
原文地址:小白系列(1) | 计算机视觉之图像分类
本文将分享以下内容:
- 图像分类为什么那么重要?
- 什么是图像分类?
- 图像分类是怎么做的?
- 基于机器学习的图像分类
- CNN图像分类(深度学习方法)
- 图像分类的应用举例
01 图像分类为什么那么重要?
我们生活在数据时代。随着物联网(IoT)和人工智能(AI)成为无处不在的技术,我们现在产生了大量的数据。数据的形式多种多样,可以是语音、文本、图像,也可以是这些形式的混合。而图像以照片或视频的形式在全球数据创建中占了很大的份额。
AIoT是人工智能和物联网的结合,能够开发高度可扩展系统,可以利用机器学习进行分布式数据分析。
1.1 为什么需要AI理解图像
由于我们从相机和传感器获取的大量图像数据是非结构化的,所以我们需要利用机器学习算法等先进技术来有效地分析图像。图像分类应该是数字图像分析中最重要的部分。现在使用基于深度学习的模型来分析图像,获得的结果在特定任务中已经超过了人类的准确性(例如在人脸识别的任务中)

计算机视觉之人脸识别——基于Voso Suite构建
由于人工智能的计算非常密集,并且涉及到大量潜在敏感的视觉信息传输,因此在云端处理图像数据具有严重的局限性。所以,现在有一种叫做边缘AI(Edge AI)的新的研究趋势,旨在将机器学习(ML)任务从云端转移到边缘。这允许将ML计算移动到数据源附近,特别是连接到相机的边缘设备(计算机)。
在边缘执行图像识别的机器学习可以克服云端在隐私、实时性能、效率、鲁棒性等方面的限制。因此,边缘人工智能在计算机视觉中的应用使得在真实世界场景中扩展图像识别应用成为可能。
1.2 图像分类是计算机视觉的基础
计算机视觉包括一系列重要任务,如图像分类、定位、图像分割和目标检测。其中,图像分类可以被认为是最基本的内容。它构成了其他计算机视觉任务的基础。
图像分类应用在许多领域,如医学成像、卫星图像中的目标识别、交通控制系统、刹车灯检测、机器视觉等。

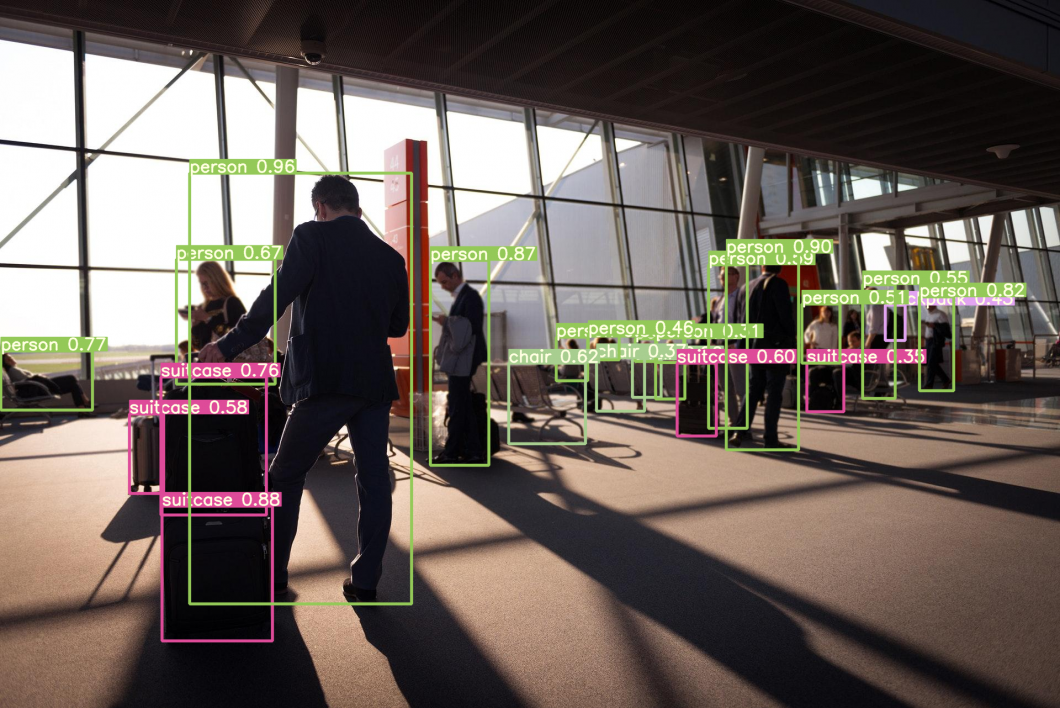
视频帧中的目标检测,可以识别预训练的类“person”“bicycle”
02 什么是图像分类?
