
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
如果有一些非常奇怪的形状的数据,你该怎么办?使用决策树吗?当你了解了非参数化模型后,很容易认为参数化模型太笨重而无法在复杂的建模项目产生好的效果。像决策树、k近邻等非参数化模型有一个显著的优势:它们不像参数模型那样对潜在的分布或方程进行假设。
正如他的名字表示的含义:参数化模型试图找到最能描述数据的参数或某些方程或直线,这可不是一项简单的任务!因为在实际生活中的数据很少会呈现这种漂亮的线性形式,例如下面这张图:
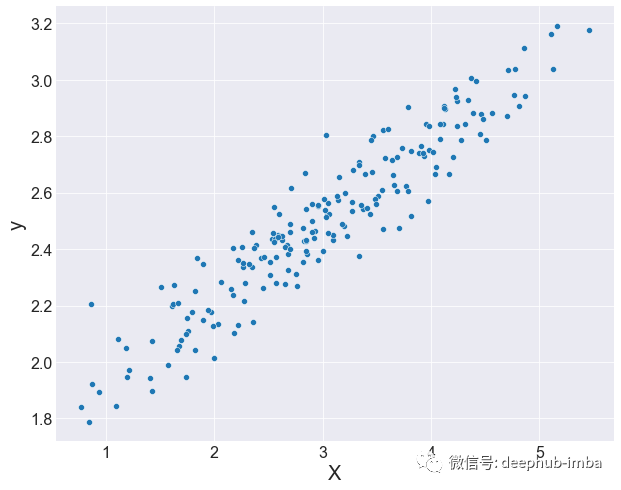
如果收集到更多的点,可能数据就变成这样了:
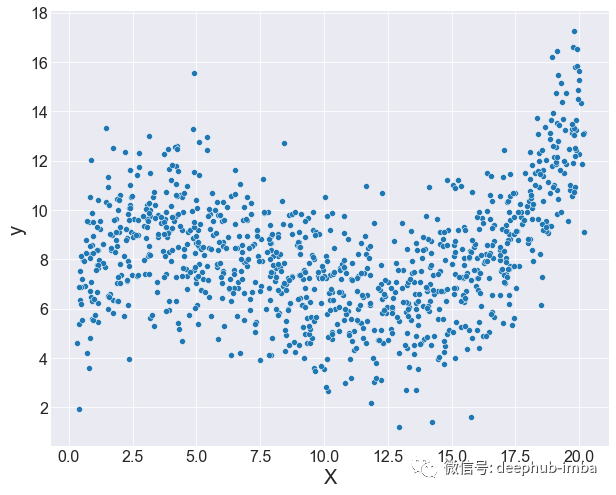
看完上面的说法,你可能认为参数估计过于局限,注定不会产生好的结果。那么我们要怎么处理呢?可以完全避免参数化建模,但这会带来一系列问题,比如有时可能必须使用参数化模型。如果必须使用参数化模型时,你可以试试多元分数多项式 (MFP)
MFP算法将复杂的特征工程和特征选择结合在一起,以一种整洁的、程序化和统计上合理的方式进行建模。
但在我深入了解 MFP 的细节之前,先简要介绍一下参数化建模……
参数化建模
我们假设,如果需要得到一条线来拟合一堆数据点。这个需求经常出现在线性回归的例子中,所以我们这里也使用线性回归因为它最简单。线性回归用这样一个方程来描述:

使用线性回归对上面的第一张图中的数据建模的2D可视化:
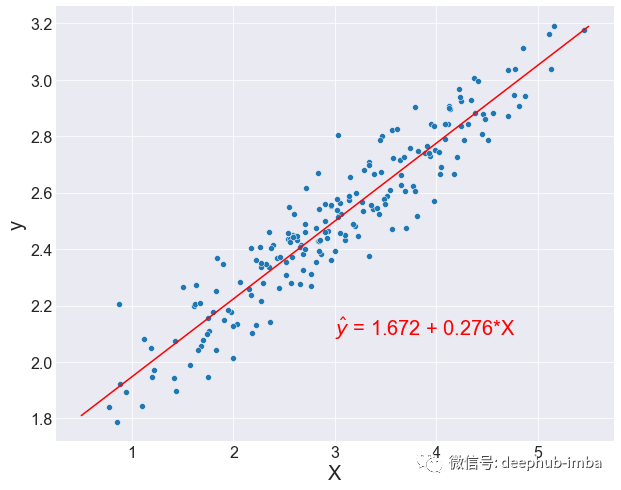
因为一般情况下,我们的大脑只能理解3D的事物,所以这里使用最简单的方式。对于多元变量来说,它的工作方式是一样的。
一个因变量可能是许多独立输入变量的输出。需要说明的是从现在开始的变量都是连续变量(可以在一个范围内取任何数值的变量)。这里另外一个最基本的基本假设是,独立变量(上面的X)是一阶的(一次方)。
