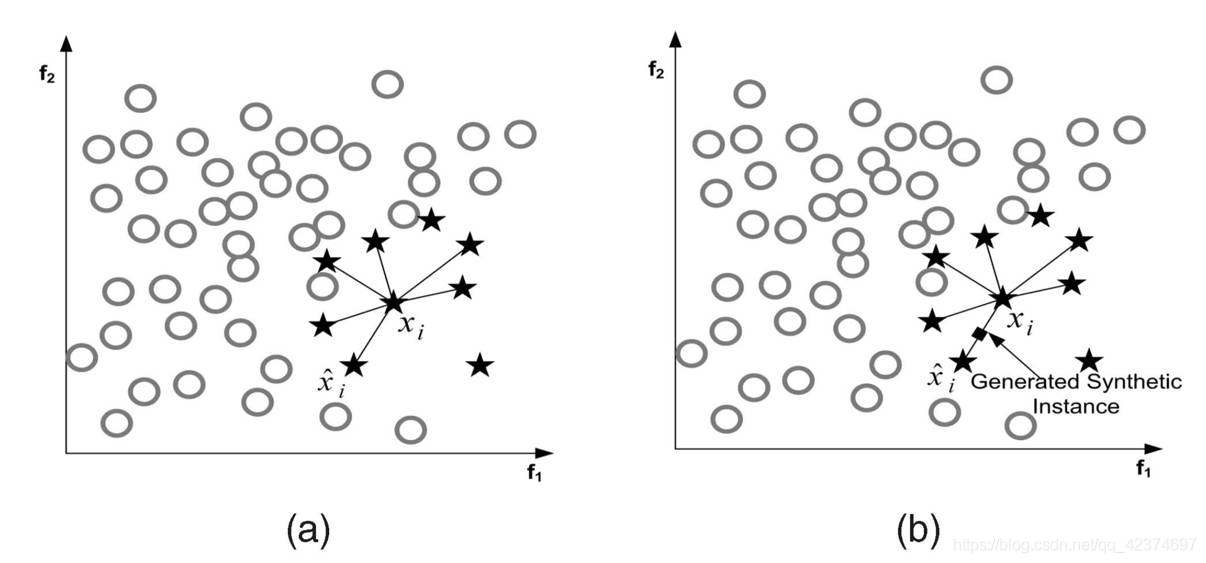
(上图星星代表少数类样本,圆圈代表多数类样本)
缺点:
该算法主要存在两方面的问题:一是在近邻选择时,存在一定的盲目性。
从上面的算法流程可以看出,在算法执行过程中,需要确定K值,即选择多少个近邻样本,这需要用户自行解决。
从K值的定义可以看出,K值的下限是M值(M值为从K个近邻中随机挑选出的近邻样本的个数,且有M< K),M的大小可以根据负类样本数量、正类样本数量和数据集最后需要达到的平衡率决定。但K值的上限没有办法确定,只能根据具体的数据集去反复测试。因此如何确定K值,才能使算法达到最优这是未知的。
另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的“人造”样本也会处在这个边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但加大了分类算法进行分类的难度。
SMOTE算法的改进算法:
①Borderline-SMOTE:
Borderline SMOTE是在SMOTE基础上改进的过采样算法,该算法仅使用边界上的少数类样本来合成新样本,从而改善样本的类别分布。
Borderline SMOTE采样过程是将少数类样本分为3类,分别为Safe、Danger和Noise,具体说明如下。最后,仅对表为Danger的少数类样本过采样。
Safe,样本周围一半以上均为少数类样本,如图中点A
Danger:样本周围一半以上均为多数类样本,视为在边界上的样本,如图中点B
Noise:样本周围均为多数类样本,视为噪音,如图中点c
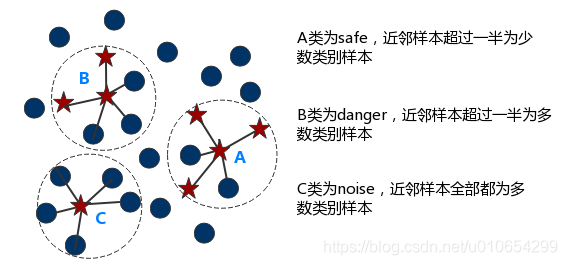
Borderline-SMOTE又可分为Borderline-SMOTE1和Borderline-SMOTE2,Borderline-SMOTE1在对Danger点生成新样本时,在K近邻随机选择少数类样本(与SMOTE相同),Borderline-SMOTE2则是在k近邻中的任意一个样本(不关注样本类别)
算法详细步骤:
Borderline Smote算法是对SMOTE算法的扩展,用于过采样不平衡的数据集。它通过在分类模型的决策边界附近插值生成少数类实例的合成样本。以下是Borderline Smote算法的详细步骤:
找出接近决策边界的少数类实例。即danger类。
对于每个少数类实例,从少数类中找到它的k个最近邻。
对于每个少数类实例,计算其和其中一个k个最近邻之间的差向量。
将差向量乘以0到1之间的随机数,并将结果加到少数类实例上,生成新的合成实例。
重复步骤4指定的次数,生成多个合成实例。
将合成实例添加到少数类中,平衡数据集。
在平衡数据集上训练分类模型,并在测试集上评估其性能。
总结:说白了就是只在DANGER决策边界上的样本进行插值过采样来改善不平衡。
②AHC:层次聚类算法
层次聚类算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树。
基本步骤:
1)(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2)寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3)重新计算新生成的这个类与各个旧类之间的相似度;
4)重复2和3直到所有样本点都归为一类,结束。
AHC算法相较于传统SMOTE算法的改进之处在于可以有效抵御噪声和识别异常值。具有鲁棒性。