图像分类是根据特定规则对图像中的像素或矢量图进行分类和分配标签的任务。分类法则可以通过一个或多个光谱或纹理表征来应用。
图像分类主要包含两类:有监督图像分类和无监督图像分类
2.1 无监督分类
吴建福分类技术是一种完全自动化的方法,不需要利用训练好的数据。这也意味着机器学习算法可以在没有人工干预的情况下,探索隐藏的模式和数据组来分析和聚类无标注的数据集。
在合适的算法的帮助下,图像处理阶段可以系统地识别图像的特定特征。模式识别和图像聚类是这里最常用的两种图像分类的当打。用于无监督图像分类的主流方法有两种:K-mean和ISODATA
- K-mean是一种无监督分类算法,它根据目标的特征将目标分为K组,这种方式也称为“聚类(Clusterization)”。K-means聚类是最简单且使用非常广泛的无监督机器学习算法之一。
- ISODATA指的是“迭代自组织数据分析方法(Iterative Self-Organizing Data Analysis Technique)”,这种方法包括使用欧几里得距离作为相似性度量的迭代方式,将数据元素聚类到不同的类中。相比于K-means方法是假定聚类数是先验已知的,ISODATA算法是可以有不同数量的聚类的。
2.2 有监督分类
有监督图像分类方法使用预分类的的参考样本(基本事实)来训练分类器,之后再对新的未知数据进行分类。
所以,有监督分类技术是在图像中直观地选择训练数据样本并将其分配各预选类别(包括:植被、道路、水、建筑物等)的过程。这样做,是为了创建能够应用于所有图像的统计标准。
2.3 图像分类方法
使用训练数据的方式对整体图像进行分类,最常用的方法有两种:最大似然估计(Maximum Likelihood)和最小距离法(Minimum Distance)。
像最大似然估计法,是基于数据的统计特征进行的,其中首先分析图片的每个纹理和光谱指数的标准差和平均值,然后通过每个类中像素的正态分布来计算每个像素分离类的可能性。另外,也会使用一些经典的统计和概率关系。最终像素呗标记为一类显示最高可能性的特征。
03 图像分类是怎么做的?
计算机是以像素的形式对图像进行分析的。它通过将图像视作矩阵数组来达到分析的目的,其中,矩阵的大小取决于图像的分辨率。总的来说,计算机视觉中的图像分类是使用算法对这些统计数据的分析。在数字图像处理中,图像分类是通过自动将像素分组到制定的类别(类)来完成的。
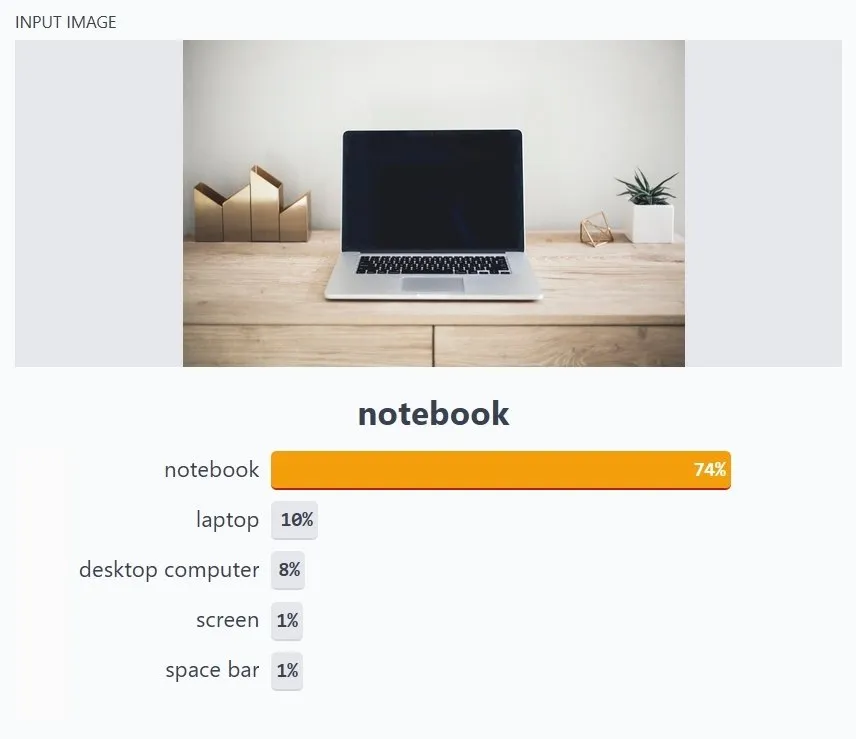
图像分类示例:深度学习模型返回类及概率(置信度)