为了使我们得到的关系更线性,还可以对自变量进行许多试验,这就是我们说的特征工程。例如可以创建交互项,多项式特征,对特征进行对数变换等等,理论上可以对原始特征进行任何的变换。例如Scikit-learn中的PolynomialFeatures能够在一行代码中通过将所有原始特征相乘或与它们自身相乘来创建一系列新特征:如果你有特征 A、B、C,你可以制作 AB、AC、A²、B*C、B²、C² 的 2 次多项式特征。
除了前面提到的这些之外,通过编程创建非线性特性并不容易,因为通常需要一定程度的领域专业知识才能知道该注意什么。但这里也可以进行一些猜测和实验,因为无论你对这个领域有多了解,都不可能一次性的想到所有的注意事项,特征工程虽然是经验性的但还是需要实验。从上面说的 PolynomialFeatures 方面来看,仅仅制作一大堆特征也会导致其他问题:只有一小部分是重要的。这种霰弹枪方法需要一些强大的特征选择算法的支持,才能保证真正重要的特征组合被留下来。
如果我们可以创建一些极端复杂的组合并消除不必要的复杂性,那会怎么样?
多元分数多项式(MFP)
据我所知,这项技术最早发表于1994年,由Patrick Royston和Douglas G. Altman在《Journal of the Royal Statistical Society》上发表。在论文的总结中,他们描述了我上面描述的一些相同的缺点(当然还有其他的)并完整地描述了传统解决方案的缺点。然后他们提出了一个解决方案,即“extended family of curves…whose power terms are restricted to a small predefined set of integer and non-integer values. Powers are selected so that conventional polynomials are a subset of the family”。在论文的最后,他们提出了一种在这个曲线家族中迭代选择每个因变量的幂的算法。这就是我上面提到的关键特征选择的作用所在,因为它将逆向消除包含在内作为处理过程的一部分。这篇论文以几个医学上的例子结尾——也许这是一个结尾的含义重大,因为目前看这种技术在今天仍然存在于该领域并且还在使用。