原因:AHC 算法可以处理噪声和异常值,因为它使用分层聚类方法,可以将相似的数据点分组在一起,而不管它们的噪声或异常值状态如何。 这意味着即使有一些数据点远离主要集群,算法仍然能够识别它们并将它们与其余数据区分开来。 此外,AHC 算法使用有助于最小化噪声和异常值影响的链接标准,例如单一链接标准,它仅考虑每个集群中最接近的点对。 总的来说,AHC 算法是一种鲁棒的聚类方法,可以处理范围广泛的数据类型和噪声水平。
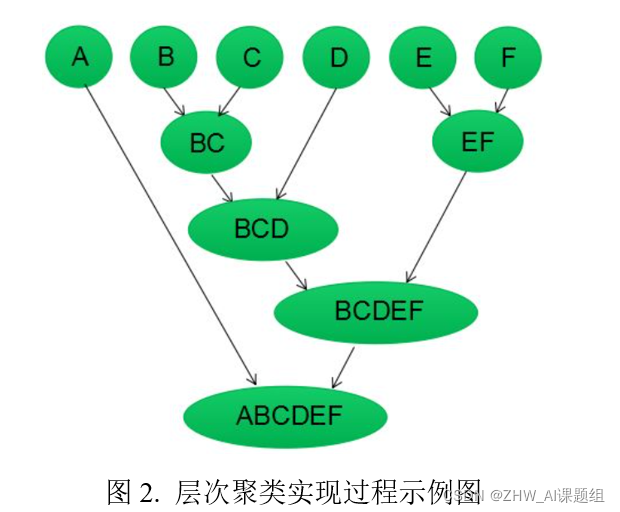
AHC算法为什么能够处理不平衡数据?
答:AHC算法采用的是层次聚类的方法,这种方法可以根据数据相似度将数据逐层地合并为更大的类别。在这个过程中,如果某个类别的数据量较小,那么它可以被合并到更大的类别中,从而避免了数据不平衡造成的影响。 参考流程如上图所示
方法3 Easy Ensemble
Easy Ensemble 算法是一种集成学习算法,主要用于解决非平衡数据集分类问题。非平衡数据集是指在分类问题中不同类别的样本数目存在明显不平衡,例如在肿瘤样本数据集中,恶性样本可能只占样本总数的一小部分,而良性样本占大多数。这种不平衡的数据集会导致传统分类算法的准确率和召回率降低。
Easy Ensemble 算法的核心理念是将所有少数类别样本的子集分配给不同的基分类器,然后将它们的预测结果进行整合来获得最终的分类结果。具体步骤如下:
第一步是生成多个子集,每个子集包含少数类别的样本和同等数量的多数类别的样本。(Easy Ensemble算法生成的子集中,每个子集内的多数类和少数类之间的样本数量比例是相等的,都是1:1。具体而言,Easy Ensemble算法首先通过某种方式得到多个不同的训练集(例如通过有放回的随机抽样),然后对每个训练集进行下采样,使得少数类别样本的数量等于多数类别样本的数量,从而保证了每个子集内的多数类和少数类之间样本数量的平衡。接着,在每个子集上,可以使用任何分类器训练出一个基分类器,然后将这些基分类器进行集成,形成一个更为强大的分类器,能够更好地处理不平衡的数据集。)
在每个子集上使用基分类器进行训练,例如决策树、支持向量机等。
对于每个基分类器,只选择分类准确率较高或较好的模型,或者采用随机选择的方式。
对所有基分类器的预测结果进行汇总,例如采用投票、加权投票等方式进行汇总,以得到最终的分类结果。
Easy Ensemble 算法的优点在于能够有效地解决非平衡数据集分类问题,并且可以提高分类的准确率和召回率。缺点是需要使用大量的基分类器,计算成本较高。此外,Easy Ensemble 算法可以进一步扩展到其他的集成学习算法上,如 AdaBoost 和 Bagging 等。
方法4
Balance Cascade算法是一种基于级联分类器的算法,它被广泛应用于解决高度不平衡的数据集分类问题。Balance Cascade算法的基本思想是通过级联分类器的方式,对多次下采样的训练集进行训练,以增强分类器对少数类的检测能力。
算法的具体步骤如下:
根据少数类和多数类的比例,选择一个适当的下采样比例,从多数类中随机采样一部分样本与少数类样本匹配。
使用下采样后的样本,通过某种分类算法(如SVM、LR等)训练一个基分类器,得到该分类器的误分类样本集合。
在误分类样本中,随机选择一部分样本,加入少数类样本中,重新构建训练集,并使用该数据集训练一个新的分类器。
重复步骤2和步骤3,直到达到一定的分类精度(如达到指定的误差率或达到指定的基分类器数目)为止。
将得到的多个基分类器进行集成(如使用投票方法),以得到最终的分类器。
Balance Cascade算法的核心思想是通过不断迭代地下采样和重新训练,使得训练集中少数类和多数类的样本比例越来越接近,并且在每个级联分类器中,通过结合误分类样本和少数类样本,强化分类器对少数类的分类能力。相比于一些采用权重调整的方法,Balance Cascade算法更适用于高度不平衡的数据集分类问题,能够有效地提高分类精度。
-待续
版权归原作者 kobe_shen 所有, 如有侵权,请联系我们删除。