这些算法将图像分离成一系列最突出的特征,从而减轻了最终的分类器的工作量。这些特征帮助分类器了解图像所表示的内容,以及它可以被分为那一个类。特征提取过程是对图形进行分类的最重要的步骤,后面其它步骤都要在这个基础之上进行。
图像分类,尤其是有监督的分类,也在很大程度上依赖提供给算法的训练数据。与基于类的数据不平衡以及图像和图像标注的质量较差的不好的数据集相比,优化良好的分类数据集的效果会更好。

图为基于YOLO的目标检测示例,检测的是COCO数据集的“bicycle”和“dog”类
04 基于机器学习的图像分类
基于机器学习的图像识别是利用算法从有组织和无组织样本的数据集中学习隐藏知识(监督学习)的潜力。现在最流行的机器学习技术是深度学习,在深度学习模型中包含有许多的隐藏层。
4.1 图像分类的最新进展
深度学习的出现之后,结合强大的AI硬件和GPU,其在图像分类的任务已经表现出了出色的性能。因此,深度学习在整个图像识别、人脸识别和图像分类算法领域取得了很大的成功,实现了高于人类水平的性能和实时目标检测。
此外,在过去几年之中,算法推理性能也有了极大的进步:
- 在2017年,Mask R-CNN算法是MS COCO基准测试中最快的实时目标检测算法,每一帧的推理是啊金为330ms。
- 2021年发布的YOLOR算法,在同样的情况下,实现了12ms的推理时间,超过了主流的YOLOv3和YOLOv4算法
- 今年7月,YOLOv7的发布标志着一种新的技术水平,在速度和准确性方面超过了包括 YOLOR 在内的所有之前的版本。
4.2 相比于传统的图像处理,深度学习的优势是什么
与传统的图像处理方法相比,深度学习只需要机器学习工具的工程知识。它不需要特定机器视觉领域的专业知识来创建手工特征。
不管怎样,深度学习都需要人工的数据标记来解释好的和坏的样本,这被称为图像标注。从人类标注的数据中获取知识或提取见解的过程称为有监督学习。
此类用来训练AI模型的标注数据需要繁琐的人工工作,例如,标注自动驾驶中的常规交通状况。不过现在我们拥有大型数据集,其中包含数千个类别的数百万个高分辨率标注数据,例如ImageNet,LabelMe,Google OID或MS COCO。

用于深度学习监督训练的手工图像标注示例。视频帧中,绘制的是“person”类的矩形框
05 基于CNN的图像分类
图像分类可以定义为将图像分类为一个或多个预定义类的任务。尽管对图像进行分类是人的本能和习惯,但是对于自动化的系统而言,对图像进行识别和分类是很有挑战的。
5.1 神经网络的成功