我不会深入研究这篇文章中的各种示例,本文的目的是介绍这种技术是如何处理真实数据的。此外,如果你希望获得更多示例,只需简单地搜索“Multivariate Fractional Polynomials”,就可以获得大量医疗数据示例。
“曲线家族”:让特征工程变得更简单
我们将首先深入了解“曲线家族”的基本概念,然后深入研究他们提出的迭代算法。Duong 等人的论文。(2014) 提供了比我能想出的任何内容都要好的总结。有一个预定义的集合 S = {-2, -1, -0.5, 0, 0.5, 1, 2, 3} 包含所有自变量的可能幂(0 定义为 ln(X))。对于取自该集合 S 的不同幂值(p、p1 和 p2),变量可以采用 X^p(度数 1)或 X^p1 + X^p2(度数 2)的形式。从技术上来说,这可以扩展到2度以上,但Royston和Altman认为这是不必要的。这两个分数多项式(FP)的构造如下:
FP degree 1 with one power p:
y = β0 +β1X^p
(when p=0): y= β0 +β1ln(X)
FP degree 2 with one pair of powers (p1, p2):
y = β0 + β1X^p1 + β2X^p2(适用与 p=0 相同的规则)
(when p1=p2): y = β0 + β1X^p1 + β2X^p2*ln(X)
从这个结构中,FP1有8个具有8种不同幂值的模型,而FP2有36个不同的模型——这8种值的28种组合和8种重复的组合。所以我们得到了44个可能的模型,我们可以用它们来拟合我们的数据。关键点是这些只是起点,因为β系数的值也会改变这些线的形状(见下文)。
仅仅基于方程可能很难看出它的价值,视觉演示也许能最好地解释为什么这44个模型如此有效。看下面的图时,请思考一下这些线轨迹有多么复杂。
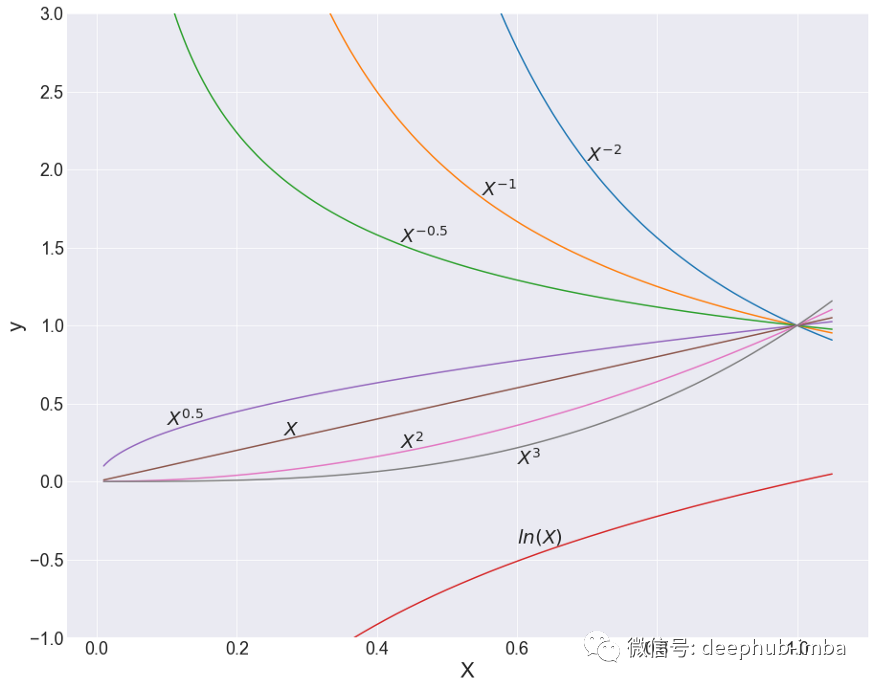