在深度神经网络(DNN)中,卷积神经网络(CNN)在计算机视觉任务中表现出色,特别是在图像分类方面。卷积神经网络(CNN,或ConvNet)是一种特殊的多层神经网络,其灵感来自人类光学和神经系统的机制。
2012年,一个名为AlexNet的大型深度卷积神经网络在ImageNet大规模视觉识别挑战赛(ILSVRC)上表现出色,这标志着卷积神经网络模型(CNN)的广泛使用和发展的开始,如VGGNet,GoogleNet,ResNet,DenseNet等等。
应用于复杂场景的神经网络,基于Viso Suite构建
5.2 卷积神经网络(CNN)
CNN是使用机器学习概念开发的框架。CNN能够在没有人工干预的情况下,自己从数据中学习和训练。
事实上,使用 CNN 时只需要一些预处理。他们开发和调整自己的图像滤波器,这些滤波器必须针对大多数算法和模型进行详细编码。CNN 框架具有一组执行特定功能的层,以使 CNN 能够执行这些功能。
5.3 CNN 架构和层
CNN框架的基本单元被称为神经元。神经元的概念是基于人类神经元的。这些是统计函数,用于计算输入的加权平均值并将激活函数应用于生成的结果。层是神经元的簇,每层都有特定的功能。
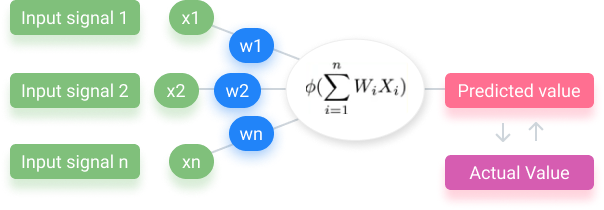
具有输入值(input,绿色)和权重(蓝色)的神经网络
一个CNN系统,可能拥有3-150层,甚至更多层:深度神经网络的“深度”就是只层数多。每层之间,一个层的输出,作为下一层的输入。深度多层神经网络有Resnet50(50层)、ResNet101(101层)。
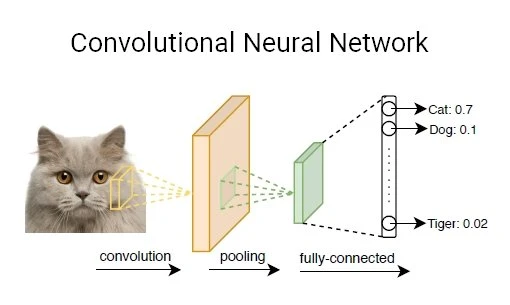
卷积神经网络(CNN)
CNN 层主要有四种类型:卷积层、ReLu 层、池化层和全连接层。
- 卷积层:卷积是将滤波器简单地应用于输入,从而导致激活。卷积层有一组可训练的滤波器,其接收范围很小,但可用于提供的全部数据。卷积层是卷积神经网络中使用的主要构建块。
- ReLu层:ReLu层,也称为整流线性单元层,是用于降低过拟合并构建CNN准确性和有效性的激活函数。具有这些层的模型更易于训练并生成更准确的结果。
- 池化层:该层收集其前面层中所有神经元的结果并处理此数据。池化层的主要任务是减少要考虑的因素数量并提供简化的输出。
- 全连接层:该层是 CNN 模型的最终输出层,它将从前面的层接收的输入数据进行扁平化处理并给出结果。
06 图像分类的应用举例
几年前,图像分类的主要应用于于安全方面。但是今天,图像分类的应用在众多行业中变得越来越重要,像医疗保健、工业制造、智能城市、保险,甚至太空探索中都很受。