FP 1 次多项式,从 X=~0 到刚好高于 X=1。所有 β 系数 = 1。
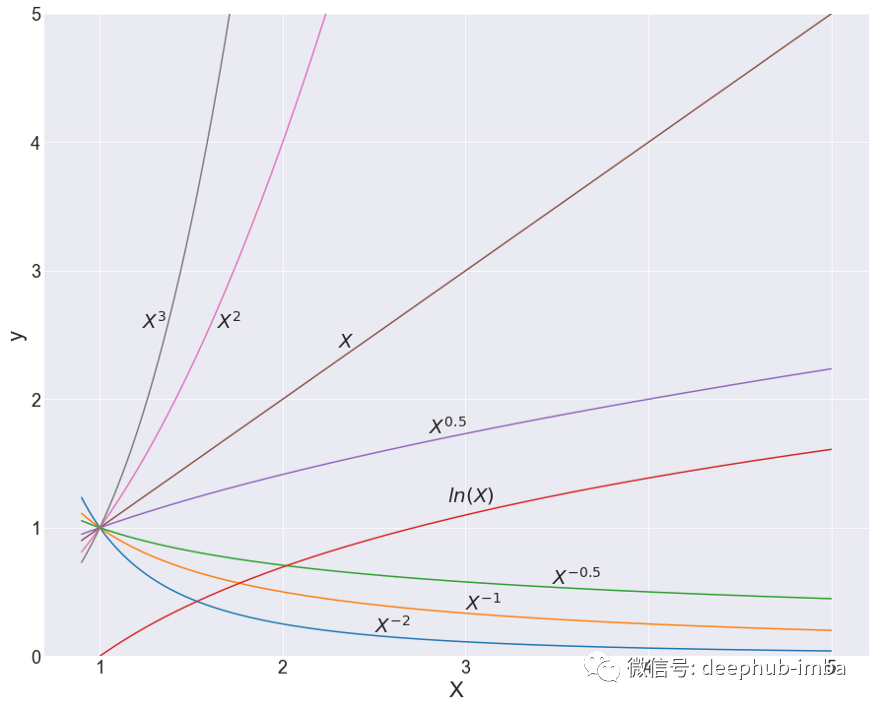
FP 1 次多项式,从 X=1 到 X=5。所有 β 系数 = 1。
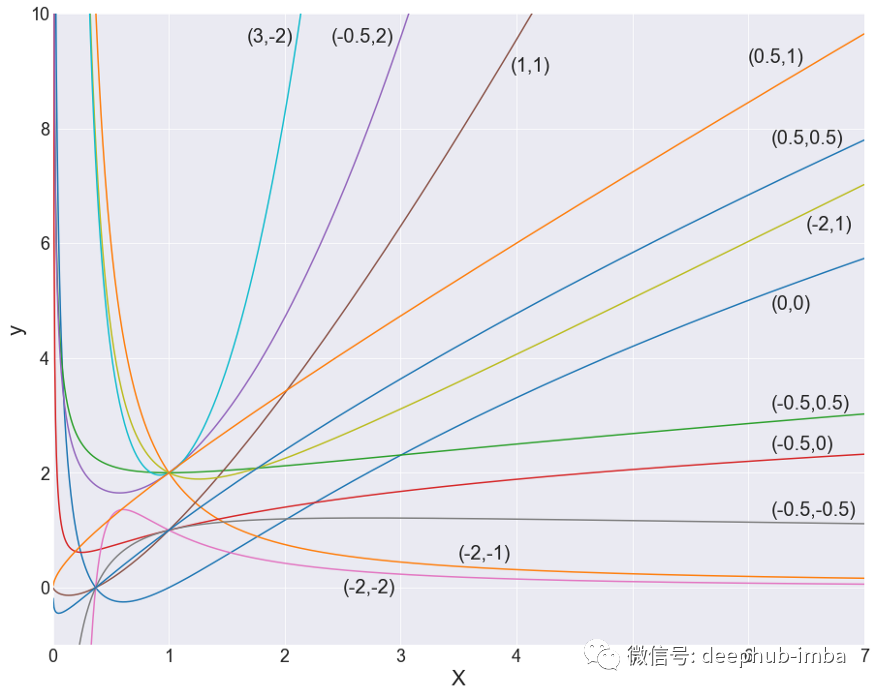
FP 2 次多项式。元组表示 X 的幂。所有 β 系数 = 1。我花了很长时间才做到这一点。
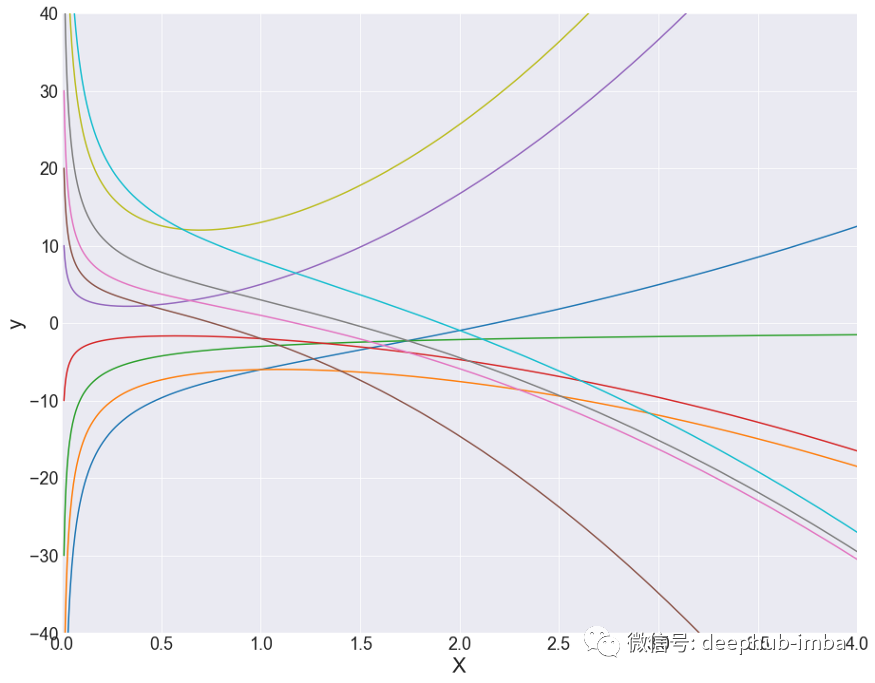
形式为 (-0.5, 2) 的 FP 2 次多项式,具有不同的 β 系数值。
这就是特征工程的强大之处——这种方法为我们的自变量提供了一组最具描述性的能力,以及将它们组合在一起的结构。这已经足够了,而且该方法还带有一个特征选择组件。
内置特征选择原理
我将使用其他人的清晰解释来说明这一点,这里是来自 Duong 和 Zhang 等人(2016 年)发表的文章。Zhang 概述了如何为自变量选择合适的度数和正确的幂的一般程序。它首先指出该过程有两个组成部分:
- 向后消除统计上不显著的变量
- 变量的 FP 度的迭代检查
对于上述两部分,需要两个显着水平:α1:用于排除/包含变量,以及 α2:用于确定变换的显著性。a1 和 a2 可以(并且通常是)相同的值,但也可以随意对其修改。
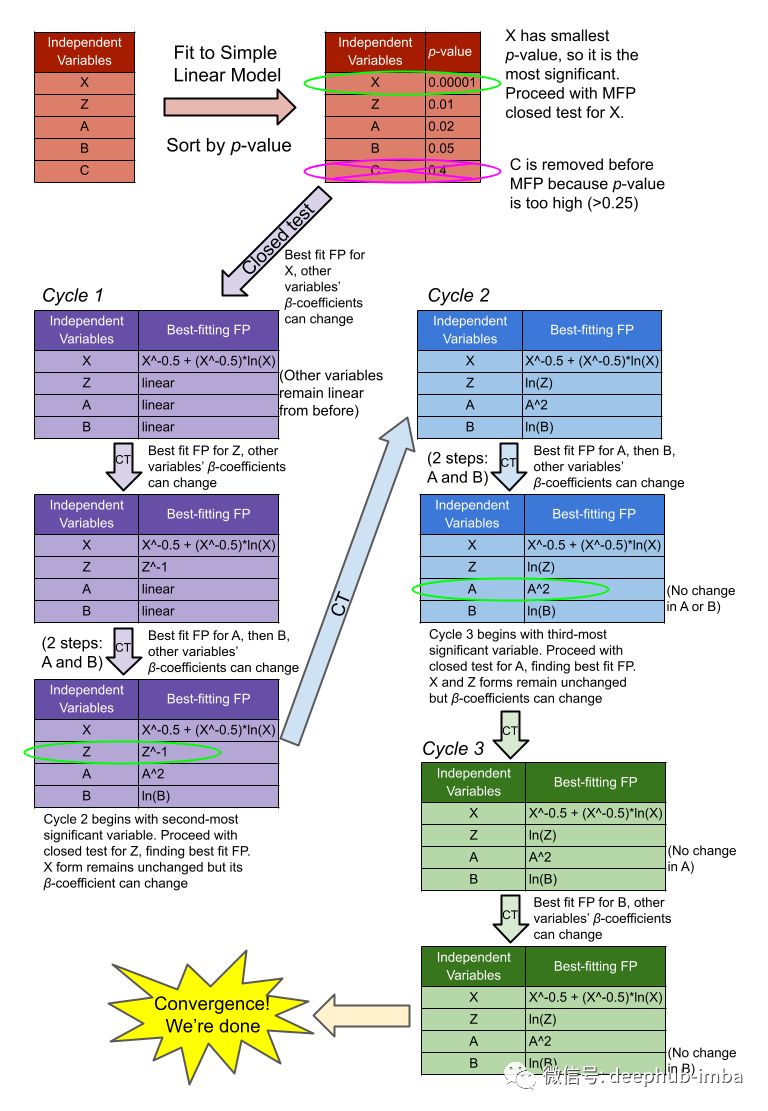
有了α值和连续变量列表,就可以开始构建一个包含所有变量的多变量线性模型,或者可以使用目标对每个变量进行单变量分析,将结果中筛选出p<0.25或0.2的变量以减少不重要的变量(特征选择)。然后根据第一个模型的p值的增加来顺序筛选所有变量。
下一步是取最高、最低的 p 值变量并开始测试,这个测试将跟踪更改变量是如何影响完整模型拟合(也就是它不是单变量模型)。其过程如下(来自 Duong 的统计测试的详细信息):
- 第一步:根据偏差(模型误差),找到该变量的最佳拟合二阶分数多项式 (FP2)。使用具有 4 个自由度的卡方差异检验将其与空模型(其中变量不存在)进行比较。如果检验不显著(根据 α1),则放弃该变量并得出该变量对目标没有影响的结论。否则,继续。
- 第二步:将第一步中的FP2模型与线性模型(幂= 1)进行比较,使用3个自由度的卡方差分检验确定非线性。如果测试不显著(根据α2),变量是线性的,测试结束。否则,继续。
- 第三步:求变量的最拟合一阶分数多项式(FP1),类似于第一步。使用2自由度的卡方差异检验将其与FP2模型进行比较。如果测试不显著(根据α2),模型不会从额外的复杂性中受益,正确的模型是FP1。
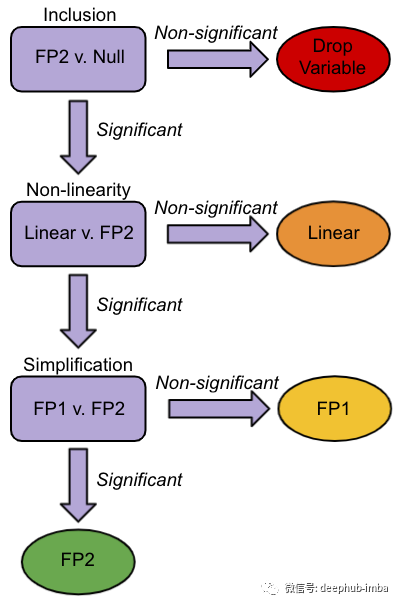
现在,一旦对最低 p 值变量执行了上述测试,那么就可以对前面在原始大型线性模型中生成的有序列表中的下一个最高的p值变量进行同样的评估。保留前一个 X 的 FP 形式但 β 系数可以改变。对其他变量依次进行并且标记为第一个循环。第二个循环是相同的过程,只是从第二个最低p值变量开始,并保持前一个低p值变量的FP形式。这个循环过程不断重复,直到两个循环收敛并且没有任何变化。
MFP 缺点
据我所知,MFP 的主要缺点在于它的计算成本很高。但我想这并不奇怪,因为需要经过很多个步骤才能为每个特征找到理想的 FP 形式——在典型的场景中,选择算法需要计算 44 个模型进行比较,对于每个特征,这可能需要相当长的时间。但如果放在实际环境中,能够捕捉到类似复杂性水平的模型(例如使用grid search的随机森林或神经网络)可能不会取得那么好的效果。此外,使用有些模型运行时间会减少,但没有可解释性(神经网络)。所以MFP 似乎取得了很好的平衡。
另外一个缺点:MFP 似乎忽略了交互项,如果两个变量具有协同效应,则 MFP 将在执行算法时忽略它们。解决这个问题的一个简单方法是在开始时提供交互条件,但是添加特征会增加运行时间。或者可以完全放弃内置选择算法并尝试 PolynomialFeatures 类型的工作流程,只需使用 FP 集 S 中的幂。
切入正题——Python 包在哪里?