应用方向激增的一个原因是可用的视觉数据量不断增加以及先进计算技术的快速发展。图像分类是一种从这些数据中提取价值的方法。作为一种战略资产,视觉数据的存储和管理成本已经超过了整个商业应用实现的价值。
图像分类有许多应用,例如:
(1)自动化检测和质量控制:图像分类可用于自动检查装配线上的产品,并识别不符合质量标准的产品。

制药时的AI视觉:用于压印药片视觉检查的图像处理
(2)无人驾驶中的物体识别:无人驾驶汽车需要能够识别道路上的物体,以便安全导航。图像分类可用于此目的。
(3)基于AI视觉的皮肤癌的分类:皮肤科医生检查数千种皮肤状况,寻找恶性肿瘤细胞。这是一项耗时的任务,可以使用图像分类自动执行。
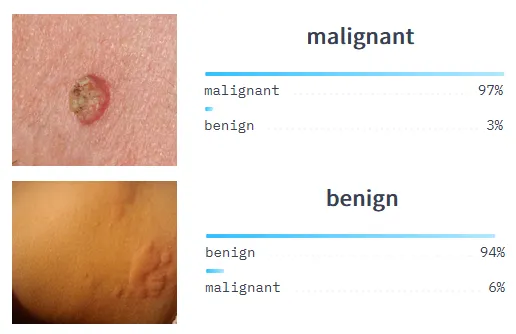
用于医学案例中癌症检测的图像分类示例
(4)人脸识别在安防中的应用:图像分类可用于从安全录像中自动识别人员,例如,在机场或其他公共场所执行人脸识别。
(5)流量监控和拥塞检测:图像分类可用于自动计算道路上的车辆数量,并检测交通拥堵。
(6)客户细分:图像分类可用于根据客户的行为自动将他们细分为不同的组,例如可能购买产品的客户。
(7)土地测绘:影像分类可用于自动绘制地图,例如,识别森林或农田区域。在这里,还可用于监测环境变化,例如,检测森林砍伐或城市化,或用于农业案例中的产量估算。
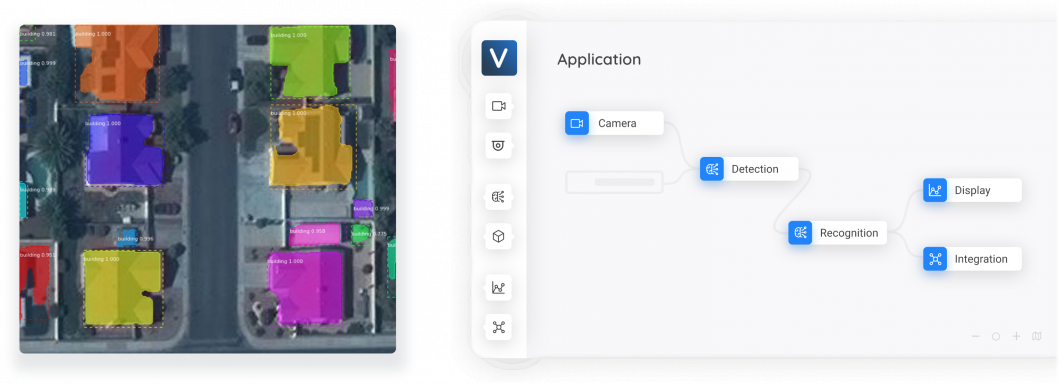
卫星图分析,基于图像分类的AI视觉Pipeline ,Viso Suite
07 最后的话
在图像分析和计算机视觉领域工作的研究人员明白,利用人工智能,特别是CNN,是图像分类的革命性一步。由于CNN是自训练模型,因此随着它们以标注图像(标记数据)的形式输入更多数据,它们的有效性只会提升。
不过下一个阶段会是什么呢?
今天,卷积神经网络(CNN)标志着人工智能视觉的当前技术水平。而2021年的相关研究表明,使用Vision Transformers (ViT) 执行计算机视觉任务的结果也很不错。
挖个坑,下一期,我们一起了解一下Vision Transformers,敬请期待!
—— 精彩推荐 ——
视觉3D目标检测,从视觉几何到BEV检测
万字综述 | 自动驾驶多传感器融合感知
两万字 | 视觉SLAM研究综述与未来趋势讨论
NeurIPS 2022 | GeoD:用几何感知鉴别器改进三维感知图像合成
末流985研一在读,视觉SLAM方向快坚持不下去了,大家可不可以给点建议...
基于SLAM的机器人自主定位导航全流程

版权归原作者 一点人工一点智能 所有, 如有侵权,请联系我们删除。