感谢你能够阅读到这里,但不幸的是这里没有什么好消息要告诉你。目前看似乎没有简单的方法可以将其合并到 Python 的数据项目中。在医学统计背景之外,也没有太多关于这种非常强大的方法的讨论,尽管它的广泛用途是显而易见的,并且它确实作为 R 和 Stata 中的一个函数存在,但目前还没发现任何 Python 包,我觉得这令人震惊。Python 中最接近于对这种级别的曲线细节进行建模的是 Scikit-learn 的spline函数,它似乎做了一件非常棒的工作——但它可能很难单独使用,而且MFP方法有明显的优势。
其实这才是回答本文标题的要点,没有包啊这才是最大的缺点🤣
引用
Royston, P., & Altman, D. G. (1994). Regression Using Fractional Polynomials of Continuous Covariates: Parsimonious Parametric Modelling. Journal of the Royal Statistical Society. Series C (Applied Statistics), 43(3), 429–467. https://doi.org/10.2307/2986270
Duong, H., & Volding, D. (2014). Modelling continuous risk variables: Introduction to fractional polynomial regression. Vietnam Journal of Science, 1(2), 1–5.
Zhang Z. (2016). Multivariable fractional polynomial method for regression model. Annals of translational medicine, 4(9), 174. https://doi.org/10.21037/atm.2016.05.01
作者:Nicholas Indorf
喜欢就关注一下吧:
点个 在看 你最好看!********** **********